Применение методов машинного обучения при работе с литературными источниками

Автор: Артюхин Валерий Викторович
Журнал: Образовательные технологии и общество @journal-ifets
Статья в выпуске: 2 т.18, 2015 года.
Бесплатный доступ
В статье рассматриваются два примера применения методов машинного обучения, позволяющих существенно облегчить работу исследователя или преподавателя при поиске и анализе литературных источников. Кластеризация книг позволяет получить представление о структуре и содержании публикационной активности по определенной тематике. С другой стороны, применение описанной вариации алгоритма Луна для ранжирования предложений позволяет выделить «важное», с точки зрения исследователя и конкретного исследования, в отдельной статье или корпусе статей (например, полученных с помощью поиска в интернет-библиотеках), то есть сэкономить время на отбор и изучение материалов.
Литературные источники, машинное обучение, кластеризация, анализ биграмм, алгоритм луна
Короткий адрес: https://sciup.org/14062618
IDR: 14062618
Текст научной статьи Применение методов машинного обучения при работе с литературными источниками
Научным сотрудникам в рамках научно-исследовательских и других работ, преподавателям в рамках подготовки материалов учебных курсов, соискателям ученых степеней зачастую приходится работать с большими объемами отечественной и зарубежной литературы. Такие разделы, как «Современное состояние проблемы», «Обзор проведенных научных исследований по теме» и другие, де-факто необходимы в любом научном или методическом материале, не говоря уж о том, что сам процесс изучения трудов других людей представляет необходимую и логичную часть любого научного исследования или структурирования информации для последующего составления учебника, учебного пособия, учебной программы.
Зададимся гипотетическим вопросом: можно ли изучить и структурировать в рамках одного исследования по определенной тематике (или даже в рамках человеческой жизни) абсолютно все, что было написано и опубликовано по данной и смежным тематикам другими людьми? Очевидно, что на этот вопрос может быть дан только отрицательный ответ. В таком случае, какие варианты имеются у добросовестного исследователя? Первый и наихудший вариант (который при исключительном его применении, однако, опровергает гипотезу о добросовестности исследователя) заключается в том, чтобы изучить или упомянуть лишь то, что уже изучалось или просто широко известно. Второй вариант заключается в использовании поисковых средств общего (например, Google, Yandex ) или специального (НЭБ / elibrary.ru и т. д.) назначения. Третий вариант предполагает поиск тезисов с тематических конференций, поиск по сайтам профильных научных организаций и т. п. Увлеченный исследователь использует все три варианта, а также множество других (например, использует свои онлайн- или оффлайн-контакты в научном мире или перебирает книги на сайте интернет-магазина).
Сформулируем следующий вопрос: способен ли исследователь подробно изучить все то, что он обнаружит (все книги, статьи, эссе, тезисы) с помощью его «эксклюзивной» комбинации методов поиска информации по конкретной теме? Предположим, что нас интересуют материалы исследований в области методологий, методов и методик «разработки интернет-представительств государственных и общественных организаций в социальных сервисах» (такая работа выполняется автором в продолжение исследований [1] и [2]), а также методы оценки и повышения эффективности этих представительств. Тематика в таком определении слишком многословна и специфична, чтобы статьи по ней могли быть найдены специальным средством поиска. Точнее, определенное количество материалов будет обнаружено (по указанному запросу на 14 марта 2015 г. elibrary.ru выдает 23 позиции), но нет никакой гарантии, что найденное соответствует всему набору материалов по теме, на самом деле, в силу неоднозначности языка и разницы в терминологиях вероятность этого пренебрежимо мала. Очевидным решением при продолжении поиска является редукция определения тематики до ключевых слов / фраз и их комбинаций, но в этом случае мы зачастую придем к обратной ситуации, когда материалов будет слишком много (снова): по запросу «социальный сервис, организация» elibrary.ru выдает 20 602 позиции.
Подытожим: информации всегда будет либо слишком много, либо слишком мало, и вряд ли технические средства могут решить эту проблему, по крайней мере, на сегодняшний день, поскольку, а) проблема носит фундаментальный характер, б) на самом деле, не является проблемой, а представляет собой вполне естественное явление.
Дьёрдью Пойа писал: «Если вы не можете решить проблему, где-то есть проблема, которую вы можете решить: найдите ее»! [3] При работе с литературными источниками часто возникает ряд таких задач «попроще», которые, хотя и не могут быть полностью решены в автоматическом режиме, но допускают применение методов машинного обучения для существенного облегчения работы исследователя. В данной работе, которая, в отличие от фундаментальных исследований в области компьютерной лингвистики [4,5], носит в основном практический характер, рассматривается две таких задачи и подходы к их решению.
Классификация книг
До того, как анализировать имеющиеся книги, зачастую полезно понять, какие книги по теме вообще существуют. Некоторые представляют собой учебники или учебные пособия, другие - монографии, третьи - справочники. Одни описывают технологию, другие – фундаментальные принципы. Возможны и другие варианты кластеризации, специфические для предметной области – именно они, чаще всего, и интересны. Если исследователь обладает доступом к большому объему книг, то кластеризацию можно выполнить разными способами, в зависимости от того, доступны ли полные тексты в электронном виде или нет.
В первом случае, когда тексты доступны, можно использовать различные варианты алгоритмов TF-IDF, LHS и др., но следует быть осторожными: корпусная лингвистика «хороша» тем, что способна продемонстрировать, как довольно простые по сути задачи могут вызывать проблемы при попытках их решения на обычных ПК (в части быстродействия и необходимых ресурсов).
Во втором случае предполагается, что у исследователя нет доступа к электронным версиям книг, но есть доступ к книжной полке. Рассмотрим эту ситуацию на конкретном примере решенной задачи.
Суть задачи. Необходимо было определить структуру книжной продукции, содержание которой связано с темой «интернет-представительств общественных и государственных организаций в социальных сервисах».
Исходные данные. В распоряжении автора имелось 624 книги, посвященных информационным технологиям. Эти источники были собраны в течение последних 25 лет (1989–2014 гг.) в ходе обучения, а также научной и практической деятельности автора по различным направлениям, связанным с информационными технологиями.
Первый этап. Интернет-представительства рассматривались в качестве интернет-проектов или интернет-приложений (возможны другие трактовки – именно выбор парадигмы и модели определит содержание кластеров в дальнейшем). Из указанного множества книг было вручную отобрано 115 изданий, содержание которых прямо или косвенно связано с разработкой интернет-приложений.
Второй этап. Была построена очень общая модель проекта по разработке интернет-приложений (в соответствии с ранее принятой парадигмой). На основе этой простой модели был выбран ряд категорий, соответствующих видам деятельности в ходе проекта, в каждой из которых каждой книге присваивалось значение «истина» или «ложь» (1 или 0) в зависимости от того, содержит ли издание информацию, связанную с данной категорией. Вывод производился экспертным путем на основании аннотации, раздела «Содержание» и самого содержания издания. Кроме того, было выделено три категории, отражающих предполагаемую целевую аудиторию книги. Вывод в этой части производился на основании раздела «Для кого предназначена эта книга» и содержания издания (рис. 1).
Разумеется, книге могло быть присвоено значение «истины» сразу в нескольких категориях. Отсюда кажущееся, на первый взгляд, расхождение в цифрах на следующих рисунках и в таблице.
Полученные данные были агрегированы в графической форме (рис. 2, рис. 3). В процессе классификации конкретного набора литературных источников выяснилось, что все книги соответствуют этому критерию (действительно, любая книга способна дать идею или две), поэтому она была исключена из рассмотрения.
о
Целевая аудитория
Этапы проекта (виды деятельности)
Идея
Выгода
Потребность
Концепция
Информационная архитектура
Программная архитектура
Дизайн и взаимодействие
Алгоритмы
о о т о го с о со ф L0
ф о
ф
ф с; m си
Кодирование (языки и технологии)
Разработка баз данных
Тестирование и оптимизация
Внедрение
Анализ параметров решения
Анализ контента
Оценка эффективности

Разработчик
Рис. 1 Возможные категории тематической литературы в зависимости от видов деятельности в рамках разработки интернет-представительств и целевой аудитории
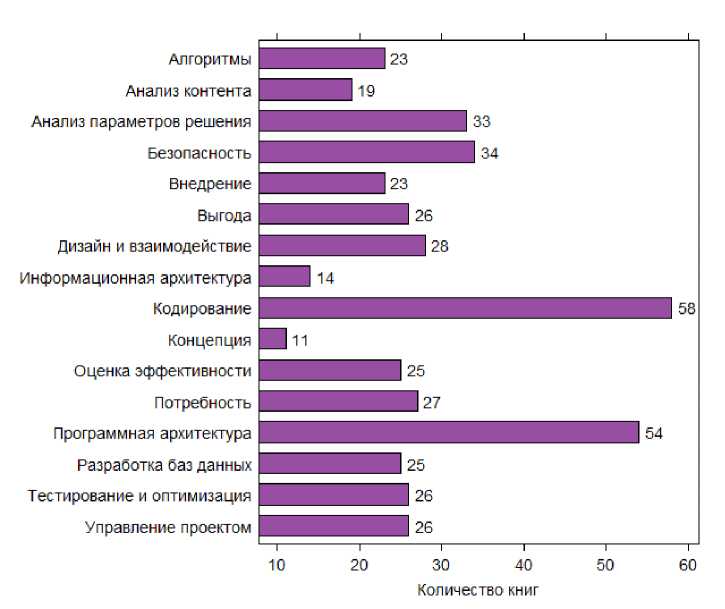
Рис. 2 Распределение видов деятельности по количеству освещающих их книг
Количество книг
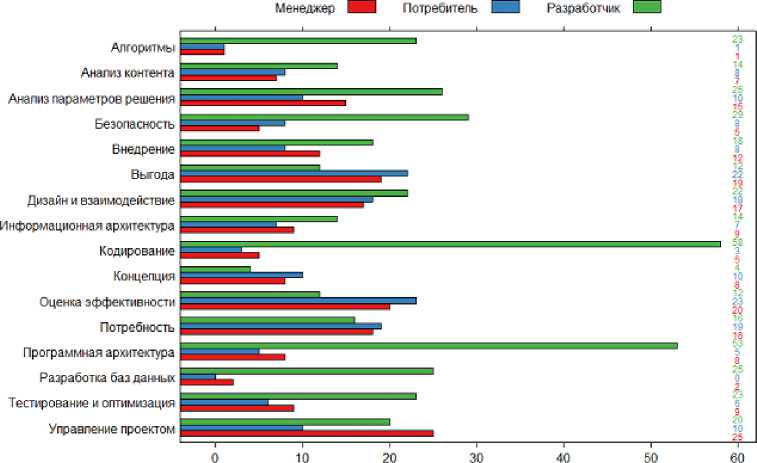
Рис. 3 Распределение видов деятельности по количеству освещающих их книг с учетом целевой аудитории этих книг
В анализируемом наборе литературы имеется явный сдвиг по ее аудиторному предназначению («Разработчик») и по тематической принадлежности («Кодирование», «Программная архитектура»). Это связано, отчасти, с профессиональным образованием автора исследования (обладателя библиотеки), а отчасти с тем, что книги для разработчиков, посвященные кодированию, объективно присутствуют в большем количестве, чем авторитетные источники по разработке концепций интернет-решений или информационной архитектуре: первые проще писать, они быстрее устаревают и чаще переиздаются. Также важно, что согласно диаграммам, даже по сравнению с менее популярными, чем «Кодирование» и «Программная архитектура» категориями, категории «Информационная архитектура» и «Концепция» занимают последние места, а это именно те виды деятельности, в рамках которых и принимается решение о том, каков будет новой сайт, новостная лента в социальном сервисе или иной вид интернет-представительства.
Третий этап. Построение матрицы расстояний между элементами данных (книгами) и иерархическая кластеризация набора полученных данных на основе евклидова расстояния по методу полной связи [6].
Фактически последовательность единиц и нулей, характеризующая отношение книги к каждой из категорий, может быть использована в качестве координат многомерного вектора, характеризующего каждую книгу. В таком случае кластеризация в R выполняется достаточно просто.
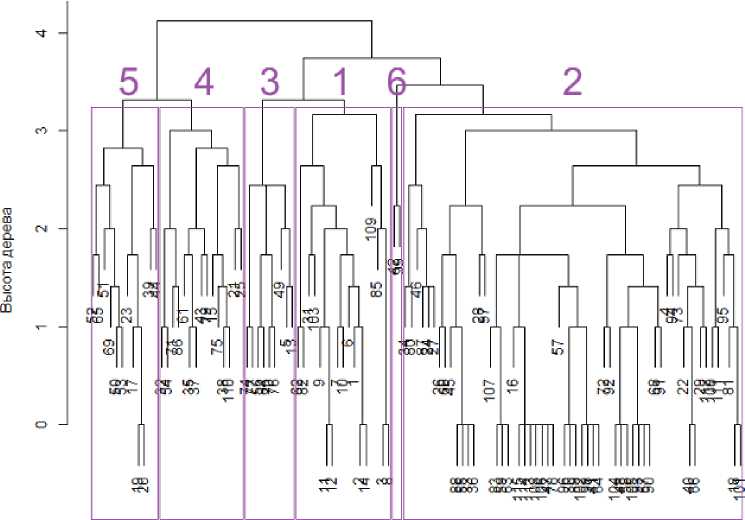
Целью этого этапа являлось получение кластеров книг, каждый из которых можно охарактеризовать содержательно с точки зрения его отличий от других. По этой причине количество рассматриваемых кластеров уменьшалось (выполнялся подъем по уровням дендрограммы) до тех пор, пока:
Номера книг по списку
Рис. 4 Дендрограмма кластеров
Таблица 1
Характеристика книг по кластерам
|
^ н о л |
5 S^ ¥ я ч я о я я я ^ © °- 5 S S Ри я |
Содержательная характеристика кластера |
|
1 |
17 |
В основном в этот кластер попадают книги, предназначенные исключительно для разработчиков и посвященные алгоритмам решения тех или иных технических, аналитических и т. д. задач. Конкретный инструмент решения задачи (программный продукт, язык программирования, СУБД) в такого рода литературе, хотя зачастую и выбирается, но, по сути, является вторичным – одни и те же алгоритмы могут реализовываться с помощью разных инструментов. |
|
2 |
60 |
Наибольший кластер – классические книги для программистов, системных администраторов разработчиков баз данных, посвященные синтаксису языков программирования, взаимодействию с теми или иными API , администрированию различных программных продуктов, тестированию и отладке. Характерная особенность такого рода литературы – жесткая привязка не только к определенным программному продукту, языку программирования или технологии, но и к конкретным версиям таковых (как следствие, такие источники быстро устаревают). |
|
3 |
9 |
Книги, в основном посвященные проектированию взаимодействия пользователя с разрабатываемым программным продуктом или сайтом: удобная навигация, качественная презентация данных и т. д. Адресованы как профессиональным разработчикам, так и потребителям. Основное содержание: как «правильно» сделать что-либо, когда уже решено, что именно необходимо сделать. |
|
4 |
15 |
Наиболее интересный с точки зрения указанного исследования кластер, куда входят издания достаточно общего характера об ИТ, успехах технического прогресса и конкретных проектов в этой области, уровне развития информационного общества. Адресованы в наибольшей степени «потребителям», в меньшей степени менеджерам и в незначительной степени разработчикам. Именно из изданий, попадающих в этот кластер, можно черпать концептуальные положения для разработки конкретных решений (в какой-то мере, вся совокупность подобной литературы – это некое подобие атласа технологий, существующих на данный момент и вариантов их применения). Основных недостатков, касательно темы указанного исследования два: Несмотря на обилие примеров успешности тех или иных решений, конкретные руководства к действию: как с нуля или некоторой концептуальной точки построить эффективное решение, отсутствуют – подобного рода методологий, методов и методик нет ни в одном источнике. Все примеры касаются коммерческого использования интернет-решений. |
|
5 |
12 |
Книги по проектированию решений, могут использоваться как разработчиками, так и потребителями, и менеджерами. Сюда же попадает литература, относящаяся к оценке эффективности интернет-решений. В этом нет ничего удивительного: если в ходе проектирования принято решение реализовать тот или иной веб-сайт, то методы оценки эффективности (например, посещаемость) будут зависеть от этого принятого решения, а не от того, на каком языке сайт запрограммирован. Недостаток: как правило, рассматриваются численные оценки без привязки к определению эффективности с точки зрения предметной области (что есть «эффективность»?). Некоторые категории показателей (например, в части монетизации) неприменимы, если речь идет о государственных организациях. |
|
6 |
2 |
Книги по управлению проектами, адресованы менеджерам и разработчикам (модели разработки ПО, сколько стоит программный проект и т. д., хотя зачастую без конкретных цифр и формул). |
Кластер № 6 практически выделен вручную: хотя книги по управлению проектами в сфере ИТ представляют собой довольно-таки обособленный и явно выделяющийся пласт, но в силу самой природы управления проектом, эти книги также включают информацию о многих других его составляющих, в результате чего, они, по большей части, рассредоточены по первым 5-ти кластерам.
Учитывая ограниченный набор категорий, субъективное представление автора о принадлежности к ним той или иной книги и естественное игнорирование алгоритмом кластеризации какой-либо семантики в содержании литературы, невозможно было ожидать кластеризации, идеально гармонирующей со здравым смыслом или общепринятыми представлениями (например, возможно выделение дополнительных подкластеров), поэтому содержательная характеристика кластеров сформулирована на основании дендрограммы, диаграммы с параллельными координатными осями [7] (рис. 5) и опыта автора в предметной области. На последней из указанных диаграмм, среди прочего, видно, какая доля книг, попавших в одну категорию, попадает также и в следующую, что имеет смысл, если категории упорядочены).
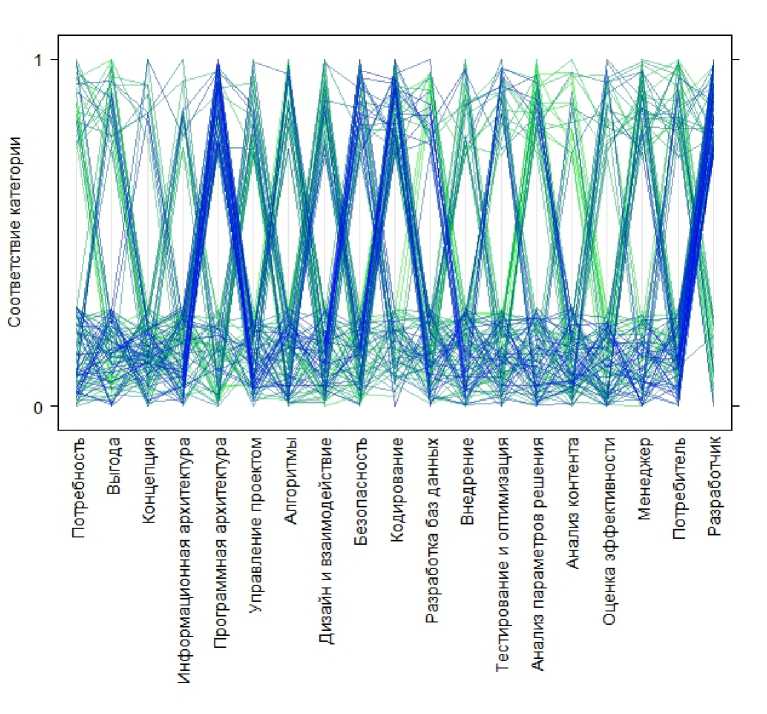
Рис. 5 Соответствие книг категориям в виде диаграммы с параллельными координатными осями
Выводы. В рамках указанного ранее исследования интересными представлялись книги из кластеров № 4 и № 5, однако, если не рассматривать литературу общего характера по истории развития социальных сервисов, других социальных и поисковых технологий (и соответствующих коммерческих компаний), то, с точки зрения возможности прямого применения на практике при разработке интернет-представительств организаций, внимания заслуживает не много источников. Другие работы, в частности, касающиеся алгоритмов интеллектуального Интернета и проектирования взаимодействия, безусловно, могут и должны использоваться в процессах разработки интернет-представительств, но применение из возможно только после формирования концепции и стратегии разработки решения.
Список литературы Применение методов машинного обучения при работе с литературными источниками
- Артюхин В. В. Базовый анализ социальных графов организаций в социальных сервисах на примере МЧС России//Международный электронный журнал «Образовательные технологии и общество (Educational Technology & Society)». 2013. № 2. -С. 562-580. ISSN 1436-4522. URL: http://ifets.ieee.org/russian/depository/v16_i2/pdf/15.pdf
- Артюхин В. В. Социальные сервисы в информационной деятельности МЧС России//Юбилейный сборник «Информационные технологии, связь и защита информации МЧС России -2015». Часть 2. Материалы территориальных органов, организаций и учебных заведений МЧС России. 2015. С. 90-94.
- Pólya, George. “How to Solve It”. Garden City, NY: Doubleday, 1957. -264 p.
- Соколова Е. Г. . Особенности подготовки терминов для русско-английского тезауруса по компьютерной лингвистике/Е. Г. Соколова, С. Ю. Семенова, И. С. Кононенко, Ю. А. Загорулько, О. Ф. Кривнова, В. П. Захаров.//Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной Межд. конф. «Диалог» (Бекасово, 25-29 мая 2011 г.). 2011. Вып. 10 (17). -URL: http://www.dialog-21.ru/dialog2011/materials/html/62.htm (дата обращения 14.04.2015).
- Захаров В. П. Веб-пространство как языковой корпус//Компьютерная лингвистика и интеллектуальные технологии: Труды межд. конф. «Диалог'2005» (Звенигород, 1-6 июня, 2005 г.)/Под ред. И. М. Кобозевой, А. С. Нариньяни, В. П. Селегея. 2005. -URL: http://www.dialog-21.ru/archive/2005/zakharov%20v/zakharovv.htm (дата обращения 15.07.2015).
- Späth, H. Cluster Analysis Algorithms. Chichester: Ellis Horwood, 1980.
- Heinrich J., Weiskopf D. State of the Art of Parallel Coordinates//EUROGRAPHICS 2013. 2003. -URL: https://classes.soe.ucsc.edu/cmps261/Fall13/papers/hcmarsh/StateXofXtheXArtXofXParallelXCoordinates.pdf (дата обращения 14.04.2015).
- Luhn, H. P. The Automatic Creation of Literature Abstracts//IBM Journal. 1958. № 4. -pp. 159-165. -URL: http://courses.ischool.berkeley.edu/i256/f06/papers/luhn58.pdf (дата обращения 14.04.2015).
- Оборнева И. В. Автоматизация оценки качества восприятия текста//Вестник Московского городского педагогического университета. 2005. № 2.
- Miles, Matthew B., Huberman, A. Michael & Saldana, Johnny. Qualitative Data Analysis: A Methods Sourcebook. 3 ed. London: SAGE Publications, Inc., 2014. -384 p.
- Артюхин В. В., Чяснавичюс Ю. К. Планирование аналитического исследования при помощи методов анализа качественных данных//Прикладная информатика. 2014. № 2 (50). -С 23-48.
