Подход к построению русско-казахского тезауруса по информатике

Автор: Бименова Жанат Батырбековна, Джумамуратов Руслан Азатович, Сидорова Елена Анатольевна
Журнал: Вестник Бурятского государственного университета. Философия @vestnik-bsu
Рубрика: Информационные системы и технологии
Статья в выпуске: 9, 2013 года.
Бесплатный доступ
В работе описывается подход к построению тезауруса на русском и казахском языках. Применяются методы корпусного исследования текстов на разных уровнях языковой действительности: морфемном, морфологическом и семантическом. Предложены методы автоматического извлечения терминов и родовидовых отношений между ними. Рассмотрена архитектура системы автоматизированного построения тезауруса, ориентированного на решение задач информационного поиска.
Тезаурус, разметка, выделение терминов, лексические шаблоны
Короткий адрес: https://sciup.org/148182046
IDR: 148182046 | УДК: 004.822
The approach to development of the Russian-Kazakh thesaurus on computer science
In the work the approach to development of the thesaurus in Russian and Kazakh languages is described. Methods of corpus research of texts at different levels of language reality are applied: morphemic, morphological and semantic. Methods of automatic extraction of terms and\generic relations between them have been proposed. An architecture of system of automated development of the thesaurus focused on solutions of problems of information search is considered.
Текст научной статьи Подход к построению русско-казахского тезауруса по информатике
Тезаурус – многозначный термин. В современной лингвистике и информатике тезаурус представляет собой некоторое, особым образом оформленное накопление [1]. В данной работе под термином «тезаурус» будем понимать словарь, в котором слова и словосочетания с близкими по смыслу значениями сгруппированы в единицы, называемые терминами или дескрипторами, и в котором явно указываются семантические отношения между этими терминами (дескрипторами) [2].
Построения тезауруса на казахском языке – непростая задача. Несмотря на то, что существуют определенные стандарты построения тезаурусов, не всегда возможно напрямую воспроизвести существующие методики. Причинами этого являются, во-первых, специфика казахского языка (агглютинативного языка с богатой морфологией, в котором морфология языка тесно связана с его семантикой), во-вторых, отсутствие источников лексической информации (например, больших корпусов текстов), в-третьих, отсутствие доступных морфологических словарей казахского языка. Все это предполагает создание инструментов на основе подхода «чистой доски».
Высококачественные тезаурусы в большинстве своем создаются вручную. Процесс поддержания тезаурусов в актуальном состоянии довольно трудоемок, особенно в быстроразвивающихся областях. Таким образом, построение тезаурусов становится «узким местом» для практической реализации проектов, использующих их для решения своих задач (например, информационный поиск), требуются методы автоматизации их наполнения и поддержки. Одной из проблем, возникающей при автоматическом наполнении тезаурусов, является большое количество «шума», который надо эффективно отсеивать. В связи с этим наряду с автоматическими методами используют последующую ручную обработку полученного материала для получения данных большей точности (такие методы называются автоматизированными).
Методы автоматического построения тезаурусов не могут работать без разнообразных словарей. Для построения тезауруса на казахском языка, ориентированного на поддержку информационного поиска, необходимо начинать с создания морфологического словаря. Данный словарь должен поддерживать функцию морфологического анализа и извлечения из текстов на казахском языке терми- нов предметной области. Для отделения общезначимых слов от терминов предметной области используется статистическая информация и создается специальный словарь предметной лексики [3].
Методы автоматического установления связей между терминами можно условно разделить на три основные группы в зависимости от области заимствования основного подхода: методы, основанные на подходах из области искусственного интеллекта, статистические методы и методы, использующие лингвистические подходы [4]. Исследования Марти Хест [5] показали, что для идентификации отношения гипонимии «достаточно адекватный» результат показывает метод лексических шаблонов.
Корпусная лингвистика – удобный инструмент для исследования языка и создания лексикографических ресурсов [6,7]. Разметка корпуса может осуществляться по разным основаниям (разным лингвистическим уровням), в частности, на морфемном, морфологическом, терминологическом, семантическом уровне и др. Использование размеченных корпусов позволяет автоматизировать наполнение необходимых словарей.
В данной работе предложен подход к автоматизированному построению тезаурусов на казахском языке, который демонстрируется в предметной области «Информатика». Реализуется полная цепочка разработки тезауруса – от этапа корпусного исследования предметной области и особенностей подъязыка, создания лексикографических ресурсов до методов автоматизированного наполнения и поддержки тезауруса.
1. Тезаурус
Тезаурус описывает терминологию предметных областей как терминосистему в виде словаря терминов и словокомплексов с фиксированными семантическими связями между ними, поддерживая возможность их редактирования в процессе функционирования.
Для построения тезауруса предметной области на казахском языке необходимо решить следующие задачи:
1) определить структуру словарной статьи тезауруса; 2) сформировать параллельный корпус текстов по тематике тезауруса; 3) определить способ выделения терминов из корпуса текстов и сформировать список терминов; 4) установить отношения между терминами. 1. 1. Структура словарной статьи тезауруса
В каждой словарной статье тезауруса описывается один термин. Это знак специальной семиотической системы, обладающий номинативно-дефинитивной функцией, или другое определение: термин – это устоявшееся понятие [8]. Все термины в тезаурусе являются дискрипторами.
Согласно ГОСТ 7.25-2001, в словарную статью включаются следующие типы лексических единиц: одиночные слова (существительные, прилагательные, глаголы, наречия), именные словосочетания, лексически значимые компоненты сложных слов и сокращения слов и словосочетаний [9].
Структуру словарной статьи тезауруса можно представить в виде тройки:
T = , где
А – символьное имя термина, соответствующее названию представляемого им понятия предметной области,
B – множество бинарных связей термина, включая иерархичные, ассоциативные отношения, отношения синонимии и перевода,
С – множество идентификаторов термина (язык, морфологический класс, тип словосочетания и т.п.).
Между терминами устанавливается два вида иерархических отношений: «Класс-Подкласс» и «Часть -Целое».
Отношение «Класс-Подкласс» в зависимости от терминологических традиций в области использования ресурса может носить разное название: таксономическое отношение, родовидовое отношение, IS-a отношение, отношение гипонимии и гиперонимии. Оно устанавливается, если объем одного понятия входит в объем другого понятия.
Отношение «Часть-Целое» устанавливается в тех случаях, когда одно понятие включено в другое понятие независимо от контекста [2].
Отношение «Ассоциируется с» устанавливается между понятиями, которые находятся в связях, отличных от синонимии и иерархических отношений.
Отношение «Перевод» устанавливается между эквивалентными терминами на разных языках. Если термин не может быть выражен на другом языке одним дескриптором, тогда для него в соответствии с ГОСТом 7.24-2007 указывается в качестве эквивалента комбинация нескольких дескрипторов [10].
1. 2. Архитектура системы построения тезауруса
На рис. 1 представлена общая архитектура системы разработки тезаурусов.
Система включает два основных модуля автоматизации наполнения тезауруса:
подсистема извлечения терминов, подсистема извлечения отношений.
Пользователь имеет доступ к тезаурусу через редактор, который позволяет просматривать и редактировать содержание тезауруса, запускать модули автоматического пополнения тезауруса на новых корпусах текстов, а также осуществлять контроль качества работы данных методов. Обучающий корпус текстов, лексические шаблоны и словарь терминов должны подготавливаться лингвистами совместно с экспертами данной предметной области.
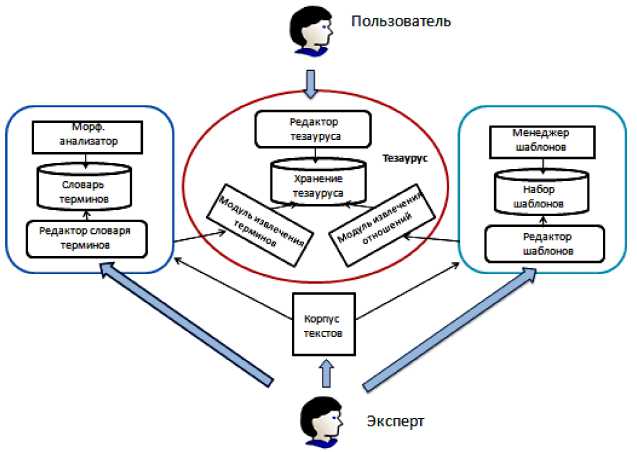
Рис. 1. Архитектура системы
2. Извлечение терминов предметной области
В процессе извлечения терминов из документа исходный текст подвергается графематическому (разбиение на слова), морфологическому (определение нормальной формы и набора параметров) и поверхностно-синтаксическому (сборка словосочетаний) анализу (рис. 2).
На этапе графематического анализа, после разбиения текста на слова, происходит поиск составных слов, которые должны рассматриваться как одно (с точки зрения морфологического анализатора). Морфологический анализ работает на уровне отдельных слов (в том числе составных) и возвращает морфологическую норму и атрибуты данного слова. При этом может оказаться, что одной словоформе может быть сопоставлено несколько возможных вариантов слов. Синтаксический анализатор может осуществлять поиск словосочетаний на основе синтаксичеких шаблонов сборки именных групп аналогично [11, 12]. В результате анализа приведенные к нормальному виду слова и словосочетания помещаются в предварительный словарь терминов.
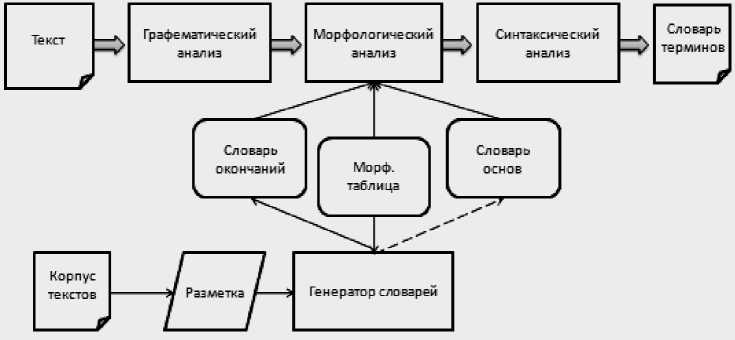
Рис. 2. Общая схема выделения терминов
На текущий момент недоступны программные инструменты, проводящие морфологический анализ текстов на казахском языке. Поэтому нами были разработаны специализированный модуль и морфологическая модель казахского языка для системы Klan [12], предназначенной для автоматизированного создания терминологических словарей. Эта же система использовалась для морфологического синтаксического анализа текстов на русском языке.
Поиск терминов-словосочетаний осуществляется на основе правил, разработанных в рамках системы Klan для русского языка и спроецированных на морфологическую таблицу казахского языка. Учет дополнительных особенностей языка в плане образования устойчивых словосочетаний требует привлечения казахских специалистов и является одной из ближайших целей проекта.
2.1. Корпусное исследование подъязыка предметной области
Казахский язык относится к группе агглютинативных языков, в которых концепция слова значительно шире, чем просто набор элементов лексики, и отличается относительной регулярностью, позиционной и грамматической стабильностью морфологической структуры различных словоформ. Слова в нем образуются присоединением к корню или основе слова грамматических частиц – аффиксов [13].
В целях построении модели морфологии казахского языка была проведена морфемноморфологическая разметка (ММР) корпуса казахских текстов (рис. 3).
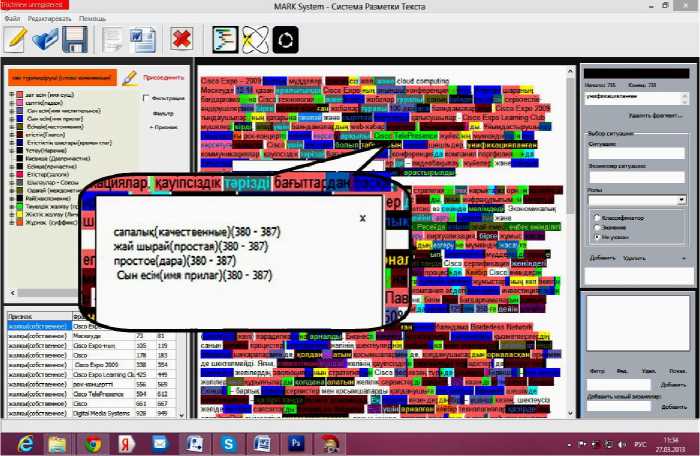
Рис. 3. Морфемно-морфологическая разметка казахского текста
Разметка была создана с помощью системы MarkSystem [14]. Помимо основного функционала, связанного с непосредственным просмотром текста и его «раскраской», в системе реализуется возможность динамического создания и пополнения системы признаков (признаками помечаются фрагменты текста) и отношений, редактирования цветовой схемы «раскраски» (посредством сопоставления признаков цветовой схемы) и управление визуализацией (фильтрация, конкорданс). Каждому фрагменту может быть сопоставлено множество признаков и связей.
Система MarkSystem ориентирована как на лингвистов, осуществляющих лингвистическое исследование корпуса текстов, так и на экспертов, отмечающих терминологию, характерную для заданной предметной области. Параллельно ММР на другом уровне создавалась семантическая разметка (СР) текстов, которая ориентирована на заданную предметную область и включает терминологическую разметку, разметку тезаурусных отношений и индикаторов.
В процессе создания ММР и СР были разработаны иерархии признаков (рис. 4).
Рис. 4. Иерархия признаков для морфемно-морфологической и семантической разметки текстов
На основе ММР была создана морфологическая таблица, описывающая модель казахского языка. Иерархия признаков ММР содержит 117 вершин, на основе которых было сформировано 17 морфологических атрибутов (в том числе и часть речи) и выделено 36 морфологических классов терминов-лексем. По типу словоизменения классы сгруппированы в 16 групп, для каждой из которых формируется свой список окончаний и функция, сопоставляющая окончанию значение одного из атрибутов. Для сравнения: русская таблица содержит 17 атрибутов, 42 класса и 15 групп. Данная таблица легла в основу создаваемого морфологического словаря казахского языка.
Иерархия признаков СР соответствует верхнему уровню иерархии терминов тезауруса по информатике и на текущий момент включает 29 вершин. В процессе СР любой термин, выделенный экспертом, либо соотносится с признаком (что означает, что эксперт считает данный термин обобщающим классом предметной области), либо связывается с одним из ранее введенных признаков. Выделенные фрагменты также могут связываться специальным отношением Род-вид (подробнее о СР будет сказано ниже). Таким образом, назначение СР – выделить основные классы терминов предметной области, которые впоследствии будут служить основой автоматизированных методов поиска новых терминов и отношений между терминами.
2.2. Морфологический анализ текста на казахском языке
На вход морфологического анализатора подается упорядоченный список словоформ (с учетом знаков), полученный в результате графематического анализа. Для каждой словоформы на первом этапе осуществляется нормализация, т.е. поиск основы – начальной формы слова. Затем, в зависимости от части речи и найденных аффиксов, вычисляются морфологические характеристики слова.
Модуль нормализации в процессе своей работы осуществляет следующую последовательность шагов:
-
1 шаг: Выполняется поиск слова в словаре начальных форм. Если слово в словаре найдено, то шаг 5.
-
2 шаг: Слово считывается посимвольно в обратном порядке (начиная с конца слова). Если слово закончилось, то работа алгоритма завершается. На основе текущего списка аффиксов формируется список гипотетических аффиксов.
-
3 шаг: Выполняется поиск всех гипотетический аффиксов в словаре аффиксов. Все найденные аффиксы добавляются в список аффиксов. Если ни один новый аффикс не найден, то переходим к шагу 2.
-
4 шаг: Выполняется поиск начальной части слова в словаре начальных форм. Если слово не найдено, то переходим к шагу 2.
-
5 шаг: В результат добавляется найденная основа и сопутствующий набор аффиксов. Переход к шагу 2.
После нормализации для каждого найденного слова осуществляется вычисление его морфологических характеристик на основе его аффиксов и морфологического класса основы.
Продемонстрируем результат морфологического анализа на следующем примере (рис. 5).
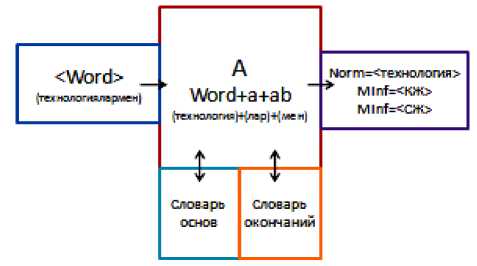
Рис. 5. Пример морфологического анализа слова
На вход анализатору подается словоформа технологиялармен , происходит поиск в словарях аффиксов мен, лар и основы технология . На основе морфологического класса основы (зат есім) и аффиксов вычисляем морфологическую информацию: лар <мн.число>, мен <род.падеж>.
Казахский язык характеризуется строгой последовательностью присоединения аффиксов к корню: вначале присоединяется словообразовательный аффикс, потом словоизменяющие аффиксы: принадлежности, падежей, лица и числа. Для имен существительных к основе слова вначале добавляется окончание множественного числа, затем притяжательное окончание, далее следует падежное окончание и последним – окончание формы спряжения [13]. Окончания прибавляются по правилу, которое можно представить следующим образом:
С=ОС+КЖ+ТЖ+СЖ+ЖЖ, (1) где С – словоформа; ОС – основа слова; КЖ – окончание множественного числа; ТЖ – притяжательное окончание; СЖ – падежное окончание; ЖЖ – окончание формы спряжения [15].
К особенностям казахского языка относится необходимость определения некоторых морфологических характеристик слова по контексту, т.е. словам, находящимся до или после данного слова. Например, время глагола или деепричастия может быть определено по слову, стоящему соответственно до или после, а превосходную степень прилагательного определяют по специальным словам, таким как ең, өте, аса, тым и т.д.
Нормальная форма слова – это одна из форм слова (строка), принятая для обозначения понятия, связанного с данным словом. Словоформа – это форма слова, связанная с нормальной формой слова и указывающая на особенности употребления данного слова.
Формально словоформа характеризуется пятеркой вида:
Wform =
