Personalized recommendation systems (PRES): a comprehensive study and research issues
: a comprehensive study and research issues")
Author: Raghavendra C. K., Srikantaiah K.C., Venugopal K. R.
Journal: International Journal of Modern Education and Computer Science @ijmecs
Article in issue: 10 vol.10, 2018.
Free access
The type of information systems used to recommend items to the users are called Recommendation systems. The concept of recommendations was seen among cavemen, ants and other creatures too. Users often rely on opinion of their peers when looking for selecting something, this usual behavior of the humans, led to the development of recommendation systems. There exist various recommender systems for various areas. The existing recommendation systems use different approaches. The applications of recommendation systems are increasing with increased use of web based search for users’ specific requirements. Recommendation techniques are employed by general purpose websites such as google and yahoo based on browsing history and other information like user’s geographical locations, interests, behavior in the web, history of purchase and the way they entered the website. Document recommendation systems recommend documents depending on the similar search done previously by other users. Clickstream data which provides information like user behavior and the path the users take are captured and given as input to document recommendation system. Movie recommendation systems and music recommendation systems are other areas in use and being researched to improve. Social recommendation is gaining the momentum because of huge volume of data generated and diverse requirements of the users. Current web usage trends are forcing companies to continuously research for best ways to provide the users with the suitable information as per the need depending on the search and preferences. This paper throws light on common strategies being followed for building recommendation systems. The study compares existing techniques and highlights the opportunities available for research in this area.
Collaborative based filtering, content based filtering, hybrid filtering, personalized recommendation technique, recommendation system
Short address: https://sciup.org/15016798
IDR: 15016798 | DOI: 10.5815/ijmecs.2018.10.02
Text of the scientific article Personalized recommendation systems (PRES): a comprehensive study and research issues
Published Online October 2018 in MECS DOI: 10.5815/ijmecs.2018.10.02
It is the need of the hour for most of the companies to initially search, map and further provide the users with the appropriate portion of information as per their requirement and tastes on World Wide Web. By studying the past behavior of the users, intelligent and smart recommendation systems are being built by Companies. The built-in algorithms of Recommendation Systems (RS) aim to deliver accurate and most relevant content to the user. This is achieved by applying filer to the huge pool of information base to get useful stuff. The engines of recommendation systems discover data patterns in the data sets. This is done by learning the choices of consumers and producing the outcomes that co-relate to their interests and needs.
Two common strategies being followed while building decision supportive system named recommendation system are content-based filtering and collaborative filtering techniques. Information like keywords, answers to queries, demographic etc., are gathered by Content based filtering to generate a profile of the user. Based on their profiles, users are matched to items. Collaborative filtering is built on the history of users’ behavior. Users rating, purchasing or viewing history is used to establish association between users with similar behaviors and between items of interest to the same users. Fig. 1 and Fig. 2 depict the flow of actions that are executed in content-based and collaborative based RS.
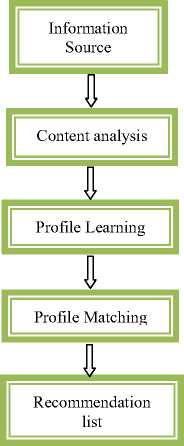
Fig.1. Content based recommendation system

Fig.2. Collaborative based recommendation system
Collaborative recommenders have advantages over content-based recommenders considering few parameters as mention in Table I.
Table 1. Comparison of recommendation systems
|
Content based recommendation system |
Collaborative based recommendation system |
|
More parameters lead to increased complexity |
Easy to implement |
|
Prediction accuracy depends on number of attributes |
More accuracy in predictions |
|
Personalized |
Non-personalized and personalized |
The important applications of recommendation systems include product recommendations, Movies recommendations and News articles delivery to the users. Fig. 3 indicates the different recommendation systems in use.
User
News Articles
Articles are identified based on users past behavior.
Product
Recommendations
These are based on the purchase decisions done by similar customers or on other techniques
Movie
Recommendations
These are user rating based recommendation
Fig.3. Recommendation systems in use.
-
II. Filtering Techniques Applied in Recommendation Systems
The biggest problem encountered by the web users is the amount of information available in web for the item of interest which invariable fails to offer the required, specific and supportive facts for the user to bank upon and further to take conclusive decisions. The recommendations systems developed can able to provide solution to this problem by applying various filtering techniques such as content based and collaborative based filtering approaches to assess the available content initially and identify the right, elite and customized information further according to the needs of the of the user based on their questioned item.
-
A. Content-based filtering (CBF):
CBF works principally based on cognitive type filtering approach, which supports in providing information or recommends the items of interest, depends solely on a comparison note developed between the items related to content and a profile of user. The filtering system works by considering the data of each questioned item in the form of a set of descriptors or terms, which means typically the information provided in the document and the user profile, also denoted with similar set of descriptors and built-up by assessing the data of objects seen by the user. CBF works very effective in particularly situations such as extracting the text documents which are represented by a group of keywords. CBF system typically uses text documents as principle information source of the content and searching by considering the terms and the keywords of the document (selects single words from documents). Further these terms were used in model approaches i.e. vector space model design and latent semantic indexing approach to represent the content documents as a single vector in a multi-dimensional space.
PRES (Personalized Recommender System) is one of the common CBF based approach applied in the recommendation systems. PRES usually work by comparing user profile with the data of all the text based documents identified. Initially data in the form of text is extracted from the pooled documents by running through a number of continuous steps based on the set of terms, further all HTML tags and stop words are identified and removed to provide customized information [1,2].
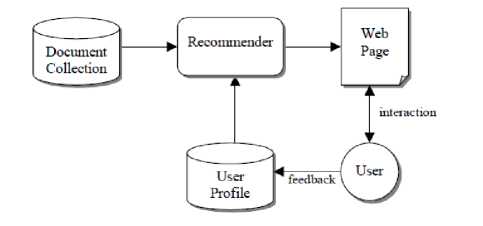
Fig.4. Flow chart depicting the workflow pattern of PRES filtering technique. Source [1]
One of the personal news systems known as News Dude provides a news stories to the users utilizing the speech content developed through TF-IDF model. In this model, short-term recommendations are determined based on the synthesized information and further these recommendations were compared with Cosine Similarity Measure and learning algorithm to provide users customized news stories [3]. One of the highly utilized and rated research paper repositories on the web IBRA today by the user populations known as CiteSeer is an involuntary automated citation indexing cite, that utilizes variety of heuristics and machine learning algorithms of CBF based recommendation system implemented through Naïve Bayes classifier to assess the web based documents and provides the recommendations depends on the needs of user profile and also develops a list of titles based on information provided by an individual user at the time of query. The developed system is competent enough to supply elucidation on any recommendations suggested for the users by cataloging the attributes that support the premier ratings and therefore, motivating the users to have self-reliance on recommendations suggested by the model [4].
CBF system faces limitation in extracting the customized information depends on the requirements of the user profile from multimedia information, because the system observation of the item content such as colors, textures, etc… differs significantly with that of the users. The donated terms for the items need to annotate based on universally accepted annotation system to avoid the miscommunication between the user profile and the system read. An automated method or an algorithm need to be designed and established to correlate the user perception with the machine language while retrieving the recommendation. Another most important setback of the CBF technique is a failure to appraise the value of an item as it cannot differentiate quality documents from the poor when both denoted with the terms. CBF do not have a way of finding opportune items that are interesting for the user but not listed in the user profile [5].
-
B. Collaborative filtering system (CF):
CF system is the most basic filtering approach of the recommendations systems, works based on the withdrawn hypothesis illustrating the psychology of the users; indicating that the people may prefer their stuff based on similarity percentage between items they basically like with that of the items available, and also based on the preferences or choices of the items made by the other who has the similar kind of taste or requirement. Significant research was carried on the applications of the CF technique in the recommendation systems and among the reported approaches the most popular and widely applied technique is model based matrix factorization which works based on low-dimensional factor models. CF techniques are broadly categorized into two different types’ i.e., 1. Memory based approach and 2. Model based approach.
-
a) Memory based approach: Memory dependent CF approaches further categorized into two main classes
such as User-Item approach, which filters the content relies on the similarity ratings of the new users given on the similar items of interest with respect to the selected user profile whereas an Item-item approach selects an item first and finds the users profile liked the same item, from that identify the other items of the same users or similar user and suggest them with a recommendation. The memory based approaches works chiefly relay on the similarity between the user and item choices calculated applying by only arithmetic operations such as Cosine similarity or Pearson correlation coefficients without depending on the gradient descent and also lack of application of other optimization algorithms to optimize both User-Item and Item-Item based similarity information to withdrawn the final recommendations. Overall methodology of CF system applied through either User-Item or Item-Item based model is an easy to use approach, but the performance of the model will decrease when less data is available, in turn reduces the efficacy of the approach with respect to the most of the real world problems faced by the users.
-
b) Model based approach: Model based approaches of the CF system works based on machine learning algorithms equipped with an ability to assess the user’s rating for unrated or less rated items given by the similar user profiles. The machine learning algorithms applied in the CF were classified into three sub-types based on the working principle.
-
i) Matrix Factorization (MF): Model works on the identified Embeddings known as small number of the hidden information helps in determining the preferences of the user .
-
ii) Clustering based algorithm (KNN): Similar to memory based filtering systems but, in KNN system user and item similarities considered as weights were measured based on an unverified learning model, rather than Pearson correlation or cosine similarity used in the memory based models. Approach is scalable as the algorithm is equipped with the option of limiting the number of similar users selected presented as k.
-
iii) Neural Nets/ Deep Learning: It possess further addition to matrix factorization method where learn the values by splitting the original sparse matrix information into product of low rank orthogonal matrices and assess them in the embedded matrix itself to withdraw the final recommendations [2, 6].
-
C. Hybrid filtering Techniques:
Different recommendation system discussed were individually have their own limitations, with the aim of achieving much improved recommendation systems solutions, a combination of different recommendation system (Hybrid filtering technique) were tested and reported with the higher efficiencies which in turn denotes the significance of Hybrid filtering technique for the much improved, informative and customized recommendation systems for the modern day users. Application of hybrid filtering system certainly improves the accuracies and the prediction abilities of the recommendation systems, as the limitation of the algorithm can be overcome with the help of other, while working in combination. So hybrid system has clear advantages compared to the individual systems. Hybrid filtering systems can be established following any of the combination i.e., Algorithms can be applied separately and the results can be combined to make the final recommendations, incorporating content-based filtering approaches with that of collaborative approach, applying few CF techniques in CBF approach and establishing a unified combitorial recommendation system that brings together both approaches [7].
-
a) Weighted hybridization (WH): WH add the outcome of individual models present as a combination in hybrid approach and withdraw the recommendation by summating the final scores retrieved from all the techniques taken in hybrid system applying a linear formula. P-tango hybrid system is one of the commonly employed weighted hybridization system [2, 7, 8].
-
b) Switching hybridization: Works by swapping any of the recommendation techniques of the hybrid design, applied involving trial and error kind of recommender ability and generates a high-quality rating. This approaches overcome the algorithm limitation by switching the recommendation system present in the hybrid. This approach was found to be very sensitive with regards to the strengths and weaknesses of its component recommenders. DailyLearner system is an exemplar of a switching based hybrid recommender system [2, 7, 9].
-
c) Cascade hybridization: This technique utilizes mathematic logic approach termed iterative based enhancement procedure while developing sequence of predilection amongst dissimilar items and refines the recommendation of the one technique with the other technique in hybrid combination. Techniques are very efficient to the background noise of the algorithm and EntreeC is an example of cascade based hybridization method, developed with the combination of cascade knowledge based and CF systems [2,7,10].
-
d) Mixed hybridization: Unite the recommendation results of all the items collected from the different recommender components of the hybrid system, together at the same time. In this mixed kind of hybridization technique, the individual technique activity or efficiencies do not always influence the universal performance of a local region. PTV system is one of the suggestive examples of mixed hybridization recommender system [7, 11].
-
e) Feature-combination: In this features of one recommendation system is utilized in the other . For example, an attribute of CF i.e. ranking information of related users is applied in a case dependent reasoning approach as key feature to resolve the similarity index between the various substances. Pipper is a renowned example of this hybrid type, which applies the collaborative filter’s ratings in a content-based system as a feature for recommending movies [7, 12].
-
f) Feature-augmentation: Utilizes the scoring and preference information retrieved from all the earlier recommenders. Libra system is an example of this kind hybrid approach, which provides CBF based
recommendation of different volumes of books on the information found in website Amazon.com through applying a naive bayes text classifier model. Hybrid approaches related to the Feature augmentation models are more efficient compared to feature-combination methods in that the former will add a small number of features to the primary recommender [5, 7].
-
g) Meta-level: The inner representation given by one recommendation model is considered as an input data for the next recommender system of the hybrid. Metalevel is one of the hybrid systems capable to provide solution to most common sparsity problem of CF techniques. LaboUr [13] an example of this technique, which uses instant based learning to produce contentbased user profiles initially and further compared in a collaborative manner to make the final recommendations.
-
III. Studies conducted on Various Recommendation Techniques
Several researchers have attempted to improve the existing document recommendation systems. This section navigates through few such studies and highlight the advantages and drawback of the techniques used.
Yu Liu, Shuai Wang, M. Shahrukh Khan, and Jieyu [14] opine that the research that combines the collaborative filtering and content based recommendations with deep learning is not yet done. The deep hybrid recommender framework that is based on auto-encoders (DHA-RS) that integrates user and item side information has been proposed in this work. DHA-RS combines stacked de noising auto-encoders with neural collaborative filtering, which corresponds to the process of learning user and item features from auxiliary information to predict user preferences. From the experiments done on real-world data set, it is proved that the performance of DHA-RS is superior than the existing computational methods.
-
F. S. Gohari, F. S. Aliee and H. Haghighi [15] proposed Trust-aware Group Recommendation (TGR) method for improvement of performance in group recommendations. Trust based metric of a novel group optimized involving a method known as Particle Swarm Optimization (PSO) has been used in the proposed scheme. For a user group, this provides a set of neighbors. The proposed approach considers group as a whole and utilizes a metric called GTM (Group Trust Metric) for identification of most truthful neighbors in the group. The process of aggregation is done during trust computation step. The method is designed based on the usual practice that the degree of trust is computed from a group to each of the user. Using this methodology, the TGR metrics can attain a set of neighbors with respect to the user’s group thus leading to improved run time performance. The results obtained by experimentation reveal that TGR improves the overall period (run time) performance and accuracy of group based RS designs.
-
B. K. Sunny, P. S. Janardhanan, A. B. Francis and R. Murali [16] state that the traditional RS designs cannot satisfy the needs of the user because of the limited capability of the models and analysis. Because of increased availability
of technologies for processing of big data, the implement of real time suggestions or recommendation has become very easy and effective. The velocity attribute of big data is being handled by new paradigm called streamcomputing. This technology enables to develop real time big data applications. Real time RS is implemented in this work. The implementation has been done using Apache Spark which is a platform for stream computing. The system recommends TV channels to users as an existent real instance. This is a huge challenge as viewers preferences are context dependent and the set of channels are dynamically changing. The traditional approaches are not capable of handling recommendation scenarios characterized by dynamic nature, time constraints, data volume etc. The researchers implemented a TV channel RS that is optimized for data streams based on the high throughput manner (Real time) that originates from settop boxes. The self-adaptive method for building recommendation model is implemented. Apache Spark’s distributed processing capability has been effectively utilized for real time recommendation. The machine learning libraries provides several algorithms for developing recommendation system. Lambda Architecture has been used for processing of huge volume of data in the system efficiently.
Manasa N, Bavya S, Kavitha G [17] utilized the perception of just-in-time retrieval, which helps in instinctively recommending documents that are associated to users’ present activities. The proposed system provides well-organized way for document recommendation system for users using the conversational data. Text file of informal data is given as input. These informal data are partitioned into m clusters. Clusters contain numerous numbers of keywords including surplus words. Important and useful topic related keywords are extracted using Word dictionary. Keywords are graded based on their number of occurrences or weights. By selecting maximum ranked keyword document recommendation method will be achieved.
RanaChamsi Abu Quba [19] investigated specific aspects of the recommendation systems like General Purpose Social or Public Networks to verify if predictions can be made depends on natural activities on social or public networks. The researchers have concerns like whether the implicit data available in GPSNs can be transformed into recommendation engine or recommendation system engine evaluation can be done apart from traditional accuracy metrics like MAE. The researchers developed a hybrid social recommender called intelligent Social Network Transformer into Recommendation Engine (iSoNTRE). The engine transforms the richness in GPSNs into recommendation system that is robust. The system can be applied across various domains by converting user’s information into recommendation based information. In this way, iSoNTRE saves users efforts as they need not enter what they like.
As pointed by S. Meng, W. Dou, X. Zhang and J. Chen [20] there is an enormous increase in the amount of customers, information and service. Because of this, problem related to the BIG data analytics has been raised for service based recommender systems. Scalability and inefficiency are the existing issues for processing and analysis of huge data in traditional recommendation systems. Currently accessible recommendation systems provide same rankings and ratings of services to users without taking into considerations of diverse user preference. Because of this, these systems fail to meet up the tailored requirements of users. The researcher group of the study proposed a KASR (Keyword Aware Service Recommendation method) to deal with these issues. The proposed method presents a service recommendation that is personalized and appropriate to the users. The preferences of the users are indicated by keywords. For generating suitable recommendations, a user-based CF algorithm is implemented. In order to adapt to the present scenario of big data analytics, KASR is executed along with Hadoop which is a widely used distributed computing framework. The experiments are done using real world data. The accuracy and scalability of the service recommenders can be enhanced by using the proposed method.
Due to large number of options available, choosing the right service is not easy. Back Sun Sim, Heeseong Kim, KwangMyung Kim and H. Y. Youn [21] opine that the recommendation system currently in use doesn’t properly judge the public relation of the entities in giving the rating for the choices. In this work, a novel approach is proposed that is context-aware that explains the user type for estimation of the proximity between the social network users, collectively with the cosine based similarity measure. The computational model performed for this projected work shows that there is a significant improvement in accuracy of ranking compared to current techniques. The amount of various items suggested or recommended by this new method is comparatively much larger quantity.
-
V. B. Savadekar and M. E. Patil [22] opine that traditional recommendation systems undergo
incompetence problems in the assessment of big data generated from large amount of information available online. Many of the existing methods provide fixed ratings and items scorings to various users devoid of considering the needs of the users resulting in failure to deliver personalized requirements. In this work, a
Table 2. Strengths and drawbacks of various RS
References Personalized recommendation systems (PRES): a comprehensive study and research issues
- Robin van Meteren and Maarten van Someren, “Using content based filtering for recommendation,” Conference Proceedings, semantics scholar, 2000.
- J. Bobadilla, F. Ortega, A. Hernando, A. Gutiérrez, “Recommender systems survey,” Knowledge-Based Systems, Vol. 46, pp.109–132, 2013.
- Billsus D, Pazzani MJ, “User modeling for adaptive news access,” User modeling and User-adapted Interaction, Vol. 10(2–3), pp.147–180, 2000.
- Raymond J. Mooney and Roy L, “Content-based book recommending using learning for text categorization,” Proceedings of the fifth ACM conference on digital libraries, ACM, pp. 195–204, 2000.
- Cacheda F, Carneiro V, Fern´andez D, Formoso V, “Comparison of collaborative filtering algorithms: Limitations of current techniques and proposals for scalable, high-performance recommender systems,” ACM Transactions on the Web (TWEB), Article 2, Vol. 5(1), February 2011. “doi: 10.1145/1921591.1921593”.
- George A Sielis, Aimilia Tzanavari, George A Papadopoulos, “Recommender Systems Review: Types, Techniques and Applications,” In 3rd edition Encyclopedia of Information Science and Technology, pp.7260-7270, 2015.
- F.O. Isinkaye, Y.O. Folajimi, B.A. Ojokoh, “Recommendation systems: Principles, methods and Evaluation,” Egyptian Informatics Journal, Vol. 16(3), pp. 261-273, November 2015,
- Claypool M, Gokhale A, Miranda T, Murnikov P, Netes D, Sartin M, “Combining content- based and collaborative filters in an online newspaper,” In Proceedings of ACM SIGIR workshop on recommender systems: algorithms and evaluation, Berkeley, California, 1999.
- Billsus D, Pazzani MJ, “A hybrid user model for news story classification,” In Proceedings of the seventh international conference on user modeling, Banff, Canada, Springer-Verlag, New York, pp. 99–108, 1999.
- Burke R, “Hybrid recommender systems: survey and experiments”, User modeling and User-adapted Interaction, vol. 12(4), pp.331–370, 2002. “doi:10.1023/A:1021240730564”.
- Smyth B, Cotter P, “A personalized TV listings service for the digital TV age,” Knowledge Based Systems, Vol. 13(2–3), pp.53–59, April 2000. ”https://doi.org/10.1016/S0950-7051(00)00046-0”
- Pazzani MJ, “A framework for collaborative, content-based and demographic filtering,” Artificial Intelligence Review, Vol. 13(5-6), pp. 393-408, December 1999.
- Basu C, Hirsh H, Cohen W, “Recommendation as classification: using social and content-based information in recommendation,” In Proceedings of the 15th national conference on artificial intelligence, Madison, WI, pp. 714–20, 1998.
- Yu Liu, Shuai Wang, M. Shahrukh Khan, and Jieyu He, “A Novel Deep Hybrid Recommender System Based on Auto-encoder with Neural Collaborative Filtering,” Big Data Mining and Analytics, Vol. 1(3), pp. 211–221, September2018.”doi: 10.26599/BDMA.2018.9020019”
- F. S. Gohari, F. S. Aliee and H. Haghighi, “A trust-aware group recommender system using particle swarn optimization,” International Symposium on Computer Science and Software Engineering Conference (CSSE), Shiraz, pp. 80-85, 2017.
- B. K. Sunny, P. S. Janardhanan, A. B. Francis and R. Murali, “Implementation of a self-adaptive real time recommendation system using spark machine learning libraries,” IEEE International Conference on Signal Processing, Informatics, Communication and Energy Systems (SPICES), Kollam, pp. 1-7, 2017.
- Manasa.N, Bavya S, Kavitha G, “To Recommend Documents In Small Business Meetings by Extracting Keywords & Clustering them”, International Journal of Advance Research in Engineering, Science & Technology, Vol. 3(7), July-2016,
- Michael J. Pazzani and Daniel Billsus, “Content Based Recommendation System”, The Adaptive Web, Springer, LNCS 4321, pp. 325 – 341, 2007.
- RanaChamsi Abu Quba, “On Enhancing Recommender Systems by Utilizing general Social Networks Combined with User’s Goals and Contextual Awareness,” Networking and Internet Architecture, University Claude Bernard - Lyon I, 2015
- S. Meng, W. Dou, X. Zhang and J. Chen, “KASR: A Keyword-Aware Service Recommendation Method on MapReduce for Big Data Applications,” IEEE Transactions on Parallel and Distributed Systems, Vol. 25(12), pp. 3221-3231, December 2014.
- Back Sun Sim, Heeseong Kim, KwangMyung Kim and H. Y. Youn, “Type-based context-aware service Recommender System for social network,” International Conference on Computer, Information and Telecommunication Systems (CITS), Amman, pp. 1-5, 2012.
- V. B. Savadekar and M. E. Patil, “Improved recommendation system with review analysis,” International Conference on Global Trends in Signal Processing, Information Computing and Communication (ICGTSPICC), Jalgaon, pp. 79-82, 2016.
- H. L. Nguyen and J. J. Jung, “Utilizing Dynamics Patterns of Trust for Recommendation System,” International Conference on Intelligent Environments (IE), Seoul, pp. 108-113, 2017.
- Zhang and Xiaoying, “Modeling the Assimilation-Contrast Effects in Online Product Rating Systems: Debiasing and Recommendations,” Proceedings of the Eleventh ACM Conference on Recommender Systems, pp. 98-106, 2017.
- EvangeliaChristakopoulou and George Karypis, “Local Item-Item Models for Top-N Recommendation,” Proceedings of the 10th ACM Conference on Recommender Systems, pp. 67-74, 2016.
- Xiaoming Liu, Chao Shen, “We know who you are: Discovering similar groups across multiple social networks,” accepted for inclusion in IEEE Transactions on Systems, Man and Cybernetics Systems, 2018.
- Surong Yan, Kwei-Jay Lin, Xiaolin Zheng and Xiaoqing Feng, “An approach for building efficient and accurate social recommender systems using individual relationship networks”, IEEE Transactions on Knowledge and Data Engineering, Vol. 29(10), October 2017.
- Xiwang Yang, Chao Liang, Miao Zhao, Hongwei Wang, Hao Ding, Yong Liu, Yang Li and Junlin Zhang, “Collaborative filtering based recommendation of online social voting”, IEEE Transactions on Computational Social Systems, Vol. 4(1), March 2017.
- Anitha Anandhan, Liyana shuib, Maizatul Akmar Ismail, and Ghulam Mujtaba, “Social Media Recommender Systems: Review and Open Research Issues,” In IEEE Access, April 2018.“doi: 10.1109/ACCESS.2018.2810062”
- Ningning Yi, Chunfang Li, Xin Feng, Minyong Shi, “Design and Implementation of Movie Recommender System Based on Graph Database,” 14th Web Information Systems and Applications Conference, 2017. “DOI 10.1109/WISA.2017.34”
