Построение EDA-системы на основе синхронизированных параллельных процессов

Автор: Богданов К.В., Ловчиков А.Н.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 4 (25), 2009 года.
Бесплатный доступ
Предложен новый подход к созданию EDA-систем, предназначенных для моделирования схем, содержащих элементы, функционирование которых связано с резким изменением параметров и при математическом описании приводит к существенному возрастанию производных фазовых переменных, что при традиционном моделировании ведет к срыву вычислительного процесса.
Моделирование, параллельные вычисления, eda-системы
Короткий адрес: https://sciup.org/148176052
IDR: 148176052 | УДК: 519.688
Сreating EDA systems based on synchronous parallel computing
In this article a new approach in modeling EDA systems is offered, containing elements the functioning of which is connected to sharp parameter changes; during a mathematical description it leads to an essential increase of the derivative phase variables. In traditional modeling this results in the failure of the computing process.
Текст краткого сообщения Построение EDA-системы на основе синхронизированных параллельных процессов
Моделирование и анализ работы электронного оборудования – весьма сложная задача, для решения которой активно используется специализированное программное обеспечение – EDA-системы. Их развитие идет по большей части экстенсивным путем, начиная от сис- тем, созданных в 70-х гг. прошлого столетия. Как правило, улучшаются пользовательские интерфейсы, расширяются базы данных электронных компонентов и т. п., в то время как основные вычислительные алгоритмы остаются прежними. Чаще всего все сводится к решению получив- шейся системы дифференциальных уравнений, являющейся математической моделью моделируемого устройства. Численные методы решения при этом позволяют получать весьма точные результаты, но при моделировании систем с большим количеством электронных компонентов возникают проблемы. Это приводит к усложнению математической модели и при моделировании систем с существенными нелинейностями значительно огрубляются результаты моделирования, что часто приводит к срыву вычислительного процесса.
В связи с этим предлагается диаметрально противоположный подход: каждый блок либо компонент устройства должен быть смоделирован отдельно. Полученные модели будут выполняться внутри отдельных вычислительных процессов. При этом, если мы рассматриваем моделирование в диапазоне времени, то каждый из таких вычислительных процессов должен получать на один или несколько своих логических входов некоторые параметры (например, мгновенное значение напряжения относительно принятой «земли»). Также этот процесс должен выдавать результаты обработки входных параметров в качестве выходных данных.
Основные проблемы, связанные с такой схемой работы, заключаются в том, что необходимо обеспечить высокую степень взаимной изолированности вычислительных процессов, сохраняя возможность синхронизированного обмена данными. Можно провести аналогию с современными вычислительными сетями, где каждая вычислительная машина максимально «самостоятельна», но имеет возможность обмениваться данными, разбитыми на пакеты, с любой другой машиной в сети в произвольный момент времени. Однако существенным отличием здесь будет являться то, что каждый процесс должен выдавать и принимать порцию информации строго по синхронизирующему сигналу. В том случае, если процесс не успевает по каким-либо причинам это сделать, возможны два подхода: ожидание и уничтожение. В первом случае ни одна порция данных от других процессов не будет принята, и не будет передана, пока от всех процессов модели не будет получен ответ. Во втором случае процессы, данные от которых не получены по истечении установленного времени, будут уничтожены либо перезапущены, а недостающие значения данных будут заменены на нулевые. Возможна и гибридная стратегия, когда процесс уничтожается после некоторого ожидания.
Реализация асинхронного обмена сообщениями, как это сделано, например, в вычислительных сетях на основе технологии Ethernet, может повлечь за собой серьезную проблему: результаты моделирования будут зависеть от производительности системы, и без предварительного профилирования реализовать модель не получится.
Как при асинхронном, так и при синхронном обмене необходим отдельный процесс-маршрутизатор. В его функции входит сбор данных от остальных процессов, уничтожение процессов, не выславших данные в течение отведенного времени, рассылка данных по процессам в соответствии с таблицей взаимосвязей (рис. 1).
Техническая реализация в этом случае требует наличия среды с определенными возможностями. Во-первых, в ней должно одновременно (параллельно) исполняться большое количество легковесных вычислительных процессов, которые будут реализовывать атомарные блоки системы. Во-вторых, она должна поддерживать обмен сообщениями между этими легковесными процессами.
Наиболее подходящей для реализации средой представляется Erlang компании Ericsson – функциональный язык программирования, позволяющий разрабатывать программное обеспечение для разного рода распределенных систем. Язык включает в себя средства порождения параллельных процессов и их коммуникации с помощью посылки асинхронных сообщений. Программа транслируется в байт-код, исполняемый виртуальной машиной, что обеспечивает переносимость. Функциональная парадигма позволяет Erlang избежать таких традиционных для императивных языков проблем распределенных приложений, как необходимость синхронизации, опасность возникновения тупиков и гонок.
Запущенный экземпляр эмулятора Erlang называется узлом. Узел имеет имя и «знает» о существовании других узлов на данной машине или в сети. Создание и взаимодействие процессов разных узлов не отличается от взаимодействия процессов внутри узла. Для создания про-
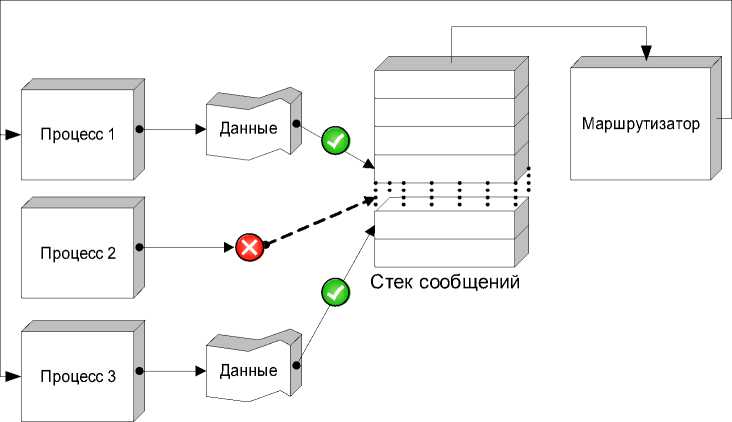
Рис. 1. Функционирование модели на основе независимых процессов
цесса на другом узле процессу достаточно знать его имя и без особых на то оснований он может не интересоваться физическим расположением взаимодействующего с ним процесса. Этим обусловливается высокая масштабируемость и способность почти линейного повышения производительности с ростом мощности системы (кластера).
Процессы, моделирующие каждый отдельный элемент схемы, смогут обмениваться сообщениями (кортежами) вида
{<имя корневого процесса>, <номер элемента>, <номер вывода>, <тип сигнала1>, <величина сигнала 1>…, <тип сигнала n>, <величина сигнала n>} .
Простейший процесс, моделирующий элемент схемы, на Erlang описывается следующим образ ом ( Server_Node – заранее определенное имя серв ера, modeling – имя исполняемой программы):
element(Server_Node) -> receive stop -> exit(normal);
{pin_number, signal1_type, signal1} -> % обработка входных значений %,
{modeling, Server_Node}!{self(), element_number, pin_number, signal1_type, signal1 } end.
Шаблон маршрутизатора выглядит следующим образом ( Element_List – список всех элементов):
server(Element_List) -> receive
{element_number, pin_number, signal1_type, signal1} -> % описание таблицы маршрутизации % element_number ! {pin_number, signal1_type, signal1 } end.
Разумеется, количество рассылаемых сообщений будет зависеть исключительно от топологии моделируемой системы, в примере показан простой случай без множественных соединений типа «один выход – много входов».
Очевидно, что для функционирования системы необходимо иметь несколько различных типов элементов: обычный процесс, коммутатор, источник, выход.
Обычный процесс (передаточная функция, пример реализации приведен выше). Обеспечивает преобразование входного потока данных в выходной. В каждый момент синхронизации обязан принять и передать одну порцию (кортеж) данных.
Коммутатор. Обеспечивает перераспределение сигналов по нескольким выходным каналам в зависимос- ти от соотношения количества входов и выходов. По сути является аналогом узла в электротехнике, но во избежание путаницы в терминологии будем называть его коммутатором. Простейший пример симметричного (распределяющего входные сигналы равномерно) коммутатора 2 на 3 будет выглядеть следующим образом:
commutator(Server_Node) -> receive stop -> exit(normal);
{pin1, signal1_type, signal1},{pin2, signal2_type, signal2} -> signal1_type -> signal1_type, signal2_type, signal1_type
(signal1+signal2)/3-> signal1, signal2, signal3
{modeling, Server_Node}!{self(), output1, 1, signal1_type, signal1},{self(), output2, 2, signal2_type, signal2},{self(), output3, 3, signal3_type, signal3 } end.
Источник. Обеспечивает выдачу сигналов. Входов не имеет. Простейший пример источника с одним выводом:
commutator(Server_Node) -> receive stop -> exit(normal);
{ } ->
{modeling, Server_Node}!{self(), output1, 1, type1, 100} end.
Выход. Псевдоблок, необходимый для получения текущих значений параметров для анализа. Является адаптером между моделью и пользовательским интерфейсом. Имеет один вход, выходов нет.
Одной из важнейших процедур при создании подобной модели является построение таблицы маршрутизации по пользовательской модели (к примеру, по принципиальной электрической схеме). На основе этой информации также должны создаваться процессы-коммутаторы.
После запуска все элементы начнут передавать сообщения маршрутизирующему процессу (серверу), который будет их распределять, опираясь на заданную топологию моделируемой системы.
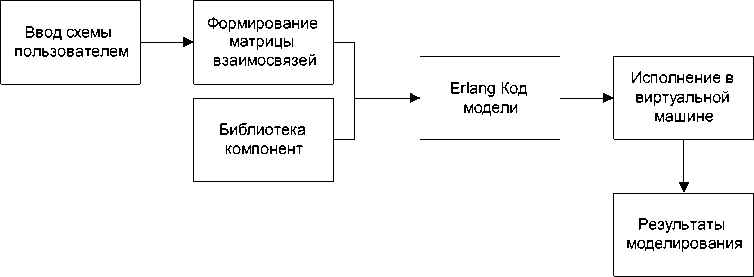
В целом, программный продукт, построенный на основе данной схемы, будет состоять из следующих компонентов (рис. 2):
-
1. Ядро системы. Виртуальная машина Erlang. Основные функции – моделирование.
-
2. Библиотека компонентов. Хранилище процедур на декларативном языке Erlang.
-
3. Построение модели. Приложение на императивном языке высокого уровня (например, C#), формирующее в автоматическом режиме матрицу взаимосвязей для маршрутизатора и исходный Erlang-код всех процессов модели.
-
4. Графический интерфейс. Приложение на императивном языке высокого уровня, обеспечивающее ввод и вывод информации для пользователя.
Реализация данной системы позволит улучшить точность и скорость моделирования больших систем с существенными нелинейностями, а также позволит проводить моделирование на длительных отрезках времени без риска потерь данных.
K. V. Bogdanov, A. N. Lovchikov
СREATING EDA SYSTEMS BASED ON SYNCHRONOUS PARALLEL COMPUTING
In this article a new approach in modeling EDA systems is offered, containing elements the functioning of which is connected to sharp parameter changes; during a mathematical description it leads to an essential increase of the derivative phase variables. In traditional modeling this results in the failure of the computing process.
