Предсказание вертикальной электронной концентрации ионосферы для вычисления ионосферных поправок в радионавигации при помощи библиотек машинного обучения sklearn

Бесплатный доступ
В данной статье рассматривается методика предсказания вертикальной электронной концентрации ионосферы для вычисления ионосферных поправок в радионавигации с использованием библиотек машинного обучения на языке Python. Проведен анализ различных алгоритмов машинного обучения, таких как Decision Tree Regressor и Random Forest, для моделирования динамики ионосферных условий. Проведено сравнение этих методов с нейронными сетями. В качестве исходных данных использовались измерения ионосферной активности и геофизические параметры. Полученные модели продемонстрировали достаточные точностные характеристики. Достигнута возможность прогнозирования в реальных условиях, что позволяет повысить точность систем спутниковой навигации и снизить влияние ионосферных искажений на измерения спутниковых сигналов. Проанализированы методы разложения изображений предсказанных распределений электронной концентрации для передачи предсказанных распределений на удаленные навигационные вычислительные устройства методом разложения на сферические гармоники и методом сплайн-интерполяции. Результаты подтверждают эффективность применения методов машинного обучения для решения задач пространственной и временной оценки ионосферных параметров в радионавигационных системах.
Ионосферные поправки, электронная концентрация, предсказание, машинное обучение, Python, радионавигация, моделирование, случайный лес, Random Forest, Decision TreeRegressor, геофизические параметры, спутниковая навигация
Короткий адрес: https://sciup.org/148332835
IDR: 148332835 | УДК: 519.2:524.73:004.77 | DOI: 10.18137/RNU.V9187.25.04.P.141
Prediction of vertical electron density of the ionosphere for calculating ionospheric corrections in radio navigation using sklearn machine learning libraries
The article discusses a method for predicting the vertical electron density of the ionosphere for calculating ionospheric corrections in radio navigation using machine learning libraries in Python. Various machine learning algorithms, such as Decision Tree Regressor and Random Forest, for modeling the dynamics of ionospheric conditions are analyzed. These methods are compared with neural networks. Measurements of ionospheric activity and geophysical parameters were used as input data. The resulting models demonstrated sufficient accuracy characteristics. The possibility of forecasting in real-world conditions was achieved, which allows for increasing the accuracy of satellite navigation systems and reducing the impact of ionospheric distortions on satellite signal measurements. Methods for decomposing images of predicted electron density distributions for transmitting the predicted distributions to remote navigation computing devices using the spherical harmonic decomposition method and spline interpolation are analyzed. The results confirm the effectiveness of machine learning methods for solving problems of spatial and temporal estimation of ionospheric parameters in radio navigation systems.
Текст научной статьи Предсказание вертикальной электронной концентрации ионосферы для вычисления ионосферных поправок в радионавигации при помощи библиотек машинного обучения sklearn
Ионосфера Земли представляет собой важный аспект для спутниковых измерений, который играет ключевую роль в радиосвязи, навигации и других технологиях, зависящих от электромагнитных волн. Одним из основных параметров, характеризующих ионосферу, является вертикальное полное электронное содержание (Vertical total electron content – VTEC), которое измеряет общее количество свободных электронов в столбе воздуха от поверхности Земли до верхней границы ионосферы. Прогнозирование VTEC1 [1; 2] имеет важное значение для обеспечения точности измерения параметров радиосигналов и навигационных систем, таких как GPS. VTEC влияет на распространение радиоволн, их задержку и искажения, что может привести к ошибкам в навигационных системах и ухудшению качества связи.
Существует задача вычисления ионосферных поправок и применения их на мобильном устройстве, которым, как правило, является навигационный терминал. В данной работе представлена технология, которая позволяет при использовании полученного двумерного распределения VTEC в заданном географическом районе раскладывать его на коэффициенты, передавать в навигационный терминал, который, в свою очередь, будет восстанавливать распределение и вычислять ионосферные поправки к навигационным радиоизмерениям, повышая тем самым точность определения места пользователя.
Применение машинного обучения для прогнозирования VTEC
С развитием технологий и увеличением объёмов данных методы машинного обучения (далее – МО) становятся всё более популярными для прогнозирования [3; 4]. МО анализирует большие наборы данных, выявляет скрытые закономерности и составляет прогнозы на основе исторических данных. Для прогнозирования VTEC были собраны данные о солнечной активности, геомагнитных бурях, метеорологических условиях и других факторах ионосферы из таких источников, как спутники, наземные станции и модели.
Предсказание вертикальной электронной концентрации ионосферы для вычисления ионосферных поправок в радионавигации при помощи ...
Опишем основные этапы и задачи данной работе. Одна из задач – это передача карты или модели распределения ионосферы в виде аналитических выражений и коэффициентов на мобильное устройство для расчёта ионосферных поправок с учётом местоположения пользователя. Это включает в себя разработку компактного представления (коэффициентов разложения) карты VTEC.
Предварительная обработка данных включает очистку, нормализацию и подготовку данных путём удаления выбросов, заполнения пропусков и форматирования для анализа.
Следующий этап – выбор метода машинного обучения, например, регрессии, деревьев решений или нейронных сетей. Были протестированы деревья решений и ансамблевые случайные леса. Мы применяем ММ для прогнозирования VTEC в ионосфере Земли . Данные VTEC были получены для 59°с. ш. и 30°в. д. из Глобальной карты ионосферы (GIM) по адресу Далее мы сравниваем два метода разложения: коэффициенты сферических гармоник и коэффициенты кубических сплайнов для передачи распределения VTEC в навигационные устройства.
Работа с Ionex-файлами
Для получения ионосферных данных мы используем архивные файлы Ionex. Ionex (формат обмена ионосферными данными) – стандарт обмена ионосферными данными в геодезии и навигации. Он был разработан для хранения и передачи информации об ионосферной задержке, которая может влиять на работу GPS и других систем глобального позиционирования. Файлы Ionex представляют собой текстовые файлы с заголовками и данными. Заголовки содержат информацию о времени, местоположении, типе данных и параметрах модели ионосферы. Данные содержат значения ионосферной концентрации в единицах TECU (1016 м–2), представленные в виде сетки точек. Эти данные помогают корректировать сигналы GPS и навигационных систем. Файлы Ionex имеют строгую структуру, включая блоки данных со значениями задержки для различных частот и временных интервалов.
Напишем функции и утилиты для загрузки файлов IONEX, получения VTEC и построения карт VTEC. Ниже приведены примеры с использованием библиотек numpy и scipy.
Функция разбора строки файла Ionex:
def parse_map(tecmap, exponent=-1):
Функция получения массива данных VTEC из файла Ionex:
def get_tecmaps(filename):
with open(filename) as f:
Функция получения значения VTEC из заданной точки координат файла Ionex:
MAX_LAT = 87.5 MAX_LON = 180
def get_tec(tecmap, lat, lon):
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
return tecmap[i,j]
Функция составления строки с именем файла Ionex:
def ionex_filename(year, day, centre, zipped=True):
return’{}{:03d}0.{:02d}i{}’.format(centre, day, year%100, ‘.Z’ if zipped else’’)
Функция формирования пути к файлу:
def ionex_local_path(year, day, centre=’IACG’, directory=»d:/projects/PYTHON/GNSS/ IONO/ionex», zipped=False):
return directory+’/’+str(year) +’/’+ionex_filename(year, day, centre, zipped)
где year и day – заданный день и год.
Функция отрисовки карты VTEC отображает карту VTEC с помощью библиотеки Matplotlib и Cartopy. Она создает график с проекцией Plate Carree, наносит цветовую карту данных TECU в диапазоне от 0 до VMAX на заданных границах долготы и широты, добавляет цветовую шкалу с подписью, форматирует оси с указанием долготы и широты, а также отображает сетку и заголовок. Эта функция позволяет визуализировать карту VTEC на земной поверхности с географическими метками и цветовой градацией TECU. VMAX – это максимальное значение данных TECU, используемое для масштабирования цветовой карты на карте VTEC. Оно определяет яркость цветов и диапазон отображаемых значений, чтобы лучше визуализировать вариации и особенности данных.
Разработка механизма получения компактного представления (в виде коэффициентов разложения) карты распределения VTEC
Построение глобальных ионосферных карт VTEC (GIM) похоже на расчет локальных ионосферных карт по измерениям на одной станции, но используется глобально распределенная сеть станций [5]. Однослойные ионосферные модели предполагают, что все свободные электроны находятся в бесконечно тонком слое на некоторой высоте над Землей. Наклонная электронная плотность (STEC) находится путем умножения VTEC на функцию отображения mf ( E ), которая зависит от угла места E, высоты ионосферного слоя ( h = 450 км) и радиуса Земли Re. Используя метод наименьших квадратов, уточняются ионосферные задержки для всех спутников, наряду с вертикальным распределением VTEC, моделируемым как сферическое гармоническое разложение на основе широты и солнечно-фиксированной долготы. Распределение VTEC в локальной области станции зависит от географической широты φ i и солнечно фиксированной долготы λ i точки ионосферного прокола.
VTEC ( ф , X ) = £ N=0 £ n m =0 [ A n , m л ( n , m ) P n , m (sin Q )cos( m X ) ]
An , m – коэффициенты разложения (определяются методом наименьших квадратов);
Л ( n, m ) - нормированные функции Лежандра Л( n , m ) - нормализующая функция;
P nm sin( ф ) — ассоциированные функции Лежандра;
Произведем вычисление задержки распространения:
40.3
dt = -°^ * STEC , c * f
STEC = mf ( E )* vtec ,
-2
mf (E) = -1- * 11 + h- I , cos E ^ Re J
Предсказание вертикальной электронной концентрации ионосферы для вычисления ионосферных поправок в радионавигации при помощи ...
где h – выcота слоя ионосферы; E – угол возвышения спутника; STEC – наклонная ионосферная концентрация; mf ( E ) – функция отображения.
Напишем функцию вычисления коэффициентов сферических гармоник на языке Python: def calculate_spherical_harmonic_coeffs(image_array, l_max, height, width):
-
# Создаем массив для хранения коэффициентов сферических гармоник,
-
# размеры: (l_max+1) x (2*l_max+1), так как m варьируется от -l до l
-
# Проходим по каждому пикселю изображения
for theta in range(height):
for phi in range(width):
-
# Значение интенсивности пикселя
r = image_array[theta, phi]
-
# Преобразование координат пикселя в сферические углы:
-
# θ (от 0 до π)
-
# φ (от 0 до 2π)
-
# Вычисляем синус θ для учета площади элемента сферы
-
# Проходим по всем l и m для вычисления соответствующих гармоник
for l in range(l_max + 1):
for m in range(-l, l + 1):
-
# Вычисляем значение сферической гармоники Y_l^m в точке (θ, φ)
Y_lm = sph_harm(m, l, phi_s, theta_s)
-
# Накопление вклада данного пикселя в коэффициенты:
-
# Умножаем значение на интенсивность r и sin(θ) для учета площади
coeffs[l, m + l] += r * Y_lm * sin_theta
-
# Нормализация коэффициентов для приближения интеграла по всей сфере
coeffs *= normalization return coeffs
Рассмотрим восстановление карты VTEC по коэффициентам кубического сплайна. Кубический сплайн – это гладкая кусочная функция. Она состоит из нескольких кубических полиномов, каждый из этих полиномов определён только между конкретными узлами. Сначала производится разбиение данных по узлам (точкам с заданными значениями). Для каждого интервала строится кубический полином, проходящий через соответствующие узлы. Сплайн в итоге получается таким образом, чтобы производные первая, вторая или третья, совпадали на границах интервалов, обеспечивая гладкость. Использование сплайна состоит в том, что для любой точки внутри интервала выбирается соответствующий кубический полином и вычисляется его значение:
Si (x) = ai + bi * x + ci * x2 + di * x3 , где i – номер точки.
Напишем такую функцию для расчета коэффициентов пространственного распределения VTEC через сплайн-интерполяцию:
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
def splineImage(image):
-
# Получение размеров изображения
-
# Создание сетки координат
-
# Создание кубического сплайна
spline=Rect Bivariate Spline(y, x, image)
-
# Создание новой сетки для интерполяции
x_new=np.linspace(0, width-1, width)
y_new=np.linspace(0, height-1, height)
image_interp=spline(y_new, x_new)
retur nimage_interp;
здесь Rect Bivariate Spline – это класс из библиотеки SciPy, который выполняет двумерную интерполяцию по сетке. Он строит сплайн-аппроксимацию функции, заданной на прямоугольной сетке, и позволяет получать значения интерполированной функции в произвольных точках. Используя этот код, мы выбираем из папки на компьютере нужный нам файл Ionex за выбранную дату и далее мы считываем из него все значения вертикальной электронной концентрации VTEC за сутки и формируем из них массив tecmap.
strion=ionex_local_path(2024, 22);# 2024 – год, 22 – день года tecmaps=get_tecmaps(strion);
tecmap=tecmaps[0];
Возьмем сформированный нами из файла Ionex массив значений VTEC, выведем его размерность:
Найдем коэффициенты сферических гармоник:
coefficients=calculate_spherical_harmonic_coeffs(tecmap, order, imlen0, imlen1)
Реконструируем изображение по ним:
return_image_Harmonic=reconstruct_image(coefficients, imlen0, imlen1)
Найдем коэффициенты кубического сплайна:
return_image_Cubic=splineImage(tecmap);
Нарисуем оригинальную карту VTEC:
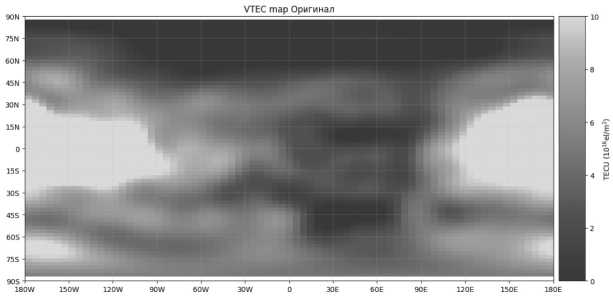
Предсказание вертикальной электронной концентрации ионосферы для вычисления ионосферных поправок в радионавигации при помощи ...
Восстановим карту VTEC при помощи коэффициентов cферических гармоник:
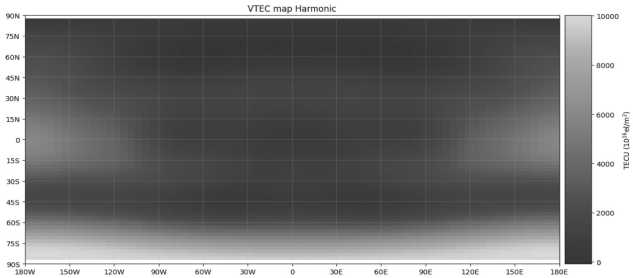
Восстановим карту VTEC при помощи коэффициентов сплайна:
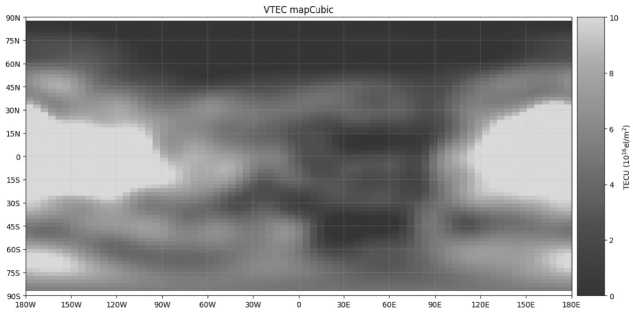
Кубическая сплайн-интерполяция точнее сферического гармонического разложения, поскольку сплайны представляют собой локальные аппроксимации, которые лучше отражают такие особенности, как края и текстуры. Сферические гармоники являются глобальными и аппроксимируют всю функцию, часто теряя локальные детали. Изображения содержат множество локальных структур, которые сплайны хорошо моделируют, в то время как гармоники подходят для гладких периодических функций. Сплайны обеспечивают регулируемую гладкость для лучшей адаптации к особенностям изображения. Гармоники зависят от количества компонентов; слишком малое их количество может привести к потере деталей. Кроме того, сплайны обеспечивают хорошую стабильность и локальные корректировки, повышая точность реконструкции изображения.
Прогнозирование электронной концентрации ионосферного слоя при помощи машинного обучения с использованием библиотеки sklearn
В качестве входных данных мы использовали измерения солнечной активности и солнечно-земных процессов, таких как поток радиоизлучения F10.7, скорость солнечного ветра, индекс Bz и индекс Dst (геомагнитные возмущения). Данные были загружены из базы данных NASA OMNI Web2 в формате CSV, что позволило выбрать конкретные периоды
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
и поля данных. Для прогнозирования электронной концентрации ионосферы были выбраны следующие поля: дата-время, день года, час дня, индекс F10.7 (солнечное радиоизлучение на длине волны 10,7 см, индикатор солнечной активности), скорость солнечного ветра (км/с), индекс Bz (нТл, измеряющий компонент магнитного поля Земли), индекс Dst (нТл, измеряющий интенсивность геомагнитной бури) и VTEC (единицы ПЭС, измеряющие полное электронное содержание в ионосфере).
Данные загружаются в Data Frame библиотеки Pandas, индексом которого служат дата и время. Необходимые пакеты включают numpy, pandas, seaborn, sklearn.tree, sklearn. model, squared_error, mean_absolute_error и metrics. Мы подготавливаем данные для прогноза VTEC на 24 часа вперёд: после сброса индекса создаём новый Data Frame со строками, начиная с 24-го числа, содержащий только столбец VTEC, назначенный VTEC_ forecast data_df.reset_index(inplace=True)
Исследовательский анализ данных
Для оценки корреляции между признаками мы используем матрицу диаграмм рассеяния для проведения разведочного анализа данных (см. Рисунок 1). Они будут показывать визуально видимое влияние одного признака на другой по принципу «каждый с каждым». Это будет построено для каждой пары признаков по двум осям как графики. Применим для этого библиотечную функцию sns.pairplot(data_df).
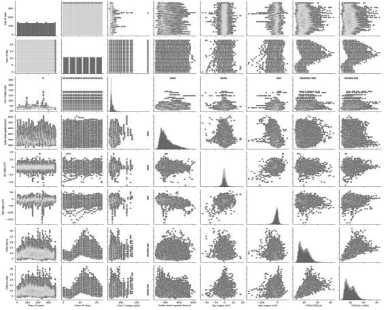
Рисунок 1. Матрица рассеяния
Источник : здесь и далее рисунки выполнены автором.
Корреляционный анализ
Произведем корреляционный анализ признаков данных. Применим для этого метод corr(). Он создает сложную матрицу, включающую в себя связи между разными признаками по принципу «каждый с каждым». На пересечении столбцов и строк, которые состоят из признаков, устанавливается число, означающее степень корреляции признаков между собой, от –1 до 1, где 0 – это отсутствие корреляции. Ячейки этой матрицы раскрашиваются в разные цвета, степень насыщенности которых – от синего до красного – пропорциональна значению корреляции (см. Рисунок 2).
Предсказание вертикальной электронной концентрации ионосферы для вычисления ионосферных поправок в радионавигации при помощи ...
В Python это можно сделать следующим образом:
sns.heatmap(c, annot=True, vmin=-1, vmax=1, cmap=’coolwarm’, square=True)
Этот код сначала вычисляет матрицу корреляции для числовых столбцов в data_df и округляет её до двух знаков после запятой.
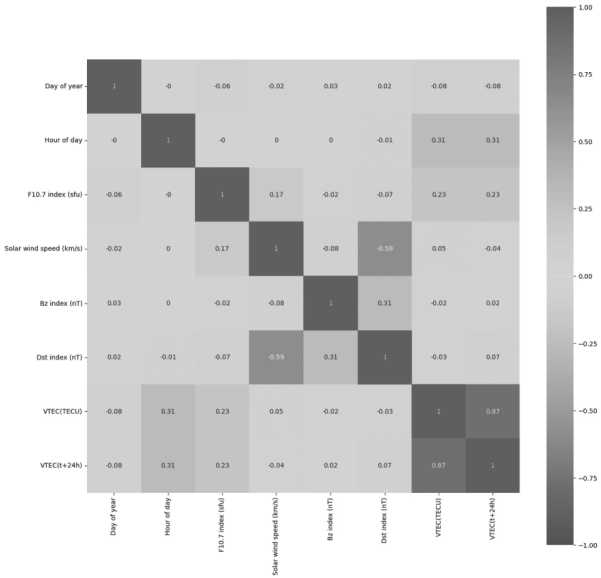
Рисунок 2. Тепловая карта корреляций параметров (Correlation Heatmap)
Подготовка данных для обучения
Далее преобразуем данные в массивы NumPy, которые будут использоваться алгоритмами scikit-learn [6]. X будет матрицей, которая имеет элементы данных в последовательных строках и разные входные признаки в разных столбцах. Y будет вектором, состоящим из столбца «VTEC(forecast)».
y=data_df [‘VTEC(forecast)’].to_numpy()
Мы проведем тестирование за 2023 год (с 1 января по 30 декабря), что составляет 8736 точек данных, при этом исключим тестовые данные из обучающих данных:
split_time=8736
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
X_train=X[:-split_time]
y_train=y[:-split_time]
time_train=dates[:-split_time]
X_test=X [-split_time:]
y_test=y [-split_time:]
time_test=dates [-split_time:]
Построим сводный график разделенных обучающих и тестовых данных (см. Рисунок 3):
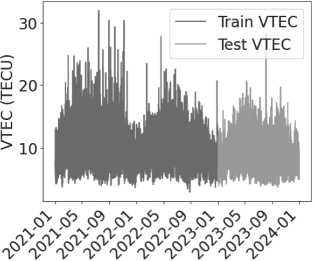
Time (UTC)
Рисунок 3. График разделенных обучающих и тестовых данных VTEC
Настройка модели Decision Tree Regressor
Мы будем использовать кросс-валидацию временных рядов по K-кратности с 20 разделениями, используя cross_val_score() и KFold для оценки различных гиперпараметров. Цель – выбрать гиперпараметры, которые максимизируют эффективность модели. Разделение данных подразумевает последовательную организацию данных временных рядов. Сначала выбираем значение K (обычно 5–10) для разделения данных на K последовательных временных окон, избегая случайных разделений и предотвращая утечку данных. Для каждого разделения модель обучается на первых N наблюдениях и тестируется на следующих M, обеспечивая чередование обучения и тестирования во времени. Этот процесс повторяется для всех K разделений, при этом каждое окно один раз служит тестовым набором. После завершения всех итераций собираются метрики производительности, такие как среднеквадратическая ошибка (RMSE) или средняя ошибка (MAE), для оценки общей эффективности модели.
Выбор модели и ее обучение
Для прогнозирования VTEC мы будем использовать Decision TreeRegressor из scikit-learn [6], реализующий алгоритм регрессии на основе дерева решений. Он прогнозирует непрерывные значения, рекурсивно разбивая данные на основе значений признаков и выбирая разбиения для минимизации ошибки прогнозирования (например, среднеквадратичной ошибки).
Параметрами модели являются:
criterion: измеряет качество разбиения («rmse» или «mae»);
max_thought: ограничивает глубину дерева для предотвращения переобучения; min_samples_split: минимальное количество выборок для разбиения узла;
Предсказание вертикальной электронной концентрации ионосферы для вычисления ионосферных поправок в радионавигации при помощи ...
min_samples_leaf: минимальное количество выборок в листовом узле;
max_weights: количество признаков, учитываемых при разбиении.
Мы будем настраивать гиперпараметр max_depth в диапазоне значений от 1 до 20, выбирая оптимальное значение на основе наименьшего значения среднеквадратичной ошибки:
max_depth= [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20]
forvalinmax_depth:
score=cross_val_score(DecisionTreeRegressor(max_depth=val), X_train, y_train, cv=tscv, scoring=»neg_mean_squared_error»)
Для maxdepth = 4,rmse= 1.84
Настройки гиперпараметров Random Forest Regressor
Для max depth = 6rmse= 1.75
max_features= [1, 2, 3, 4, 5, 6, 7]
forcountinmax_features:
score=cross_val_score(RandomForestRegressor(max_features=count, max_depth=7), X_ train, y_train, cv=tscv, scoring=”neg_mean_squared_error”)
Для max_features = 3,rmse= 1.69
estimators= [10, 50, 100, 200, 300, 400, 500, 1000]
forcountinestimators:
score=cross_val_score(RandomForestRegressor(n_estimators=count, max_features=3, max_ depth=7), X_train, y_train, cv=tscv, scoring=”neg_mean_squared_error”)
Для estimators = 200,rmse= 1.68
Преимущества Decision Tree Regressor состоят в простоте интерпретации – деревья решений легко визуализировать и интерпретировать. Также они не требуют масштабирования данных, деревья решений не чувствительны к масштабу признаков, могут обрабатывать как числовые, так и категориальные данные.
Недостатки метода – переобучение и нестабильность. Деревья решений могут легко переобучаться, особенно если не ограничены по глубине. Небольшие изменения в данных могут привести к значительным изменениям в структуре дерева.
Напишем код обучения модели Decision Tree Regressor на Python:
model_dtree=DecisionTreeRegressor(max_depth=4)
y_pred_train=model_dtree.predict(X_train)
Результаты
Тестирование модели Decision Tree Regressor
Оценим нашу модель на тестовых данных, чтобы получить окончательную оценку точности нашей модели и выведем метрики RMSE, Explain variance score, R2 score:
Root mean squared error (RMSE): 1.42
Explain variance score = 0.77
R2 score = 0.77
Построим графики предсказанной VTEC за январь – декабрь 2023 г. Обозначим VTEC forecast – предсказанные значения (см. Рисунок 4).
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
Ground truth VTEC
VTEC forecast, DT
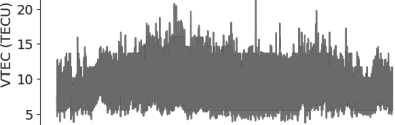
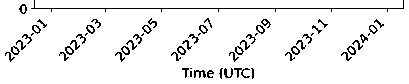
Рисунок 4. Линейный график сравнения фактическихи прогнозируемых значений VTEC Участок на 8 дней: 23–30 декабря 2023 г. (см. Рисунок 5).
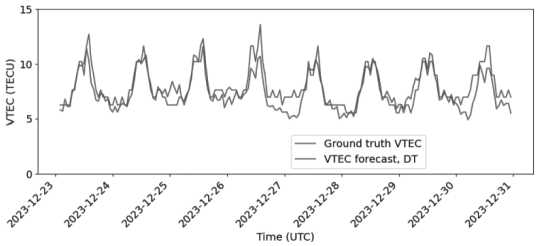
Рисунок 5. Реальные и предсказанные значения VTEC за указанный период
