Отказоустойчивая система организации высокопроизводительных вычислений для решения задач обработки потоков данных

Автор: Талалаев Александр Анатольевич, Фраленко Виталий Петрович
Журнал: Программные системы: теория и приложения @programmnye-sistemy
Рубрика: Программное и аппаратное обеспечение распределенных и суперкомпьютерных систем
Статья в выпуске: 1 (36) т.9, 2018 года.
Бесплатный доступ
В работе представлен обзор существующих систем организации отказоустойчивых вычислений; рассмотрены функциональные характеристики разработанной высокопроизводительной системы на основе вычислительного ядра, специального интерфейса и прикладных модулей. В основе предлагаемой системы организации вычислений лежит распределенная NoSQL СУБД Apache Cassandra, обеспечивающая механизмы отказоустойчивого хранения и автоматической репликации данных в гетерогенной вычислительной среде. Система, оснащенная специальным графическим интерфейсом, позволяет разрабатывать решения для различных прикладных областей. Подключаемые модули могут выполнять в том числе и функции визуализации потоков данных.
Организация вычислений, база данных, отказоустойчивость, графический интерфейс, гетерогенная среда, модуль, визуализация
Короткий адрес: https://sciup.org/143164299
IDR: 143164299 | УДК: 004.75:004.052.3:004.042 | DOI: 10.25209/2079-3316-2017-9-1-85-108
Fault-tolerant system for organizing high-performance computing for solving data processing problems
The paper presents an overview of existing systems of organization of fault-tolerant computing; functional characteristics of the developed high-performance system based on the computational core, a special interface and application modules are considered. At the heart of the proposed system of computing is distributed NoSQL database Apache Cassandra, providing mechanisms for fault-tolerant storage and automatic replication of data in a heterogeneous computing environment. The system, equipped with a special graphical interface, allows to develop solutions for various application areas. Plugins can also perform the functions of visualizing data streams (In Russian). (in Russian).
Текст научной статьи Отказоустойчивая система организации высокопроизводительных вычислений для решения задач обработки потоков данных
Организационно-технические детали реализации программного обеспечения существенно влияют на его дальнейшие эксплуатационные характеристики. В частности, при выработке мер достижения высокой доступности информационных сервисов рекомендуется опираться на следующие архитектурные принципы:
-
• апробированность всех процессов и составных частей;
-
• унификация процессов и составных частей;
Исследование выполнено при частичной финансовой поддержке РФФИ (проекты № 15-29-06945-офи_м, 16-29-12839-офи_м, 17-29-07002-офи_м и 18-07-00014-а).
(О А. А. Талалаев, В. П. Фраленко, 2018
(О Институт программных систем имени А. К. Айламазяна РАН, 2018
DO| 10.25209/2079-3316-2018-9-1-85-108
-
• управляемость процессов, контроль состояния частей;
-
• автоматизация процессов;
-
• модульность архитектуры;
-
• ориентация на простоту решений.
Наиболее критичные для информационных систем случаи — отказы целых вычислительных узлов, что приводит к необходимости переконфигурирования вычислительной сети. Далее предлагается обзор решений, используемых для обеспечения отказоустойчивости вычислительных процессов.
В системе «GRACE» [1] в случае отказа одного из узлов все вычисления, отправленные на него с других компьютеров, будут автоматически переданы на вычисление другим свободным узлам. Не менее важным является реагирование на появление дополнительных ресурсов во время вычислений. В «GRACE» все вычислительные ресурсы образуют иерархию ресурсов, для каждого уровня которой динамически вычисляется доступная в ней свободная вычислительная мощность. В случае появления (подключения) нового компьютера происходит динамическая реконфигурация иерархии вычислительных ресурсов, алгоритм внешнего планирования начинает учитывать вновь появившиеся узлы.
Одним из возможных подходов к повышению отказоустойчивости является дублирование вычислений и важных вспомогательных функций, например, функций хранения данных; гранулярный характер решаемых задач может позволять вводить дублирование вычислений для того, чтобы одни и те же задачи выполнялись на нескольких независимых узлах [2] . Другой подход позволяет обеспечить отказоустойчивость за счет портальной работы с данными: в работе [3] задача разбивается на подзадачи, между которыми организуются каналы связи. Порталы используются для фиксации переходов T-подзадач из одного вычислительного пространства в другое. В случае потери связи с узлом или выхода последнего из строя портал содержит именно те T-функции, что необходимо вычислить заново. Планировщик старается пересылать промежуточные функции на промежуточные узлы, а на роль последних выдвигает наиболее надежные. Тем не менее, и промежуточные узлы могут выйти из строя. Если выведен из строя промежуточный узел квази-иерархии, то его подчиненные узлы пытаются найти свое место у следующего вышестоящего лидера и т.д.
В работе [4] рассмотрено динамическое распределение запросов на использование функциональных ресурсов, рассредоточенных по узлам вычислительной системы, определены рациональные по производительности и надежности варианты размещения этих ресурсов. Проведена оценка отказоустойчивости и производительности сравниваемых конфигураций при реализации динамического распределения запросов через канал распределенной вычислительной сети, когда в процессе решения задачи могут формироваться запросы, каждый из которых требует доступ к нескольким ресурсам разного типа.
Исследование [5] рассматривает отказоустойчивую многопроцессорную систему с непрерывным взаимным контролем работоспособности вычислительных модулей. На основе принципов характеризационного анализа получены необходимые и достаточные условия, при выполнении которых для заданной степени отказоустойчивости структура межмодульных диагностических связей обеспечивает локализацию всего множества неисправных вычислительных модулей.
В работе [6] введено понятие d-ограниченной компоненты связности графа вычислительной системы. Исследованы функции отказоустойчивости кольцевой и полносвязной структур системы, ограничивающие область определения этой функции для структур, промежуточных в отношении их степени. Постановка задачи анализа структурной отказоустойчивости вычислительной системы, представленная в работе, впервые рассматривает в качестве критических параметров работоспособности минимально допустимый размер компоненты связности графа вычислительной системы и ее предельный диаметр. Дано определение структурно отказоустойчивой системы, проведено исследование полярных в отношении связности кольцевой и полносвязной структур.
В работе [7] предложена следующая архитектура. Для обнаружения отказов ресурса и дальнейшего восстановления совместно работают диспетчер восстановления и мониторы ресурсов. Мониторы ресурсов следят за состоянием ресурсов, периодически опрашивая ресурсы с использованием библиотек ресурсов.
Опрос проводится в два этапа: коротким запросом «LooksAlive» и более долгим и детальным запросом «IsAlive». Когда монитор ресурсов обнаруживает отказ ресурса, он извещает об этом диспетчер восстановления и продолжает следить за ресурсом. Диспетчер восстановления поддерживает ресурсы и рабочее состояние групп ресурсов. Он также отвечает за выполнение восстановления, когда ресурс отказывает, и вызывает монитор ресурсов в ответ на действия пользователя или на отказы. После обнаружения отказа ресурса диспетчер выполняет действия по восстановлению, которые включают либо перезапуск ресурса и зависящих от него ресурсов, либо перемещение целой группы ресурсов на другой узел. В процессе восстановления после отказа группа рассматривается как единое целое, чтобы зависимости ресурсов были правильно восстановлены.
В публикации [8] предлагается в вектор состояния отдельных узлов добавить «маску активности» узлов, формируемую локально на каждом узле по факту получения вектора состояния от других узлов системы. Таким образом, кроме сигнала извещения об активности, формируемого и отправляемого самим узлом, контролируется физическая доступность данного узла и, соответственно, физическая целостность канала связи. Функции запуска, останова, контроля состояния задач, запускаемых на конкретном узле распределенной системы управления, возлагаются на данный узел. Однако, для успешного выполнения этих функций следует учитывать состояние системы в целом, что в децентрализованной системе приводит к необходимости выделения функции арбитра системы.
На основании текущей информации о состоянии системы арбитр дает команды узлам на запуск и останов процессов. Функция арбитра является переходящей. Для каждой задачи в конфигурации системы описывается, на каких узлах задача может запускаться, в какой последовательности, также фиксируется количество одновременно запущенных в системе экземпляров данной задачи. При первоначальном запуске задачи арбитр подает соответствующую команду на первый активный узел из очереди приоритетов для данной задачи, на последующие активные узлы из очереди — для запуска остальных экземпляров задачи. В случае пропадания одного из узлов из системы выдается команда на запуск задачи на следующем по приоритету активном узле, на котором данная задача еще не запущена. При восстановлении активности выведенного из системы узла арбитр выдает команду на останов всех экземпляров задачи, а затем — на запуск с учетом изменений в очереди узлов, т.е. со сдвигом к ее началу, что обеспечивает обратную миграцию задач на восстановленный узел.
В исследовании [9] рассматриваются вопросы, связанные с проведением расчетов в распределенных вычислительных системах, компоненты которых подвержены отказам. В работе приводятся: определения системы, сбоя, ошибки, отказа и модели сбоя; наиболее важные результаты исследований отказов в параллельных вычислительных системах, в том числе с большими группами дисков; основные существующие методы восстановления и распространенные программные реализации обеспечения отказоустойчивости. Развивается подход обеспечения отказоустойчивости на уровне пользователя. Данный подход требует непосредственного участия разработчика прикладной программы в реализации метода обеспечения отказоустойчивости, в частности в формировании контрольных точек и процедур восстановления. Предложена схема сохранения в памяти вычислительных узлов данных прикладной программы, формирующих согласованную глобальную контрольную точку. В ее рамках осуществляется дублирование локальных контрольных точек, что позволяет восстановить вычислительный процесс, если число отказов не превосходит допустимого для данной схемы уровня.
В рамках С++-библиотеки «T-Sim» создан отдельный тип переменных — неготовые переменные с заданным временем жизни [10] . Этот тип обладает всеми свойствами неготовой переменной, для него определена сериализация, что позволяет корректно оперировать переменными данного типа в распределенной памяти. Но, в отличие от обычной неготовой переменной, в шаблонных параметрах данного типа можно указать еще и время жизни такой переменной. Обычная неготовая переменная имеет два состояния: «готова» (и тогда значением данной переменной является вычисленное значение) и «не готова», неготовая переменная со временем жизни имеет третье, дополнительное состояние — результат до сих пор не вычислен, а время жизни истекло. Недостатком подхода является сложность применения в случае неравновесных гранул параллелизма, которые, к примеру, могут быть порождены при рекурсивном вычислении.
В случае перехвата отказа одного из вычислительных узлов все оставшиеся активными узлы удаляют адрес данного узла из списка доступных для проведения вычисления и выполняют повторную посылку тех задач, которые были на него отправлены. Такой подход позволяет обеспечить отказоустойчивость даже для задач с неравновесными гранулами параллелизма, к тому же использование данного подхода позволяет довести до конца обработку задач, которые были направлены на отказавший узел, а во время вычисления на узле случился сбой, т.к. после того, как сбой будет обнаружен, задача будет заново перенаправлена на другой узел. Недостатком такого подхода является наличие высоких накладных расходов на сохранение задач и требуемой оперативной памяти на поддержание списка задач. Достоинством является движение в сторону локальной синхронизации, т.к. каждый узел помнит те задачи, для которых было проведено локальное назначение.
В диссертационной работе [11] разработаны модели формирования оптимальных модульных систем на основе мультиверсионной программной архитектуры, обеспечивающие распределение мульти-версионных процедур по модулям программной системы с учетом заданных требований и достижение требуемой надежности системы. Разработана и программно реализована среда исполнения на базе компонентной архитектуры для распределенной мультиверсионной системы, которая позволяет подключать к среде исполнения любое количество программных модулей, распределяя вычислительную нагрузку на множество машин.
В диссертационной работе [12] создан метод оперативного пере-размещения программ в отказоустойчивых мультикомпьютерных системах, использующий диагональное распределение скользящего резерва непосредственно в матрице процессоров. Метод позволяет минимизировать время межпроцессорного обмена данными путем целенаправленного пошагового снижения отклонения указанного времени от нижней оценки наибольшей частной коммуникационной задержки, определяемой исходя из длин заранее формируемых (статических) маршрутов передачи данных в присутствии неоднородностей, обусловленных отказами физической структуры системы. Разработан аппаратно-ориентированный алгоритм, в рамках которого выполняется поиск резервного модуля для замещения отказавшего процессора на множестве ближайших к отказу резервных модулей. Алгоритм позволяет снизить время поиска нового варианта размещения программ в системе после возникновения отказа.
В исследовании [13] предлагается асинхронная отказоустойчивая распределенная система, которая на основе собираемой статистики и требований пользователя принимает решения об использовании той или иной оптимизации. Кроме того, собираемая информация позволяет системе подбирать оптимальные параметры используемых алгоритмов. Проблема миграции задач решается следующим образом. Вводится дополнительная системная служба управления задачами. Эта служба хранит информацию об идентификаторе задачи и соответствующей ей группе. При изменении состава группы эта информация обновляется. Если некоторый клиент после длительного отсутствия коммуникаций теряет связь с группой, вследствие ее полного или частичного изменения, он может обратиться с запросом к этой службе и получить адреса новых членов этой группы. Естественно, возникает проблема с поиском самой этой службы и ее миграцией. Для этого каждый вычислительный узел хранит идентификаторы физических процессоров, входящих в состав виртуального процессора, на котором работает служба [14].
Следует упомянуть об универсальном программном обеспечении для повышения отказоустойчивости грид-систем «HPC4U» [15 , 16] . Целью группы разработчиков является расширение потенциала использования грид-систем для решения сложных задач путем разработки компонентов программного обеспечения, реализующих надежную и достоверную среду выполнения грид-приложений, и увязки этого с соглашениями сервисного уровня (Service Level Agreements, SLA) и с промышленными кластерами. Программное обеспечение позволяет прозрачным образом добавлять в приложения для кластеров точки синхронизации, выполнять миграцию задач.
В цикле работ о системе «Dryad» [17 –20] рассказывается о среде исполнения распределенных приложений, которая берет на себя следующие функции: планирование и управление распределенными заданиями; управление ресурсами; обеспечение отказоустойчивости; мониторинг. Задание в «Dryad» представляет собой направленный ациклический граф, где вершины представляют собой программы, а ребра графа — каналы данных. Этот логический граф отражается исполняемой средой на физические ресурсы, находящиеся в кластере. В общем случае количество вершин в графе превышает количество физических вычислительных узлов в кластере.
«HTCondor» [21] – специализированная система управления нагрузкой на вычислители. Поддерживает работу с очередями, приоритезацию задач, политики планирования, мониторинг и управление ресурсами. При недоступности удаленной машины осуществляется миграция задач на другие вычислители, это выполняется за счет использования механизма контрольных точек. В Linux-системах для их создания используется модуль «BLCR», позволяющий осуществлять сохранение полного контекста процесса и его дальнейший перезапуск. «HTCondor»
и «BLCR» в настоящее время не имеют поддержки режима отказоустойчивости для программ с регулярными межпроцессными обменами данных, что существенно ограничивает применимость такого подхода. Однако, использование библиотек, подобных «NR-MPI» [22] , позволяет обойти данное ограничение. «NR-MPI» имеет набор дружественных программисту программных интерфейсов резервного копирования. Проведенные эксперименты показывают, что библиотека позволяет продолжить вычислительный процесс без перезапуска, при этом накладные расходы оказываются небольшими даже при использовании десятков тысяч вычислительных ядер.
Функция динамического переконфигурирования вычислительной сети крайне востребована в ситуации, когда в счете принимают участие десятки, сотни и даже тысячи компьютеров. Программное обеспечение, предназначенное для работы над сложными математическими и прикладными задачами, требует использования огромного числа вычислительных устройств, которые могут непредсказуемо выходить из строя. Далее будет описано решение, ориентированное на крупногранулярный параллелизм задач и коренным образом отличающееся от ранее известных подходов.
-
1. Внутреннее устройство вычислительного ядра
В основе предлагаемой системы организации вычислений лежит распределенная NoSQL СУБД Apache Cassandra [23] , обеспечивающая механизмы отказоустойчивого хранения и автоматической репликации данных, что позволяет обеспечить отказоустойчивый режим работы при решении прикладных задач. Общая архитектура представлена на рис. 1. Все данные, обрабатываемые в ходе решения прикладной задачи (задач), пользователя хранятся в СУБД, также, как и внутренние состояния модулей, вычислителей и подсистемы диспетчеризации. Фактически, СУБД используется не только как хранилище данных, но и как «очередь сообщений», обеспечивая реализацию механизмов информационного обмена и взаимодействие между отдельными элементами системы. Благодаря использованию подобного подхода повышается отказоустойчивость хранения данных и, соответственно, надежность вычислительной среды.
Опишем элементы программной системы и принципы их функционирования. Основными компонентами разработанной системы
Графический интерфейс пользователя
-
1. Средства визуального проектирования задач 2. Средства когнитивного отображения информации
Распределенная СУБД
-
1. Описание задач пользователей
-
2. Состояние системы диспетчеризации нагрузки
-
3. Ресурсы
-
3.1. Обрабатываемые данные
-
3.2. Контексты вызова программных модулей
-
-
4. Информационные сообщения о ходе выполнения задач/состоянии системы
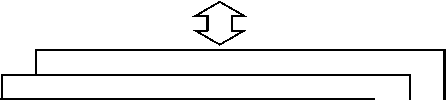
Вычислитель
Аппаратные ресурсы:
-
1. Многоядерные CPU
-
2. GPU
Алгоритмическое обеспечение:
-
1. Загружаемые программные модули обработки данных
-
2. Коммуникационная среда модулей
-
3. Кэш ресурсов
-
4. Подсистема диспетчеризации нагрузки
Рис. 1. Общая архитектура системы распределенных вычислений являются ресурсы, программные модули обработки данных, вычислитель, диспетчер распределения нагрузки, файлы описания прикладной задачи, база данных в СУБД. Одной из основных сущностей системы является понятие ресурса. Ресурс (Resource) — это данные, обрабатываемые в ходе решения прикладной задачи пользователя. Формально, ресурс представляет собой пару <идентификатор, значение>, при этом ««идентификатор» — уникальный ключ, а «значение» — массив байт, хранящий произвольные данные в сериализованном виде. Подобное представление соответствует отображению данных в NoSQL-системах, хранящих данные в виде пар «ключ-значение».
Явная типизация данных отсутствует, задача их корректной интерпретации ложится на разработчика модулей обработки данных. Программисту предлагается использовать структуры-дескрипторы. Дескриптор хранит список уникальных имен (полей ресурса) и соответствующие им идентификаторы, являющиеся ключами для доступа к пользовательским данным, сохраненным в базе данных (БД). Иерархическая структура ресурса, описываемая с использованием дескриптора, может быть изменена в ходе обработки данных модулями, могут быть добавлены новые поля или удалены существующие, что также позволяет частично обойти ограничение Apache Cassandra на максимальный размер одного экземпляра пользовательских данных (два гигабайта).
Важным элементом разработанной системы является понятие модуля обработки данных. Модуль (Plugin) — это программная реализация некоторой группы функции обработки данных (ресурсов). Для каждого модуля определен «контекст вызова» и дополнительная метаинформация, используемая в системе диспетчеризации нагрузки для управления процессом вычислений. Контекст вызова представлен структурой, аналогичной описанному ранее ресурсу и дополнительной метаинформацией, представленной в виде описания модуля в формате xml. В процессе работы модуля контекст может изменяться, там, к примеру, могут быть сохранены важные данные, для восстановления которых требуется длительное время. Контексты сохраняются в базе данных в транзакционном режиме, таким образом при сбое уже не придется повторно вычислять эти данные. Модули могут осуществлять графическую визуализацию тех или иных данных, для вызова таких программных функций разработан специальный интерфейс программирования.
Каждый модуль имеет множество каналов передачи данных, посредством которых он может получать или отсылать данные, взаимодействуя с другими модулями. Понятие канала (Channel) — удобная абстракция, обеспечивающая идентификацию поступающих на обработку данных, что упрощает программную реализацию модулей.
Для модулей, использующих GPGPU-технологии, ядро системы обеспечивает асинхронный вызов функций обработки потоков данных, привязанных к каналам связи, на узлах с установленными графическими ускорителями (видеокартами). На каждом запуске такой функции модулю сообщаются уникальные идентификаторы карт, которые могут быть использованы для организации вычислений. Ускорители в рамках системы считаются неразделяемым ресурсом, диспетчер нагрузки планирует исполнение задач так, чтобы обеспечить монопольный доступ. Однако, идентификаторы представляют собой лишь строки, программист, реализующий прикладной модуль, сам решает, как эти строки интерпретировать, какую технологию использовать (CUDA, OpenCL или какую-то другую). При желании можно запустить множество независимых потоков обработки ресурсов, поступающих по каналам передачи данных, используя для этого систему всего лишь с одним ускорителем вычислений.
Вычислитель (Worker) — программный компонент системы, обеспечивающий дополнительный уровень абстракции над аппаратным уровнем. Представляет собой реализацию пула потоков, способного загружать и выполнять код, реализованный в программных модулях, в соответствии с указаниями диспетчера распределения нагрузки. Вычислители, запущенные на доступном оборудовании, образуют вычислительную сеть. Управление ходом вычислений осуществляется диспетчером распределения нагрузки, данную роль может принять любой из активных вычислителей. Распределение роли управляющего узла повышает отказоустойчивость системы. В ходе инициализации вычислитель сообщает системе диспетчеризации о доступных аппаратных ресурсах (количество вычислительных ядер, идентификаторы GPU). Эта информация используется диспетчером распределения нагрузки при назначении задач.
Для обеспечения отказоустойчивости вычислители постоянно (по таймеру) сообщают диспетчеру о своем состоянии, в случае, если подобные сообщения не поступают длительное время, диспетчер принимает решение о перераспределении задач. Вычислители поддерживают локальный LRU-кэш для хранения запрошенных из БД ресурсов, что позволяет уменьшить количество запросов к БД и объем передаваемой по сети информации. Особым типом вычислителя можно считать вычислитель, запущенный на стороне клиента, ресурсы подобных вычислителей не распределяются автоматически и могут быть использованы лишь для запуска определенного пользователем списка модулей, в том числе модулей визуализации.
Диспетчер распределения нагрузки (Scheduler) предназначен для генерации управляющих команд и распределения задач между вычислителями. Новые задачи и управляющие команды порождаются в ходе обработки прикладной задачи по факту возникновения в выходных каналах модулей новых ресурсов или возникновения особого состояния системы (например, восстановления работоспособности после сбоя). Диспетчер обеспечивает функционирование схемы решения задачи, определяя, на каких вычислителях будет произведена обработка данных, в соответствии с заданными ограничениями, в том числе используя информацию об ограничениях на распределение модулей по вычислительным узлам; метаинформацию модуля, описывающую принцип его функционирования; информацию о доступных аппаратных ресурсах; приоритеты модулей. Запуск каждого модуля, входящего в схему решения задачи считается атомарной операцией (транзакцией) и в случае отказа узла происходит отмена всех назначенных ранее вычислителю задач и их перераспределение.
Файл описания прикладной задачи хранит информацию о требуемых для решения задачи модулях, их настройках и определенных пользователем каналах передачи данных. Структурно описание задачи состоит из двух основных секций: секции описания модулей (определены тегом
Состояние системы, включая описание пользовательских задач, текущее состояние системы диспетчеризации, обрабатываемые в ходе решения задач данные и информационные сообщения, сохраняется в распределенной СУБД в виде множества таблиц. Все информационные сообщения о функционировании системы и ходе решения задач пользователей сохраняются в БД, все сообщения снабжены временными метками и имеют привязку к уникальному идентификатору задачи, что позволяет системе функционировать в многопользовательском режиме.
Пользователь сам строит схему задачи, используя принципы визуально-блочного проектирования. В состав разработанной системы входят
-
• вычислительное ядро для работы в гетерогенной вычислительной среде [24] ;
-
• программные модули предварительной и нейросетевой обработки данных;
-
• универсальный графический интерфейс [25] , дополненный функциональной поддержкой отказоустойчивого вычислительного ядра (см. рис. 2, 3 и 4) .
Обобщая, перечислим основные особенности системы, так или иначе связанные с реализованной схемой обеспечения отказоустойчивости:
-
• для того, чтобы вычислительное ядро могло отличать одну сессию от другой, при инициализации задания передается уникальный идентификатор сессии, позволяющий не только снимать строго определенную задачу (прекращать счет), но и подключаться к ранее запущенным задачам;
-
• функции визуализации, в том числе когнитивной, исполняются непосредственно вычислительными модулями, а не основным графическим интерфейсом;
-
• вычислительное ядро на уровне каналов передачи данных работает с нетипизированными данными; ядро не формирует программных низкоуровневых каналов передачи данных, модули получают лишь те поля «передаваемых» ресурсов, что им необходимы, строго через прикладной интерфейс базы данных Apache Cassandra, то есть имеется поддержка стримминга данных.
-
2. Когнитивная визуализация в составе отказоустойчивой системы
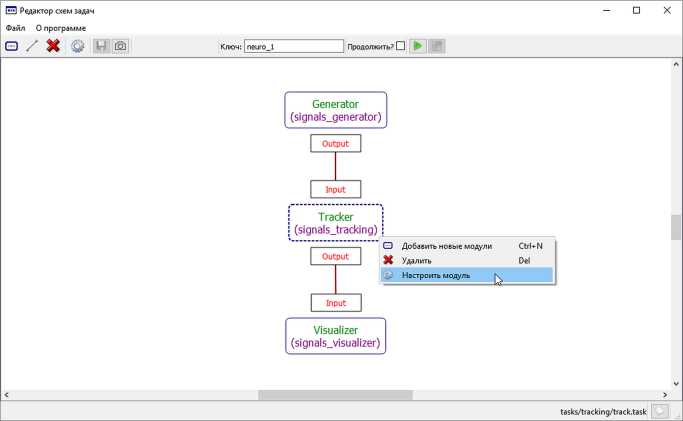
Рис. 2. Главное окно графического интерфейса системы
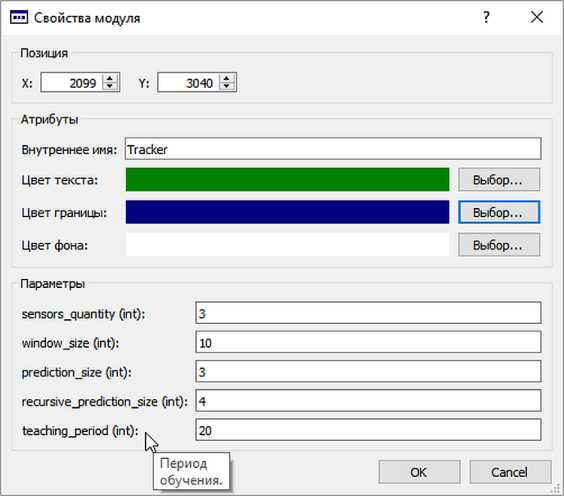
Рис. 3. Форма настроек модуля
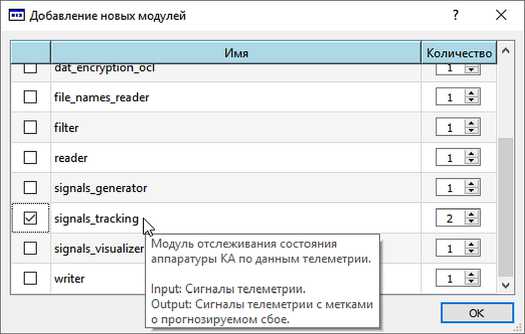
Рис. 4. Форма добавления новых модулей в схему
Актуальность технологии когнитивной визуализации обуславливается необходимостью оперативной оценки контролируемых ситуаций по данным для поддержки принятия решений человека-оператора. Перспективным направлением исследований служит когнитивная визуализация многомерных данных специальными средствами интерфейса, позволяющая оперативно обнаруживать нештатные ситуации. Человеко-машинное взаимодействие строится на базе технологий образного представления больших объемов информации контролируемых объектов, способствующих быстрому принятию решений. Результатом внедрения когнитивной графики является повышение эффективности информационной поддержки лица, принимающего решения.
Использование методов обеспечения отказоустойчивости положительным образом сказывается на поддержке лиц, принимающих решения, так как система обеспечивает бесшовный режим работы пользователя. Например, модуль визуализации может интерактивно подгружать данные от модулей, осуществляющих обработку целевых данных. В случае выхода из строя тех или иных вычислительных узлов, выполняющих обработку данных, процесс визуализации в рамках отказоустойчивой системы не прерывается. Таким образом, когнитивную визуализацию можно считать индикатором работоспособности
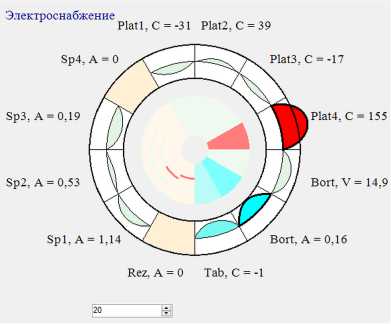
Рис. 5. Мониторинг состояния подсистем космического аппарата
IPrdl, A=0
рассматриваемой системы.
На рис. 5 приведены примеры когнитивных образов, получаемых от соответствующих модулей визуализации в составе разработанной системы, отображающих состояния подсистем исследованного в рамках работы космического аппарата [26 –28] . На рис. 6 приведен скриншот модуля визуализации ишемизированного мозга лабораторного животного (крысы), где программно выделенные фрагменты ишемического поражения мозга представлены отдельными 3D-объектами [29, 30] . На рис. 7 — результат работы нейросетевого модуля поиска целевых объектов на панорамном изображении дистанционного зондирования Земли [31] .
Несмотря на то, что приведенные когнитивные образы затрагивают разные прикладные области, все они отражают процессы обработки информации реального времени в динамике и служат индикатором работоспособности вычислительной системы при своем непрерывном воспроизведении.
Заключение
Новая программная система имеет три основные составляющие: универсальное отказоустойчивое вычислительное ядро; графический интерфейс с функциями создания схем вычислительных задач из ранее разработанных библиотечных модулей; подсистема визуализации, позволяющая исполнять процессы визуализации, в том числе когнитивной, на заранее определенных узлах. Программная система

Рис. 6. 3D-модель ишемизированного мозга крысы
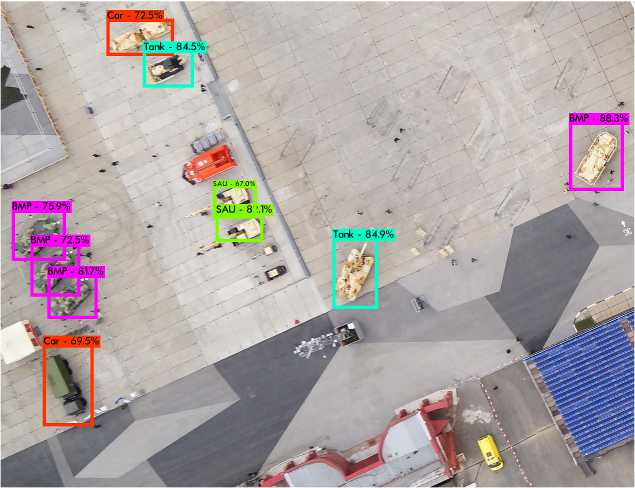
Рис. 7. Визуализация результатов поиска целевой техники военного назначения апробирована на широком ряде вычислительных задач и показала свою эффективность и удобство использования.
Проведенные испытания показали полную защищенность от сбоев. Вычисления идут вплоть до полного отключения всех компьютеров вычислительной сети, решение поставленных задач продолжается при восстановлении доступа к базе данных.
Список литературы Отказоустойчивая система организации высокопроизводительных вычислений для решения задач обработки потоков данных
- В. А. Васенин, В. A. Роганов. GRACE: распределенные приложения в Internet//Открытые системы, 2001, №5. С. 29-33.
- Е. Н. Новиков, Р. Р. Валеев. Резервирование сервера технологических данных -путь к созданию отказоустойчивых технологических серверов//Промышленные АСУ и контроллеры, 2002, №7. С. 14-18.
- А. Н. Фирсов. Архитектура распределенной системы устойчивой к произвольным отказам//Девятая международная конференция-семинар "Высокопроизводительные параллельные вычисления на кластерных системах", 2009.
- M. Hovestadt. Fault tolerance mechanisms for sla-aware resource management//Parallel and Distributed Systems. Proceedings. 11th International Conference on. vol. 2 (Fukuoka, Japan, July 20-22, 2005).
- F. Heine, M. Hovestadt, O. Kao, A. Keller. SLA-aware Job Migration in Grid Environments//Grid Computing: New Frontiers of High Performance Computing, Elsevier. С. 185-201.
- M. Isard, M. Budiu, Y. Yu, A. Birrell, D. Fetterly. Dryad: Distributed Data-parallel Programs from Sequential Building Blocks//Proceedings of the 2007 Eurosys Conference (Lisboa, Portugal, March 21-23, 2007).
- Y. Yu, M. Isard, D. Fetterly, M. Budiu, Ú. Erlingsson, P. K. Gunda, J. Currey. DryadLINQ: A System for General-Purpose Distributed Data-Parallel Computing Using a High-Level Language//OSDI'08: Eighth Symposium on Operating System Design and Implementation USENIX (San Diego, California, USA, December 8-19, 2007).
- J. Ekanayake, T. Gunarathne, G. Fox, A. S. Balkir, C. Poulain, N. Araujo, R. Barga. DryadLINQ for Scientific Analyses//e-Science '09. Fifth IEEE International Conference on (Oxford, UK, December 9-11, 2009).
- F. McSherry, T. Rodeheffer. Using DryadLINQ for Large Matrix Operations, Microsoft Technical Report, 2011, MSR-TR-2011-140.
- D. C. Aiftimiei, M. Antonacci, S. Bagnasco, T. Boccali, R. Bucchi, M. Caballer, A. Costantini, G. Donvito, L. Gaido, A. Italiano. Geographically distributed Batch System as a Service: the INDIGO-DataCloud approach exploiting HTCondor//Journal of Physics: Conference Series, 2017.
- G. Suo, Y. Lu, X. Liao, M. Xie, H. Cao. NR-MPI: A non-stop and fault resilient mpi supporting programmer defined data backup and restore for e-scale super computing systems//Supercomputing frontiers and innovations, 2016, №1. С. 4-21.
- S. Kalid, A. Syed, A. Mohammad, M. N. Halgamuge. Big-Data NoSQL Databases: A Comparison and Analysis of "Big-Table", "DynamoDB", and "Cassandra"//Proceedings of the IEEE 2nd International Conference on Big Data Analysis (ICBDA'17) (Beijing, China, March 10-12, 2017). С. 89-93.
- В. П. Фраленко. Универсальный графический интерфейс визуального проектирования параллельных и параллельно-конвейерных приложений//Программные системы: теория и приложения, 2016, №3. С. 45-70.
- Н. С. Абрамов, А. А. Талалаев, В. П. Фраленко, В. М. Хачумов, О. Г. Шишкин. Высокопроизводительная нейросетевая система мониторинга состояния и поведения подсистем космических аппаратов по телеметрическим данным//Программные системы: теория и приложения, 2017, №3. С. 109-131.
