Ontology-Alignment Techniques: Survey and Analysis

Автор: Fatima Ardjani, Djelloul Bouchiha, Mimoun Malki
Журнал: International Journal of Modern Education and Computer Science (IJMECS) @ijmecs
Статья в выпуске: 11 vol.7, 2015 года.
Бесплатный доступ
The ontology alignment consists in generating a set of correspondences between entities. These entities can be concepts, properties or instances. The ontology alignment is an important task because it allows the joint consideration of resources described by different ontologies. This paper aims at counting all works of the ontology alignment field and analyzing the approaches according to different techniques (terminological, structural, extensional and semantic). This can clear the way and help researchers to choose the appropriate solution to their issue. They can see the insufficiency, so that they can propose new approaches for stronger alignment. They can also adapt or reuse alignment techniques for specific research issues, such as semantic annotation, maintenance of links between entities, etc.
Ontology Alignment, Terminological Method, Structural Method, Extensional Method, Semantic Method
Короткий адрес: https://sciup.org/15014814
IDR: 15014814
Текст научной статьи Ontology-Alignment Techniques: Survey and Analysis
Published Online November 2015 in MECS DOI: 10.5815/ijmecs.2015.11.08
The rapid development of Internet technology generated a growing interest in research on the sharing and integrating dispersed resources in a distributed environment. The Semantic Web offers the possibility for software agents to understand resources semantically linked in a decentralized architecture. Ontologies have been recognized as an essential component for sharing knowledge and realizing this vision. By defining concepts associated with particular areas, ontologies allow both to describe the content of the resources to be integrated, and to clarify the vocabulary used in queries of users. However, it is unlikely that a global ontology covering all distributed systems can be developed. In practice, ontologies of different systems have been developed independently of each other by different communities. Thus, if knowledge and data have to be shared, it is essential to establish semantic correspondences between the concerned ontologies. The ontology alignment task is important because it allows the joint consideration of resources described by different ontologies.
The Ontology Alignment is a complex task based on similarity measures. Many studies have been performed, but most of time only one measure is revealing insufficient to detect a similarity. Different approaches combining several measures sequentially were proposed: this combination is performed a priori, and it is not modified. The approaches should be more promising.
Our objective is to study, analyze and examine deferent alignment techniques and approaches that employ these techniques.
The rest of the paper is organized as follows: Section 2 describes techniques and methods used in the literature to address the research issue of similarity and dissimilarity, or correspondence between two entities in general. The deferent approaches that employ these techniques will be presented in Section 3. Section 4 presents statistics describing the rate of use of alignment techniques (terminological, structural, semantic and extensional) by different approaches. Finally, we conclude our work and mention some perspectives.
-
II. Alignment Techniques
The Ontology Alignment is performed according to a strategy or a combination of techniques for calculating similarity measures, and it uses a set of parameters (e.g., weighting parameters, thresholds, etc.) and a set of external resources (e.g., thesaurus, dictionary, etc.). At the end, we obtain a set of semantic links between the entities that compose the ontologies. There are several methods for calculating similarity between entities of several ontologies. Classifications of Alignment techniques are given in [94], [95] and [96].
-
A. Terminological methods
These methods are based on the comparison of terms, strings or texts. They are used to calculate the value of similarity between units of text, such as names, labels, comments, descriptions, etc. These methods can be further divided into two sub-categories: methods that compare the terms based on characters in these terms, and methods using some linguistic knowledge.
-
B. Structural methods
These methods calculate the similarity between two entities by exploiting structural information, when the concerned entities are connected to the others by semantic or syntactic links, forming a hierarchy or a graph of entities.
We call:
-
• Internal structural methods, methods that only exploit information about entity attributes,
-
• External structural methods, methods that consider relations between entities.
-
C. Extensional methods
These methods infer the similarity between two entities, especially concepts or classes, by analyzing their extensions, i.e. their instances.
-
D. Semantic methods
Techniques based on the external ontologies: When two ontologies have to be aligned, it is preferable that the comparisons are done according to a common knowledge. Thus, these techniques use an intermediate formal ontology to meet that need. This ontology will define a common context [35] for the two ontologies to be aligned.
Deductive techniques: Semantic methods are based on logical models, such as propositional satisfiability (SAT), SAT modal or description logics. They are also based on deduction methods to deduce the similarity between two entities. Techniques of description logics, such as the subsumption test, can be used to verify the semantic relations between entities, such as equivalence (similarity is equal to 1), the subsumption (similarity is between 0 and 1) or the exclusion (similarity is equal to 0), and therefore used to deduce the similarity between the entities.
These alignment techniques are integrated into approaches for mapping ontologies. We find approaches that combine multiple alignment techniques. Much work has been developed in the area of Ontology and focus on the alignment techniques.
-
III. Alignment Approaches
The literature counts a wide range of methods [31]. These are from various communities, such as information retrieval, databases, learning, knowledge engineering, automatic natural language processing, etc.
In [19] the authors consider a context where experts can use their own ontologies, called personal ontologies. Ontology is then represented by a support in the conceptual graph formalism. This support comprises a grid concept types, a hierarchy of relations types and a set of markers for the identification of instances.
The objective is to build a common knowledge model (common ontology) from different knowledge models of experts (personal ontology). This is realized, in a system called MULTIKAT, by comparing personal ontologies using techniques based on operations of the conceptual graph formalism or the structure of graphs.
Anchor-PROMPT [68] constructed a labeled oriented graph representing the ontology from the hierarchy of concepts (called classes in the algorithm) and the hierarchy of relations (called slots in the algorithm), where nodes in the graph are concepts and the arcs denote relations between concepts (labels of arcs are the names of relations). An initial list of anchor pairs (pairs of similar concepts) defined by the user or automatically identified by the lexicological mapping serves as input to the algorithm. Anchor-PROMPT then analysis paths in the sub-graphs limited by anchors, and determines which concepts appear frequently in similar positions on the similar paths.
GLUE [21] is the advanced version of LSD [20] which aims to find semi-automatic mappings between schemas for data integration. Like LSD, GLUE uses the learning technique (such as the naive Bayes learning technique) to find matches between two ontologies. GLUE includes several learning modules (Learners), which are entrained by instances of ontologies.
S-Match [34] is an algorithm and a system for semantically searching for correspondences based on the idea of using the engine of propositional satisfiability (SAT) [35] for the mapping schema issue. It takes as input two graphs of concepts (schemas), and generates as outputs relations between concepts, such as equivalence, overlapping, difference (mismatch), more general or more specific. The principal idea of this approach is to use logic to encode the concept of a node in the graph and applying SAT for reports.
COMA [22] is a system to match schemas (of databases, XML or ontologies) automatically or manually. The system provides a library of basic mapping algorithms (called matchers) and some mechanisms for combining results of the basic algorithms to get a final similarity value of two elements in two schemas.
OLA [30] is an algorithm to align ontologies represented in OWL. He tries to calculate the similarity of two entities in two ontologies based on their characteristics (their types: class, relations or instance; their reports with other entities: subclass, domain, codomain ...) and combine the similarity values calculated for each pair of entities homogeneously.
It is further noted that:
-
• The approaches, coma and COMA ++, S-Match, manage many types of ontologies.
-
• The approaches, DCM, HSM, IceQ, their inputs have multiple ontologies.
-
• The approaches, coma and COMA++ and GeRoMeSuite, their internal presentations are oriented acyclic graphs.
-
• Most of systems focus on the discovery of simple
correspondences one-to-one. Although only a few systems have attempted to solve the problem of discovering more complex correspondences, such as IMAP, DCM, HSM, AOA, PORSCHE Optima Optima+.
The approaches S-Match, DSSim and TaxoMap calculate the similarity measures between different entities of the ontology, as disjunction and subsumption. However, the other approaches only calculate the equivalence relations.
Several approaches have introduced new ways for encoding the alignment process. For example, iMatch and CODI use the Markov networks. Others, like PARIS, propose interesting imbrications between the data links and the alignment schema. Other approaches, as VSBM and GBM, analyze also the image data.
Several recent approaches have introduced the alignment check in the matching process, like Lily, YAM++ and LogMap.
The approaches, Falcon, Anchor-Flood, Lily, AgreementMaker, LogMap FSM and effectively manage large-scale ontologies.
-
• The approaches, COMA++, S-Match,
AgreementMaker, DSSim, Sambo and YAM++, are equipped with a graphical user interface.
Table.1. summarizes the schema and ontology alignment approaches. In fact, many approaches use the same techniques based on strings. We note also that some approaches use WordNet as an external resource.
In turn, the semantic measures are used only in some approaches, for example, CtxMatch, S-Match and LogMap.
The Input column represents the inputs of the systems.
The Needs column represents the resources to be available to star the system. This covers the manual aspect, referenced by "USER" in the table, when the user's back is required; "SEMI" when the system can take advantage of the user feedback; but can be "AUTOMATIC" when the system operates without the user intervention. The "INSTANCES" value indicates that the system requires data instances.
The columns, Terminological Measures , Structural Measures , Extensional Measures and Semantic Measures , specify the alignment techniques adopted by the approach in question.
Table 1. Summary of alignment approaches
|
Approach |
Input |
Needs |
Terminological Measures |
Structural Measures |
Extensional Measures |
Semantic Measures |
Observation |
|
T-tree [29] |
Ontologies |
AUTO, INSTANCES |
Correlation |
||||
|
SEMINT [52] |
Relational schema |
AUTO, INSTANCES |
Neural network, Data types |
Constraintbased |
|||
|
DELTA [9] |
Relational schema, EER |
USER |
String-based |
||||
|
Hovy [41] |
Ontologies |
SEMI |
String-based, Languagebased |
Taxonomic |
|||
|
Cupid [58] |
XML schema, Relational schema |
AUTO |
String-based, Languagebased, Data types, Auxiliary thesaurus |
Tree matching weighted by leaves |
|||
|
LSD [17] |
XML schema, Relational schema |
AUTO, INSTANCES |
Naive Bayes, |
Hierarchical structure |
Constraintbased |
||
|
COMA/ COMA++ [16] |
XML schema, Relational schema OWL |
USER |
String-based, Languagebased, Data types, Auxiliary thesaurus |
DAG (tree) matching with a bias towards various structures, e.g., leaves, Repository of structures |
|||
|
Similarity flooding [63] |
XML schema, Relational schema |
USER |
String-based, Data types |
Iterative fixed point computation |
|||
|
XClust [50] |
DTD |
AUTO |
Cardinality, WordNet |
Paths, Children, Leaves, Clustering |
Constraintbased |
||
|
Automatch [4] |
Relational schema |
AUTO, INSTANCES |
Naive Bayes, |
Internal structure, Statistics |
|
[92] |
XML schema, Taxonomy |
AUTO, INSTANCES |
String-based, Language-based, WordNet |
||||
|
IF-Map [53] |
KIF, RDF |
AUTO, INSTANCES |
String-based |
Formal concept analysis |
|||
|
SBI&NB [42] |
Classification |
AUTO, INSTANCES |
Statistics, Naive Bayes, |
Pachinko Machine, Naive Bayes |
|||
|
[54] |
Relational schema |
INSTANCES |
Language-based |
Mutual information, Dependency graph matching |
|||
|
S-Match [33] |
Classification, XML schema, OWL |
AUTO |
String-based, Language-based, WordNet |
Propositional SAT |
|||
|
GLUE [18] |
XML schema, Relational schema, Taxonomic |
AUTO, INSTANCES |
Naive Bayes, |
Hierarchical structure |
Instances-Based, Constraintbased |
||
|
iMAP [13] |
Relational schema |
AUTO, INSTANCES |
Naive Bayes, |
Hierarchical structure |
Constraintbased |
||
|
ASCO [3] |
RDFS, OWL |
AUTO |
String-based, Language-based, WordNet |
Iterative similarity propagation |
|||
|
[89] |
Web form |
INSTANCES |
Language-based |
Mutual information |
Data Integration |
||
|
NOM [26] |
RDF, OWL |
AUTO, INSTANCES |
String-based |
Matching of neighbours, Taxonomic structure |
|||
|
QOM [27] |
RDF, OWL |
AUTO, INSTANCES |
String-based, Domain, Application, Vocabulary |
Matching of neighbours, Taxonomic structure |
|||
|
IceQ [91] |
Web form |
AUTO, SEMI |
String-based |
Clustering |
Constraintbased |
||
|
OLA [30] |
RDF, OWL |
AUTO, INSTANCES |
String-based, Language-based, Data type, WordNet |
Iterative fixed point computation, Matching of neighbours, Taxonomic structure |
|||
|
[79] |
WSDL |
AUTO |
String-based, Language-based, WordNet |
Structure comparison |
|||
|
MWSDI [69] |
WSDL, OWL |
AUTO |
String-based, Language-based, WordNet |
Structure comparison |
|||
|
BayesOWL [70] |
Classification, OWL |
AUTO |
Text classifier, Google |
Bayesian inference |
|||
|
OMEN [64] |
OWL |
AUTO, ALIGNEMENT |
Bayesian inference, Meta-rules |
||||
|
DCM [8] |
Web form |
AUTO |
Correlation, Statistics |
Data integration |
|||
|
Dumas [5] |
Relational schema |
INSTANCES |
String-based |
Instance identification |
|||
|
oMap [78] |
OWL |
AUTO, INSTANCES |
Naive Bayes,, String-based |
Similarity propagation |
Query answering |
||
|
eTuner [76] |
Relational schema, Taxonomy |
AUTO |
|||||
|
SAMBO [51] |
OWL |
AUTO, DOCUMENTS |
String-based, Naive Bayes,, WordNet |
Iterative structural similarity based on is-a , part-of hierarchies |
Ontology merging |
||
|
AROMA [12] |
Classification, OWL |
AUTO, INSTANCES |
String-based |
Association rules |
|
RiMOM [83] |
OWL |
AUTO, INSTANCES |
Stringbased, Naive Bayes,, WordNet |
Taxonomic structure, Similarity propagation |
|||
|
LCS [46] |
RDF, OWL |
AUTO |
|||||
|
HSM [80] |
Ontologies |
AUTO |
Co-occurrence patterns, Statistics |
||||
|
CtxMatch/ CtxMatch2 [7] |
Classification, OWL |
USER |
Stringbased, Languagebased, WordNet |
Based on description logics |
|||
|
CBW [37] |
OWL |
AUTO |
Stringbased |
Coincidencebased weighting |
|||
|
GeRoMeSuite [55] |
SQL DDL, XML, OWL |
AUTO, SEMI |
Stringbased |
Similarity flooding, Children |
Merging, Composing |
||
|
AOAS [93] |
OWL |
AUTO |
Stringbased, Languagebased |
Compatible is-a , part-of paths |
Rule-based inference |
||
|
ILIADS [87] |
OWL |
AUTO, INSTANCES |
Stringbased, Languagebased, WordNet |
Matching neighbors, Clustering |
Rule-based inference |
Ontology merging |
|
|
Scarlet [74] |
OWL |
AUTO |
Stringbased |
Ad hoc rule-based inference |
|||
|
BeMatch [10] |
BPEL, WCSL |
AUTO, SEMI |
Stringbased, Languagebased, WordNet |
Graph isomorphism |
Service transformation |
||
|
PORSCHE [75] |
XSD |
AUTO |
Stringbased, Languagebased, Thesaurus |
Clustering, Tree mining |
Mediation schema |
||
|
Match-Planner [24] |
XML |
AUTO, |
Second String, Languagebased, WordNet |
||||
|
Falcon-AO [40] |
RDF, OWL |
AUTO, INSTANCES |
Stringbased, WordNet |
Structural affinity |
|||
|
SMB [61] |
Web form, XML schema, OWL |
AUTO |
|||||
|
FSM [45] |
Relational schema |
AUTO, INSTANCES |
Stringbased |
||||
|
Anchor-Flood [39] |
RDFS, OWL |
AUTO |
Stringbased, Languagebased, WordNet |
Internal, external similarities, Iterative anchorbased similarity propagation |
|||
|
[88] |
OWL |
AUTO, SEMI |
Stringbased |
Variations of similarity flooding |
|||
|
AgreementMaker [11] |
XML, RDFS, OWL, N3 |
AUTO, SEMI |
Stringbased, Languagebased, WordNet |
Descendant, sibling similarities |
|||
|
HAMSTER [66] |
XML |
AUTO, SEMI, INSTANCES |
Stringbased, Languagebased, Naive Bayes,, Click logs |
Structure comparison |
|
Smart Matcher [90] |
UML |
AUTO, USER , INSTANCES |
COMA++, FOAM |
Structure comparison |
Instances-based |
Instance transformation |
|
|
GEM/Optima/ Optima+ [23][86][87] |
RDF, OWL, N3 |
AUTO, INSTANCES |
String-based, Language-based, WordNet |
ExpectationMaximization, Matching of neighbors |
|||
|
YAM/YAM++ [25] |
XML, OWL |
AUTO, SEMI |
WordNet |
Structure profiles, Similarity flooding |
|||
|
GOALS [59] |
OWL |
AUTO |
|||||
|
ContentMap [47] |
OWL |
AUTO, SEMI |
Integrated ontology |
||||
|
SeqDisc [2] |
WSDL |
AUTO |
String-based, Language-based |
Leafs, Children, Ancestor comparison |
|||
|
OMviaUO [62] |
RDFS, OWL |
AUTO |
String-based, Language-based |
Taxonomic |
Rule-based inference |
||
|
BLOOMS/ BLOOMS+ [43] |
RDFS, OWL |
AUTO |
Language-based, API alignment |
Taxonomic structure |
Rule-based inference |
||
|
Homolonto [71] |
OBO |
AUTO, SEMI |
Language-based, |
Children similarity |
Homologous groups |
||
|
DSSim [65] |
OWL, SKOS |
AUTO |
String-based, Language-based, WordNet |
Instances-based |
Question answering |
||
|
TaxoMap [38] |
OWL |
AUTO, SEMI |
String-based, Language-based |
Structure comparison via is-a hierarchies |
|||
|
VSBM&GBM [44] |
Ontologies |
AUTO, INSTANCES |
Statistics, SVM |
Correlations in graph |
|||
|
CSR [82] |
OWL |
AUTO, INSTANCES |
String-based |
Feature-based similarity, Machine learning |
|||
|
Prior+ [60] |
OWL |
AUTO, INSTANCES |
String-based, Language-based |
Feature-based similarity, Neural network |
|||
|
MoTo [28] |
OWL |
AUTO, INSTANCES |
Naive Bayes, k -Nearest neighbor |
Structural validation: Taxonomy, Other relations |
Neural network |
||
|
CODI [67] |
OWL |
AUTO, INSTANCES |
SimMetrics |
Structure comparison |
Markov net inference |
||
|
CIDER [36] |
OWL |
AUTO |
String-based, Language-based |
||||
|
MapPSO [6] |
OWL |
AUTO |
String-based, Language-based, WordNet |
Populationbased optimization |
|||
|
ProbaMap [84] |
Taxonomy |
AUTO, INSTANCES, |
Statistics, Naive Bayes, C4.5, SVM |
||||
|
LogMap [48] |
OWL |
AUTO, SEMI |
String-based, Language-based, WordNet |
Structure comparison |
Propositional Horn satisfiability |
||
|
AMC [72] |
Relational schema, XML, OWL |
AUTO, SEMI, INSTANCES |
|||||
|
iMatch [1] |
OWL |
AUTO, SEMI |
String-based |
||||
|
PARIS [81] |
RDFS |
AUTO, INSTANCES |
String-based |
Probabilistic estimates via iterative fixed point computation |
|||
|
AMS [73] |
Relational schema, XML, OWL |
AUTO, SEMI, INSTANCES |
|
LogMap2 [49] |
OWL |
AUTO, SEMI |
String-based, Language-based, WordNet |
Structure comparison |
Propositional Horn satisfiability |
||
|
XMapSiG/ XMapGen [14] |
Ontology |
SEMI |
WordNet, String-based |
Based on information about the presence of the properties and their cardinality constraints |
|||
|
XMAP ++ [15] |
Ontology OWL-DL |
SEMI |
WordNet, String-based, Aggregated similarities |
Based on information about the presence of the properties and their cardinality constraints |
Based on linguistic measures |
RNA is used to calculate the best match between pairs of entities, to maximize the discovery of many similar couples and reduce the number of those who are dissimilar. The final alignment is obtained after filtering based on a threshold |
|
|
RiMOM-IM [77] |
Ontologies |
SEMI |
Tokens-based (TF/IDF), Aggregated similarities |
Instances-based, cosines traditional similarity, maxpooling+ similarity |
|||
|
MaasMatch [32] |
Ontologies |
AUTO |
Language-based |
Based on linguistic measures |
|||
|
InsMT [56] |
Ontologies |
AUTO, SEMI |
String-based (levenshtein, Jaro, SLIM-Winkler), Aggregated similarities |
Instances-based |
|||
|
InsMTL [57] |
Ontologies |
AUTO, SEMI |
String-based (levenshtein distance, Jaro, SLIM-Winkler) , Aggregated similarities, WordNet |
Instances-based, Based on linguistic measures |
The system applies a local filter |
||
|
AOT [56] |
Ontologies |
AUTO, SEMI |
String-based (distance of levenshtein, Jaro, SLIM-Winkler, Jaro-Winkler, Smith-Waterman and Needleman- Wunsch), Aggregated similarities |
The system applies a local filter, The system applies a second filter to identify global alignment |
|||
|
InstML [57] |
Ontologies |
AUTO, SEMI |
String-based (distance of levenshtein, Jaro, SLIM-Winkler, Jaro-Winkler, Smith-Waterman and Needleman- Wunsch), Aggregated similarities, WordNet |
Based on linguistic measures |
-
IV. Statistics
The approaches we have previously cited, their main difference reside in the strategy used to discover the similarity between two entities. In most cases, are used terminological and/or structural and/or extensional similarity measures. Semantic measures are operated in some approaches, for example, CtxMatch, S-Match and LogMap.
A combination strategy allows to find the final similarity. This, generally, represents an equivalence or subsumption relationship between two entities from two different ontologies. The use of multiple similarity measures gives often better results. On the other side, these tools do not always specify which matchers were used or how the similarities were aggregated. Moreover, it should be noted that frameworks are more suitable for reuse as well as the combination of existing similarity measures according to preset criteria. These systems also differ in functioning and interaction offered to their users.
The intervention of a domain expert in the ontology alignment process is often necessary to avoid inconsistencies. By more interactive tools, such as PROMPT or FOAM, suggesting alignment results to the user often gives better results. On the other side, they do not allow reusing the alignment results to deduce other correspondence relations.
Fig.1. shows that researches in the ontology alignment field started with the nineties. From 2000 to 2009, the number of works in this domain is becoming increasingly important with the appearance of the Semantic Web notion. This number reaches its maximum in 2010. Researches continue to this day.
From Fig. 2, it is clear that the terminological method intervenes in a large number of approaches. The structural method also marks its importance among other techniques. This can be explained by the fact that the methods based on terms or structure are often manageable and easy to be implemented. Unlike semantic methods which require the availability of semantic sources, difficult to be constructed. They also require complex reasoning engines to infer semantic relations.
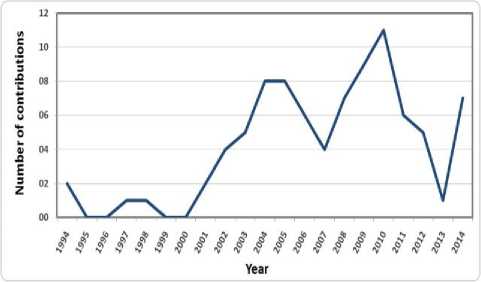
Fig.1. Evolution of the number of works in the ontology alignment field.
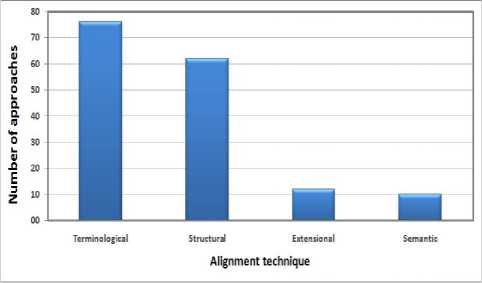
Fig.2. Rate of using alignment techniques (terminological, structural, extensional and semantic)
-
V. Conclusion and Perspectives
The Alignment Process Consists In Producing A Set Of Mappings (Correspondences) Between Entities. However, The Automatic Generation Of
Correspondences Between Two Ontologies Is Extremely Difficult, Due To The Differences (Conceptual, Habits, Etc.) Between Different Communities Concerned By These Ontologies. Furthermore, The Alignment Issue Is Particularly Acute When The Number And Volume Of Data Schemas Are Important. Indeed, In The Real Applications, Where Ontologies Are Voluminous And Complex, Requirements Of Execution Time And Memory Space Are Two Significant Factors That Directly Influence The Performance Of An Alignment Algorithm.
The Purpose Of This Paper Is To Identify And Cite Works In The Ontology Alignment Field. This Can Clear The Way For Researchers In This Domain. They Can Choose The Appropriate Approach To Their Problem. They Can Also See The Shortcomings And Correct Them, Or Propose New Alignment Approaches. As For Us, We Expect To Offer A Maintenance Approach Of Existing Alignments. This Problem Can Be Caused By The Development And Evolution Of Ontologies Making Parts Of An Existing Alignment.
Список литературы Ontology-Alignment Techniques: Survey and Analysis
- Albagli, S.Ben-Eliyahu-Zohary, R.Shimony, S.E.: Markov network based ontology matching. J. Comput. Syst. Sci. 78(1), 105–118, (2012).
- Algergawy, A., Nayak, R., Siegmund, N., Köppen, V. and Saake, G.: Combining schema and levelbased matching for web service discovery. In: Proc. 10th International Conference on Web Engineering (ICWE), Vienna, Austria, pp. 114–128, (2010).
- Bach, T.-L., Dieng-Kuntz, R. and Gandon, F.: On ontology matching problems (for building a corporate semantic web in a multi-communities organization). In: Proc. 6th International Conference on Enterprise Information Systems (ICEIS), Porto, Portugal, pp. 236–243 (2004).
- Berlin, J. and Motro, A.: Database schema matching using machine learning with feature selection. In: Proc. 14th International Conference on Advanced Information Systems Engineering (CAiSE), Toronto, Canada. Lecture Notes in Computer Science, vol. 2348, pp. 452–466, (2002).
- Bilke, A. and Naumann, F.: Schema matching using duplicates. In: Proc. 21st International Conference on Data Engineering (ICDE), Tokyo, Japan, pp. 69–80, (2005).
- Bock, J. and Hettenhausen, J.: Discrete particle swarm optimisation for ontology alignment. Inf. Sci. 192, 152–173, (2012).
- Bouquet, P., Serafini, L., Zanobini, S. and Sceffer, S.: Bootstrapping semantics on the web: meaning elicitation from schemas. In: Proc. 15th International World Wide Web Conference (WWW), Edinburgh, UK, pp. 505–512, (2006).
- Chang, K., He, B. and Zhang, Z.: Toward large scale integration: building a metaquerier over databases on the web. In: Proc. 2nd Biennial Conference on Innovative Data Systems Research (CIDR), Asilomar, CA, USA, pp. 44–55, (2005).
- Clifton, C., Hausman, E. and Rosenthal, A.: Experience with a combined approach to attribute matching across heterogeneous databases. In: Proc. 7th IFIP Conference on Database Semantics, Leysin, Switzerland, pp. 428–453, (1997).
- Corrales, J.C., Grigori, D., Bouzeghoub, M.and Burbano, J.E.: BeMatch: a platform for matchmaking service behavior models. In: Proc. 11th International Conference on Extending Database Technology (EDBT), Nantes, France, pp. 695–699, (2008).
- Cruz, I., Antonelli, F.P. and Stroe, C.: AgreementMaker: efficient matching for large real-world schemas and ontologies. Proc. VLDB Endow. 2(2), 1586–1589, (2009).
- David, J., Guillet, F. and Briand, H.: Matching directories and OWL ontologies with AROMA. In: Proc. 15th ACM Conference on Information and Knowledge Management (CIKM), Arlington, VA, USA, pp. 830–831, (2006).
- Dhamankar, R., Lee, Y., Doan, A.-H., Halevy, A. and Domingos, P.: iMAP: discovering complex semantic matches between database schemas. In: Proc. 23rd International Conference on Management of Data (SIGMOD), Paris, France, pp. 383–394, (2004).
- Djeddi, W. and Khadir, M.-T.: XMapGen and XMapSiG results for OAEI 2013. In Proceedings of the 8th International Workshop on Ontology Matching co-located with the 12th International Semantic Web Conference (ISWC 2013), pp. 203–210. Sydney, Australia, October 21, (2013).
- Djeddi, W. and Khadir, M. T.: XMap++: Results for OAEI 2014. In Proceedings of the 9th International Workshop on Ontology Matching collocated with the 13th International Semantic Web Conference (ISWC 2014). Riva del Garda, Trentino, Italy, October 20, (2014).
- Do, H.-H. and Rahm, E.: COMA—a system for flexible combination of schema matching approaches. In: Proc. 28th International Conference on Very Large Data Bases (VLDB), Hong Kong, China,pp. 610–621, (2002).
- Doan, A.-H., Domingos, P. and Halevy, A.: Reconciling schemas of disparate data sources: a machinelearning approach. In: Proc. 20th International Conference on Management of Data (SIGMOD), Santa Barbara, CA, USA, pp. 509–520, (2001).
- Doan, A.-H., Madhavan, J., Domingos, P. and Halevy, A.: Ontology matching: a machine learning approach. In: Staab, S., Studer, R. (eds.) Handbook on Ontologies, pp. 385–404. Springer, Berlin, (2004).
- Dieng, R. and Hug, S.: Comparison of -personal ontologies- represented through conceptual graphs. In Proc. 13th ECAI, Brighton (UK), pp. 341–345, (1998).
- Doan, A., Domingos, P. and Halevy, A.: Learning source descriptions for data Integration. In: ProcWebDBWorkshop, pp. 81–92, (2000).
- Doan, A., Madhavan, J., Domingos, P. and Halevy, A.: Learning to Map between Ontologies on the Semantic Web. The 11th International World Wide Web Conference (WWW'2002), Hawaii, USA, (2002).
- Do, H.-H. and Rahm, E.: Matching large schemas: Approaches and evaluation. Information Systems, Volume32, Issue 6, pp. 857-885, September (2007)
- Doshi, P., Kolli, R. and Thomas, C.: Inexact matching of ontology graphs using expectationmaximization. J. Web Semant. 7(2), 90–106, (2009).
- Duchateau, F., Bellahsene, Z. and Coletta, R.: A flexible approach for planning schema matching algorithms. In: Proc. 16th International Conference on Cooperative Information Systems (CoopIS), Monterrey, Mexico. Lecture Notes in Computer Science, vol. 5331, pp. 249–264, (2008).
- Duchateau, F., Coletta, R., Bellahsene, Z. and Miller, R.: (not) Yet Another Matcher. In: Proc. 18th ACM Conference on Information and Knowledge Management (CIKM), Hong Kong, China, pp. 1537–1540, (2009).
- Ehrig, M. and Sure, Y.: Ontology mapping—an integrated approach. In: Proc. 1st European Semantic Web Symposium (ESWS), Hersounisous, Greece. Lecture Notes in Computer Science, vol. 3053, pp. 76–91, (2004).
- Ehrig, M. and Staab, S.: QOM—quick ontology mapping. In: Proc. 3rd International Semantic Web Conference (ISWC), Hiroshima, Japan. Lecture Notes in Computer Science, vol. 3298, pp. 683–697, (2004).
- Esposito, F., Fanizzi, N. and d'Amato, C.: Recovering uncertain mappings through structural validation and aggregation with the MoTo system. In: Proc. 25th ACM Symposium on Applied Computing (SAC), Sierre, Switzerland, pp. 1428–1432, (2010).
- Euzenat, J.: Brief overview of T-tree: the Tropes Taxonomy building Tool. In: Proc. 4th ASIS SIG/CRWorkshop on Classification Research, Columbus, OH, USA, pp. 69–87, (1994).
- Euzenat, J. and Valtchev, P.: Similarity-based ontology alignment in OWL-lite. In: Proc. 16th European Conference on Artificial Intelligence (ECAI), Valencia, Spain, pp. 333–337, (2004).
- Euzenat, J. and Shvaiko, P.: Ontology matching. Springer, Heidelberg (DE), (2007).
- Schadd, F.-C. and Roos, N.: Alignment Evaluation of MaasMatch for the OAEI 2014 Campaign. In Proceedings of the 9th International Workshop on Ontology Matching collocated with the 13th International Semantic Web Conference (ISWC 2014). Riva del Garda, Trentino, Italy, October 20, (2014).
- Giunchiglia, F. and Shvaiko, P.: Semantic matching. Knowl. Eng. Rev. 18(3), 265–280, (2003).
- Giunchiglia, F., Shvaiko, P. and Yatskevich, M.: S-Match: an algorithm and an implementation of semantic matching. In Proceedings of ESWS 2004, Heraklion (GR), pp. 61–75, (2004).
- Giunchiglia, F., Shvaiko, P. and Yatskevich, M.: Discovering missing background knowledge in ontology matching. In Proc. 16th European Conference on Artificial Intelligence (ECAI), pages 382–386, Riva del Garda (IT), (2006).
- Gracia, J., Bernad, J. and Mena, E.: Ontology matching
- with CIDER: evaluation report for OAEI 2011. In: Proc. 6th International Workshop on Ontology Matching (OM) at the 10th International Semantic Web Conference (ISWC), Bonn, Germany, pp. 126–133, (2011).
- Haeri (Hossein), S., Abolhassani, H., Qazvinian, V. and Hariri, B.-B.: Coincidence-based scoring of mappings in ontology alignment. J. Adv. Comput. Intell. Intell. Inform. 11(7), 803–816, (2007).
- Hamdi, F., Reynaud, C. and Safar, B.: Pattern-based mapping refinement. In: Proc. 17th International Conference on Knowledge Engineering and Knowledge Management (EKAW), Lisbon, Portugal. Lecture Notes in Computer Science, vol. 6317, pp. 1–15, (2010).
- Hanif, M.-S. and Aono, M.: An efficient and scalable algorithm for segmented alignment of ontologies of arbitrary size. J. Web Semant. 7(4), 344–356, (2009).
- Hu, W., Qu, Y. and Cheng, G.: Matching large ontologies: a divide-and-conquer approach. Data Knowl. Eng. 67(1), 140–160, (2008).
- Hovy, E.: Combining and standardizing large-scale, practical ontologies for machine translation and other uses. In: Proc. 1st International Conference on Language Resources and Evaluation (LREC), Granada, Spain, pp. 535–542, (1998).
- Ichise, R., Takeda, H. and Honiden, S.: Integrating multiple Internet directories by instance-based learning. In: Proc. 18th International Joint Conference on Artificial Intelligence (IJCAI), Acapulco, Mexico, pp. 22–30, (2003).
- Jain, P., Hitzler, P., Sheth, A., Verma, K. and Yeh, P.: Ontology alignment for linked open data. In: Proc. 9th International Semantic Web Conference (ISWC), Shanghai, China. Lecture Notes in Computer Science, vol. 6496, pp. 401–416, (2010).
- James, N., Todorov, K. and Hudelot, C.: Combining visual and textual modalities for multimedia ontology matching. In: Proc. 5th International Conference on Semantic and Digital Media Technologies (SAMT), Saarbrücken, Germany. Lecture Notes in Computer Science, vol. 6725, pp. 95–110, (2010).
- Jaroszewicz, S., Ivantysynova, L. and Scheffer, T.: Schema matching on streams with accuracy guarantees. Intell. Data Anal. 12(3), 253–270, (2008).
- Ji, Q., Liu, W., Qi, G. and Bell, D.: LCS: a Linguistic Combination System for ontology matching. In: Proc. 1st International Conference on Knowledge Science, Engineering and Management (KSEM), Guilin, China, pp. 176–189, (2006).
- Jiménez-Ruiz, E., Grau, B.-C., Horrocks, I. and Berlanga, R.: Ontology integration using mappings: towards getting the right logical consequences. In: Proc. 6th European Semantic Web Conference (ESWC), Hersounisous, Greece. Lecture Notes in Computer Science, vol. 5554, pp. 173–188, (2009).
- Jiménez-Ruiz, E. and Grau, B.-C.: LogMap: logic-based and scalable ontology matching. In: Proc. 10th International Semantic Web Conference (ISWC), Bonn, Germany. Lecture Notes in Computer Science, vol. 7031, pp. 273–288, (2011).
- Jiménez-Ruiz, E., Grau, B.-C., Zhou, Y. and Horrocks, I.: Large-scale interactive ontology matching: algorithms and implementation. In: Proc. 20th European Conference on Artificial Intelligence (ECAI), Montpellier, France, pp. 444–449, (2012).
- Lee, M.-L., Yang, L.-H., Hsu, W. and Yang, X.: XClust: clustering XML schemas for effective integration. In: Proc. 11th International Conference on Information and Knowledge Management (CIKM), McLean, VA, USA, pp. 292–299, (2002).
- Lambrix, P. and Tan, H.: SAMBO—a system for aligning and merging biomedical ontologies. J. Web Semant. 4(1), 196–206, (2006).
- Li, W.-S. and Clifton, C.: Semantic integration in heterogeneous databases using neural networks. In: Proc. 20th International Conference on Very Large Data Bases (VLDB), Santiago, Chile, pp. 1–12, (1994).
- Kalfoglou, Y. and Schorlemmer, M.: IF-Map: an ontology mapping method based on information flow theory. J. Data Semant. I, 98–127, (2003).
- Kang, J. and Naughton, J.: On schema matching with opaque column names and data values. In: Proc. 22nd International Conference on Management of Data (SIGMOD), San Diego, CA, USA, pp. 205–216, (2003).
- Kensche, D., Quix, C., Chatti, M.-A. and Jarke, M.: GeRoMe: a Generic Role-based Metamodel for model management. J. Data Semant. VIII, 82–117, (2007).
- Khiat, A. and Benaissa, M.: AOT / AOTL Results for OAEI 2014. In Proceedings of the 9th International Workshop on Ontology Matching collocated with the 13th International Semantic Web Conference (ISWC 2014). Riva del Garda, Trentino, Italy, October 20, (2014).
- Khiat, A. and Benaissa, M.: InsMT / InsMTL results for OAEI 2014 instance matching. In Proceedings of the 9th International Workshop on Ontology Matching collocated with the 13th International Semantic Web Conference (ISWC 2014). Riva del Garda, Trentino, Italy, October 20, (2014).
- Madhavan, J., Bernstein, P., Doan, A.-H. and Halevy, A.: Corpus-based schema matching. In: Proc. 21st International Conference on Data Engineering (ICDE), Tokyo, Japan, pp. 57–68, (2005).
- Maio, P. and Silva, N.: GOALS: a test-bed for ontology matching. In: Proc. 1st International Conference on Knowledge Engineering and Ontology Development (KEOD), Madeira, Portugal, pp. 293–299 (2009).
- Mao, M., Peng, Y. and Spring, M.: An adaptive ontology mapping approach with neural network based constraint satisfaction. J. Web Semant. 8(1), 14–25, (2010).
- Marie, A. and Gal, A.: Boosting schema matchers. In: Proc. 16th International Conference on Cooperative Information Systems (CoopIS), Monterrey, Mexico. Lecture Notes in Computer Science, vol. 5331, pp. 283–300, (2008).
- Mascardi, V., Locoro, A. and Rosso, P.: Automatic ontology matching via upper ontologies: a systematic evaluation. IEEE Trans. Knowl. Data Eng. 22(5), 609–623, (2010).
- Melnik, S., Garcia Molina, H. and Rahm, E.: Similarity flooding: a versatile graph matching algorithm. In: Proc. 18th International Conference on Data Engineering (ICDE), San Jose, CA, USA, pp. 117–128, (2002).
- Mitra, P., Noy, N. and Jaiswal, A.: Ontology mapping discovery with uncertainty. In: Proc. 4th International Semantic Web Conference (ISWC), Galway, Ireland. Lecture Notes in Computer Science, vol. 3729, pp. 537–547, (2005).
- Nagy, M. and Vargas-Vera, M.: Towards an automatic semantic data integration: multi-agent framework approach. In: Wu, G. (ed.) Semantic Web, pp. 107–134. In-Teh, Vukovar, (2010).
- Nandi, A. and Bernstein, P.: HAMSTER: using search clicklogs for schema and taxonomy matching. Proc. VLDB Endow. 2(1), 181–192, (2009).
- Niepert, M., Meilicke, C. and Stuckenschmidt, H.: A probabilistic-logical framework for ontology matching. In: Proc. 24th Conference on Artificial Intelligence (AAAI),
- Atlanta, GA, USA, pp. 1413–1418, (2010).
- Noy, N. and Musen, M.: Anchor-PROMPT: Using non-local context for semantic matching. In Proc. IJCAI 2001 workshop on ontology and information sharing, Seattle (WA US), pp. 63–70, (2001).
- Oundhakar, S., Verma, K., Sivashanugam, K., Sheth, A. and Miller, J.: Discovery of web services in a multi-ontology and federated registry environment. Int. J. Web Serv. Res. 2(3), 1–32, (2005).
- Pan, R., Ding, Z., Yu, Y. and Peng, Y.: A Bayesian network approach to ontology mapping. In: Proc. 4th International Semantic Web Conference (ISWC), Galway, Ireland. Lecture Notes in Computer Science, vol. 3729, pp. 563–577, (2005).
- Parmentier, G., Bastian, F. and Robinson-Rechavi, M.: Homolonto: generating homology relationships by pairwise alignment of ontologies and application to vertebrate anatomy. Bioinformatics 26(14), 1766–1771, (2010).
- Peukert, E., Eberius, J. and Rahm, E.: AMC: a framework for modelling and comparing matching systems as matching processes. In: Proc. 27th International Conference on Data Engineering (ICDE), Hannover, Germany, pp. 1304–1307 (2011).
- Peukert, E., Eberius, J. and Rahm, E.: A self-configuring schema matching system. In: Proc. 28th International Conference on Data Engineering (ICDE), Washington, DC, USA, pp. 306–317, (2012).
- Sabou, M., d'Aquin, M. and Motta, E.: Exploring the semantic web as background knowledge for ontology matching. J. Data Semant. XI, 156–190, (2008)
- Saleem, K., Bellahsene, Z. and Hunt, E.: PORSCHE: Performance ORiented SCHEma mediation. Inf. Sci. 33(7–8), 637–657, (2008).
- Sayyadian, M., Lee, Y., Doan, A.-H. and Rosenthal, A.: Tuning schema matching software using synthetic scenarios. In: Proc. 31st International Conference on Very Large Data Bases (VLDB), Trondheim, Norway, pp. 994–1005, (2005).
- Shao, C., Hu, L. and Li, J.: RiMOM-IM results for OAEI 2014. In Proceedings of the 9th International Workshop on Ontology Matching collocated with the 13th International Semantic Web Conference (ISWC 2014). Riva del Garda, Trentino, Italy, October 20, (2014).
- Straccia, U. and Troncy, R.: oMAP: combining classifiers for aligning automatically OWL ontologies. In: Proc. 6th International Conference on Web Information Systems Engineering (WISE), New York, NY, USA, pp. 133–147, (2005).
- Stroulia, E. and Wang, Y.: Structural and semantic matching for assessing web-service similarity. Int. J. Coop. Inf. Syst. 14(4), 407–438, (2005).
- Su, W.,Wang, J. and Lochovsky, F.: Holistic schema matching for web query interfaces. In: Proc. 10th Conference on Extending Database Technology (EDBT), Munich, Germany. Lecture Notes in Computer Science, vol. 3896, pp. 77–94, (2006).
- Suchanek, F., Abiteboul, S. and Senellart, P.: PARIS: Probabilistic Alignment of Relations, Instances, and Schema. Proc. VLDB Endow. 5(3), 157–168, (2012).
- Spiliopoulos, V., Vouros, G. and Karkaletsis, V.: On the discovery of subsumption relations for the alignment of ontologies. J. Web Semant. 8(1), 69–88, (2010).
- Tang, J., Li, J., Liang, B., Huang, X., Li, Y. and Wang, K.: Using Bayesian decision for ontology mapping. J. Web Semant. 4(1), 243–262, (2006).
- Tournaire, R., Petit, J.-M., Rousset, M.-C. and Termier, A.: Discovery of probabilistic mappings between taxonomies: principles and experiments. J. Data Semant. XV, 66–101, (2011).
- Thayasivam, U. and Doshi, P.: Optima results for OAEI 2011. In: Proc. 6th International Workshop on Ontology Matching (OM) at the 10th International Semantic Web Conference (ISWC), Bonn, Germany, pp. 204–211, (2011).
- Thayasivam, U. and Doshi, P.: Improved convergence of iterative ontology alignment using blockcoordinate descent. In: Proc. 26th Conference on Artificial Intelligence (AAAI), Toronto, Canada, pp. 150–156, (2012).
- Udrea, O., Getoor, L. and Miller, R.: Leveraging data and structure in ontology integration. In: Proc. 26th International Conference on Management of Data (SIGMOD), Beijing, China, pp. 449–460, (2007).
- Wang, P. and Xu, B.: An effective similarity propagation method for matching ontologies without sufficient or regular linguistic information. In: Proc. 4th Asian SemanticWeb Conference (ASWC), Shanghai, China. Lecture Notes in Computer Science, vol. 5926, pp. 105–119, (2009).
- Wang, J.,Wen, J.-R., Lochovsky, F. and Ma,W.-Y.: Instance-based schemamatching for web databases by domain-specific query probing. In: Proc. 30th International Conference on Very Large Data Bases (VLDB), Toronto, Canada, pp. 408–419, (2004).
- Wimmer, M., Seidl, M., Brosch, P., Kargl, H. and Kappel, G.: On realizing a framework for selftuning mappings. In: Proc. 47th International Conference on Technology of Object-Oriented Languages and Systems (TOOLS), Zürich, Switzerland, pp. 1–16, (2009)
- Wu, W., Yu, C., Doan, A. and Meng, W.: An interactive clustering-based approach to integrating source query interfaces on the deep web. In: Proc. 23rd International Conference on Management of Data (SIGMOD), Paris, France, pp. 95–106, (2004).
- Xu, L. and Embley, D.: Discovering direct and indirect matches for schema elements. In: Proc. 8th International Conference on Database Systems for Advanced Applications (DASFAA), Kyoto, Japan, pp. 39–46, (2003)
- Zhang, S. and Bodenreider, O.: Experience in aligning anatomical ontologies. Int. J. Semantic Web Inf. Syst. 3(2), 1–26, (2007).
- Shvaiko P., Euzenat J. « A survey of schema-based matching approaches », Journal on Data Semantics, 2005, vol. 4, p. 146–171.
- Rahm E., Bernstein P. « A survey of approaches to automatic schema matching », The International Journal on Very Large Data Bases, VLDB, 2001, vol. 10, n 4, 334–350.
- Kalfoglou Y., Schorlemmer M. « Ontology mapping: the state of the art », The Knowledge Engineering Review Journal, KER, 2003, vol. 18, n 1, p.1–31.
