OSGI сервис распознавания речи с использованием Google API

Автор: Оболонный В.И.
Журнал: Теория и практика современной науки @modern-j
Рубрика: Математика, информатика и инженерия
Статья в выпуске: 8 (26), 2017 года.
Бесплатный доступ
Предложена архитектура декларативного OSGi сервиса распознавания речи. В архитектуре сервиса учтены требования, полученные в результате анализа заинтересованных сторон. Разработанная архитектура реализована в прототипе сервиса распознавания речи с использованием библиотеки J.A.R.V.I.S. и Google Speech API.
Распознавание речи, сервис
Короткий адрес: https://sciup.org/140272144
IDR: 140272144
OSGI recognition service with Google API
The article proposes the architecture of the declarative OSGi speech recognition service. The architecture of the service takes into account the requirements obtained as a result of stakeholder analysis. The developed architecture was implemented in the prototype of the speech recognition service with the library J.A.R.V.I.S. and the Google Speech API.
Текст научной статьи OSGI сервис распознавания речи с использованием Google API
В экосистеме OSGi существует набор спецификаций, описывающих стандартные сервисы [1] (для логирования, HTTP, веб приложений и др.), но нет спецификаций сервисов, связанных с распознаванием речи, хотя наличие такого сервиса было бы весьма полезно для Java разработчиков, желающих добавить в свой проект голосовое взаимодействие между пользователем и системой.
Для того, чтобы улучшить повторное использование библиотек работы с голосом, обеспечить их взаимозаменяемость - нужна спецификация такого сервиса. В данной работе предложено решение этой проблемы с помощью создания архитектуры, тестирования интерфейсов, архитектурных модулей с целью привлечения внимание сообщества к этой проблеме.
1 Сервис распознавания речи в окружении внешних систем
Основной задачей сервиса распознавания речи является преобразование речи в текст. Эта задача состоит из нескольких подзадач:
-
• Запись окружающих звуков в аудиопоток посредством микрофона;
-
• Выделение из аудиопоток областей, где может быть голос человека;
-
• Преобразование этих областей в текст.
Таким образом, сервис должен постоянно слушать окружающую среду и, после детектирования сообщения от пользователя, должен преобразовывать речь пользователя в текст. После чего, с этим текстом уже может работать какая-нибудь другая система, к примеру система управления устройствами умного дома (Рисунок 1).
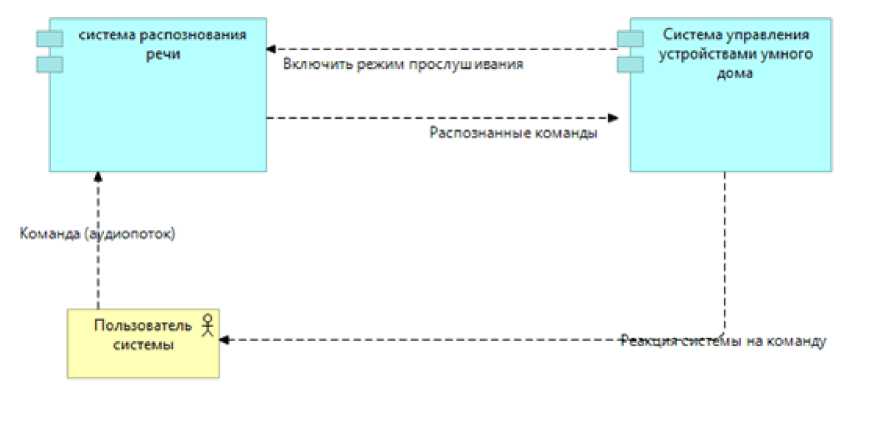
Рисунок 1- Подсистема распознавания речи в окружении внешних систем
Предполагается, что данный сервис разрабатывается не только для личных нужд автора, но и для общего пользования. Поэтому ниже приводится перечисление возможных заинтересованных сторон (ЗС) и их основных целей. На основе этой информации, в соответствии с [2] и [3] сформулированы требования, предъявляемые к сервису.
В данном случае можно выделить 4 ЗС: разработчик системы, сторонний разработчик, пользователь системы, тестировщик (Рисунок 2).
Разработчик системы – его основной интерес заключается в создании работоспособного сервиса распознавания речи с удобной архитектурой – т.е. такой, в котором можно было бы легко добавлять новые компоненты, обновлять или заменять старые. Это может быть достигнуто благодаря использовании OSGi спецификации.
Сторонний разработчик – в мире существует множество людей, использующих OSGi сервисы. Их основной интерес – возможность использовать готовые “решения из коробки” в своих проектах. Другими словами, сторонние разработчики хотят иметь возможность пользоваться OSGi сервисом и отдельными его компонентами без необходимости переписывания кода, что в целом также достигается благодаря использованию OSGi спецификации.
Пользователь системы, использующей сервис распознавания речи – в его интересы входит использование русскоязычной системы. Также очень важно, чтобы система имела малую долю ошибок.
Тестировщик – его интерес заключается в лёгком и удобном тестировании сервиса.
На основе заинтересованных стороны и их интересов были определены основные требования, предъявляемые к системе, они также представлены на рисунке 2.
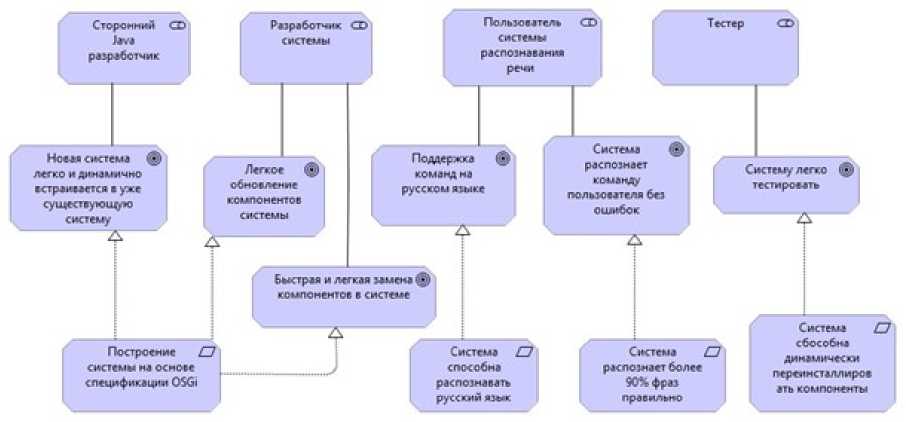
Рисунок 2 - Заинтересованные стороны, их цели, требования к системе
2 Анализ схожих проектов
Как уже говорилось выше, готовый OSGi сервис распознавания речи не был найден.
Т.к. создание собственного проекта преобразования аудиопотока в текст – это трудоёмкая и сложная задача, было решено найти проект, реализующий распознавание речи, и доработать его до OSGi сервиса. При этом основное внимание уделялось двум составляющим: модулю записи голоса в аудиопоток через аудио API и модулю преобразования аудиопотока в текст.
2.1 Проекты с Audio API
Был произведён поиск проектов, реализующих Audio API. Результат их сравнения приведён в таблице 1.
Таблица 1 - сравнительный анализ проектов, реализующих Audio API
|
JSyn [4] |
jsresources [5] |
TarsosDSP [6], [7] |
Xuggler [8] |
J.A.R.V.I.S. [9] |
|
|
Наличие лицензии |
Да |
Да |
Да |
Да |
Да |
|
Возможность работы с несколькими микрофонами |
Да |
Да |
Нет |
Нет |
Да |
|
Возможность работы с несколькими устройствами звука |
Нет |
Да |
Да |
Нет |
Нет |
|
Наличие класса Microphone |
Нет |
Нет |
Нет |
Нет |
Да |
|
Наличие класса аудиопотока |
Да |
Да |
Да |
Да |
Да |
|
Возможность создания конвейера обработки аудиопотока |
Да |
Да |
Да |
Да |
Да |
2.2 Проекты с API для распознавания речи
Был произведён поиск проектов, реализующих преобразования аудиопотока в текст Результат их сравнения приведён в таблице 2. Из них можно выделить:
-
1. CMU Sphinx - сейчас является крупнейшим проектом по распознаванию человеческой речи [10]. К минусам этого проекта можно отнести создание изначального словаря и грамматики. Точность распознавания зависит от созданной языковой модели.
-
2. Yandex SpeechKit - Комплекс речевых технологий Яндекса, который включает распознавание и синтез речи, голосовую активацию и выделение смысловых объектов в произносимом тексте [11]. Является достаточно точной [12] системой, имеющей свой API. Но использование API не бесплатное.
-
3. Code4Reference, J.A.R.V.I.S. и GoogleCloudPlatform – проекты, использующие Google Speech API для преобразования аудиофайла в текст.
Таблица 2 - сравнительный анализ проектов, реализующих преобразования аудиопотока в текст
|
Проект |
Цена |
Поддержка русского языка |
Точность |
|
Cmu sphinx |
Бесплатно |
Да |
? |
|
Code4Reference |
Бесплатно первые 60 минут в месяц |
Да |
95% [13] |
|
J.A.R.V.I.S. (Java-Speech-API) |
Бесплатно первые 60 минут в месяц |
Да |
95% [13] |
|
GoogleCloudPlatform |
Бесплатно первые 60 минут в месяц |
Да |
95% [13] |
|
Yandex SpeechKit Cloud |
200 рублей за 1000 запросов / 60 копеек за 1 минуту. |
Да |
82-95% [12] |
В результате анализа проектов, было решено за основу OSGi сервиса взять проект J.A.R.V.I.S., который использует анализатор аудиофайлов от Google (GoogleRecognizer), тем самым позволяя добиться поставленных требований по точности распознавания [13] и поддержке русского языка. В этом проекте в явном виде есть класс Microphone, что также упрощает создание сервиса.
3 Архитектура сервиса
В общем случае, простая сервис распознавания речи должен состоять из трёх компонент: микрофона, который будет записывать все происходящие звуки в аудиопоток, разделителя, который будет делить непрерывный аудиопоток на слова или фразы, и анализатора, который будет анализировать входной аудиофайл и преобразовывать его в текст (Рисунок 3).
Распознанный текст будет передаваться во внешнюю систему, которая в свою очередь сможет обработать этот текст.
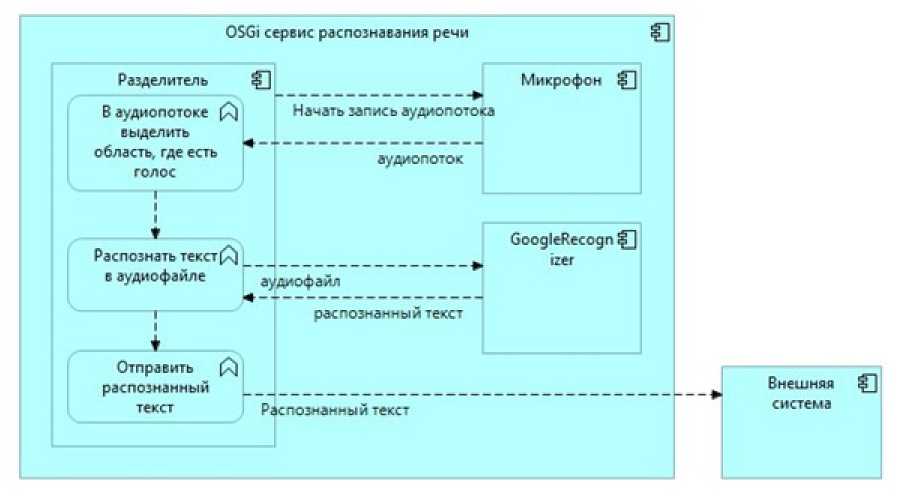
Рисунок 3- Модульная диаграмма OSGi сервиса
Как уже говорилось выше, готовый OSGi сервис не был найден, но был найден проект J.A.R.V.I.S., который наиболее подходит для доработки. Стоит отметить, что выбор конкретной реализации анализатора не столь важен, т.к. модульность разрабатываемого сервиса позволит легко заменить GoogleRecognizer на что-нибудь другое.
Для реализации OSGi сервиса на основе проекта J.A.R.V.I.S. были поставлены следующие задачи:
-
1. Создать интерфейс для микрофона;
-
2. На основе класса Microphone из библиотеки JARVIS сделать OSGi компоненту микрофона;
-
3. Создать интерфейс для анализатора текста;
-
4. На основе класса GoogleRecognizer из библиотеки JARVIS сделать OSGi компоненту анализатора;
-
5. Создать интерфейс для разделителя аудиопотока;
-
6. Реализовать OSGi компоненту разделителя аудиопотока.
4 Особенности реализации OSGi сервиса распознавания речи
В результате OSGi сервис состоит из трёх компонент: Recording, Recognizer и Micro, использующие интерфейсы RecordingAPI, RecognizerAPI и MicroAPI, код доступен по ссылке [14]. Схематичное изображение OSGi сервиса составлено в соответствии с [2] и представлено ниже (Рисунок 4), где зелёным цветом показаны самостоятельно написанные модули, а голубым цветом используемые.
RecordingAPI – интерфейс для работы с компонентой Recording , состоящей из двух потоков: RecordingThread и SendToGoogleThread. Поток RecordingThread использует компоненту Micro через интерфейс MicroAPI . Основная задача этого потока – постоянно записывать окружающие звуки через компоненту Micro . Как только уровень шума превышает некоторое заранее установленное пороговое значение, RecordingThread начинает записывать звуки через микрофон до тех пор, пока уровень шума не опустится ниже порогового, либо пока не пройдёт заранее установленное время (стоит отметить, что GoogleSpeechAPI позволяет обрабатывать аудиофайлы длиной не более 15 сек.). После этого RecordingThread передаёт записанный аудиофайл в поток SendToGoogleThread.
Поток SendToGoogleThread использует компоненту Recognizer через RecognizerAPI . Основная задача этого потока – передать аудиофайл компоненте Recognizer, которая, используя GoogleSpeechAPI, преобразует аудиофайл в текст, а потом передает полученный текст компоненте Command , которая представляет из себя любую стороннюю программу, в которой требуется получать распознанный текст.
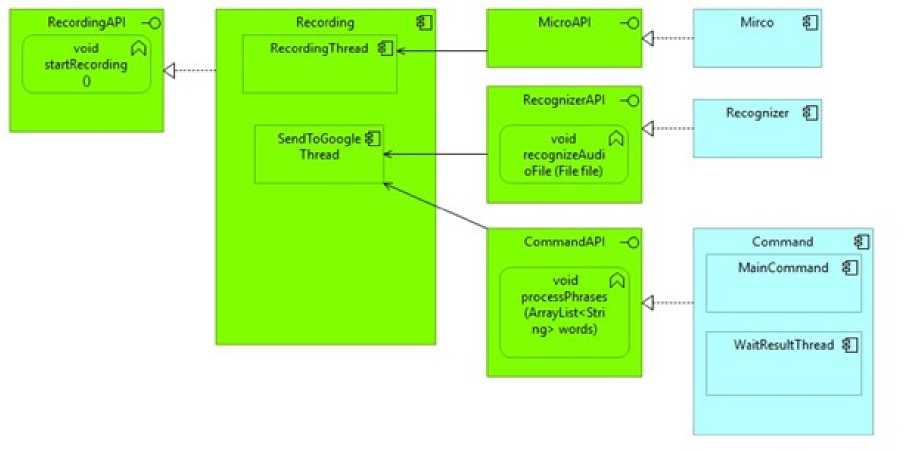
Рисунок 4 – Схематичное изображения OSGi сервиса распознавания речи
5 Тестирование системы
Для тестирования работоспособности сервиса была создана компонента Command , с простой функцией вывода в консоль распознанного текста. Для примера были произнесены три фразы: “Программа работает”, “Программа работает”, “Включить свет”. Пример вывода компоненты Command приведен на рисунке 5.
-
•_ Problems "^J Target Platform ... t: Plug-in Explorer ^ Console 53 5* Call
-
■ X ^t| @C £
Recording Complete!
My Google response:® программа работы
My Other Possible Responses:® End of Google Responses.
Start RECORDING...
Recording Complete!
My Google response:® программа работает My Other Possible Responses:® End of Google Responses.
Start RECORDING...
Recording Complete!
My Google response:® Включить свет
My Other Possible Responses:® End of Google Responses.
Рисунок 5 - Пример работы OSGi сервиса с выводом распознанного текста в консоль
Также производилось тестирование модульности разработанного сервиса. Вместо компонент Micro и Recognizer ставились заглушки и проверялась работоспособность сервиса.
Вместо компоненты Micro была поставлена заглушка, которая возвращала один из трёх заранее записанных аудиофайлов – первый файл с шумом, второй файл с одним словом, третий файл с фразой. В процессе тестирования сервис продолжал корректно работать и результаты работы совпадали с ожидаемыми.
Потом вместо компоненты Recognizer поставлена заглушка, которая принимала на вход аудиофайл и возвращала текст. В процессе тестирования сервис продолжал корректно работать и результаты работы совпадали с ожидаемыми.
Заключение
В работе рассмотрен OSGi сервис распознавания речи с использованием GoogleSpeechAPI, разработанный на основе проекта J.A.R.V.I.S, состоящий из трёх компонент: микрофона, анализатора и слушающего потока. Каждая из компонент создана на основе спецификации OSGi и может использоваться по отдельности.
В дальнейшем планируется улучшить точность распознавания путём добавления автоматической калибровки микрофона. Кроме того, планируется улучшить способ детектирования речи в аудиопотоке путём изменения логики выделения участков, содержащих голосовые сообщения. На данный момент запись аудиофайла начинается тогда, когда уровень шума превышает некоторый пороговый уровень, недостаток заключается в том, что пока уровень шума мал, то аудиопоток не сохраняется, и тут возможны потери голосовых сообщений. Планируется изменить логику на анализ большого аудиопотока на наличие скачков уровня шума, и дальнейшее распознавание этих скачков.
Список литературы OSGI сервис распознавания речи с использованием Google API
- Wikipedia contributors. "OSGi Specification Implementations". [Электронный ресурс]: Wikipedia, The Free Encyclopedia. Режим доступа: https://en.wikipedia.org/wiki/OSGi_Specification_Implementations. Дата обращения: 10.06.2017.
- Alexander, Ian (Ian F.), 1954-Discovering requirements: how to specify products and services / Ian Alexander & Ljerka Beus-Dukic. Great Britain: WILEY, 2009. - 478 c.
- Басс, Л., Клементс, П., и др. Архитектура программного обеспечения на практике. - СПб.: Питер, 2006. - 576 с.
- SoftSynth [Электронный ресурс] - режим доступа: http://www.softsynth.com/jsyn/ (дата обращения 28.05.2017).
- Java Sound Resources[Электронный ресурс] - режим доступа: http://www.jsresources.org (дата обращения 28.05.2017).
- TarsosDSP [Электронный ресурс] - режим доступа: https://github.com/JorenSix/TarsosDSP (дата обращения 28.05.2017).
- Joren Six, Olmo Cornelis, Marc Leman, TarsosDSP, a Real-Time Audio Processing Framework in Java // INTERNATIONAL CONFERENCE, London, UK, 2014 January 27-29.
- Xuggler [Электронный ресурс] - режим доступа: http://www.xuggle.com/about/ (дата обращения 28.05.2017).
- J.A.R.V.I.S. Speech API [Электронный ресурс] - режим доступа: https://github.com/lkuza2/java-speech-api (дата обращения 28.05.2017).
- Распознавание речи с помощью CMU Sphinx, Хабрахабр [Электронный ресурс] - режим доступа: https://habrahabr.ru/post/267539 (дата обращения 14.05.2017).
- Речевые технологии SpeechKit [Электронный ресурс] - режим доступа: https://tech.yandex.ru/speechkit/ (дата обращения 14.05.2017).
- Печатать нельзя, говорить, Блог Яндекса [Электронный ресурс] - режим доступа: https://yandex.ru/blog/company/85770 (дата обращения 14.05.2017).
- Google's speech recognition is now almost as accurate as humans [Электронный ресурс] - режим доступа: https://9to5google.com/2017/06/01/google-speech-recognition-humans/ (дата обращения 14.05.2017).
- VoiceOSGI [Электронный ресурс] - режим доступа: https://github.com/vladimirobolonnyy/VoiceOSGI.
