Offline Handwritten Gurmukhi Numeral Recognition using Wavelet Transforms

Author: Pritpal Singh, Sumit Budhiraja
Journal: International Journal of Modern Education and Computer Science (IJMECS) @ijmecs
Article in issue: 8 vol.4, 2012.
Free access
This paper presents an OCR (optical character recognition) system for the handwritten Gurmukhi numerals. A lot of work has been done in recognition of characters and numerals of various languages like English, Chinese, and Arabic etc. But in case of handwritten Gurmukhi script very less work has been reported. Different Wavelet transforms are used in this work for feature extraction. Also zonal densities of different zones of an image have been used in the feature set. In this work, 100 samples of each numeral character have been used. The back propagation neural network has been used for classification. An average recognition accuracy of 88.83% has been achieved.
Optical Character Recognition, Handwritten Gurmukhi Script, Wavelet Transforms, Feature Extraction, Zonal Densities
Short address: https://sciup.org/15014476
IDR: 15014476
Text of the scientific article Offline Handwritten Gurmukhi Numeral Recognition using Wavelet Transforms
Published Online August 2012 in MECS DOI: 10.5815/ijmecs.2012.08.05
Handwritten character recognition is a hot research area in pattern recognition. Character recognition is a process of converting an image of a handwritten or printed text in to a computer editable format.
Handwritten character recognition is of two types:
-
1. Online handwritten character recognition
-
2. Offline handwritten character recognition
In online handwritten character recognition the character is recognized as soon as it has been written. On the other hand, in offline handwritten character recognition the character has been written first, and recognition has been performed later on. In this paper the offline character recognition has been performed for the Gurmukhi numerals. The recognition of handwritten characters is very difficult. There are many external and internal problems which are present in an OCR system for handwritten characters. The external problems are related to the variation in the shapes of characters and writing styles of different writers. There is a possibility of wrong recognition due to similarity between different characters. The internal problems in an OCR system are related to the distortion in the character images during scanning of images, addition of noise during image acquisition and degraded and broken characters images.
These problems lead to reduction in the accuracy of the offline handwritten character recognition. Same problems are there in case of handwritten Gurmukhi numerals. The ten Gurmukhi numerals are shown in Fig. 1.
|
Decimal no. |
Corresponding Gurmukhi numeral |
Decimal no. |
Corresponding Gurmukhi numeral |
|
0 |
0 |
5 |
4 |
|
1 |
1 |
6 |
£ |
|
2 |
9 |
7 |
9 |
|
3 |
3 |
8 |
t |
|
4 |
X |
9 |
t |
Figure 1. Gurmukhi Numerals
The handwritten recognition of Gurmukhi numerals finds application in the field of automatic sorting of letters in postal services based on the postal codes, in automatic processing of various handwritten forms in various government departments and institutes, in digitization of old manuscripts etc.
The organization of this paper is: Section II has discussed the previous work, section III has illustrated proposed recognition system, and section IV has discussed the experimental results and conclusion has been drawn in section V.
-
II. PREVIOUS RELATED WORK
Many researchers have proposed several techniques for handwritten as well as printed character and numeral recognition. Vikas J Dongre et al. [1] has given a review of various techniques used for feature extraction and classification of Devnagari character recognition. The various feature extraction techniques like Fourier transforms, wavelets, zoning, projections etc has been discussed in [1] O. D. Trier et al. [2] has also discussed the various feature extraction techniques. Raju G. [3] has proposed an OCR system for Malayalam characters. The proposed feature extraction method has used different wavelet filters and MLP network has been used as classifier. An average recognition rate of 81.3% has been achieved. M Abdul Rahiman et al. [4] has also proposed a Malayalam OCR system. The proposed system has used Daubechies wavelet (db4) for feature extraction and neural networks for recognition. The system has been given an accuracy of 92%. Piu Upadhyay et al. [5] has been proposed bangla OCR system. Images have been scaled to a pre defined area. Characteristic points have been extracted to get feature vector. An artificial neural network has been used for classification purpose. The recognition accuracy of 98% has been achieved. For Gurmukhi OCR system following methods has been proposed:
G S Lehal et al. [6] has given an OCR system for printed Gurmukhi script. The feature extraction has been done using the structural features and binary classifier trees and nearest neighbour classifier has been used. It has been found that an accuracy of 96.6% has been obtained.
Puneet Jhajj et al.[7] has first resized the original image to 48*48 pixels normalized image and created 64 (8*8) zones to find zonal densities. These zonal densities have been taken as features. The SVM and K-NN classifiers have been used for classification process. It has been found that 72.83% was the highest accuracy with SVM (Support Vector Machine) with RBF kernel. Ubeeka Jain et al. [8] has been created horizontal and vertical profiles for each chracter, stored height and width of each character and used neocognitron artificial neural network for feature extraction and classification. The accuracy of 92.78% has been achieved. Kartar Singh Siddharth et al. [9] have been used statistical features e.g. zonal density, projection histograms (horizontal, vertical and both diagonal), distance profiles (from left, right, top and bottom sides) for feature extraction. In addition to these features background directional distribution (BDD) features have also been used. The images have been normalized to 32*32 sizes. For classification process SVM, K-NN and PNN classifiers have been used. The highest accuracy of 95.04% has been obtained as 5-fold cross validation of whole database using zonal density and background distribution features in combination with SVM classifier used with RBF kernel. Pritpal Singh et al. [10] have been proposed OCR system for Gurmukhi script in which the feature extraction has been done using Daubechies Wavelet Transforms. The back propagation neural network has been used for classification. Kartar Singh Siddharth et al. [11] have proposed an OCR for handwritten Gurmukhi numerals. For feature extraction distance Profiles and Background Directional Distribution (BDD) has been used .The SVM classifier with RBF (Radial Basis Function) kernel has been used for classification. It has been found that the maximum recognition accuracy was 99.2%. In [12] another approach has been discussed for the handwritten Gurmukhi character recognition. In this approach Gabor filters has been used for feature extraction and SVM classifier with RBF kernel has been used. The recognition accuracy of 92.29% has been obtained.
-
III. THE PROPOSED RECOGNITION SYSTEM FOR GURMUKHI NUMERALS
Handwritten OCR system for Gurmukhi numerals consists of several stages. The stages for recognition process of handwritten Gurmukhi numerals are given below:
-
1. Image acquisition
-
2. Pre-processing
-
3. Feature extraction using different wavelet transforms
-
4. Classification using BP neural network
-
5. Recognised character
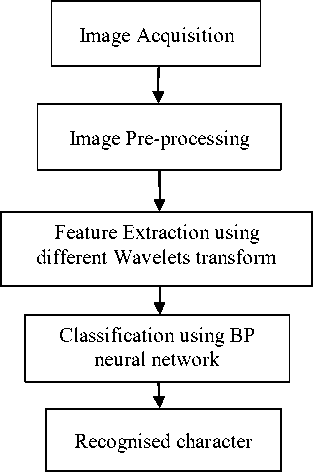
Figure 2. Block Diagram of Handwritten Gurmukhi Numeral Recognition System
The block diagram of handwritten Gurmukhi numerals recognition system has been shown in Fig. 2. The brief explanation for each stage has been given below:
Image Acquisition: In image acquisition raw image of the character has been obtained by using a scanner which has been fed to the next stage for further operations.
Pre-processing: Raw image may carry some unwanted noise. The preprocessing stage has been used to remove the unwanted noise and distortion of the image. The unwanted extra white space has been clipped off. After preprocessing of the raw image, this pre processed image fed to feature extraction stage.
Feature Extraction: The next stage has been used for feature extraction. In feature extraction stage every character is used to create a set of numeral values called feature vector. This vector is used to uniquely identify the character. Various feature extraction methods are zoning, structural features, and Directional Distance Distribution etc.
Classification: Classification stage has been used for decision making to identify the character. It has used the feature vectors extracted in the feature extraction stage to identify the characters. Various types of classifiers are K-nearest neighbour, Back propagation neural network, Support Vector Machine etc.
Recognised character is the final output of an OCR system. After the brief introduction to various stages of an OCR system, the proposed OCR system for the handwritten Gurmukhi numerals has been explained below:
-
A. Image Acquisition
The handwritten Gurmukhi numerals samples are taken from different writers. There are total 1000 samples which have been used in the proposed recognition system. Out of these, 750 samples have been used for training of neural network and 250 samples have been used for testing. These samples are taken by scanning the handwritten Gurmukhi numeral characters at 400 dpi. Some samples of Gurmukhi numerals have been shown below in Fig. 3.
|
Gurmukhi numeral |
Samples of Gurmukhi numerals |
||||
|
੦ |
о |
CD |
о |
о |
|
|
੧ |
2 |
2 |
2 |
||
|
੨ |
2. |
||||
|
੩ |
? |
||||
|
੪ |
У |
У |
|||
|
੫ |
ч |
И |
ч |
||
|
੬ |
£ |
£ |
|||
|
੭ |
7 |
9 |
|||
|
੮ |
^^ |
||||
|
੯ |
т |
||||
Figure 3 Samples of Gurmukhi Numerals
-
B. Pre-Processing
In the pre-processing stage the Recognition system has given a raw scanned colour image then following operations has been performed on it:
-
1. Conversion of colour image in to grey image.
-
2. Median filtering is performed to the image to remove noise.
-
3. The image then converted in to the binary image using thresholding.
-
4. The binary character image is normalized to 32*64.
-
C. Feature Extraction
Wavelets are localized basis functions which are translated and dilated versions of some fixed mother wavelet. The decomposition of the image into different frequency bands is obtained by successive low-pass and high-pass filtering of the signal and down-sampling the coefficients after each filtering. In this work we have used various discrete wavelet transforms e.g. Daubechies, symlet, coiflet, biorthogonal etc.
The feature extraction is done by using the following algorithm:
For each pre-processed image following steps have been repeated:
-
a. Number of black pixels along each row of the binarized image has been counted to form a 32 sized vector.
-
b. The 1D wavelet transform on row count vector (two levels) has been applied.
-
c. Then the approximation (low frequency or average) coefficients have been directly taken as feature values.
-
d. Number of black pixels along each column has been counted to form a 64 sized vector.
-
e. The 1D wavelet transform on column count vector (three levels) has been applied.
-
f. Then the approximation coefficients have been directly taken as next feature values.
-
g. Divide each 32*64 image in to 16 zones of size 8*16.
-
h. Then find the mean zonal densities of these 16 zones.
-
i. Take these as the next 16 values of feature vector.
-
j. Take aspect ratio as the last feature element of the feature vector.
Above explained steps are repeated with different wavelet filters viz. db1, db2, db6, sym2, sym4, sym6, coif1, coif3, coif5, bior1.3, bior2.4 and bior3.9. After the feature extraction has been done, the feature vectors lengths are summarized in the Table I:
TABLE I . LENGTH OF FEATURE VECTORS
|
Wavelet filter |
Length of feature vector |
|
Db1 |
33 |
|
Db2 |
37 |
|
Db6 |
50 |
|
Sym2 |
37 |
|
Sym4 |
44 |
|
Sym6 |
50 |
|
Coif1 |
40 |
|
Coif3 |
42 |
|
Coif5 |
79 |
|
Bior1.3 |
40 |
|
Bior2.4 |
46 |
|
Bior3.9 |
46 |
D. Classification
The back propagation neural network has been used for classification of the Gurmukhi numerals. Back Propagation Neural Network (BPNN), is a Multilayer Neural Network which is based upon back propagation algorithm for training. This neural network is based upon extended gradient-descent based Delta learning rule, commonly known as Back Propagation rule . T he basic architecture of a back propagation neural network has been shown in Fig. 4.
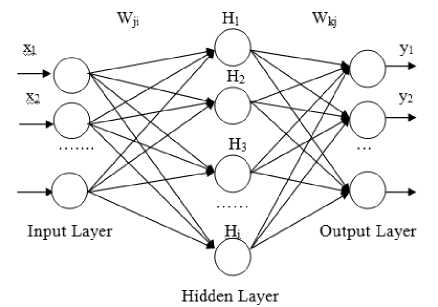
Figure 4. Back Propagation Neural Network Architecture
In this network, error signal between desired output and actual output is being propagated in backward direction from output to hidden layer and then to input layer in order to train the network. In this network input nodes equal to number of feature vector elements, one hidden layer with 30 nodes and 10 output nodes are used. The testing input is fed into the input layer, and the feed forward network will generate results based on its knowledge from trained network.
-
IV. EXPERIMENTAL RESULTS
90.4 88,4 89.2 89.3
In this work, various Discrete Wavelet Transforms e.g. db1, db2, db6, sym2, sym4, sym6, coif1, coif3, coif5, bior1.3, bior2.4 and bior3.9 have been used to extract the wavelet coefficients. Then a feature vector has been obtained by combining the wavelet coefficients, zonal densities and aspect ratio which is given as input to the BPN network. The outcomes have been summarized in Table II. The values of average recognition accuracy using different Daubechies wavelets are 89.3% and average recognition time is 2.3 seconds and shown in Fig. 5. Similarly the values of average recognition accuracy using different symlet, coiflet and biorthogonal wavelets are 88.8%, 88.9% and 88.3% respectively. The values of average time using different symlet, coiflet and biorthogonal wavelets are 2.2 seconds, 2.2 seconds and 2.0 seconds respectively. These values are compared in Fig. 6, 7, 8 respectively.
TABLE II . COMPARISION OF RECOGNITION ACCURACY USING DIFFERRENT WAVELETS
|
S.no. |
Wavelet filter |
%Recognition accuracy |
Recognition Time (in sec.) |
|
1 |
db1 |
90.4 |
2.480695 |
|
2 |
db2 |
88.4 |
2.202486 |
|
3 |
db6 |
89.2 |
2.155824 |
|
4 |
sym2 |
89.6 |
2.087943 |
|
5 |
sym4 |
88.8 |
2.314143 |
|
6 |
sym6 |
88.0 |
2.233715 |
|
7 |
coif1 |
90.4 |
2.130107 |
|
8 |
coif3 |
88.8 |
2.255693 |
|
9 |
coif5 |
87.6 |
2.293411 |
|
10 |
bior1.3 |
88.0 |
2.103718 |
|
11 |
bior2.4 |
88.4 |
2.063909 |
|
12 |
bior3.9 |
88.4 |
1.879375 |
|
average |
88.8 |
2.183418 |
■ recognition accuracy(%) ■ recognition time(in seconds)
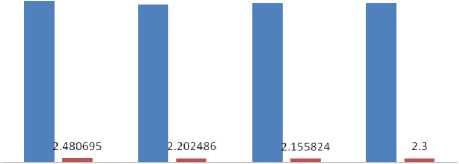
dbl db2 db6 average value
Figure 5. Recognition Accuracy and Recognition Time using Different Daubechies Wavelets
■ recognition accuracy(%) ■ recognition time(in seconds)
89.6 88.8 88 88.8
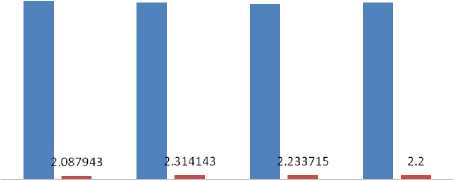
sym2 sym4 sym6 average value
Figure 6. Recognition Accuracy and Recognition Time using Different Symlet Wavelets
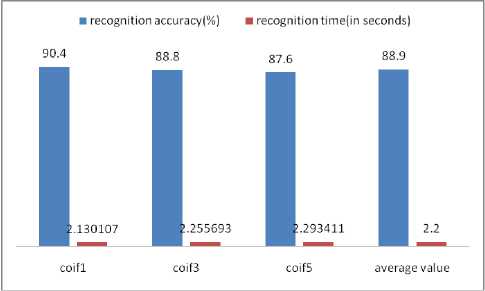
Figure 7. Recognition Accuracy and Recognition Time using Different coiflet Wavelets
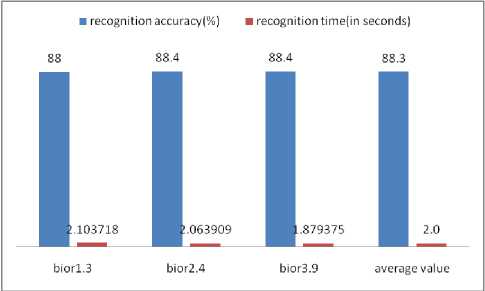
Figure 8. Recognition Accuracy and Recognition Time using Different Biorthogonal Wavelets
The highest average recognition accuracy is 89.3% using Daubechies wavelet transform and lowest recognition time is 2.0 seconds using biorthogonal wavelet transform. The overall average recognition time for these samples is 2.18 seconds and overall recognition accuracy is 88.8%.
-
V. CONCLUSION
In this handwritten Gurmukhi numeral recognition system the feature vector has lesser elements as compared to other OCR systems developed so far. The result obtained is comparable with similar works reported earlier. In this recognition system an average recognition rate of 88.8% has been obtained. It has been found that db1 and coif1 wavelets have given the highest recognition accuracy. The bior3.9 wavelet has the least recognition time. As the size and quality of database is major factor influencing HCR systems, so relatively large database can be used in the future work. This will help to enhance the recognition accuracy. By adding some more features can also be helpful to enhance the recognition accuracy. It has been observed in this work that certain numerals have confused with other numerals during recognition process. It has been found that for numeral ‘ ੧ ’ recognition accuracy is least. The confusion matrix for each Gurmukhi numeral is shown below:
TABLE III . CONFUSION MATRIX FOR GURMUKHI NUMERALS
|
Gurmukhi numeral |
Recognized as Gurmukhi numeral |
|||||||||
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
0 |
93% |
0% |
0% |
1% |
0% |
1% |
0% |
4% |
1% |
0% |
|
1 |
19% |
76% |
0% |
0% |
1% |
0% |
0% |
3% |
1% |
0% |
|
2 |
1% |
1% |
91% |
1% |
0% |
4% |
1% |
0% |
0% |
1% |
|
3 |
5% |
0% |
0% |
85% |
2% |
0% |
0% |
4% |
4% |
0% |
|
4 |
0% |
2% |
0% |
1% |
89% |
1% |
5% |
0% |
2% |
0% |
|
5 |
0% |
0% |
0% |
0% |
8% |
89% |
0% |
0% |
3% |
0% |
|
6 |
0% |
0% |
0% |
0% |
6% |
0% |
92% |
0% |
0% |
2% |
|
7 |
4% |
0% |
0% |
0% |
0% |
1% |
0% |
95% |
0% |
0% |
|
8 |
0% |
7% |
0% |
0% |
1% |
0% |
0% |
3% |
89% |
0% |
|
9 |
0% |
0% |
0% |
0% |
4% |
0% |
0% |
1% |
0% |
95% |
References Offline Handwritten Gurmukhi Numeral Recognition using Wavelet Transforms
- Vikas J Dungre et al., "A Review of Research on Devnagari Character Recognition", International Journal of Computer Applications, Vol. 12, No.2, November 2010.
- O. D. Trier, A. K. Jain and T. Text, "Feature Extraction Methods for Character Recognition- A Survey", Pattern Recognition, Vol. 29, No. 4, pp. 641-662, 1996.
- Raju G., "Wavelet Transform and Projection Profiles in Handwritten Character Recognition – A Performance Analysis", IEEE, pp. 309-314, 2008.
- M Abdul Rahiman, M S Rajasree, "OCR for Malayalam Script Using Neural Networks",IEEE, 2009.
- Piu Upadhyay, Sumana Barman, Debnath Bhattacharyya, Manish Dixit, "Enhanced Bangla Character Recognition using ANN", International conference on Communication Systems and Network Technologies, IEEE, pp. 194-197, 2011.
- G S Lehal and Chandan Singh, "A Gurmukhi Script Recognition System", Proceedings of the International Conference on Pattern Recognition (ICPR'00), 2000.
- Puneet Jhajj, D. Sharma, "Recognition of Isolated Handwritten Characters in Gurmukhi Script", International Journal of Computer Applications, Vol. 4, No. 8, 2010.
- Ubeeka Jain, D. Sharma, "Recognition of Isolated Handwritten Characters of Gurumukhi Script using Neocognitron", International Journal of Computer Applications, Vol. 10, No. 8, 2010.
- Kartar Singh Siddharth, Mahesh Jangid, Renu Dhir, Rajneesh Rani, "Handwritten Gurmukhi Character Recognition Using Statistical and Background Directional Distribution Features", International Journal on Computer Science and Engineering, Vol. 3 No. 6 June 2011.
- Pritpal Singh, Sumit Budhiraja, "OCR for Handwritten Gurmukhi Script using Daubechies Wavelet Transforms", International Journal of Computer Applications, Vol. 45, No.10, May 2012.
- Kartar Singh Siddharth, Renu Dhir, Rajneesh Rani," Handwritten Gurmukhi Numeral Recognition using Different Feature Sets", International Journal of Computer Applications, Volume 28, No.2, August 2011.
- Sukhpreet Singh, Ashutosh Aggarwal, Renu Dhir, "Use of Gabor Filters for Recognition of Handwritten Gurmukhi Character", International Journal of Advanced Research in Computer Science and Software Engineering, Vol. 2, Issue 5, May 2012.
