Применение нечеткого алгоритма кластеризации C-means для сегментации изображений

Автор: Егорова Д.К., Курбатов Д.И.
Журнал: Огарёв-online @ogarev-online
Статья в выпуске: 10 т.7, 2019 года.
Бесплатный доступ
В статье рассматривается применение нечеткого алгоритма кластеризации с-means для анализа изображений. Приведена программная реализация алгоритма на языке С#.
Итерации, кластеризация, нечеткий метод c-means, пиксели, цвет
Короткий адрес: https://sciup.org/147249655
IDR: 147249655 | УДК: 519.237.8
Application of Fuzzy C-Means Clustering Algorithm for Image Segmentation
Application of fuzzy clustering algorithm with с-means for image analysis is considered in this article. A software implementation of the algorithm in C# is provided.
Текст научной статьи Применение нечеткого алгоритма кластеризации C-means для сегментации изображений
В работе приведена программная реализация сегментации цветного изображения методом с-means, относящегося к методам «мягкой» кластеризации и позволяющего более точно вычислить принадлежность элемента кластеру. Этот алгоритм успешно используется для кластеризации изображений и неконтролируемой сегментации медицинских, геологических, спутниковых изображений и т.п. [1].
Описание алгоритма. Нечеткий алгоритм кластеризации с-means был разработан (для случая m=2) J. C. Dunn в 1973 г. и усовершенствован (для случая m>2) J. C. Bezdek в 1981 г. Данный метод предполагает, что входные данные могут принадлежать более чем одному кластеру одновременно, то есть первоначально для каждого вектора, описывающего исследуемый объект, случайным образом определяется вероятность принадлежности заданным кластерам. Алгоритм получает на входе набор кластеризуемых векторов, количество кластеров, коэффициент неопределенности т и коэффициент £ > 0, определяющий точность алгоритма. Затем запускается итерационный процесс, состоящий в выполнении следующей последовательности действий: 1) расчет центров кластеров; 2) расчет расстояния от каждого вектора до центра каждого кластера; 3) расчет и нормализация коэффициентов принадлежности векторов кластерам; 4) расчет значения матрицы нечеткого 1
разбиения и сравнение этого значения со значением матрицы нечеткого разбиения на предшествующей итерации. На выходе получают матрицу вероятностей принадлежности каждого входного вектора каждому кластеру.
Таким образом, нечеткий алгоритм c-means минимизирует величину
Z i=1 ZMU 0 II* ; - 9Ц2, 1 <m<^. (1)
где m E R, щ^ - коэффициент принадлежности вектора X ; кластеру C j , X ; - i-ый компонент |Х|-мерного вектора X, C - количество кластеров, C j - центр j-ого кластера, а || * ||- норма, определяющая расстояние от вектора до центра кластера. Нечеткое разбиение входных данных на кластеры производится итеративной оптимизацией функции (1), пересчетом коэффициентов принадлежности U ;j и переопределением центров кластеров C j . [2]
Вычисляемые величины. На каждой итерации вычисляются следующие величины.
-
1. Центры кластеров:
-
2. Коэффициент принадлежности:
U ;,j =
Хп^Х с- = -----—
Cj v=^
где щ^ - коэффициент принадлежности X ; вектора к кластеру C j .
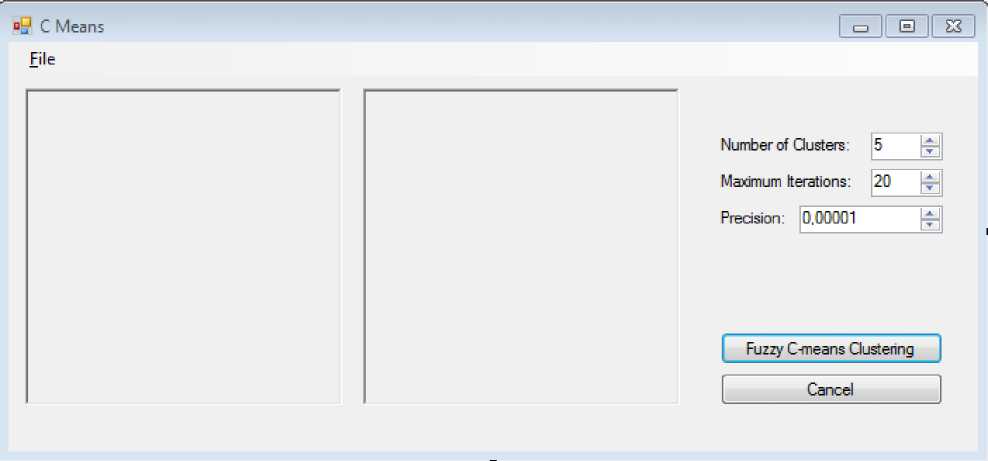
Рис. 1. Графический интерфейс.
Параметры, доступные для изменения, приведены в правой верхней части интерфейса программы – это количество кластеров, максимальное количество итераций и точность.
При активации «Fuzzy C-means Clustering» запускается процесс создания точечных объектов кластера для каждого пикселя изображения (см. код, приведенный ниже).
List
{
Color c2 = originalImage.GetPixel(row, col);
} }
Затем создается заданное количество «ClusterCentroid» объектов кластера. Центры кластеров (или центроиды) на первой итерации выбираются случайным образом и корректируются алгоритмом (см. код).
List
//Create random points to use a the cluster centroids
Random random = new Random();
for (int i = 0; i < numClusters; i++)
}
Далее создается FCM-объект и запускаются итерации (см. код).
k++;
alg.J = alg.CalculateObjectiveFunction();
alg.CalculateClusterCentroids();
double Jnew = alg.CalculateObjectiveFunction();
Console.WriteLine("Run method i={0} accuracy = {1} delta={2}",
-
k, alg.J, Math.Abs(alg.J - Jnew));
backgroundWorker.ReportProgress((100 * k) / maxIterations, "Iteration " + k);
После завершения итераций алгоритм выполняет процесс построения результирующего изображения, назначая каждый пиксель кластеру, для которого он имеет наибольший коэффициент принадлежности.
Для тестового примера было выбрано изображение, представленное на рисунке 2. Сегментация осуществлялась на 2 кластера.

Рис. 2. Исходное изображение.
Результирующее изображение представлено на рисунке 3.

Рис.3. Результат выполнения алгоритма.
Список литературы Применение нечеткого алгоритма кластеризации C-means для сегментации изображений
- Jain A. K. Data clustering: 50 years beyond K-means//Pattern Recognition Letters. -2010. -Vol. 31. -Р. 651-666.
- Барсегян А. А., Куприянов М. С., Холод И. И., Тесс М. Д., Елизаров С. И. Анализ данных и процессов: учеб. пособие/под ред. А. А. Барсегян. -3-е изд., перераб. и доп. -СПб.: БХВ-Петербург, 2009. -512 с. EDN: SDPQDT
- Gauge C. Cluster analysis . -Режим доступа: https://ru.scribd.com (дата обращения 08.05.2019).
