Перспективы финансовой поддержки информационных кластерных инициатив Белорусским фондом финансовой поддержки предпринимателей

Автор: Степанов Н.В., Михайлов Б.А.
Журнал: Теория и практика современной науки @modern-j
Рубрика: Математика, информатика и инженерия
Статья в выпуске: 2 (116), 2025 года.
Бесплатный доступ
В данной статье рассмотрены инновационные разработки в области управления данными, аналитике. В эпоху цифровой трансформации информационным системам приходится сталкиваться с фундаментальной проблемой - как организовать эффективное управление разнородными источниками данных, учитывая экспоненциальный рост объёмов информации, а также сложность её структурирования. Современные бизнес-процессы требуют не только хранения и обработки разного рода сведений, но и разработки прогностических моделей, способных обнаруживать латентные закономерности в потоках информации. Исследуемая проблема заключается в необходимости интеграции инновационных методов аналитики в существующую IT-инфраструктуру хозяйствующих субъектов, что требует пересмотра традиционных архитектур и подходов к обработке данных.
Аналитика, большие данные, масштабируемость, машинное обучение, микросервисная архитектура, предиктивная аналитика, прогнозирование, распределённые вычисления, управление данными
Короткий адрес: https://sciup.org/140310940
IDR: 140310940
Текст научной статьи Перспективы финансовой поддержки информационных кластерных инициатив Белорусским фондом финансовой поддержки предпринимателей
Обращаясь к ретроспективе, следует отметить, что исторически управление в рассматриваемой области развивалось от централизованных СУБД к распределённым системам, ориентированным на параллельную обработку информации. Ранняя стадия эры ИТ характеризовалась строгой структурированностью данных, что позволяло применять классические алгоритмы обработки [5, с. 1068].
Однако с появлением интернета вещей, социальных сетей, сенсорных устройств информация стала поступать в гетерогенном виде, что привело к усилению потребности в разработке адаптивных архитектур, обрабатывающих как структурированные, так и неструктурированные данные. В этом контексте концепция Data Lake и гибридные модели хранения становятся фундаментальными — с позиций обеспечения масштабируемости, оперативности аналитических процессов.
На схеме (рис. 1) выделены инновационные подходы, благодаря которым реализуется управление данными и аналитика.
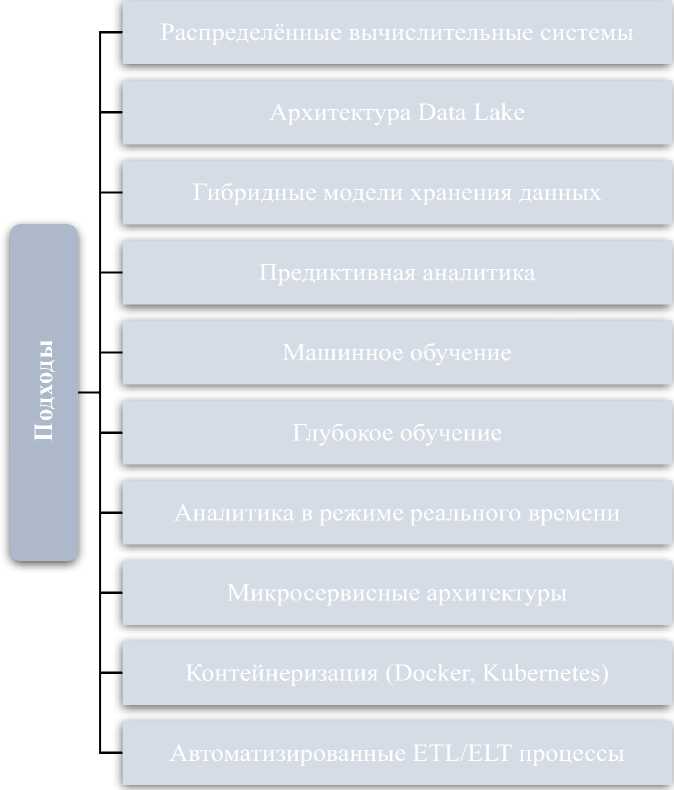
Рисунок 1. Систематизация инновационных подходов к управлению данными и аналитике (составлено автором)
Так, современные информационные системы опираются на распределённые вычислительные платформы (к примеру, имеются в виду Apache Hadoop, Apache Spark), которые обеспечивают обработку данных в режиме реального времени. Эти технологии помогают формировать параллельные процессы ETL (Extract, Transform, Load) для интеграции сведений из различных источников, что является весьма значимым для построения качественных аналитических моделей. Характеризуемые решения демонстрируют высокую отказоустойчивость и гибкость, что особенно актуально при работе с неструктурированными данными, которые отличаются высокой скоростью обновления, а также разнообразием форматов [1, с. 210].
В свою очередь, предиктивная аналитика, опирающаяся на статистические методы и алгоритмы машинного обучения, даёт возможность как выявлять закономерности, так и прогнозировать будущие тренды. В отличие от традиционных подходов, современные методы предсказательной аналитики опираются на алгоритмы регрессии, кластеризации, анализ временных рядов, благодаря чему обеспечивается точное моделирование бизнес-процессов [3, с. 15].
Так, за счёт интеграции моделей глубокого обучения компании прогнозируют поведение клиентов, оптимизируют цепочки поставок, предотвращают финансовые риски. Важным аспектом служит корректная настройка гиперпараметров в сочетании с постоянной адаптацией модели к новым данным, что требует разработки специализированных методик валидации и тестирования.
Что касается machine learning (ML), то оно стало неотъемлемым звеном аналитических решений в корпоративном секторе. Системы, которые базируются на алгоритмах обучения с учителем и без него, позволяют автоматизировать процессы обнаружения аномалий и сегментации данных. Применение сверточных (CNN), рекуррентных (RNN) нейросетей в задачах анализа временных рядов либо обработки изображений открывает дополнительные опции, содействуя принятию аргументированных, тщательно подготовленных управленческих решений. Внедрение гибридных алгоритмов, сочетающих элементы классической статистики и нейронных сетей, помогает повысить точность прогнозов, а также адаптивность системы к изменяющимся условиям [2, с. 28].
Интеграция технологий Big Data в бизнес-инфраструктуру предоставляет возможность оптимизировать операционные процессы.
Анализ транзакционных данных, клиентских профилей, логистических цепочек с использованием предиктивной аналитики способствует повышению эффективности процессов принятия решений. В ряде случаев применение распределённых вычислений совместно с алгоритмами machine learning помогает создавать системы, способные в режиме реального времени реагировать на рыночную динамику и корректировать стратегию развития.
Далее целесообразно рассмотреть практические кейсы и индустриальные примеры. Так, в финансовом секторе задействование ML для анализа кредитного риска и мониторинга аномалий в транзакциях уже продемонстрировало значительное снижение операционных затрат, повышение безопасности операций. В розничной торговле применение предиктивных моделей для анализа покупательского поведения даёт возможность оптимизировать цепочки поставок, персонализировать маркетинговые кампании. Примеры интеграции аналитических решений в производственные процессы свидетельствуют о том, что применение комплексных систем мониторинга и анализа содействует как сокращению издержек, так и усилению конкурентоспособности субъектов хозяйствования на глобальном рынке.
Несмотря на очевидные преимущества, внедрение современных методов управления данными сопровождается рядом сложностей (рис. 2).
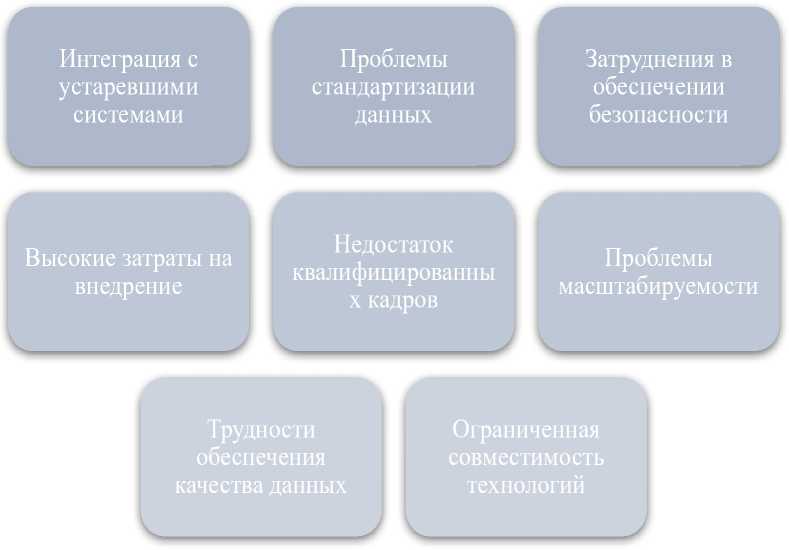
Рисунок 2. Проблемные зоны внедрения инновационных подходов к управлению данными и аналитике (составлено автором)
Так, среди основных проблем целесообразно выделить необходимость стандартизации данных, обеспечение безопасности при обработке больших объёмов информации, адаптацию устаревших систем к новым технологическим требованиям. Риск потери качества сведений при интеграции разнородных источников требует разработки специализированных алгоритмов очистки, нормализации информационных потоков. Помимо этого, постоянное обновление моделей ML требует организации непрерывных процессов обучения и перекалибровки, что представляет собой дополнительное требование к IT-инфраструктуре предприятия [4, с. 73].
Перспективы, а также стратегические направления в исследуемой области предлагается рассматривать через призму:
-
• последующей эволюции архитектур данных;
-
• развития интеллектуальных алгоритмов;
-
• управления качеством данных и вопросы безопасности.
Так, будущие архитектурные решения будут ориентированы на создание полностью автономных аналитических систем, способных самостоятельно подстраиваться под изменения внешней среды. Тенденция к построению микросервисных архитектур и использованию контейнерных технологий (например, Docker, Kubernetes) даёт возможность создавать гибкие, масштабируемые решения, где каждый компонент системы можно обновить или заменить без нарушения общей целостности инфраструктуры. Рассматриваемый подход содействует ускорению процессов внедрения инноваций; он позволяет быстрее реагировать на трансформации в рыночных условиях.
Прогресс в области искусственного интеллекта открывает многообещающие перспективы для разработки алгоритмов, которые способны не только анализировать информацию, но и самостоятельно генерировать гипотезы для последующего исследования. Интеграция методов reinforcement learning (обучения с подкреплением) с элементами классической статистики должно привести к созданию систем, оптимизирующих процессы управления данными на основе динамической обратной связи. Подобный симбиоз методов поможет существенно повысить качество прогнозов и сократить вероятность ошибок в управленческих действиях.
Одним из приоритетных направлений видится разработка эффективных механизмов обеспечения качества данных. С учётом постоянно растущего объёма информационных потоков актуальной становится задача обеспечения их целостности, консистентности, безопасности. Формирование и внедрение многоуровневых систем защиты, включающих криптографические методы и алгоритмы распределённого контроля доступа, становится неотъемлемой частью стратегии управления. Помимо этого, современные подходы требуют оперативно
создания адаптивных систем мониторинга, которые обнаруживают и устраняют проблемы, сопряжённые с качеством информации.
Таким образом, инновации в управлении данными и аналитике представляют собой синтез передовых технологий, позволяющих преобразовать традиционные управленческие модели. Постоянное развитие распределённых вычислительных платформ, интеграция предиктивной аналитики, машинного обучения, а также переход к гибким архитектурным решениям создают предпосылки для формирования устойчивых, масштабируемых систем, отвечающих требованиям современного предпринимательского сектора. Разрешение проблемы ввода в практику разнородных источников сведений, обеспечения их качества остаётся актуальной задачей, работа над которой опирается на междисциплинарный подход и систематическое обновление методологического инструментария. В реалиях интенсивно меняющейся технологической среды предприятия, которые способны оперативно приспосабливаться к новым вызовам, будут обладать стратегическим преимуществом на конкурентном рынке.
Резюмируя, уместно указать на необходимость синергии между теоретическими исследованиями и практическими разработками, что помогает создать инновационные решения, способные не только удовлетворить текущие потребности бизнеса, но и предвосхитить будущие тренды в управлении данными и аналитике.
