Parus - синтаксически аннотированный корпус русского языка

Автор: Власова Наталья Александровна, Трофимов Игорь Владимирович, Сердюк Юрий Петрович, Сулейманова Елена Анатольевна, Воздвиженский Илья Николаевич
Журнал: Программные системы: теория и приложения @programmnye-sistemy
Рубрика: Искусственный интеллект, интеллектуальные системы, нейронные сети
Статья в выпуске: 4 (43) т.10, 2019 года.
Бесплатный доступ
В статье представлен новый аннотированный корпус русского языка PaRuS (Parsed Russian Sentences). Корпус имеет объем свыше 2,5 миллиардов токенов и предназначен для решения задач компьютерной лингвистики методами машинного обучения. PaRuS состоит из предложений русского литературного языка. Каждое предложение снабжено лингвистической разметкой: морфологической в формате MULTEXT-East и синтаксической в нотации СинТагРус. В статье рассмотрена методология создания корпуса, описан гибридный лингвистический конвейер PaRuS_pipe, разработанный для порождения разметки. Обсуждаются вопросы качества аннотирования языкового материала в корпусе PaRuS, выполнена оценка морфологического анализатора конвейера PaRuS_pipe по методологии соревнования MorphoRuEval-2017.
Компьютерная лингвистика, корпусная лингвистика, русский язык, языковой корпус, разметка, морфология, синтаксис
Короткий адрес: https://sciup.org/143169807
IDR: 143169807 | УДК: 004.89:81'322.2 | DOI: 10.25209/2079-3316-2019-10-4-181-199
Parus - syntax annotated Russian corpus
In this article we present a new annotated Russian language corpus named PaRuS (Parsed Russian Sentences). The corpus containing over 2.5 billion tokens is intended for use in computer linguistics tasks involving machine learning methods. PaRuS is a collection of annotated literary Russian sentences. Our linguistic annotation includes morphological features in MULTEXT-East format, and syntactic information in SynTagRus notation. We consider the methodology of corpus creation and describe PaRuS_pipe, a hybrid linguistic pipe developed for sentence annotation. We also discuss the quality of linguistic annotation in PaRuS and provide an assessment of the PaRuS_pipe morphological analyzer, according to the MorphoRuEval-2017 competition methodology.
Текст научной статьи Parus - синтаксически аннотированный корпус русского языка
Всё более широкое распространение методов машинного обучения в современной компьютерной лингвистике порождает потребность в больших объемах аннотированного в том или ином аспекте текстового материала. Лингвистика «моделей» в разработках компьютерных систем постепенно уступает место лингвистике размеченных данных [1] .
В период доминирования «модельных подходов» аннотированные данные служили главным образом для исследовательских целей. Размечавшиеся вручную небольшие корпуса в полной мере отвечали этой потребности. Сейчас, когда основой компьютерной лингвистики
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 19-07-00779.
(О Н. А. Власова, И. В. Трофимов, Ю. П. Сердюк, Е. А. Сулейманова, И. Н. Воздвиженский, 2019
стали обучаемые алгоритмы, объем и репрезентативность корпуса становятся ключевыми факторами, определяющими качество решения задачи.
Корпуса большого объема создаются автоматически и полуавтоматически. Качество разметки в корпусе зависит от методологии его создания. Вопрос о том, какой должна быть эта методология, — отдельный научный вопрос, не имеющий очевидного ответа. Как подобрать и подготовить текстовый материал, чтобы имеющийся арсенал средств автоматического аннотирования позволил получить приемлемый результат? Как выявить и устранить систематические ошибки аналитических средств? Как обеспечить верификацию, одновременно минимизируя трудоемкость? Сложность такого рода проблем растет вместе с увеличением объема корпуса.
Еще один фактор, во многом определяющий свойства создаваемого корпуса, заключается в выборе — для каждого уровня разметки — теоретической базы, на основе которой будет выполняться аннотирование. Пока этот выбор не очевиден, имеет смысл создавать корпуса на основе разных теоретических принципов.
Таким образом, для современной компьютерной лингвистики, ориентированной на машинное обучение, актуальны:
-
(1) создание корпусов большого объема, различающихся лежащими
в основе разметки теоретическими подходами;
-
(2 ) поиск эффективных методов создания больших корпусов.
В данной работе описан опыт создания большого русскоязычного корпуса PaRuS с морфологической и синтаксической разметкой. Корпус состоит из предложений русского литературного языка. Объем — свыше 2,5 миллиардов токенов (более 150 миллионов предложений). Синтаксическая разметка корпуса выполнена в нотации СинТагРус . Лежащий в ее основе формализм создан ведущей отечественной школой теоретической и компьютерной лингвистики в рамках проекта ЭТАП [2] .
Дальнейший материал изложен в следующем порядке. В первой части статьи приводится краткий обзор аннотированных корпусов русского языка, вторая посвящена особенностям корпуса PaRuS , в третьей описан метод его создания.
-
1. Аннотированные корпуса русского языка
-
2. Корпус русского языка PaRuS
Требованию большого объема в настоящий момент удовлетворяют несколько корпусов русского языка: Araneum Russicum [3 , 4] , RuTenTen [5] , ГИКРЯ [6] , Taiga [7 , 8] . В каждом из перечисленных корпусов присутствует морфологическая разметка.
Синтаксическая разметка в корпусах русского языка представлена далеко не так широко, как морфологическая. Между тем, для обучаемых алгоритмов синтаксическая информация может оказаться полезной. Так, например, первый корпус русского языка с синтаксической разметкой СинТагРус [9] , входящий в состав Национального корпуса русского языка [10] , несмотря на скромный по современным меркам объем, успешно применялся для тренировки алгоритмов машинного обучения. В частности, на его материале обучена русскоязычная модель синтаксического парсера MaltParser [11] ; решалась задача выявления границ сложных именных групп [12] .
Первым русскоязычным корпусом большого объема с синтаксической разметкой стал корпус Taiga . Корпус аннотирован в формате Universal Dependencies (UD) [15] — международном универсальном формате морфологической и синтаксической разметки, который был разработан для нивелирования различий в метаязыках описания синтаксической структуры, используемых для типологически различных языков.
Ответ на вопрос, могут ли UD -корпуса служить полноценной заменой корпусам, аннотированным в соответствии с «традиционными» национальными схемами, по-видимому, зависит от решаемой задачи и требует соответствующих исследований на параллельных корпусах (как, например, эксперименты с обучением парсеров для шведского языка [16] ).
Разметка в корпусе СинТагРус основана на системе синтаксических отношений, которая используется многоцелевым лингвистическим процессором ЭТАП [13 , 14] . В нотации СинТагРус задействовано, по разным источникам, от 67 [17] до 78 [18] типов синтаксических отношений, тогда как формат UD использует всего 40 синтаксических тегов [17] 1 . В качестве принципиального отличия между двумя подходами к синтаксической разметке мы бы отметили следующее: в UD тип зависимости определяется поверхностными признаками словоформ, тогда как нотация СинТагРус учитывает особенности модели управления подчиняющих сло в2.
С учетом всего сказанного, задача создания большого, объемом в несколько миллиардов токенов, корпуса с разметкой в нотации СинТагРус представляется актуальной.
При создании корпуса PaRuS преследовались две ключевые цели:
-
(1) обеспечение качественной лингвистической разметки (морфология и синтаксис);
-
(2 ) достижение объемов, отвечающих потребностям современных обучаемых аналитических алгоритмов.
Этим обусловлен ряд принятых при создании корпуса специфических методологических решений, речь о которых пойдет ниже.
Единицей языкового материала корпуса PaRuS является предложение. Предложение — это языковая единица, в рамках которой проявляются в полной мере морфологические и синтаксические свойства словоформ, а также семантика отдельных лексем и словосочетаний. Поэтому предложение можно использовать для получения полноценной информации об этих языковых единицах и соответствующих языковых уровнях.
Такое нестандартное для корпусной лингвистики решение имеет определенные преимущества по сравнению с традиционным подходом, когда единицей корпуса является текст. Во-первых, на стадии подготовки материалов для корпуса нет необходимости решать задачу определения границ текста. Это непросто, когда речь идет о комментариях к новостям, чатах в соцсетях, диалогах, электронной переписке — такие материалы всё чаще включаются в языковые корпуса для обеспечения репрезентативности.
Во-вторых, работа с предложениями позволяет использовать эффективные алгоритмы фильтрации языкового материала, не применимые к текстам. В частности, без последствий для целостности можно удалять из корпуса предложения, автоматическая обработка которых, вероятно, окажется неуспешной (подозрительно длинные токены, предложения на языках, отличных от русского, «странные» последовательности символов и т.п.).
В-третьих, отпадает необходимость рассмотрения вопросов, связанных с авторскими правами.
Недостатками выбора предложения в качестве единицы корпуса можно считать утрату метаданных и информации о структуре текста, потерю целостности дискурса. Однако для задач, которые предполагается решать с помощью корпуса PaRuS, такие потери не существенны.
Предложения, составляющие корпус русского языка PaRuS , получены из двух типов источников:
-
( а ) произведения художественной, научно-популярной, публицистической литературы, доступные онлайн;
-
( б ) новостные сообщения с нескольких десятков новостных сайтов.
-
3. Метод создания корпуса PaRuS
В PaRuS не включались предложения из блогов, социальных сетей, форумов, комментариев к новостям и т.п. Такие источники сложны для автоматического анализа, так как часто содержат символы и комбинации знаков, не применяющиеся в литературных текстах, предложения имеют специфическую синтаксическую структуру и пр. Кроме того, в таком языковом материале гораздо чаще, чем в редакционном, встречаются опечатки и ошибки, что требует дополнительных усилий по очистке. Таким образом, PaRuS состоит из предложений современного русского литературного языка.
Итак, корпус PaRuS — это большой морфологически и синтаксически аннотированный корпус предложений русского литературного языка. Объем корпуса в настоящий момент превышает 2,5 миллиардов токенов. Цель — более 5 миллиардов. PaRuS можно использовать для обучения алгоритмов, оперирующих в пределах предложения, таких как алгоритмы морфологического и синтаксического анализа, некоторые алгоритмы разрешения лексической неоднозначности, алгоритмы построения дистрибутивных моделей, обнаружения устойчивых словосочетаний и т.п. Данные и техническая документация корпуса PaRuS размещены по адресу
В методе создания корпуса PaRuS выделяется три крупных группы операций:
-
(1 ) отбор и подготовка текстов;
-
(2 ) лингвистическое аннотирование (разметка);
-
(3 ) дедупликация, фильтрация и перемешивание предложений. Рассмотрим подробнее каждую из них.
3.1. Отбор и подготовка текстов
Целью данного этапа обработки было получение материалов для корпуса в виде простых текстовых файлов в кодировке utf-8. Напомним, что корпус составлялся из текстов двух категорий: художественной и нехудожественной литературы, далее книг (а) и новостных сообщений (б). Каждая из категорий потребовала особой технологии селекции и предварительной обработки текстов.
Книги
Источником литературных произведений послужили открытые онлайн-библиотеки. Загрузка документов не представляла сложности, поскольку многие библиотеки публикуют резервные копии в виде архивов. Дальнейшая обработка включала:
– техническую обработку (форматы файлов, кодировки, разбор метаданных);
– жанровую фильтрацию;
– фильтрацию иноязычной литературы.
Жанровая фильтрация выполнялась при наличии указания на жанр в метаданных книги. В частности, исключались поэтические, драматургические произведения, детские сказки, религиозная литература, книги в жанре «фэнтези», юмор. Драматургические произведения, в силу их специфического оформления, исключались с целью снижения доли ошибок в синтаксической разметке корпуса. Детские сказки, религиозная литература и фэнтези описывают вымышленные миры; в таких произведениях встречается множество лексических новообразований, словосочетаний с нехарактерными отношениями между словами (фиолетовая листва, железная бумага и т.п.), что нежелательно, например, для дистрибутивного моделирования. Юмористические тексты изобилуют игрой слов. Поэтической речи свойственны нестандартный порядок слов, непроективные синтаксические конструкции и другие особенности, с которыми современные автоматические анализаторы справляются плохо.
Для фильтрации иноязычной литературы потребовалось реализовать следующую многоступенчатую процедуру определения языка текста.
1. Для первичной фильтрации использовалась метаинформация о языке текста, если она присутствовала в документе.
2. Затем применялся классификатор на базе n-граммной статистики [19]. Реализация — утилита mguesser3. Утилита позволила отфильтровать значительную долю иноязычной литературы, а также некоторые многоязычные тексты (в частности, документы с большим количеством цитат на иностранных языках).
3. Эксперименты показали, что n-граммного метода оказалось недостаточно. Так, mguesser иногда принимает тексты на белорусском, украинском, болгарском и других языках с кириллическим алфавитом за русскоязычные. Для решения этой проблемы был реализован специальный эвристический алгоритм, подсчитывающий в тексте количество слов, частотных в перечисленных языках, но отсутствующих в русском. Если число таких слов в тексте оказывалось выше установленного порога, то текст считался не русскоязычным и исключался из корпуса. Например, для определения текстов на украинском языке использовался поиск по таким высокочастотным в данном языке словам, как нi, цi, вiд, вже, оце, щось, тодi, менi, тобi, вiн, щоб, його, якщо. Для белорусского языка в качестве индикаторных слов были выбраны цi, калi, зусiм, яшчэ, вельмi, гэта, тады, надта, мяне, цябе. Для казахского языка — олар, быз, кайда, кашан, ондой, анау, онда, санда, сыз, казр, тагх, айт. Аналогичный прием применялся для фильтрации текстов на русском языке в дореформенной орфографии, на древнерусском и церковнославянском.
3.2. Лингвистическое аннотирование
Согласно грубой оценке, жанровая и языковая фильтрация привела к удалению более половины литературных произведений, загруженных из онлайн-библиотек.
Новостные сообщения
Новостные сайты, как правило, не размещают архивы новостных сообщений в расчете на их массовое скачивание. Поэтому подзадача загрузки новостных сообщений потребовала создания специализированного краулера. Мы воспользовались тем, что многие издания предоставляют доступ к новостной ленте в формате rss-каналов. Загрузка новостей осуществлялась небольшими (суточными) порциями в течение длительного промежутка времени (около 5 лет). Для отдельных сайтов использовались специальные процедуры коррекции URL новостного сообщения, чтобы получать не страницу новости в контексте новостного сайта, а содержащую меньше посторонней информации «версию для печати». Чтобы охватить больший исторический период, для одного информационного агентства был разработан специализированный краулер, позволивший загрузить новости, относящиеся к 1990–2015 годам.
В общей сложности таким мониторингом было охвачено более 100 новостных ресурсов (государственных и региональных, отечественных и переводных зарубежных, общетематических и специализированных).
Результатом загрузки новостей были html-страницы, которые кроме новостного сообщения содержали постороннюю информацию (комментарии, элементы навигации по сайту, рекламу и т.п.). Страницы необходимо было очистить. Извлечение текста новости из html-страницы осуществлялось алгоритмом jusTex t4 [20] . Этот эвристический алгоритм имеет высокие показатели точности на наборах размеченных данных CleanEval и очень хорошие показатели полноты, не требует обучающего множества и прост в настройке. Мы использовали собственную реализацию алгоритма, которая, кроме очистки html-дерева, осуществляла конвертацию текста в кодировку utf-8.
Для порождения лингвистической разметки корпуса был создан гибридный конвейер PaRuS_pip e5, основанный на двух известных русскоязычных лингвистических процессорах: конвейере Шарова-Нивре [21] и UDPipe [22] . Новый конвейер решает следующие задачи:
– определение границ слов и предложений,
– морфологический анализ,
– синтаксический анализ.
Работая над PaRuS_pipe , мы проанализировали сильные и слабые стороны положенных в его основу конвейеров и с учетом этого попытались создать более эффективный аналитический инструментарий. Ведущая роль отводилась конвейеру Шарова-Нивре (далее Ш-Н ), а UDPipe использовался как вспомогательное средство. В частности для определения границ предложений мы использовали UDPipe , так как он имеет более совершенный алгоритм распознавания сокращений. Качественное решение этой задачи важно для успеха последующего синтаксического анализа. В морфологическом анализе UDPipe лучше распознаёт ряд граммем (например, признак «имя собственное»), а также частично компенсирует неполноту Ш-Н в части лемматизации.
Также в PaRuS_pipe реализована группа дополнительных модулей, служащих для:
– адаптации исходного текста к формату, с которым базовые конвейеры ( Ш-Н и UDPipe ) работают более успешно;
– коррекции в том или ином аспекте результатов базовых конвейеров.
Для повышения качества лемматизации был задействован словарный морфологический анализатор АОТ [23] , а также ряд эвристик для обработки слов, которые пишутся через дефис.
Структурная схема получившегося конвейера изображена на рисунке 1. Более подробное техническое описание каждого из модулей можно найти на сайте корпус а6 .
модуль предварительной обработки токенизатор и морфологический анализатор UDPipe

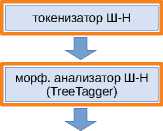
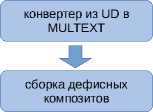
CoNLL конвертер

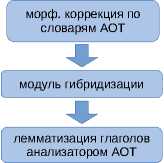


— модуль конвейера Шарова-Нивре
— модуль UDPipe
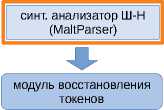
Рисунок 1. Структурная схема конвейера PaRuS_pipe
В нотационном отношении в PaRuS_pipe приняты следующие решения:
– в токенизации: дефисные композиты (светло-серый, слуга-азиат) представляются одним токеном;
– в морфологическом анализе:
используется нотация MULTEXT-Eas t7 [24] ;
– в синтаксическом анализе: строится дерево зависимостей в нотации СинТагРу с8 [14] ; количество типов синтаксических отношений — 76.
Качество морфологического анализа в PaRuS_pipe было оценено по методологии MorphoRuEval-2017. Опираясь на свежий обзор по автоматическому морфологическому анализу русского языка [25] , приведем оценки точности PaRuS_pipe в сравнении с TreeTagger (из Ш-Н ), UDPipe и современным нейросетевым алгоритмом rnnmorph [26] — таблицы 1 –2. Колонке 3-in-1 соответствует gold standard соревнований MorphoRuEval-2017 (он состоял из трех частей). Также для оценки использовались два более крупных набора размеченных данных (фрагменты ГИКРЯ и СинТагРус ), служивших обучающими множествами в ходе соревнований. Серые пустые ячейки соответствовали бы тестированию на обучающем множестве, поэтому значения в них не приводятся.
Таблица 1. Точность определения граммем по правилам MorphoRuEval-2017
|
Система |
3-in-1 |
Набор данных |
|
|
ГИКРЯ |
СинТагРус |
||
|
PaRuS_pipe |
90,73 |
90,54 |
90,40 |
|
rnnmorph |
96,28 |
93,17 |
|
|
TreeTagger |
89,88 |
89,69 |
88,97 |
|
UDPipe |
89,01 |
88,90 |
|
Таблица 2. Точность восстановления нормальной формы (независимо от успешности определения граммем)
|
Система |
3-in-1 |
Набор данных |
|
|
ГИКРЯ |
СинТагРус |
||
|
PaRuS_pipe |
97,89 |
97,69 |
97,10 |
|
rnnmorph |
95,28 |
94,79 |
|
|
TreeTagger |
92,56 |
92,22 |
90,68 |
|
UDPipe |
93,36 |
93,03 |
|
7
8
Из таблиц видно, что в задаче лемматизации новый конвейер превзошел даже самый современный алгоритм, хотя и уступает ему в задаче определения граммем (из числа тех, что оцениваются по методологии MorphoRuEval-2017).
Качество синтаксического анализа мы не оценивали самостоятельно. Согласно оценке [11] , проводившейся на корпусе СинТагРус (т.е. с идеальной морфологической разметкой), использованный в PaRuS_pipe синтаксический анализатор MaltParser может достигать показателей:
– 89% — точность установления синтаксического родителя (UAS, unlabeled attachment score),
– 82% — точность установления и родителя, и типа синтаксического отношения (LAS, labeled attachment score).
3.3. Дедупликация, фильтрация и перемешивание предложений
Проблема дублирования текстовой информации особенно остро стояла для новостных сообщений. Это связано с практикой цитирования новостной информации, а также спецификой современного стиля новостного сообщения (возврат к ранее опубликованной информации с целью напомнить читателю контекст события или обозначить связь с подобными событиями). Технически дедупликация выполнялась на уровне предложений. По тексту предложения вычислялась свертка на базе хэш-функции SHA-256. Уникальность свертки контролировалась в масштабе всего корпуса.
Фрагментарная верификация новостной части корпуса показала, что, несмотря на высокую эффективность алгоритма jusText, в очищенные тексты попало значительное количество посторонней информации. Кроме того, полезность некоторых предложений самого новостного сообщения также оказалась под вопросом. Например, краткие подписи к изображениям и фотографиям, имя и фамилия автора публикации, дата публикации и т.п. Для решения проблемы «бесполезных» предложений был создан специальный инструмент, позволявший специалисту формировать поисковые запросы для их обнаружения и выборочно удалять записи. В общей сложности это позволило отфильтровать около 750 тыс. предложений в новостной части корпуса. Также для повышения качества корпуса выполнено удаление предложений, в которых содержалась низкочастотная лексика. С этой целью был построен словарь лемм, встречающихся в корпусе, и подсчитаны их абсолютные частоты. На основании словаря был создан список низкочастотных слов (с частотой менее 4). В основном он состоял из опечаток и последовательностей символов, не являющихся словами. Все предложения, в которых встречалось хотя бы одно слово из списка низкочастотных, удалялись из корпуса. Это привело к удалению чуть более 2% предложений.
Последним шагом в создании корпуса было перемешивание предложений в случайном порядке. Такой прием позволил избежать необходимости рассмотрения правовых вопросов, связанных с текстами-источниками.
Заключение
В статье представлен новый корпус русского языка PaRuS , состоящий из предложений русского литературного языка, снабженных морфологической и синтаксической разметкой. Для создания корпуса был разработан гибридный конвейер PaRuS_pipe на основе двух существующих конвейеров — Шарова-Нивре и UDPipe . Итоги тестирования конвейера PaRuS_pipe показывают, что качество разметки языкового материала корпуса PaRuS достаточно высоко. Таким образом, новый корпус может быть успешно использован для задач компьютерной лингвистики.
Список литературы Parus - синтаксически аннотированный корпус русского языка
- С. Ю. Толдова, О. Н. Ляшевская. «Современные проблемы и тенденции компьютерной лингвистики (в зеркале 24-ой конференции по компьютерной лингвистике COLING 2012 Мумбаи)», Вопросы языкознания, 2014, №1, с. 120-145.
- Ю. Д. Апресян, И. М. Богуславский, Л. Л. Иомдин и др. Лингвистическое обеспечение системы ЭТАП-2, Наука, М., 1989, , 296 с. ISBN: 5-02-006572-2
- V. Benko. “Aranea: yet another family of (comparable) web corpora”, 17th International Conference TSD 2014 (Brno, Czech Republic, September 8-12, 2014), Lecture Notes in Computer Science, vol. 8655, eds. P. Sojka, A. Horák, I. Kope, K. Pala, Springer International Publishing, Switzerland, 2014, , pp. 257-264. DOI: 10.1007/978-3-319-10816-2_31 ISBN: 978-3-319-10815-5
- В. Бенко, В. Захаров. «Сверхбольшие корпусы русского языка: новые возможности и новые проблемы», По материалам ежегодной международной конференции «Диалог» (Москва, 1-4 июня 2016 г.), Компьютерная лингвистика и интеллектуальные технологии, т. 15(22), Изд-во РГГУ, М., 2016, с. 79-93 (англ., http://www.dialog-21.ru/media/3383/benkovzakharovvp.pdf http://www.dialog-21.ru/media/3383/benkovzakharovvp.pdf).
- M. Jakubicek, A. Kilgarriff, V. Kovar, P. Rychly, V. Suchomel. “The TenTen corpus family”, Int. Conf. on Corpus Linguistics (Lancaster, 2013) URL https://www.sketchengine.co.uk/wp-content/uploads/The_TenTen_Corpus_2013.pdf.
- В. И. Беликов, Н. Ю. Копылов, А. Ч. Пиперски, В. П. Селегей, С. А. Шаров. «Корпус как язык: от масштабируемости к дифференциальной полноте», По материалам ежегодной Международной конференции «Диалог» (Бекасово, 29 мая-2 июня 2013 г.), Компьютерная лингвистика и интеллектуальные технологии, т. 12 (19), Изд-во РГГУ, М., 2013, с. 84-95.
- Т. Шаврина, О. Шаповалова. «To the methodology of corpus construction for machine learning: ‘Taiga’ syntax tree corpus and parser» (Санкт-Петербург, 27-30 июня 2017 г.), Издательство СПбГУ, СПб., 2017, с. 78-84 (англ.).
- T. O. Shavrina. «Дифференциальный подход к построению веб-корпусов», По материалам ежегодной международной конференции «Диалог» (Москва, 30 мая-2 июня 2018 г.), Компьютерная лингвистика и интеллектуальные технологии, т. 17(24), Изд-во РГГУ, М., 2018 URL http://www.dialog-21.ru/media/4261/shavrina.pdf (англ.).
- Ю. Д. Апресян, И. М. Богуславский, Б. Л. Иомдин, Л. Л. Иомдин, А. В. Санников, В. З. Санников, В. Г. Сизов, Л. Л. Цинман. «Синтаксически и семантически аннотированный корпус русского языка: современное состояние и перспективы», Индрик, М., 2005, с. 193-214.
- В. А. Плунгян. «Зачем нужен Национальный корпус русского языка? Неформальное введение», Индрик, М., 2005, с. 6-20.
- J. Nivre, I. M. Boguslavskii, L. L. Iomdin. “Parsing the SynTagRus treebank of Russian”, 22nd International Conference on Computational Linguistics, COLING 2008 (18-22 August 2008, Manchester, UK), 2008, pp. 641-648.
- DOI: 10.3115/1599081.1599162
- M. Kudinov, A. Romanenko, I. Piontkovskaya. «Conditional random field in segmentation and noun phrase inclination on tasks for Russian», По материалам ежегодной Международной конференции «Диалог» (Бекасово, 4-8 июня 2014 г.), Компьютерная лингвистика и интеллектуальные технологии, т. 13 (20), Изд-во РГГУ, М., с. 297-306 (англ.).
- П. В. Дяченко, Л. Л. Иомдин, А. В. Лазурский, Л. Г. Митюшин, О. Ю. Подлесская, В. Г. Сизов, Т. И. Фролова, Л. Л. Цинман. «Современное состояние глубоко аннотированного корпуса русского языка (СинТагРус)», Труды Института русского языка им. В. В. Виноградова, т. 6, М., 2015, с. 272-299.
- I. Boguslavsky. “SynTagRus - a deeply annotated corpus of Russian”, English and French edition, eds. P. Blumenthal, I. Novakova, D. Siepmann, P. Lang, 2014, , pp. 367-380.
- ISBN: 978-3-631-64608-3
- J. Nivre, M.-C. de Marneffe, F. Ginter, Y. Goldberg, J. Hajic, Ch. D. Manning, R. McDonald, S. Petrov, S. Pyysalo, N. Silveira, R. Tsarfaty, D. Zeman. “Universal Dependencies v1: A multilingual treebank collection”, LREC 2016 (May 23-28, 2016, Portoro Slovenia), pp. 1659-1666.
- Ф. А. Антомонов. «Универсальные зависимости: сравнение синтаксического анализа для шведского языка», По материалам ежегодной международной конференции «Диалог» (Москва, 1-4 июня 2016 г.), Компьютерная лингвистика и интеллектуальные технологии, т. 15(22), Изд-во РГГУ, М., 2016, 7 с. (англ.).
- O. Lyashevskaya, K. Droganova, D. Zeman, M. Alexeeva, T. Gavrilova, N. Mustafina, E. Shakurova. Universal dependencies for Russian: a new syntactic dependencies tagset, 2016.
- DOI: 10.2139/ssrn.2859998
- I. Boguslavsky, S. Grigorieva, N. Grigoriev, L. Kreidlin, N. Frid. “Dependency treebank for Russian: concept, tools, types of information”, 18th International Conference on Computational Linguistics, COLING 2000 (July 31-August 4, 2000, Universität des Saarlandes, Saarbrücken, Germany), 2000, pp. 987-991.
- W. B. Cavnar, J. M. Trenkle. “N-gram-based text categorization”, 3rd Annual Symposium on Document Analysis and Information Retrieval, SDAIR-94 (April 11-13, 1994, Las Vegas, Nevada), pp. 161-175.
- J. Pomikálek. Removing boilerplate and duplicate content from Web corpora, Masaryk university, Faculty of informatics, Brno, Czech republic, 2011, 108 pp.
- S. Sharoff, J. Nivre. «The proper place of men and machines in language technology. Processing Russian without any linguistic knowledge», По материалам ежегодной Международной конференции «Диалог» (Бекасово, 25-29 мая 2011 г.), Компьютерная лингвистика и интеллектуальные технологии, т. 10(17), Изд-во РГГУ, М., 2011, с. 591-604 (англ.).
- M. Straka, J. Straková. Tokenizing, POS tagging, lemmatizing and parsing UD 2.0 with UDPipe, CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies (Vancouver, Canada, August 2017), 2017, 12 pp.
- DOI: 10.18653/v1/K17-3009
- А. В. Сокирко. «Морфологические модули на сайте www.aot.ru», По материалам ежегодной Международной конференции «Диалог» (2-7 июня 2004 г.), Компьютерная лингвистика и интеллектуальные технологии, Наука, М., 2004, с. 559-564.
- S. Sharoff, M. Kopotev, T. Erjavec, A. Feldman, D. Divjak. “Designing and evaluating Russian tagsets”, 6th International Conference on Language Resources and Evaluation, LREC 2008 (Marrakech, May, 2008), pp. 279-285.
- И. В. Трофимов. «Морфологический анализ русского языка: обзор прикладного характера», Программная инженерия, 10:9-10 (2019), с. 391-399.
- DOI: 10.17587/prin.10.391-399
- Д. Г. Анастасьев, И. О. Гусев, Е. М. Инденбом. «Улучшение морфологического парсера с помощью вспомогательных задач обучения и представлений слов на символьном уровне», По материалам ежегодной международной конференции «Диалог» (Москва, 30 мая-2 июня 2018 г.), Компьютерная лингвистика и интеллектуальные технологии, т. 17(24), Изд-во РГГУ, М., 2018, с. 14-27 (англ.).
- arXiv: 1807.00818
