Применение метода улучшения изображений для систем распознавания лиц

Автор: Пахирка Андрей Иванович
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 3 (29), 2010 года.
Бесплатный доступ
Представлен алгоритм обработки изображений лиц, включающий три этапа: нелинейное улучшение изображения (сжатие динамического диапазона), локализация лиц на основе цветовой сегментации кожи с последующим выделением антропометрических точек лица. Также рассмотрен процесс распознавания лиц на основе метода главных компонент
Сжатие динамического диапазона, локализация лиц, распознавание лиц
Короткий адрес: https://sciup.org/148176244
IDR: 148176244 | УДК: 004.93у1;
Image enhancement for face recognition system
Three steps face recognition algorithm is proposed. We used the method of image enhancement based on high dynamic range compression, face detection algorithm based on skin color information, face recognition process based on principal components analysis method is considered as well
Текст обзорной статьи Применение метода улучшения изображений для систем распознавания лиц
Интерес к распознаванию лиц всегда был значительным, особенно в связи с возрастающими практическими потребностями, такими как биометрия, содержательный поиск изображений, компрессия видеоданных, организация видеоконференций, системы машинного зрения в робототехнике, интеллектуальные системы безопасности и контроля доступа.
Методы распознавания лиц могут быть разделены на две широкие категории: методы, основанные на извлечении особенностей изображения, и методы, основанные на представлении изображения лица. Первая группа методов использует свойства и геометрические отношения, такие как области, расстояния и углы между особыми точками изображения лица. Вторая группа методов рассматривает глобальные свойства изображения лица. Названные методы стараются представить данные изображения лица более эффективно, например, как набор главных векторов. Как правило, алгоритм распознавания лиц включает в себя три этапа: предварительную обработку изображения, локализацию лиц и непосредственное распознавание лиц. В данной работе представлен алгоритм, включающий нелинейное улучшение изображений (сжатие динамического диапазона), локализацию лиц на основе цветовой сегментации кожи, а также распознавание лиц на основе метода главных компонент [1].
На практике захватываемые цифровыми устройствами изображения зачастую отличаются от того, что видит наблюдатель. Это происходит потому, что устройство захвата получает физические значения световых данных, в то время как нервная система наблюдателя обрабатывает эти данные. Например, человек может четко видеть детали, как в глубоких тенях, так и в сильно освещенных областях, в то же время устройство захвата получит данную сцену со слишком темными тенями или засвеченными областями. Человек легко воспринимает сцены с широким диапазоном световых интенсивностей (HDR, High Dynamic Range – высокий динамический диапазон), при этом отношение между максимальной и минимальной яркостью превышает возможности устройства захвата или отображения.
Человек, наблюдая HDR-сцену, локально адаптирует каждую ее часть, благодаря чему может рассматривать детали в плохо освещенных областях так же хорошо, как и в ярко освещенных. Для цифровых устройств HDR-сцена требует сжатия, из-за чего захватываемое изображение зачастую теряет детали в плохо или ярко освещенных областях. Для устройств захвата это решается путем комбинирования изображений, снятых с разной экспозицией (тех- нология HDR в фотографии), в результате которого получается единое изображение, содержащее все детали из всех исходных изображений, как в тенях, так и в освещенных областях. Однако остается проблема отображения данных изображений на цифровых устройствах, обладающих существенно меньшим диапазоном яркостей [2].
В данной работе для улучшения изображения применяется алгоритм Multi-Scale Retinex – MSR, имитирующий визуальную систему человека. MSR-алгоритм сжимает динамический диапазон изображения с сохранением (увеличением) локального контраста в плохо и ярко освещенных областях [3].
Классический многомерный MSR-алгоритм является взвешенной суммой одномерных SSR-алгоритмов (SingleScale Retinex) для различных масштабов. Одномерная выходная функция i -го цветового канала Ri ( x , y , s) вычисляется следующим образом:
Ri(x, y, s) = log{Ii(x, y)} – log{F(x, y, s) * Ii(x, y)}, где Ii(x, y) – входная функция i-го цветового канала по координатам x и y; s – масштабный коэффициент; знак * обозначает свертку функций; F(x, y, s) – гауссиан, определяемый как
F ( x , y , s) = Ke–( x 2 + y 2)/s2.
При этом коэффициент K выбирается таким образом, чтобы выполнялось условие я..
F ( x, y, a ) dxdy = 1,
где . xy - множество пикселей, принадлежащих всему изображению.
Тогда многомерная выходная функция i -го цветового канала RMi ( x , y , w , s) определяется как
N
R M ( x , y , w , a ) = ^ w „ R , ( x , y , a „ ) , n = 1
где w = (w1, w2, …, wm), m = 1, 2, …, M – весовой вектор одномерных выходных функций -го цветового канала R (x, y, s); s = (1, 2, …, sn), n = 1, 2, …, N – вектор масштабов N одномерных выходных функций. При этом ^ wn = 1. Раз-n=1
мерность вектора масштабов обычно выбирается не меньше 3. В различных источниках приводятся разные рекомендуемые значения масштабов, в наших экспериментах они составили 15, 90, 180. Весовой вектор w, как правило, имеет элементы с равными значениями.
Функциональная схема модуля улучшения изображения показана на рис. 1. Переход к цветовому простран- ству YCbCr обусловлен тем, что в нем яркостная компонента представлена независимо от других. Поэтому алгоритм применяется только к Y-компоненте, не затрагивая Cb и Cr, что, в свою очередь, увеличивает скорость работы алгоритма. Для Гауссова размытия применяется рекурсивный алгоритм фильтрации, который аппроксимирует гауссиан, с расчетом коэффициентов фильтра для желаемого значения сигма (s), такое представление фильтра работает значительно быстрее, чем стандартная фильтрация с использованием ядра свертки [4].
Пример работы MSR-алгоритма для изображения с низкой освещенностью показан на рис. 2.
После улучшения изображения следует этап локализации лиц на основе цветовой сегментации кожи. Процесс локализации лица на изображении можно разделить на две составляющие:
-
– выделение участков изображения, имеющих цвет, сходный с цветом кожи человека (цветовая сегментация);
-
– анализ выделенных после сегментации регионов.
Определение цвета кожи позволяет существенным образом сократить область поиска и является первым шагом во многих методах локализации лица. Человеческая кожа имеет характерный оттенок, позволяющий успешно сегментировать кожу на цветных изображениях. Независи- мость оттеночной компоненты цвета кожи от ориентации лица, а также его небольшая зависимость от яркости освещения, делают цвет устойчивым признаком кожи. Преимуществами метода цветовой сегментации кожи являются:
-
– малая вычислительная сложность;
-
– устойчивость к изменению масштаба и повороту лица;
-
– устойчивость к изменению освещения;
-
– устойчивость к изменению выражения лица и частичному перекрытию лица другим объектом сцены.
Цветовая сегментация кожи человека на изображении требует построение определяющих правил, которые будут разделять пиксели цвета кожи и пиксели, не относящиеся по цвету к коже. Для этого вводится метрика, позволяющая измерить расстояние между цветом пикселя и тоном кожи. Даная метрика является моделью распределения цвета кожи в выбранном цветовом пространстве.
Используем метрику для нормализованного RGB - цветового пространства, для которого распределение цвета кожи представлено на рис. 3:
Skin( r , g ) =
-
1 if ( g < g u ) ■ ( g > g d ) ■ (W > 0,0004),
0 otherwise,
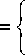
Рис 1. Функциональная схема применения MSR-алгоритма к изображению

аб
Рис 2. Пример работы MSR-алгоритма:
а – входное изображение; б – выходное изображение после обработки MSR-алгоритмом
где u – верхняя граница; d – нижняя граница. Значения gu, gd, W определяются как gu = Jur2 + Kur + Lu , gd = Jdr2 + Kdr + Ld ,
W = (r - 0,33)2 + (g - 0,33)2, а коэффициенты принимают следующие значения:
J u =- 1,377, K u = 1,074, L u = 0,145,
J d = - 0,776 K d = 0,560, L d = 0,177.
Пример сегментации кожи представлен на рис. 4. Сегментированное изображение подвергается морфологической обработке (сжатие с последующим расширени- ем), которая позволяет разъединить плохо связанные регионы и удалить регионы малого размера (шум). Далее производится маркировка связных областей (рис. 5), после чего в каждой области ищутся антропометрические точки (глаза, нос, губы).
Распознавание лиц осуществляется с помощью метода главных компонент (Principal Components Analysis, PCA), который позволяет уменьшить размерность данных за счет минимизации потерь информации. Метод главных компонент (МГК) один из наиболее часто используемых методов для снижения размерности данных в системах распознавания и сжатия. Данный метод проеци-
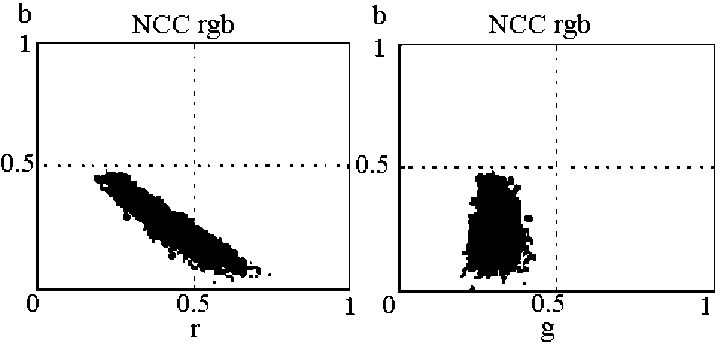
Рис 3. Распределение цвета кожи для нормализованного RGB-пространства

а
б
Рис. 4. Пример сегментации кожи: а – входное изображение; б – выходное изображение после применения метрики

а бв
Рис. 5. Пример локализации лиц: а – входное изображение; б – морфологическая обработка с маркировкой связанных областей; в – выделение антропометрических точек лица
рует пространство изображения в пространство признаков меньшей размерности. Главная идея метода главных компонент состоит в представлении изображений лиц людей в виде набора главных компонент изображений, называемых «собственные лица» (Eigenfaces). Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы, которая рассчитывается из изображения [5].
Любое изображение может рассматриваться как вектор из пикселей, каждое значение которого представлено значением в полутоновой градации. Например, изображение 8 x 8 пикселей может рассматриваться как вектор длиной в 64 пикселя. Такое векторное представление описывает входное пространство изображения. Для представления и распознавания лиц используем подпространство, созданное собственными векторами ковариационной матрицы исследуемых изображений. Собственные векторы, соответствующие ненулевым собственным значениям ковариационной матрицы, формируют ортогональный базис, который отображает изображения в N -мерное пространство [5]. Каждое изображение сохраняется в векторе размера N :
X = [ x^- xiN ] Т , (1) где x i – эталонные изображения; X – матрица эталонных изображений. Изображения центрируются вычитанием из каждого вектора усредненного изображения:
P x = x - m, где m = — x^x . (2) P и
Эти векторы объединяются, образуя матрицу данных NxP (где P - количество изображений; x i - центрированное изображение) следующим образом:
-
X = [ x 1 x 2 --- x P ] . (3)
Матрица данных X умножается на транспонированную матрицу данных для расчета ковариационной матрицы
Q = XX T . (4)
Эта ковариационная матрица Ω имеет до P собственных векторов, связанных с ненулевыми собственными значениями, при этом P < N . Собственные векторы сортируются от большего значения к меньшему значению в соответствии с их собственными значениями. Собственный вектор с наибольшим собственным значением представляет самую большую дисперсию в изображениях.
Распознавание изображений с использованием проецирования на собственное пространство осуществляется в три этапа:
-
1. Создается собственное пространство из эталонных изображений (этап обучения).
-
2. Эталонные изображения проецируются в собственное пространство (этап обучения).
-
3. Спроецированное входное изображение сравнивается с проецированным тестовым изображением (этап распознавания).
Рассмотрим первый этап – создание собственного пространства, состоящего из следующих шагов:
-
– центрирование данных: каждое изображение центрируется вычитанием усредненного изображения из каж-
- дого эталонного изображения. Усредненное изображение – это вектор-столбец, в который входят средние значения пикселей из всех пикселей эталонных изображений (выражение (2));
-
– создание матрицы данных: как только входные изображения центрированы, они комбинируются в матрицу данных N Ч P (выражение (3));
-
– создание ковариационной матрицы: матрица данных умножается на ее транспонированное представление (выражение (4));
-
– вычисление собственных векторов и собственных значений: собственные векторы и их собственные значения вычисляются из ковариационной матрицы
Q V = Л V ,
-
гд е V – набор собственных векторов связанных с собственными значениями Λ ;
– упорядочивание собственных векторов: упорядочиваются собственные векторы vi О V в соответствии с их собственными значениями X i e Л от большего значения к меньшему значению. Сохраняются собственные векторы с ненулевыми собственными значениями. Эта матрица собственных векторов является собственным пространством V , где каждый столбец – собственный вектор:
-
V = [ V ) V 2 --- v P ] .
На втором этапе происходит проецирование эталонных изображений в собственное пространство. Каждое i центрированное входное изображение x проецируется в собственное пространство:
x i = V T x i ■
В рамках третьего этапа происходит распознавание входного изображения. Каждое входное изображение центрируется вычитанием усредненного изображения и затем проецируется в собственное пространство V :
1 P
-
y = y -m , где m = — ^ x и % i = V y.
PI" )
Спроецированное входное изображение сравнивается со всеми спроецированными эталонными изображениями. Изображения могут сравниваться с использованием любой из простых метрик, например евклидовой.
В настоящий момент проводится разработка системы нелинейного улучшения изображений в разных цветовых пространствах, планируется использовать алгоритм Multi-Scale Retinex с восстановлением цветов для захвата и обработки видеоизображений, имеющих большой диапазон значений яркостей. Разрабатывается система захвата изображений лиц из видеоизображения, с последующей обработкой и приведением изображений к некоторому «усредненному» виду, снижением влияния освещения, корректировкой положения лица, выбором из видеоданных относительно лучшего изображения лица.
Таким образом, в статье предлагается усовершенствованный подход к распознаванию лиц по изображению, использующий алгоритм нелинейного улучшения изображения, который позволяет скомпенсировать тени и блики. Также проведенный анализ цветовых пространств позволяет повысить качество распознавания сегментов кожи и антропометрических точек лица.
