Обзор возможностей Compumine rule discovery system

Автор: Пальмов Сергей Вадимович
Журнал: Инфокоммуникационные технологии @ikt-psuti
Рубрика: Новые информационные технологии
Статья в выпуске: 1 т.9, 2011 года.
Бесплатный доступ
В статье приводится обзор возможностей программного продукта Compumine Rule Discovery System, который при помощи алгоритмов технологии Data Mining позволяет анализировать данные и находить в них скрытые закономерности. Получаемые результаты обладают высокой степенью достоверности. Данная аналитическая система может быть использована в самых различных областях человеческой деятельности.
Интеллектуальный анализ данных, деревья решений, ассоциативные правила, прогнозирование
Короткий адрес: https://sciup.org/140191455
IDR: 140191455 | УДК: 004.89
Overview of Compumine rule discovery system
This article provides an overview of the Compumine Rule Discovery System, which, with the help of Data Mining algorithms, allows you to analyze data and find hidden patterns in it. The obtained results have a high degree of confidence. This analytical system can be used in various fields of human activity.
Текст научной статьи Обзор возможностей Compumine rule discovery system
«Стремясь к повышению эффективности и прибыльности бизнеса, при создании баз данных (БД) все стали пользоваться средствами обработки цифровой информации, появился и побочный продукт этой активности – горы собранных данных. И вот все больше распространяется идея о том, что эти горы полны золота» [1]. В настоящее время для добычи этого «золота» широко используется технология, которая называется data mining (в дословном переводе – «добыча данных»), или интеллектуальный анализ данных: процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности [2].
На практике для выявления скрытых закономерностей используются различные алгоритмы data mining: ассоциативные правила, деревья решений, нейронные сети, генетические алгоритмы и т.д. Созданы десятки платных и бесплатных аналитических пакетов, реализующих вышеуказанные алгоритмы [3].
Одной из таких программ является Rule Discovery System (RDS), разработанная шведской компанией Compumine (https://www.compumine. com). Этот программный продукт в нашей стране практически неизвестен (публикаций на русском языке найти не удалось), так что данная статья будет полезна для всех, кто интересуется практическим использованием методов технологии data mining.
Рассмотрим, как осуществляется работа с RDS. На первом этапе происходят импорт и настройка обучающего набора данных, а также по- строение моделей, которые в дальнейшем будут использованы для поиска скрытых закономерностей. Чтобы импортировать обучающий набор данных, необходимо выбрать из меню «File» пункт «Import» и в появившемся диалоговом окне указать нужный файл в формате .txt. Затем в открывшейся таблице задать способ разделения колонок (пробел, точка, табуляция и т.д.), способ пометки пропущенных значений, изменить кодировку символов и удалить пустые столбцы. После этого в навигаторе экспериментов появится ссылка «Modeling data set» (см. рис. 1), нажав на которую, можно изменить тип данных и задать целевую переменную.
В нашем случае используется тренировочная база данных, которая идет в комплекте с RDS и содержит информацию о различных грибах.
Рис. 1. Настройка программы (генерация прогностических моделей)
RDS работает со следующими основными типами данных: категориальный, числовой, идентификатор (аналог первичного ключа в базе данных; может быть только один столбец такого типа), класс (указывает на то, что это переменная категориального типа и она является целевой; может быть только один столбец такого типа), регрессионный (указывает на то, что это переменная числового типа и она является целевой; может быть только один столбец такого типа) и некоторые другие [4].
В данном случае целевая переменная – «class»: съедобный (edible) или нет (poisonous). Исходные данные можно импортировать из со- храненного файла предыдущего эксперимента (аналогично работе с текстовым файлом). Если в дальнейшем будет необходимо точно воссоздать эксперимент, то для этого нужно настроить генераторы случайных чисел (задать определенные значения для каждого из трех генераторов). Опция доступна через ссылку «Advanced settings» в «Навигаторе экспериментов» (см. рис. 1).
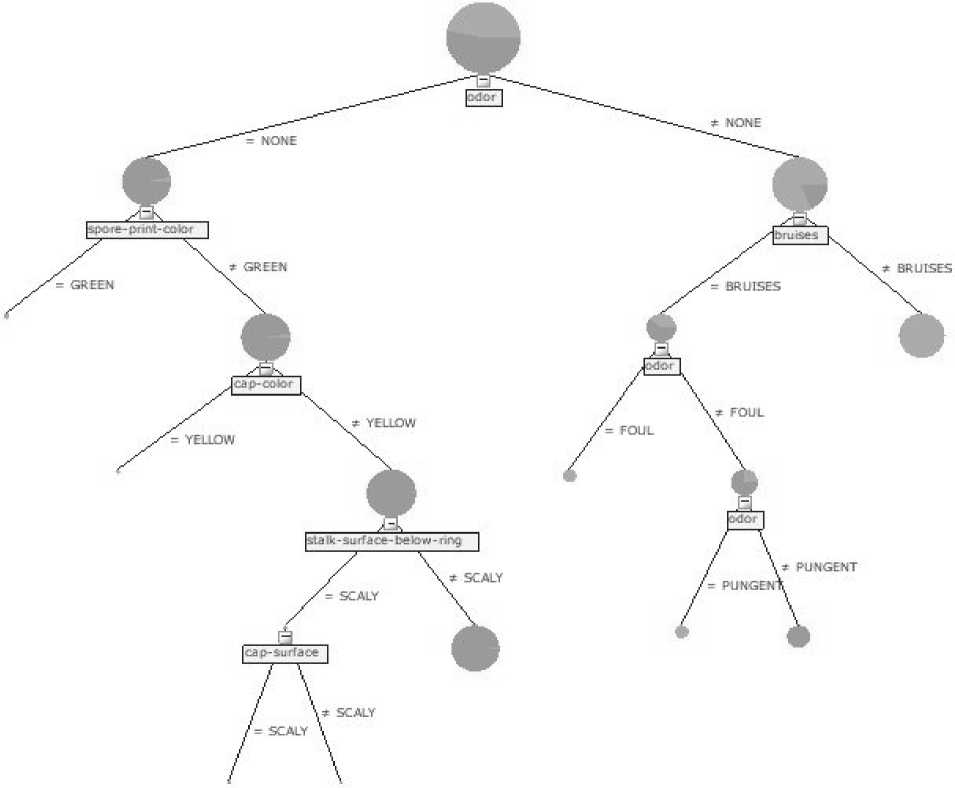
Рис. 2. Дерево решений
Затем требуется выбрать валидационный (проверочный) метод. В RDS доступны следующие методы: разделенная выборка (split sample) (необходимо указать, какая часть набора данных будет использована для проверки), внешнее тестовое множество (external test set) (необходимо импортировать файл), N-проходная перекрестная проверка (N-fold cross-validation) (необходимо задать количество проходов), перекрестная проверка с исключениями (leave-X-out cross-validation) (разновидность перекрестной проверки) и групповая перекрестная проверка (group-wise cross-validation) (необходимо задать количество групп) [4].
На следующем этапе происходит добавление моделирующих методов. Это осуществляется при помощи кнопки «Добавить метод» («Add method») (см. рис. 1). В RDS есть три моделирующих метода: ассоциативные правила, деревья решений и ансамбли (ensemble) моделей.
При использовании первого метода модель представляет собой набор независимых правил в формате «если ... то …». Второй метод формирует иерархические структуры, организованные в виде дерева, которые эффективно решают задачи классификации. Ансамбли моделей – это группы моделей первых двух типов, используемые в тех случаях, когда необходима высокая точность прогнозирования. Существует два подвида вышеуказанных моделирующих методов: с настройками «по умолчанию» и настраиваемые пользователем (custom). Если выбрать второй подвид, то для настройки будут доступны следующие параметры:
-
- минимальная поддержка правил;
-
- размер тренировочной выборки;
-
- веса классов зависимой переменной;
-
- количество моделей в ансамбле;
-
- использовать (или нет) бэггинг (bagging – метод формирования ансамблей классификаторов с использованием случайной выборки с возвратом);
-
- использовать (или нет) случайный выбор переменных (увеличивает скорость построения моделей).
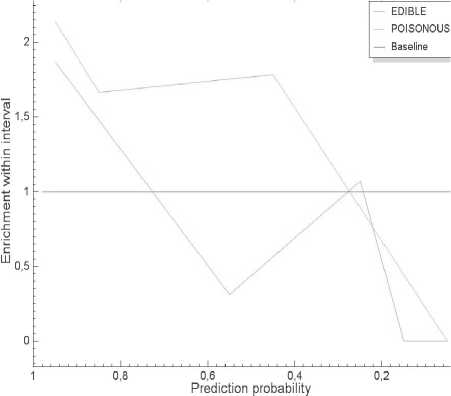
Рис. 3. Lift-график и ROC-кривая (для дерева решений)
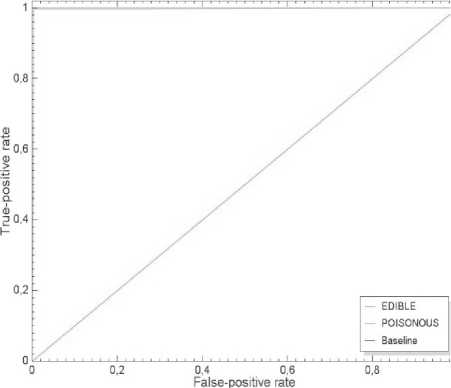
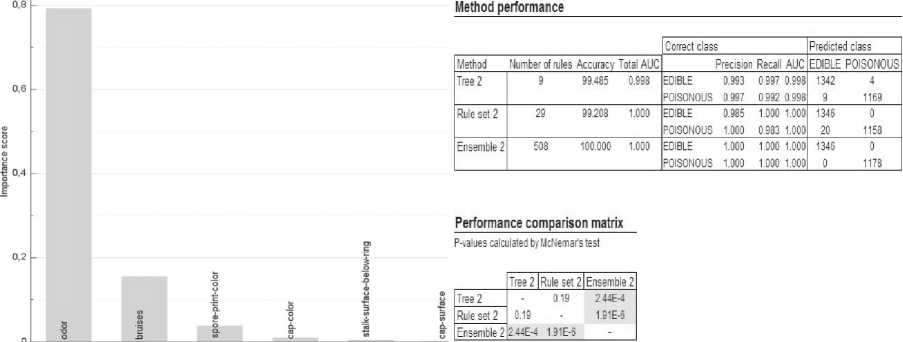
Рис. 4. Значимость переменных (для дерева решений) и общая статистика по моделям (деревья решений, ассоциативные правила и ансамбль моделей)
Последние два параметра доступны при использовании ансамблей моделей. Модели, построенные в результате эксперимента, можно сохранить, поставив соответствующую пометку («Store resulting models»). Когда все вышеуказанные действия выполнены, можно запускать эксперимент («Start»).
В итоге работы программы будут выведены следующие результаты.
-
1. Статистика модели (Model statistic).
-
2. Значимость переменных (Variable Importance).
-
3. Модели (Models) (только для деревьев решений и ассоциативных правил, см. рис. 2).
-
4. Лифт-графики (Lift charts).
-
5. ROC-кривые (ROC-curves; ROC – Receiver Operator Characteristic, см. рис. 3) показывают зависимость количества верно классифицированных положительных примеров от количества неверно классифицированных отрицательных примеров [5].
-
6. Общая статистика по моделям (Statistics). Содержит статистическую информацию об эффективности работы всех методов и их сравнительную характеристику (см. рис. 4).
-
7. Прогнозы (Predictions). Спрогнозированные значения целевой переменной для всех методов.
Содержит измерения показателей эффективности для каждой модели.
Относительная мера того, насколько сильно каждая из переменных, используемых в модели, влияет на уменьшение ошибки прогнозирования (см. рис. 4).
Отображают обогащение (enrichment) примеров определенного класса относительно ожидаемой вероятности прогноза. Обогащение (или достоверность) определенного класса есть отношение частоты появления условия в примерах, которые также содержат и следствие, к частоте появления условия в целом (см. рис. 3).
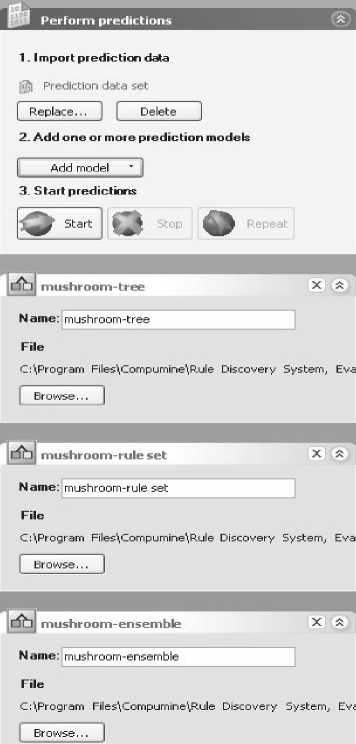
Рис. 5. Настройка программы (прогнозирование)
После завершения формирования моделей можно приступать к прогнозированию на основе новых данных. Для этого необходимо импортировать текстовый файл с информацией (как делалось выше), загрузить нужные прогностические модели и запустить программу на выполнение (см. рис. 5). В итоге для каждого из методов будут получены следующие результаты: статистика модели, значимость переменных, модели (только для деревьев решений и ассоциативных правил). Также формируется общая статистика по моделям.
Таким образом, данный аналитический пакет позволяет на основе алгоритмов технологии data mining формировать в зависимости от конкретных требований прогностические модели различной степени сложности. Затем они (все или частично) применяются для выявления скрытых закономерностей в новых массивах данных. RDS можно использовать в самых разных предметных областях, в том числе и телекоммуникациях, чтобы получать прогнозы, обладающие высокой достоверностью.
Список литературы Обзор возможностей Compumine rule discovery system
- 112/MId__500/ModeID__0/PageID__516DesktopDefault.aspx.
- -php?title' TARGET='_new'>http://www.machinelearning.ru/wiki/index.->-php?title
- http://www.the-data-mine.com/bin/view/> Software/DataMiningSoftware
- Rule Discovery System 2.6 Modeling Edition. User Guide. -P. 28-30, 31-34.
- http://www.basegroup.ru/library/analysis/> regression/logistic/
