Подход к разграничению доступа в информационных системах на основе интеллектуального анализа данных

Автор: Краснов Сергей Александрович, Нечай Александр Анатольевич, Бамбурова Ольга Николаевна
Рубрика: Управление сложными системами
Статья в выпуске: 4, 2021 года.
Бесплатный доступ
Рассматриваются различия между тематическим разграничением доступа и другими известными политиками безопасности, обосновывается выбор тематического подхода. Представлена модель подхода к тематическому разграничению доступа на основе интеллектуального анализа данных. Приведено сравнение существующих методов интеллектуального анализа данных и предложено использовать нейронные сети в качестве решения задачи классификации при тематическом подходе к разграничению доступа.
Тематическое разграничение доступа, политика безопасности, интеллектуальный анализ данных, информационные системы, нейронные сети
Короткий адрес: https://sciup.org/148323539
IDR: 148323539 | УДК: 004.056 | DOI: 10.18137/RNU.V9187.21.04.P.095
An approach to declining access in information systems based on intellectual data analysis
This paper discusses the differences between thematic access control and other well-known security policies, justifies the choice of the thematic approach. A model of approach to thematic access control based on data mining is proposed. A comparison of the existing data mining methods is given and it is proposed to use neural networks as a solution to the classification problem in the proposed thematic approach to access control.
Текст научной статьи Подход к разграничению доступа в информационных системах на основе интеллектуального анализа данных
Технология защиты информационных систем (далее – ИС) начала развиваться относительно недавно, но сегодня уже существует значительное число теоретических моделей, позволяющих описывать различные аспекты безопасности и обеспечивать средства защиты формально подтвержденной алгоритмической базой. Формальные модели безопасности позволяют решить целый ряд задач, возникающих в ходе проектирования, разработки и сертификации защищенных систем, поэтому их используют не только теоретики информационной безопасности, но и другие категории специалистов, участвующих в процессе создания и эксплуатации, защищенных ИС (производители, потребители, эксперты).
Важным аспектом, присутствующим в практике разграничения доступа (далее – РД) к «бумажным» ресурсам является тематическая окрашенность информационных ресурсов предприятий, учреждений по организационно технологическим процессам и профилям деятельности. Организация доступа сотрудников к информационным ресурсам организации (в библиотеках, архивах) осуществляется на основе тематических классификаторов. Все документы информационного хранилища тематически индексируются, то есть соотносятся с теми или иными тематическими рубриками классификатора [1]. Сотрудники предприятия согласно своим функциональным обязанностям или по другим основаниям получают права работы с документами определенной тематики. Данный подход,
Краснов Сергей Александрович кандидат технических наук, доцент кафедры информационной безопасности. Санкт-Петербургский государственный электротехнический университет «ЛЭТИ» имени В.И. Ульянова (Ленина), Санкт-Петербург. Сфера научных интересов: информационная безопасность, системы искусственного интеллекта. Автор более 40 опубликованных научных работ.
в сочетании с избирательным и мандатным доступом, обеспечивает более адекватную и гибкую настройку системы РД на конкретные функционально-технологические процессы, предоставляет дополнительные средства контроля и управления доступом.
Отличие тематического РД от других моделей, регулирующих доступ
Существующие методы и средства управления доступом с использованием различных моделей политики безопасности (далее – ПБ) весьма разнообразны, к ним относятся базовые ПБ – дискреционного, мандатного, ролевого РД и расширенные – смешанные методы РД.
Описанные выше известные модели доступа, а также их разновидности основаны на присвоении объектам контроля доступа некоторых меток безопасности или атрибутов. Однако пользователи заинтересованы в управлении доступом к информации, представленной в документах, базах данных, на основе ее содержания [3]. Для достижения этой цели существует тематическая политика доступа.
Как и при мандатном доступе, тематический принцип определяет доступ субъекта к объекту неявно, через соотношение предъявляемых специальных характеристик субъекта и объекта и, соответственно, по сравнению с дискреционным принципом существенно упрощает управление доступом. Отличительной особенностью тематического РД является возможность создания не линейного порядка классов, а частичного, задаваемого, в частности, иерархическими деревьями [4].
Стремление расширить мандатную модель для отражения тематического принципа РД, применяемого в государственных организациях многих стран, привело к использованию более сложных структур, чем линейная решетка уровней безопасности, именуемых
Подход к разграничению доступа в информационных системах на основе ...
MLS-решетками. MLS-решетка является произведением линейной решетки уровней безопасности и решетки подмножеств множества категорий (тематик).
В общем плане принцип тематической ПБ можно пояснить схемой, приведенной на Рисунке 1 [1; 2].
Анализ библиотечных и других автоматизированных систем документального поиска, основанных на тематическом индексировании содержания документов (текстов), показывает, что определяющее значение в таких системах имеет тематико-классификационная схема, в большинстве случаев именуемая тематическим рубрикатором [6–8]. Применяются три основных способа тематической классификации:
-
• перечислительная классификация (дескрипторный подход);
-
• систематизированная классификация (иерархический подход);
-
• аналитико-синтетическая классификация (фасетный подход).
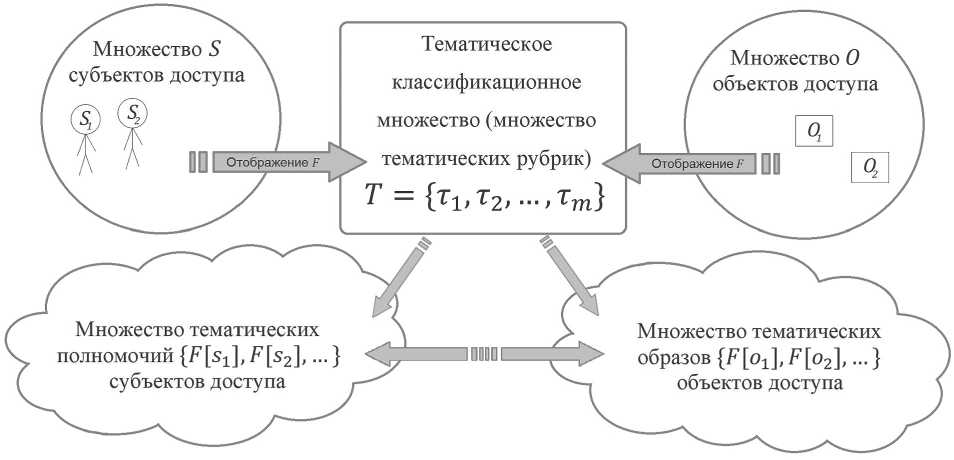
Рисунок 1. Общий принцип тематической политики безопасности
При дескрипторном подходе классификационная схема представляет перечень тематик (рубрик), произвольной совокупностью которых можно отразить содержание конкретного документа. При этом тематики имеют никаких отношений между собой [5]. Доступ субъекта к объекту дается в случае доступа ко всему набору тематик этого объекта.
При иерархическом подходе тематико-классификационная схема представляет корневую древовидную структуру, устроенную наподобие таксономической иерархии. Тематика документа определяется тематическими узлами классификатора с автоматическим распространением на объект классификации всех соответствующих подчиненных тематических узлов. Субъекту предоставляется доступ к объекту в случаях, если его тематики соответствуют одному или нескольким узлам классификатора или их подчиненным узлам.
При фасетной классификации, которую также называют классификацией двоеточием или классификацией Ранганатана, основу составляет определенное количество тематических блоков-фасет, отражающих логику соответствующей предметной сферы [15]. Каждый фасет, в свою очередь, представляет классификационную подсистему тематик иерархического типа [16]. Тематика конкретного информационного объекта строится на основе сочетания тематических узлов фасетных рубрик [17]. Этот метод можно сравнить с фильтрацией по различным не связанным между собой признакам [18]. При этом раз- личные документы могут соответствовать нескольким фильтрам одновременно, а сами фильтры могут содержать в себе несколько различных критериев [19]. Права доступа в случае с фасетной классификацией определяются объединением всех рубрик, к которым данный субъект имеет доступ.
Общее правило предоставления доступа субъекта к объектам по всем способам классификации следующее: объект доступен субъекту, если он не содержит тематик, запрещенных (не разрешенных) для данного субъекта.
Модель предлагаемого подхода к тематическому РД
Задействование тематического подхода для РД требует правил или механизмов для процесса соотнесения данных с установленными для системы темами. Поскольку рассматриваются главным образом текстовые данные, эту проблему можно приравнять к задаче автоматической рубрикации, или автоматической классификации текстов.
Математическую постановку задачи классификации документов по темам можно сформулировать следующим образом. Пусть O = {о1,о2,...0|O|} - конечное множество объектов (документов), С = {c1, c2, ^ C|C|} - известное конечное множество классов (тематика, рубрик). Между данными множествами существует некоторая зависимость, представлен- ная отображением f: O ^ С . Необходимо построить алгоритм, способный классифицировать случайный объект о е O и максимально близко к f .
Ориентируясь на суть любой политики РД между субъектами и объектами и на определенную выше постановку задачи, сформулируем модель предлагаемого подхода к тематическому РД.
Пусть субъекту s е S доступен набор тем { c^ , c s 2 ,... c s } e C s , где C s с С . Объект о е O должен быть доступен субъекту s в том случае, если все темы из набора тем { c o , c o ,... c o n } е С о (где C o с С ), к которым относится объект о , доступны субъекту s . Иными словами, С о с С 5 . При этом определение множества тем С о решает задача классификации, которая определена выше.
Основываясь на введенных обозначениях, сформулируем g , определяющее доступ субъекта из множества S к объекту из множества O :
-
g: S ^ O О g ( O ) = Со с С: Со С С$.
Видно, что результатом g ( O ) является набор соответствующих объекту тем С о , значит, отображение g равнозначно упомянутому выше отображению f : O ^ С , решающему задачу классификации.
Таким образом, основой предложенной модели тематического РД является непосредственно процедура классификации объектов (текстов).
Существующие решения этой задачи можно разделить на три различных класса по принципу работы алгоритма определения тематики текста:
-
• использование логики какой-либо нейронной сети;
-
• статистическое представление текстов и дальнейшее использование аппарата математической статистики и теории вероятностей;
-
• структурный анализ текста (например, лексический, морфологический анализ) и последующее использование некоторых функций подобия.
Подход к разграничению доступа в информационных системах на основе ...
Для обучения систем автоматического анализа текстов необходимо применить либо автоматическое обучение, либо ручное обучение специальными экспертами [1].
Существующие решения задачи классификации, их преимущества и недостатки
Для решения задачи классификации на основе ИАД используются различные методы. Основные из них:
-
• классификация с помощью деревьев решений;
-
• байесовская (наивная) классификация;
-
• классификация при помощи искусственных нейронных сетей;
-
• классификация методом опорных векторов;
-
• статистические методы, в частности линейная регрессия;
-
• классификация при помощи метода ближайшего соседа;
-
• классификация методом рассуждения по аналогии (CBR-метод);
-
• классификация при помощи генетических алгоритмов.
Метод опорных векторов используется для бинарной классификации, что слишком уз-конаправлено в рамках модели тематического РД, поэтому этот метод не рассматривается в данной работе. Это же касается и любых линейных классификаторов, так как они решают исключительно задачи, которые обладают свойством линейной разделимости.
Для использования автоматического анализатора текстов рассмотрены стремительно развивающиеся методы ИАД, а их оценка сведена в Таблицу по категориям «чрезвычайно низкая», «очень низкая», «низкая», «низкая/нейтральная», «нейтральная/низ-кая», «нейтральная», «нейтральная/высокая», «высокая», «очень высокая».
Сравнительная характеристика методов ИАД
|
Алгоритм |
л h 0 £ |
8 0 g Рч s XD rt h 3 rt s |
8 0 Рч s h Ф Рч R Рч Ф h И S |
h 0 0 S' |
h ^ |
rt H о O' 3 и |
|
Классические методы |
Нейтр. |
Выс. |
Выс./нейт. |
Выс. |
Нейтр. |
Выс. |
|
Нейронные сети |
Выс. |
Низ. |
Низ. |
Низ. |
Нейт. |
Очень низ. |
|
Методы визуализации |
Выс. |
Очень выс. |
Выс. |
Выс. |
Очень выс. |
Чрезв. низ. |
|
Деревья решений |
Низ. |
Выс. |
Выс. |
Выс./нейт. |
Выс. |
Выс./нейт. |
|
Полиномиальные нейронные сети |
Выс. |
Нейт. |
Низ. |
Выс./нейт. |
Нейт./низ. |
Низ./нейтр. |
|
k -ближайшего соседа |
Низ. |
Очень низ. |
Выс./нейт. |
Нейт. |
Нейт./низ. |
Выс. |
Как видно из таблицы, каждый из методов имеет свои сильные и слабые стороны. Но ни один метод, какой бы ни была его оценка с точки зрения присущих характеристик, не может обеспечить решение всего спектра задач ИАД. Большинство инструментов ИАД, предлагаемых сейчас на рынке программного обеспечения, реализуют несколько методов.
По итогам рассмотренных существующих методов сделан вывод, что нейронные сети обладают наиболее существенными преимуществами и наименее значительными недостатками в обобщенном случае в рамках рассматриваемой модели тематического РД. Од- нако стоит отметить, что выбор метода ИАД для использования в конкретной информационной системе должен базироваться на оценивании предметной области и самого исходного набора данных, поэтому для частных случаев более оптимальным выбором может оказаться любой из существующих методов.
Использование нейронной сети в рассматриваемой модели тематического РД
Главным элементом нейронной сети является нейрон. Главной функцией искусствен- ного нейрона является формирование выходного сигнала Y в зависимости от сигналов, поступающих на его входы {x1,x2,,..,xn }. В самой распространенной конфигурации входные сигналы обрабатываются адаптивным сумматором [3], затем выходной сигнал сумматора поступает в нелинейный преобразователь, где преобразуется функцией активации, и результат подается на выход (в точку ветвления).
n
^ w i x i , где
Текущее состояние нейрона определяется как взвешенная сумма его ходов i=1
wi - вес синапсов [3]. Выходом нейрона является функция его состояния f (5), которая представляет из себя некоторую нелинейную функцию. Выбор активационной функции определяется спецификой поставленной задачи или ограничениями, накладываемыми некоторыми алгоритмами обучения.
По способу соединения нейронов выделяют сети с разной архитектурой: персептро- ны, сети адаптивного резонанса, рециркуляционные, рекуррентные, встречного распространения, ИНС с обратными связями Хэмминга и Хопфилда, двунаправленной ассоциативной памятью, радиально-базисной функцией активации, самоорганизующиеся ИНС Кохонена и др.
Выбранная или разработанная нейронная сеть должна выполнять роль классификатора в модели тематического РД. На первом этапе решения задачи классификации происходит обучение нейронной сети. В качестве образов для обучения в случае с тематической моделью РД могут выступать разные по своему виду документы. При обучении сети предлагаются различные образцы с указанием того, к какому классу они относятся. Образец, как правило, представляется как вектор значений признаков. При этом совокупность всех признаков должна однозначно определять класс, к которому относится образец. По окончании обучения сети ей можно предъявлять неизвестные ранее образы и получать ответ о принадлежности к определенному классу.
Топология такой сети характеризуется тем, что количество нейронов в выходном слое, как правило, равно количеству определяемых классов. При этом устанавливается соответствие между выходом нейронной сети и классом, который он представляет.
Ошибка обучения для построенной нейронной сети вычисляется путем сравнения выходных и целевых (желаемых) значений. Из полученных разностей формируется функция ошибок, с помощью которой можно оценить качество работы нейронной сети во время обучения.
При подготовке данных для обучения нейронной сети необходимо обратить особое внимание на нормализацию данных. Целью нормализации значений является преобразование данных к виду, который наиболее подходит для обработки, то есть данные, поступающие на вход, должны иметь числовой тип, а их значения должны быть распределены в определенном диапазоне [3]. Нормализация может приводить дискретные данные к набору уникальных индексов либо преобразовывать значения, лежащие в про-
Подход к разграничению доступа в информационных системах на основе ...
извольном диапазоне, в конкретный диапазон. Нормализация выполняется путем деления каждой компоненты входного вектора на длину вектора, что превращает входной вектор в единичный.
Существует множество разнообразных готовых решений программного обеспечения (далее – ПО) для работы с нейронными сетями. Такое ПО называется нейросимулятором, или нейропакетом. Большинство нейропакетов включают следующую последовательность действий [3]:
-
• создание сети (выбор пользователем параметров либо одобрение установленных по умолчанию);
-
• обучение сети;
-
• выдача пользователю решения.
Среди специализированных нейропакетов можно назвать, например, такие, как BrainMaker, NeuroOffice, NeuroPro.
При выборе конкретной предметной области информационной системы подразумевается создание и обучение собственной нейронной сети, более узко ориентированной на задачи конкретного набора данных и классов.
Существуют основополагающие принципы, которыми следует руководствоваться при разработке новой конфигурации [3].
-
1. Возможности сети возрастают с увеличением числа ячеек сети, плотности связей между ними и числом выделенных слоев.
-
2. Введение обратных связей наряду с увеличением возможностей сети поднимает вопрос о динамической устойчивости сети.
-
3. Сложность алгоритмов функционирования сети (в том числе, например, введение нескольких типов синапсов – возбуждающих, тормозящих и др.) также способствует усилению мощи нейронной сети.
Вопрос о необходимых и достаточных свойствах сети для решения того или иного рода задач представляет собой целое направление нейрокомпьютерной науки. Процесс функционирования нейронной сети, то есть сущность действий, которые она способна выполнять, зависит от величин синаптических связей, поэтому, задавшись определенной структурой нейронной сети, отвечающей конкретной задаче, разработчик сети должен найти оптимальные значения всех переменных весовых коэффициентов.
Заключение
В настоящей работе проанализированы существующие модели РД и выяснено, что для некоторых пользователей есть необходимость в управлении доступом на основе содержания информации, что обеспечивает тематическая модель РД. Кроме того, в ходе выполнения работы были рассмотрены методы ИАД, приведен их сравнительный анализ и сделан вывод, что ни один из методов нельзя признать единственно эффективным, имеющим очевидное превосходство над другими методами. Для решения задачи классификации в рамках тематического РД к текстовым данным предложен подход, основанный на классификаторе в виде нейронной сети. В дальнейшем исследования будут направлены на повышение эффективности функционирования классификатора путем исследования влияния алгоритмов предварительной обработки данных на результат точности и полноты классификации [9–14].
Список литературы Подход к разграничению доступа в информационных системах на основе интеллектуального анализа данных
- Бабошин В.А., Нечай А.А., Вылегжанин А.Н. Цифровая трансформация телекоммуникационных систем железнодорожной отрасли // Специальная техника и технологии транспорта: сборник научных статей. СПб.: Петергоф, 2021. С. 180–188.
- Баглюк С.И., Нечай А.А. К вопросу о выборе исходных данных при автоматизации тестирования программ // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2020. № 4. С. 103–107.
- Баранов Ю.А. Тематическое разграничение доступа в информационно-поисковой системе на основе авторубрикации: автореф. дис. … канд. техн. наук. СПБ., 2009. 29 с.
- Бубнов В. П. Модели информационных систем: учебное пособие. М.: Учебно-методический центр по образованию на железнодорожном транспорте, 2015. 188 с.
- Гайдамакин Н.А. Учебно-методический комплекс «Теоретические основы компьютерной безопасности». Екатеринбург: УрГУ, 2008. 212 с.
- Краснов С.А. О возможности смыслового анализа информации для выявления информационных интересов пользователей // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2019. № 2. С. 157–163.
- Краснов С.А., Борисов А.А., Нечай А.А. Технология блокчейн и проблемы ее применения в различных информационных системах // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2018. № 2. С. 63–67.
- Краснов С.А., Нечай А.А. Аналитическая модель обеспечения информационной безопасности образовательных организаций системы общего и среднего образования // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2020. № 4. С. 77–84.
- Макаренко С.И., Ковальский А.А., Краснов С.А. Принципы построения и функционирования аппаратно-программных средств телекоммуникационных систем: учебное пособие. Ч. 2. Сетевые операционные системы и принципы обеспечения информационной безопасности в сетях. СПБ.: Наукоемкие технологии, 2020. 357 с.
- Модели и методы исследования информационных систем: монография / А.Д. Хомоненко, А.Г. Басыров, В.П. Бубнов, А. В. Забродин, С. А. Краснов [и др.]; под общ. ред. А.Д. Хомоненко. СПБ.: Лань, 2019. 204 с.
- Нечай А.А., Котиков П.Е. Актуальные проблемы защиты информации в современных автоматических телефонных станциях // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2015. № 2. С. 65–69.
- Нечай А.А., Котиков П.Е. Методика комплексной защиты данных, передаваемых и хранимых на различных носителях информации // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2015. № 1. С. 92–95.
- Применение Big Data для анализа околоземного космического пространства / А.И. Гладышев, А.И. Зимовец, А.А. Нечай, А.В. Обухов // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2020. № 4. С. 127–134.
- Свидетельство о регистрации программы для ЭВМ RU 2016619650. Программное средство анализа распределенной информации / Калиниченко С.В., Краснов С.А., Илатовский А.С. 2016.
- Свидетельство о регистрации программы для ЭВМ RU 2019616036. Программное средство выявления ключевых признаков негативного интернет-контента в мультимедийных объектах на основе метода латентно-семантического анализа с динамическим определением ранговых значений / Пилькевич С.В., Гнидко К.О., Сабиров Т.Р., Лохвицкий В.А., Краснов С.А., Дудкин А.С., Иванов О.С. 2019.
- Свидетельство о регистрации программы для ЭВМ RU 2019616488. Программное средство разработки онтологических моделей стратифицированного представления состояний сложных иерархических систем / Пилькевич С.В., Гнидко К.О., Сабиров Т.Р., Лохвицкий В.А., Краснов С.А., Дудкин А.С., Иванов О.С. 2019.
- Синтез модели автоматизированной информационной системы радиоэлектронного мониторинга объектов наблюдения на основе логико-алгебраического подхода / Е.Г. Мысливец, И.А. Пучкова, А.А. Нечай, Д.А. Антонов // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2020. № 4. С. 135–142.
- Чубукова И.А. Электронная книга Data Mining / Интернет-университет информационных технологий (ИНТУИТ). Бином. Лаборатория знаний, 2008. 383 с.
- Krasnov S., Lokhvitckii V., Dudkin A. (2020) On the applicability of the modernized method of latent-semantic analysis to identify negative content in multimedia objects. Studies in Computational Intelligence, vol. 868, pp. 224–229.
