Обучение с расписанием для фильтрации данных и доменной адаптации в нейросетевом машинном переводе

Автор: Карпачёв Н.Е.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 3 (67) т.17, 2025 года.
Бесплатный доступ
Современные системы нейросетевого машинного перевода требуют для обучения большие объемы параллельных данных. Однако такие корпуса, собранные из множества источников, часто содержат значительный шум: неточности, стилистические расхождения и семантические ошибки. Стандартный подход с однократной статической фильтрацией неэффективен, так как слишком жесткая очистка ведет к потере ценных лингвистических примеров и ухудшению обобщающей способности модели, а мягкая — оставляет в данных артефакты, снижающие качество перевода. В данной работе для решения этой проблемы предлагается использовать технику «обучения с расписанием» (curriculum learning). Представлен метод динамической фильтрации, при котором критерии отбора данных постепенно ужесточаются по мере обучения, что позволяет модели сначала освоить общие закономерности, а затем сфокусироваться на высококачественных примерах. Эффективность этого подхода доказывается эмпирически. Кроме того, на базе той же методологии разработана схема адаптации больших языковых моделей (LLM) для перехода от перевода отдельных предложений к более сложной задаче перевода на уровне документов.
Нейросетевой машинный перевод, обучение с расписанием, большие языковые модели
Короткий адрес: https://sciup.org/142245836
IDR: 142245836 | УДК: 004.852
Curriculum learning for data filtering and domain adaptation of neural machine translation models
Modern Neural Machine Translation (NMT) systems require large volumes of parallel data for training. However, corpora collected from diverse sources often contain significant noise, such as translation inaccuracies, stylistic mismatches, and semantic errors. The conventional approach of static filtering faces a critical trade-off: overly aggressive filtering results in the loss of valuable linguistic diversity and harms model generalization, while lenient filtering allows artifacts that degrade final translation quality to remain. To address this challenge, this work proposes a dynamic filtering method based on curriculum learning technique. In this approach, data selection criteria become progressively stricter as training progresses, enabling the model to first master general patterns before focusing on high-quality examples. We empirically demonstrate the effectiveness of this method. Furthermore, we extend the same methodology to propose a framework for adapting Large Language Models (LLMs), guiding them from sentence-level translation to the more complex task of document-level translation.
Текст научной статьи Обучение с расписанием для фильтрации данных и доменной адаптации в нейросетевом машинном переводе
Современные системы машинного перевода основаны на глубоких нейросетевых моделях, обучаемых в режиме supervised learning на данных референсных переводов. Эти данные представляют собой пары из текста на исходном языке и примера хорошего перевода на целевом.
Для обучения нейросетевой модели с высокой аппроксимирующей способностью требуются большие объемы обучающих выборок. Исходя из этого, для получения параллельных данных достаточного размера используются разные источники и алгоритмы сбора: от ручных человеческих переводов до полностью автоматических процессов поиска и генерации данных.
В результате собранные выборки больших размеров могут содержать неточности и даже грубые ошибки в переводах, несвязанные по смыслу тексты, плохое соответствие стилю и канонам построения предложений на целевом языке.
Большое число таких ошибок в данных приводит к аналогичным проблемам у модели, вместе с тем жесткая фильтрация обучающего корпуса влечет за собой низкое покрытие возможных языковых явлений и плохую обобщаемость модели.
В текущей работе представлен способ динамической фильтрации зашумленных обучающих выборок на основе техники «обучения с расписанием» («curriculum learning»). Более конкретно, используемый для обучения датасет подбирается динамически и зависит от текущего шага: в начале обучения мелкие ошибки некритичны, так как для модели полезны любые примеры связанных по смыслу текстов на двух языках. На более поздних стадиях, напротив, даже небольшие неточности способны привести к аналогичным ошибкам в модели и необходима более жесткая фильтрация.
Кроме того, предложена схема адаптации больших языковых моделей (LLM) к задаче перевода более длинных документных сегментов текста от перевода по отдельным предложениям. Данных с переводами на уровне документов гораздо меньше, чем данных с переводами на уровне предложений, и стандартное обучение с равномерным смешиванием приводит к сильному смещению в сторону предложений. При этом апсэмплинг документного корпуса быстро приводит к переобучению.
В текущем исследовании предложен алгоритм быстрого дообучения за счет техники curriculum learning: изначально модель учится решать более простую задачу на уровне предложений и лишь в конце этапа дообучения переходит к более сложной и содержательной выборке с документами.
2. Обзор литературы2.1. Фильтрация данных
Существует большое количество методов фильтрации предложений для обучения перевода.
Глобально их можно разделить на три категории: фильтрация на основе правил (rulebased approach), использование машинно-обученной метрики для скоринга одного сэмпла из параллельной выборки и фильтрация на основе комбинации метрик.
Rule-based filters. Критериями отсева могут служить длина предложений, их лексический состав, наличие специфических токенов (например, URL-адресов) или несоответствие заявленной языковой принадлежности. Данный подход позволяет элиминировать наиболее явные аномалии в данных.
Scoring methods. Более сложные подходы предполагают переход от бинарной классификации к количественной оценке качества пар. Так, скоринговые методы применяют вероятностные модели, в частности языковые, для вычисления балла, коррелирующего с адекватностью перевода. Наиболее же современные подходы базируются на векторных представлениях (эмбеддингах), которые позволяют оценить семантическую эквивалентность пред- ложений в едином векторном пространстве, где близость векторов служит индикатором качества пары.
Центральной проблемой, инвариантной к выбранной стратегии фильтрации, является нахождение оптимального баланса между показателями точности и полноты (precisionrecall tradeoff). Установление избыточно строгих порогов ведет к исключению не только ошибочных, но и лингвистически разнообразных примеров, что снижает обобщающую способность модели. Напротив, мягкие критерии допускают сохранение в обучающей выборке значительного числа артефактов, негативно влияющих на качество итоговой системы. Следовательно, ключевая задача состоит в определении такого порога, который максимизирует элиминацию некорректных данных при минимизации потерь ценного обучающего материала.
2.2. Расписание обучения
Обучение с расписанием, или curriculum learning, представляет собой семантически осмысленный процесс отбора данных для обучения на каждом шаге, в отличие от стандартного обучения с равномерным сэмплированием каждого мини-батча из полного набора обучающих данных.
С формальной точки зрения, расписание обучения С определяется как упорядоченная последовательность обучающих критериев Qi, где каждый критерий соответствует отдельной фазе обучения. На каждой фазе Qi задает модифицированное распределение вероятностей для сэмплирования данных. Это достигается путем введения весовой функции W(х,у), которая изменяет исходную вероятность выбора для каждой пары (х,у). Таким образом, на различных этапах градиентного спуска мини-батчи формируются из данных, отобранных в соответствии с заданным смещенным распределением.
Последовательная модуляция распределения выборки позволяет организовать процесс обучения в соответствии с некоторой стратегией, чаще всего — по принципу возрастающей сложности («от простого к сложному»). По аналогии с человеческим обучением, такой подход позволяет модели сначала извлечь фундаментальные, более простые закономерности и лишь затем адаптироваться к полному, более сложному распределению данных. Благодаря своей эффективности, данная методология нашла широкое применение в различных областях машинного обучения, включая задачи нейросетевого машинного перевода.
2.3. Перевод на основе больших языковых моделей
В настоящий момент технология машинного перевода активно смещается от специализированных нейросетевых моделей к универсальным большим языковым моделям (LLM). Эти модели демонстрируют впечатляющие способности к переводу без специальной подготовки (zero-shot), однако их применение в «сыром» виде ограничено недостаточной точностью в узких доменах, склонностью к генерации нерелевантной информации («галлюцинациям») и высокой вычислительной стоимостью инференса. Таким образом, для достижения максимального качества и надежности возникает необходимость в их адаптации.
Полномасштабное дообучение LLM является крайне ресурсозатратным, поэтому для их адаптации были разработаны методы параметро-эффективного дообучения (РЕРТ). Ключевая идея РЕРТ заключается в «заморозке» основной части весов предобученной модели и обучении лишь небольшого числа дополнительных параметров. Наиболее успешные техники, такие как LoRA (Low-Rank Adaptation) и ее более эффективная версия QLoRA, позволяют адаптировать даже гигантские модели к задачам перевода на относительно доступном оборудовании, значительно снижая затраты и риск «катастрофического забывания».
3. Динамическая фильтрация обучающих данных
В качестве критерия для ранжирования примеров во время процедуры обучения имеет смысл использовать две метрики — сложности перевода (difficulty) и зашумленности примера (noise). Эти два фактора играют существенную роль в полезности данных для обучения модели. При этом они особенно важны в конфигурации обучения на больших корпусах, собранных из разных источников.
Известно, что процедура обучения, основанная на сложности примеров («от простого к сложному»), эффективна в машинном обучении в целом и в том числе в машинном переводе. Ранжирование примеров позволяет обеспечить постепенное усложнение решаемой нейросетью задачи: алгоритм начинает успешно справляться с задачей «упрощенного» машинного перевода гораздо быстрее, чем при обучении на всех данных, и переходит к более сложной полной задаче, уже находясь в осмысленном промежуточном состоянии.
Второй компонент расписания, динамическая фильтрация, позволяет поэтапно сужать множество используемых данных — в начале обучения незначительный шум и отклонения от правильного перевода не являются критичными, тогда как на финальных стадиях это влечет появление аналогичных ошибок у модели. Так, известный метод борьбы с шумными данными — дообучение на чистом корпусе небольшого объема [3]. Эмпирически показано, что при дообучении модели даже на очень маленькой выборке данных лучшего качества (порядка нескольких тысяч) качество модели существенно растет. Предложенная схема динамической фильтрации обобщает этот подход: вместо двух фаз обучение можно представить как повторяющееся дообучение модели на постепенно улучшающихся данных.
В качестве метрики зашумленности данных мы используем величину, напрямую полученную из оценок данных уже обученной моделью перевода. Мы предполагаем, что обученная на небольшом наборе чистых данных вспомогательная прокси-модель, возможно, невысокого качества, способна семантически ранжировать обучающие данные. Существенное преимущество такого подхода состоит в отсутствие необходимости ручного подбора эвристик. Этот процесс трудоемок, так как «качество» с точки зрения человека может слабо коррелировать с релевантностью данных для модели. Предложенный метод, напротив, достаточно робастен — качество примера оценивается напрямую с помощью модели и не подвержено explicit bias (смещению) эвристических критериев.
Noise metric
В качестве меры зашумленности данных мы предлагаем использовать Dual Conditional Crossentropy. Более подробно, для пары предложений (х,у) вычисляется величина:
DCCF = |.Hfwd(yk) - Hbwd(x[y)l + |(Hfwd(y|x) + Hbwd(x\y)), где fwd и bwd — прямая и обратная обученные модели перевода соответственно.
Эта величина показывает, с одной стороны, насколько вероятна данная пара с точки зрения обученных моделей перевода в прямом и обратном направлениях (для неправильных и нестандартных переводов величины H будут высоки). С другой стороны, DCCF содержит штраф за несогласованность прямой и обратной моделей — логично предположить, что качественные переводы имеют примерно одинаковую вероятность в двух направлениях.
Было показано, что скоринг DCCF эффективен для статической фильтрации данных. В данной работе эта величина используется как мера зашумленности примера.
Опишем процедуру curriculum learning более подробно.
Расписание обучения определяет множество используемых на разных стадиях данных. Мы используем схему с постепенным переходом к самым релевантным для задачи данным на поздних стадиях обучения. На старте обучения в течение некоторго числа шагов — annealing rate («период разогрева») множество сэмплируемых данных изменяется от начального значения до конечного и затем фиксируется до сходимости.
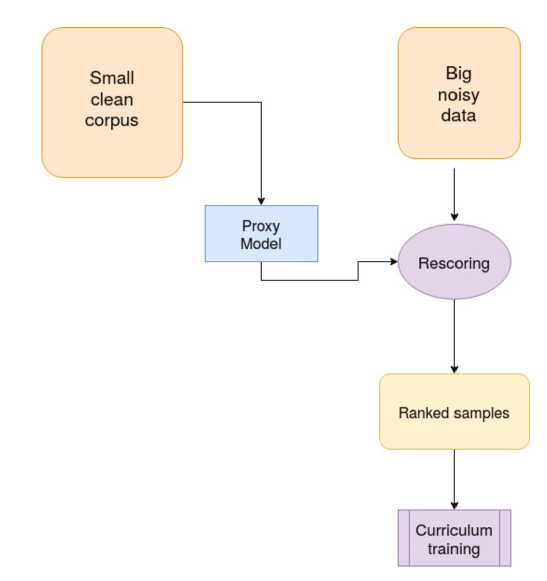
Рис. 1. Динамическая фильтрация данных. Схема процедуры
Другими словами, в течение периода разогрева происходит переход к конечной задаче через набор вспомогательных, цель которых сгладить неблагоприятные эффекты в данных, ухудшающие сходимость, такие как шум и чрезмерная сложность примеров для слабой модели на старте.
Мы исследуем два критерия релеватности примеров: критерий шума {denoising) и сложности {difficulty).
В случае denoising curriculum изначально на вход нейросети сэмплируются почти все данные, включая шумные примеры (значения метрики шума от 0 до nstart). Затем верхняя граница линейно убывает до пеп^ в течение некоторого числа шагов к — период «разогрева». На старте модели, не имеющей никаких знаний о переводе, для запоминания простейших закономерностей достаточно шумных примеров. При этом на финальных стадиях использование чистых данных как раз критично — нужно исправлять ошибки модели, и для этого требуются данные высокого качества, не содержащие подобных ошибок (такие как non-fluent переводы или артефакты выравнивания по предложениям — overtranslation и undertranslation).
4. Эксперименты4.1. Данные
Во всех экспериментах были использованы следующие обучающие данные:
1) Paracrawl. В качестве шумного набора автоматически собранных данных используется датасет paracrawl-vl [2]. Исходный корпус содержит 4.5 миллиарда пар предложений, для обучения моделей из корпуса удалены дубликаты, пары с пустыми предложениями, также применен фильтр по языку LangID [4].
2) WMT. Для обучения вспомогательных моделей был использован достаточно качественный корпус новостей WMT [5]. Использовались все доступные корпуса 2019 года для англо-немецкой пары. Была применена предварительная фильтрация, из данных были удалены предложения с соотношением длин более 1.5, также удалены дубликаты. Итоговый размер чистого корпуса — 4.9 миллионов пар предложений.
4.2. Модель
4.3. Denoising curriculum
В качестве тестовых наборов были использованы тестовые наборы WMT с 2015 по 2017 гг. (с разбиением каждого тестсета на два по языку оригинального текста).
К данным была применена ВРЕ-токенизация [6], с размером словарей 32.000 токенов (отдельные словари для немецкого и английского языков).
В экспериментах с динамической фильтрацией мы используем архитектуру transformerbase [2] с б слоями в энкодере и декодере. Во всех экспериментах используются одинаковые гиперпараметры: размерность слоя эмбеддингов 512, полносвязного слоя 2048. В полносвязных слоях был применен dropout [8] с р = 0.3, использован механизм внимания с 8 головами, в качестве оптимизатора используется Adam [9]. При обучении всех моделей применен механизм label smoothing с равномерным априорным распределением над мно-жестом токенов из словаря [7] с е = 0.1. Размер батча составляет 32 тысячи токенов. При декодинге используется beam search ширины 4 и нормализация по длине [10] с коэффициентом 0.6.
Для исследовния полезности denoising расписания использована следующая обучающая конфигурация: в качестве шумных данных был взят корпус Paracrawl — после предварительной фильтрации его размер составил 80 миллионов пар предложений. Далее корпус был поскорей двумя моделями en-de и de-en, обученными на чистых данных WMT до сходимости. Параметры вспомогательных моделей совпадают с параметрами основной модели.
Из результатов экспериментов можно сделать вывод, что метод эффективен: динамическая фильтрация превосходит по качеству обе статические фильтрации. Разница довольно существенна и составляет 2-3 BLEU. Динамическая модель за счет плавного перехода от более шумных данных к более чистым сглаживает проблемы статического фильтра со слишком жестким и слишом мягким порогами.
Таблица!
Результаты эксперимента по динамической фильтрации {denoising curriculum)
|
Модель |
wmtl7-fwd (BLEU) |
wmtl6-fwd (BLEU) |
|
Paracrawl + langid (80М) |
25.20 |
32.61 |
|
Static DCCF 40M |
27.76 |
35.32 |
|
Static DCCF 5M |
26.73 |
34.80 |
|
Dynamic DCCF 40Мч5М, 400k |
29.91 |
38.12 |
|
Proxy Model (WMT) |
27.80 |
35.18 |
Также проведено сравнение с прокси-моделью, использовавшейся для скоринга. Лучший результат по сравнению с ней говорит о приросте качества именно за счет адаптивной фильтрации, а не дистилляции от прокси-модели (что могло происходить вследствие неявного использования ее оценок вероятности на обучающем датасете).
4.4. Precision-Recall Tradeoff
Далее было проведено более детальное исследование зависимости качества модели перевода от порога фильтрации.
Для лучшего понимания precision-recall tradeoff было обучено несколько моделей с разными порогами статической фильтрации по Dual Crossentropy Score: 5М, ЮМ, 20М, ЗОМ и 40М. Мы предполагаем, что обучение довольно чувствительно к оптимальному подбору порога (слишком мягкая фильтрация содержит много шума, слишком жесткая содержит мало данных) и результирующее качество может быть существенно ниже оптимального. Также интересно сравнить динамическую фильтрацию с оптимальной статической.
Результаты экспериментов подтверждают нашу гипотезу. Оптимальный порог статической фильтрации — 20М, он существенно лучше как слишком строгой фильтрации, так и слишком мягкой. При этом динамическое расписание превосходит и его — на wmtl7 наблюдается прирост в 0.52 BLEU, на wmt!6 — в 0.44 BLEU.
Т а б л и ц а 2
Сравнение статических порогов фильтрации с динамическим расписанием (precision-recall tradeoff)
|
Модель |
wmtl7-fwd (BLEU) |
wmtl6-fwd (BLEU) |
|
Static DCCF 5М |
26.73 |
34.80 |
|
Static DCCF ЮМ |
28.83 |
37.20 |
|
Static DCCF 20М |
29.39 |
37.68 |
|
Static DCCF 30M |
29.16 |
37.51 |
|
Static DCCF 40M |
27.76 |
35.32 |
|
Dynamic DCCF I0M+M |
29.91 (+0.52) |
38.12 (+0.44) |
Важно отметить, что в данном блоке экспериментов параметры динамического фильтра отдельно не подбирались — значения 40М и 5М были выбраны как пороги фильтрации с заведомо высокой полнотой и высокой точностью соответственно. Можно сказать, что предложенный подход более эффективен, чем статический фильтр: он превосходит по качеству фильтр с оптимальным порогом, при этом подобрать подходящие для него гиперпараметры достаточно просто.
4.5. Difficulty curriculum
Задача данного эксперимента состояла в получении конфигурации обучения на датасете из смеси двух корпусов: корпуса предложений и корпуса документов.
В качестве базовой модели использовалась версия большой языковой модели YandexGPT, прошедшая базовое дообучение под задачу перевода: после базовой стадии предобучения YandexGPT (pretrain) модель прошла дополнительную адаптацию в двух стадиях — postpretrain на смеси general-purpose данных и данных перевода и SFT на корпусе параллельных документов.
Дальнейший этап пайплайна — alignment — представляет собой обучение на тройках размеченных данных вида (исходный текст, перевод_1, перевод_2), где два варианта перевода прошли сравнение по некоторой автоматической метрике, либо разметке людей. Таким образом, датасет алайнмента содержит сравнительный сигнал между двумя вариантами перевода, тем самым задача обучения сводится к получению консистентности между ранжированием модели и ground-truth ранжированием из датасета.
Технически алгоритм обучения на этапе alignment — СРО ( Contrastive Preference Optimization):
Aotal = ACP О + A£sF T, (1)
где SFT loss определяется как стандартная кросс-энтропия на предпочтительных ответах:
Ar т = -Е+,г/ш)-© [logте (yw |ж)] . (2)
СРО включает в себя две компоненты: оптимизацию контрастной функции потерь (лог-сигмоида) и потокенной supervised функции потерь (категориальная кросс-энтропия). Первая часть отвечает за консистентность ранжирования с обучающим датасетом, а вторая — за качество непосредственно генерации.
Сложность данной конфигурации обучения состоит в высокой степени несбалансированности датасетов: количество предложений на порядок превышает количество документов. Как следствие, обучение на равномерной смеси предложений и документов не отличается по метрикам сходимости от обучения только на предложениях.
Предлагаемый вариант обучения согласно difficulty curriculum состоит из двух обособленных стадий: (1) обучение на корпусе предложений с равномерным сэмплированием толь- ко предложений, (2) обучение на корпусе документов с равномерным сэмплированием только документов.
Сложность примера
Данные документов (высокое качество, информативность, небольшой объем)
Данные предложений (большой объем, низкая сложность, низкое качество)
Шаг обучения
Рис. 2. Curriculum learning для адаптации к задаче документного перевода
Т а б л и ц а 3
Сравнение моделей на тестовом наборе wmt22 по автоматическим метрикам
Model
BLEURT COMET
SET (PTune)
0.728
0.733
0.743
0.835
0.847
0.850
CPO-only-sents
CPO-curriculum
Результаты эксперимента представлены в таблице выше. Можем наблюдать рост качества перевода на сегменте новостей из датасета wmt22 по нейросетевым автоматическим метрикам: BLEURT и COMET. Рост достигнут как сравнительно базового чекпоинта после SFT обучения, с которого начинается обучение на этапе alignment, так и относительно обучения alignment только на корпусе предложений.
5. Результаты исследования
В текущем исследовании был предложен алгоритм динамического подбора обучающих данных для моделей машинного перевода по схеме curriculum learning для (1) обучения на зашумленных данных, (2) адаптации модели под перевод длинных документов.
Была реализована схема расписания обучения с ранжированием примеров по возрастанию сложности и убыванию зашумленности.
Предложенный метод основан на оценке примеров с помощью предобученной вспомогательной модели перевода и обладает рядом преимуществ:
-
1) Эффективность. Благодаря тому, что скоринг обучающей выборки происходит только один раз, перед стартом обучения, предложенный подход практически не замедляет обучение.
-
2) Робастность. Метод основан на скоринге обученной моделью перевода (difficulty) и длине текста (complexity). Это не требует подбора гиперпараметров и эвристик для составления расписания. Эмпирически было показано, что метрики правдоподобия примера с точки зрения моделей перевода и длина текста содержат достаточно информации для семантического ранжирования данных.
-
3) Простота. Предложенная схема ранжирования данных и составления расписания оченв проста в применении. В такой реализации curriculum learning не требуется вносить изменения непосредственно в модель перевода, вся логика может быть реализована в модуле чтения данных. Данный вид динамического расписания не специфичен для модели Transformer и может быть применен для произвольной архитектуры и любой итеративной процедуры оптимизации.
В проведенных экспериментах была показана эффективность curriculum learning относительно статической фильтрации и отсутствия фильтрации при обучении на зашумленной выборке данных из Paracrawl, а при обучении на несбалансированной выборке предложений и документов было получено улучшение относительно обучения только на предложениях.
Полученные в данном исследовании эмпирические результаты показывают практическую применимость технологии обучения с расписанием к разнообразным сценариям обучения моделей машинного перевода.
