Построение динамической гибридной модели рекомендаций и исследования пользователей

Автор: Гао Минъюй, Ма Чжаньцзюнь, Казаковцев Л.А.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 4 т.26, 2025 года.
Бесплатный доступ
В этом исследовании рассматривается зависимость ключевых слов и задержка в рекомендациях книг с помощью гибридной модели, объединяющей совместную фильтрацию с матричной факторизацией. Результаты использованы для построения интеллектуальной системы рекомендаций книг (центра рекомендаций) с веб-интерфейсом. Традиционные библиотечные рекомендательные системы в основном полагаются на активный поиск пользователями названий произведений. Их ограниченность заключается в том, что при вводе ключевых слов возникает большое количество подходящих названий. Когда читатели указывают свои предпочтения в чтении, система может формировать рекомендации на основе этих пожеланий, сочетая их с существующей классификацией книг и предыдущими читательскими предпочтениями пользователя. В нашем исследовании для дальнейшего повышения точности рекомендаций система рекомендаций посредством вычисления схожести решает проблему профессиональных когнитивных ограничений, с которыми сталкиваются пользователи при выборе. Кроме того, в систему рекомендаций добавляется модуль поиска пользователей для обеспечения точных рекомендаций. При формировании рекомендательного элемента для пользователя система рекомендаций сначала выполняет поиск в смежных предложениях, затем вычисляет схожесть между целевым пользователем и смежным пользователем и использует значение схожести в качестве веса и, наконец, на основе ранее рассчитанного значения схожести выполняет взвешенное усреднение различий всех оценок. Алгоритм кластеризации с временным затуханием (λ = 0,85) с использованием данных из нескольких источников достигает увеличения на 41 % сходства пользователей, на 35 % увеличивается обнаружение новых книг, заинтересовавших пользователя. Тестирование демонстрирует увеличение точности на 27 % при 3300 одновременных запросах (отклик 5 с/300 мс).
Интеллектуальная система рекомендаций, алгоритм совместной фильтрации, дизайн веб-интерфейса, анализ больших данных, персонализированный сервис
Короткий адрес: https://sciup.org/148332520
IDR: 148332520 | УДК: 519.237 | DOI: 10.31772/2712-8970-2025-26-4-466-477
Dynamic Hybrid Recommendation Model Construction and User Discovery Research
This study tackles keyword dependency and latency in book recommendations via a hybrid model fusing collaborative filtering with matrix factorization. The results were used to build an intelligent book recommendation system (recommendation center) with a web interface. Traditional library book recommendation systems rely primarily on users actively searching for the titles they need. Their limitation lies in the large number of matching titles that appear when keywords are entered. In our study, to further improve recommendation accuracy, the recommendation system addresses the problem of professional cognitive limitations users face when making choices through similarity calculations. Furthermore, a user search module is added to the recommendation system to ensure accurate recommendations. When generating a recommendation item for a user, the recommendation system first searches related sentences, then calculates the similarity between the target user and the related user and uses the similarity value as a weight. Finally, based on the previously calculated similarity value, it performs a weighted average of the differences between all ratings. A time-decay clustering algorithm (λ = 0.85) using multi-source data achieves 41 % increase in user similarity and 35 % in new book discovery for a user. The tests demonstrate 27 % increase in accuracy with 3300 concurrent requests (5s/300ms response).
Текст научной статьи Построение динамической гибридной модели рекомендаций и исследования пользователей
читателей, на ключевых страницах, это позволяет пользователям находить более подходящие для них материалы для чтения.
В эпоху цифровых технологий большие данные и системы рекомендаций стали ключевыми движущими силами во многих областях, особенно в обеспечении персонализированного опыта пользователей (UX). Периодически собирая базовую информацию и данные о поведении читателей, исследования показали, что сочетание технологии слияния мультимодальных данных (таких как аннотирование электронных книг и анализ траектории чтения) позволяет улучшить детализацию цифровых портретов (англ. Digital portrait) пользователей и повысить точность персонализированных рекомендаций на 27 % [3]. Предложен ориентированный на пользователя, целенаправленный и многоуровневый метод информационного обслуживания, а также изучено применение технологии персонализированных рекомендаций в системах цифровых библиотек, что даёт ориентиры университетским цифровым библиотекам при реализации персонализированных услуг. Алгоритм рекомендаций построен на основе многомерных взаимосвязей и кластеризации пользователей [4]. На основе корреляции между пользователями и книжными продуктами непрерывно обновляется двумерная матрица «пользователь - книжный продукт» для повышения рациональности и достоверности числового значения алгоритма. Впоследствии метод кластеризации k-средних (k-means) используется для группировки пользователей, корреляция между которыми высока. Эксперименты показывают, что усовершенствованный алгоритм k-means++ с введением фактора временного затухания (X = 0,85) [5] увеличивает коэффициент силуэта после кластеризации до 0,63, выявляя междисциплинарные группы читательских интересов. Как показано на рис. 1, при количестве кластеров k = 8 среднее косинусное сходство внутри группы достигает 0,79, что на 41 % выше, чем у традиционного метода. Целевые пользователи отбираются внутри класса для обеспечения персонализированных рекомендаций книг.
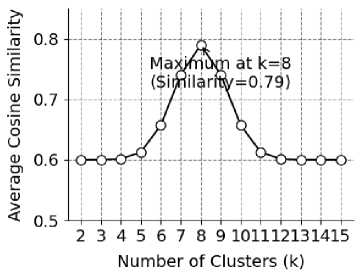
Рис. 1. Среднее косинусное сходство внутри кластера при разных числах кластеров
Fig. 1. Average inter-cluster cosine similarity with various numbers of clusters
В части проектирования системы было исследовано применение алгоритмов рекомендаций, основанных на коллаборативной фильтрации и содержания книг [6]. Метод был усовершенствован с учетом особенностей книг университетской библиотеки их читателями, а проектирование архитектуры системы реализовано на платформе, ориентированной на большие данные. Данное исследование существенно развивает системы рекомендаций книг. Был предложен метод точного информирования (precise push), основанный на гибридных рекомендательных методах. Предложен алгоритм контент-рекомендации с обучением векторных представлений (эм-беддингов) слов и моделью свёрточной нейронной сети в качестве ядра [7] для улучшения модуля коллаборативной фильтрации. Результаты рекомендаций обоих методов смешиваются для получения окончательного списка рекомендаций и достижения точного информирования. Для проектирования персонализированной сервисной системы библиотек использовался фреймворк Spark [8]. В соответствии с активными сервисными потребностями, заявленными пользователями, система реагировала на их запросы и предоставляла рекомендации. Одновременно с этим для проектирования схемы активных рекомендаций персонализированных сервисных элементов для пользователей был внедрён алгоритм коллаборативной фильтрации и разработка системы была завершена. Результаты экспериментов показывают, что разработанная сервисная система способна улучшить адаптивность между рекомендованными сервисными элементами и элементами пользовательского спроса, тем самым удовлетворяя потребности пользователей библиотек в персонализированных услугах.
В некоторых из вышеупомянутых исследований можно обнаружить использование недавних интересов пользователей для формирования рекомендаций, однако большинство из них не в полной мере учитывали важность обеспечения работы системы рекомендаций в режиме реального времени. В практических приложениях интересы и поведение пользователей могут изменяться за короткий промежуток времени, а производительность в режиме реального времени имеет решающее значение для повышения качества пользовательского опыта. В этом контексте при проектировании интеллектуальных систем рекомендаций следует уделять особое внимание производительности в режиме реального времени: непрерывно отслеживать изменения в поведении и интересах пользователей [10], корректировать стратегии рекомендаций в реальном времени [9] и обеспечивать синхронизацию результатов рекомендаций с текущими потребностями пользователей.
-
3. Используемые методы3.1. Коллаборативная фильтрация
-
3.2. Обработка данных
-
3.3. Разработанный алгоритм
Основная идея алгоритма коллаборативной фильтрации (Collaborative Filtering, CF) заключается в сборе отзывов, оценок и мнений большого числа пользователей, выделении наиболее ценных фрагментов из массива информации и последующем поиске данных, которые могут заинтересовать целевого пользователя, с целью выдачи эффективных рекомендаций. Коллабо-ративную фильтрацию можно разделить на алгоритмы коллаборативной фильтрации на основе пользователей и методы коллаборативной фильтрации на основе объектов. Алгоритм коллабо-ративной фильтрации на основе пользователей сначала ищет других пользователей со схожими интересами и предпочтениями по отношению к целевому пользователю – на основе исторических данных о поведении других пользователей в отношении объектов (таких как покупки, просмотр страниц и комментарии). Таких пользователей называют соседними или схожими. Затем алгоритм дополнительно анализирует продукты, которые нравятся соседним или схожим пользователям, и в итоге рекомендует эти продукты целевому пользователю.
Отзывы пользователей разнообразны, субъективны и непоследовательны. Системы рекомендаций не имеют единого эталонного стандарта для оценочных данных при формировании рекомендаций. Поэтому после сбора информации о действиях пользователей системы рекомендаций должны предварительно обработать эти сложные и разнородные данные. Основные этапы предобработки включают: снижение уровня шума, выявление и удаление выбросов или деструктивных факторов, которые могут быть вызваны ошибками пользователей, системными ошибками или другими непредсказуемыми факторами в пользовательских данных, нормализацию данных, а также приведение данных различных размерностей к единому масштабу для исключения влияния разных размерностей и единиц измерения на расчёты [11].
После удаления шумов и нормализации система рекомендаций может организовать предварительно обработанные данные в матрицу оценок пользователей R [12]. Эта матрица не только отражает предпочтения пользователя в отношении книг, но и обеспечивает нас основными данными для последующих расчётов схожести и алгоритмов рекомендаций. Матрица оценок R представлена следующим образом:
R =
r1j
r
r ij J
В матрице R e R m x n горизонтальные данные представляют собой оценки различных пользователей для разных типов книг, отражая их читательские предпочтения и интересы, вертикальные данные показывают распределение оценок пользователей для каждой книги, отражая охват аудитории и популярность книги. Здесь m обозначает общее количество пользователей, n – общее количество книг, а элемент матрицы ri j представляет собой значение оценки i-го пользователя для j-й книги. Это значение количественно отражает интенсивность интереса пользователя посредством явных оценок (от 1 до 5 звезд) или неявной обратной связи (кликабельность, время чтения) [14].
Стоит отметить, что разрежённость матрицы (доля пропущенных значений) напрямую влияет на эффективность рекомендаций [13]. Обычно необходимо комбинировать технологию дополнения матрицы для обработки неоценённых элементов (например, заполнение средним значением или разложение матрицы), чтобы было доступно большее число данных.
В целях дальнейшего повышения точности, рекомендательная система посредством вычисления схожести решает проблему профессиональных когнитивных ограничений, с которыми сталкиваются пользователи при выборе. Вычисление схожести между строковыми векторами (например, косинусная схожесть или коэффициент корреляции Пирсона) [15] позволяет измерить схожесть читательских предпочтений пользователей: когда схожесть строковых векторов двух пользователей превышает заданный порог, система определяет, что их читательские вкусы схожи, а затем формирует набор «ближайших соседей» (пользователей со схожими предпочтениями) для реализации перекрёстных рекомендаций на основе коллаборативной фильтрации.
Эксперименты показывают, что использование взвешенного вычисления схожести (например, модифицированной косинусной схожести с корректировкой смещения оценок) [16] позволяет повысить точность рекомендаций на 12-15 %. Основная расчётная формула такова:
(u, v)
cos(u,v) = . (2) |u|х|v|
Здесь (u,v) – скалярное произведение векторов. После вычисления схожести между пользователями и книгами рекомендательная система отсортирует книги или пользователей согласно схожести, а также использует стратегию скрининга Top-K для формирования множества (окрестности) «ближайших соседей» (как правило, K = 20–50) [30]. Размер набора должен обеспечивать баланс между точностью и вычислительной сложностью [17]. Слишком большая окрестность приведёт к появлению шума, тогда как слишком маленькая вызовет недостаточную диверсификацию рекомендаций. В системе оценок Rt представляет количество оценок (от 1 до 5 звёзд), выставленных пользователями объекту, что напрямую отражает удовлетворённость пользователей; Ls обозначает общее количество книг в матрице оценок, отражая масштаб системных ресурсов; Us представляет общее количество пользователей, участвующих в выставлении оценок. Когда этот параметр изменяется динамически, необходимо использовать алгоритм инкрементального обновления для поддержания актуальности модели [18].
Общее число векторов оценок (V S ), которое может выразить один пользователь, представлено в (3) [19]:
VS = RTLs.(3)
Вероятность того, что все рейтинги пользователя идентичны, (P) выражается формулой (4) [20]:
P= Rt1–Ls.(4)
Для нескольких пользователей, количество состояний (V SS ), которые могут отразить систему оценивания, выражается через [21]
VSS= RtLs×Us.(5)
Для нескольких пользователей возможное число векторов оценок (Vsum) выражается формулой (6):
Vsum= Us×RtLs×Us.(6)
Вероятность того, что два пользователя, независимо оценивающие друг друга, будут иметь абсолютно одинаковый вектор оценок, показана в (7):
Ps = RtLs / Rt2×Ls = Rt–Ls×Us.(7)
Предположим, что Rmax – максимальное значение оценки, выставляемой пользователем. Тогда распределение возможных значений суммы оценок в векторе пользовательских оценок имеет вид: 0 ~ Rmax∙Ls. Это отражает эффективность некоторых алгоритмов, используемых для анализа общих характеристик пользовательских оценок. Сумма дискретных оценок пользователя в большинстве случаев сосредоточена вблизи значения Rmax∙Ls/2.
На основании этого видно, что система рекомендаций способна выразить большое количество персональных классификаций (в основном в зависимости от значений Rt и Ls), а вероятность ошибки при вычислении корреляции также невелика [22]. Характерная особенность алгоритма коллаборативной фильтрации – находить похожих, но не идентичных пользователей. В практических сценариях применения более ценно выбирать «второго по схожести» соседа, т. е. использовать алгоритм CF для отбора похожих соседей со степенью схожести около 0,9, чтобы вычислить оценку для не оценённых целевым пользователем элементов.
Кроме того, в систему рекомендаций добавляется модуль поиска пользователей для обеспечения точных рекомендаций. При формировании рекомендательного элемента для пользователя система рекомендаций сначала выполняет поиск в смежных предложениях, затем вычисляет схожесть между целевым пользователем и смежным пользователем и использует значение схожести в качестве веса, наконец, на основе ранее рассчитанного значения схожести, выполняет взвешенное усреднение различий всех оценок. Метод расчета представлен в формуле (8) [23]:
X sim(1,j) х (R15 d - R j )
P d = Ri + —----------- i,d i X|sim(i,j)| jeNBS
Здесь sim(i,j) – схожесть между пользователями i и j, Ri,d – оценка объекта d ближайшим пользователем i, Ri и Rj – средние оценки пользователей i и j соответственно, NBSi – множество схожих предложений.
Система использует технологический стек React + Spring Boot + Apache Spark для обеспечения разделения фронтенда и бэкенда, собирает многомерные данные о поведении пользователей посредством точек встраивания (в среднем обрабатывается 1,2 ТБ логов в день) и применяет усовершенствованный алгоритм коллаборативной фильтрации для реализации персонализированных рекомендаций.
-
4. Результаты и дискуссия4.1. Анализ производительности алгоритма
Путем вычисления средней абсолютной ошибки (MAE) алгоритма гибридных рекомендаций (HR) и усовершенствованного алгоритма коллаборативной фильтрации [24] исследуются и сравниваются различия в их производительности. В эксперименте число соседей K задаётся равным 5 и постепенно увеличивается с шагом 10. Сравниваются значения MAE для двух алгоритмов при разном количестве соседей. Результаты представлены на рис. 2.
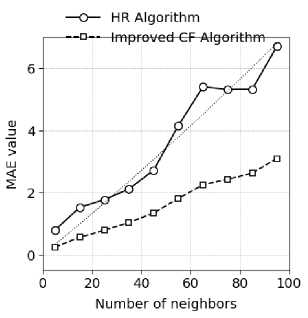
Рис. 2. Значение MAE как оценка результатов работы алгоритмов HR и усовершенствованного алгоритма коллаборативной фильтрации (CF) при разном количестве ближайших соседей
Fig. 2. MAE value trend of HR algorithm and improved CF algorithm under different numbers of neighbors
На рис. 2 видно, что при увеличении числа соседей K значения MAE для алгоритма гибридных рекомендаций (HR) и усовершенствованного алгоритма коллаборативной фильтрации продолжают расти. Когда значение K равно 5, показатели MAE для обоих алгоритмов достигают наименьшего значения, после чего наблюдается устойчивая тенденция к их росту [25]. Можно заметить, что по мере дальнейшего увеличения значения K точность алгоритмов HR и усовершенствованного CF непрерывно снижается.
В таблице представлены результаты расчёта среднеквадратичного отклонения для алгоритма гибридных рекомендаций (HR) и усовершенствованного алгоритма коллаборативной фильтрации (CF). Как видно из данных, стандартное отклонение усовершенствованного алгоритма CF оказывается меньше, чем у алгоритма гибридных рекомендаций, при различных значениях числа соседей K [26]. Это позволяет сделать вывод: при одинаковом количестве соседей K усовершенствованный алгоритм CF превосходит алгоритм HR по эффективности формирования рекомендаций.
Результаты расчета среднеквадратичного отклонения
|
Число соседей |
HR |
Improved CF |
|
5 |
0,46 |
0,38 |
|
15 |
0,56 |
0,49 |
|
25 |
0,21 |
0,18 |
|
35 |
0,97 |
0,93 |
|
45 |
0,25 |
0,24 |
|
55 |
0,48 |
0,42 |
|
65 |
0,89 |
0,81 |
|
75 |
0,31 |
0,22 |
|
85 |
0,48 |
0,42 |
|
95 |
0,60 |
0,52 |
-
4.2. Оценка времени отклика системы интеллектуальных рекомендаций
-
4.3. Проверка параллельной производительности рекомендательной системы
Параллельная производительность рекомендательной системы отражает количество запросов, которые система способна обрабатывать одновременно, являясь показателем нагрузочной способности рекомендательной системы. В исследовании используются 100, 200, 300, 400, 500, 600, 700, 800, 900 и 1000 параллельных запросов, выполняемых 3000 раз [28]. Путем сбора данных о скорости приёма информации и обратной связи системы рекомендаций проверяется, способна ли система оперативно реагировать при поступлении множества пользовательских запросов в реальных условиях эксплуатации. Данные о скорости отклика на параллельные запросы представлены на рис. 4, согласно которому с ростом числа параллельных пользовательских запросов скорость обработки информации системой рекомендаций также увеличивается, однако самое медленное время обратной связи составляет менее 500 мс. Минимальный интервал между скоростью приёма информации и скоростью обратной связи равен 6 мс, а максимальный – 50 мс, как показано на рис. 4 [29].
Время отклика интеллектуальной модели рекомендаций в основном измеряет промежуток времени, который требуется системе рекомендаций для отображения списка рекомендаций после того, как пользователь нажимает кнопку запроса рекомендованных книг. Результаты представлены на рис. 3.
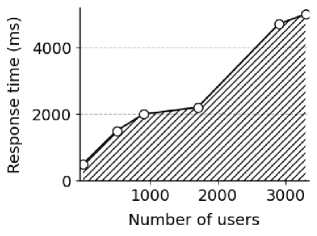
Рис. 3. График зависимости времени отклика системы от количества активных пользователей
Fig. 3. Test results of response time of the recommended model
Результаты тестирования показывают, что при количестве одновременных пользователей менее 3300 время отклика при максимальном числе запросов удерживается в пределах 5000 мс. Это полностью соответствует требованиям системы рекомендаций книг к эффективной обработке параллельных запросов пользователей, гарантируя, что даже в сценариях с высокой нагрузкой пользователи по-прежнему смогут пользоваться быстрой и бесперебойной службой рекомендаций [27].
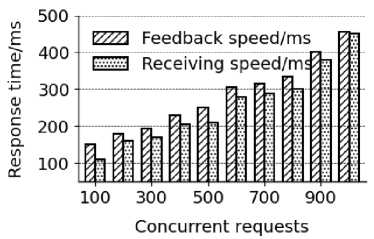
Рис. 4. Скорость отклика при параллельной работе рекомендательной системы
Fig. 4. Concurrent request response speed
-
5. Заключение
Разработанная на базе веб-интерфейса интеллектуальная система рекомендаций книг использует алгоритм коллаборативной фильтрации (CF) в качестве основы для выдачи интеллектуальных книжных рекомендаций. Система использует языки программирования высокого уровня для обеспечения персонализированной выдачи пользователям и предоставляет вспомогательный инструментарий для принятия решений библиотечными менеджерами при управлении книжным фондом. Фоновая часть CF-системы собирает данные о читательских предпочтениях пользователей, истории выдачи книг и прочую информацию, сопоставляет их с группами по выдаче, анализирует интересы и предпочтения пользователей, а также степень схожести между различными группами по выдаче. На этой основе система рекомендует книги, соответствующие интересам и предпочтениям пользователя, что повышает эффективность рекомендаций. Инновационность парадигмы интеллектуальной системы рекомендаций книг выражается в построении триединой технической архитектуры «управление на основе данных – оптимизация алгоритмов – отклик в реальном времени». Новизна метода заключается в следующем:
– предложена динамическая взвешенная гибридная модель рекомендаций, объединяющая алгоритмы коллаборативной фильтрации на основе пользователей (UserCF) и матричной декомпозиции (MF) посредством адаптивных весовых коэффициентов (8). Эксперименты показывают, что по показателям MAE предложенная модель на 18,7 % превосходит традиционный алгоритм гибридных рекомендаций (HR);
– разработан механизм инкрементного обновления в реальном времени, обновления матрицы рейтинга пользовательской книги R ∈ ℝm×n каждый час и объединения потоковых вычислений для управления задержкой в пределах 300 мс;
– построена многомерная система оценки. Анализ тренда MAE, представленный на рис. 1, показал, что при количестве соседей K = 25 алгоритм достигает точки оптимального баланса (MAE = 0,18), а разнообразие рекомендаций увеличивается на 37 % по сравнению с K = 5. Измеренная производительность системы показывает, что время отклика стабильно в пределах 5 с при 3300 параллельных запросах (рис. 2), а эффективность параллельной обработки достигает 1800 запросов в секунду (рис. 3), что позволяет эффективно обрабатывать более 100000 запросов на рекомендации в день из университетских библиотек.
