Применение видеоспектрометрии и машинного обучения для оценки чистоты семенного материала

Автор: Нестеров Г.В., Гурылева А.В., Золотухина А.А., Фомин Д.С., Фомин Д.С., Шашко Ю.К., Мачихин А.С.
Журнал: Компьютерная оптика @computer-optics
Рубрика: Обработка изображений, распознавание образов
Статья в выпуске: 3 т.49, 2025 года.
Бесплатный доступ
Настоящая работа посвящена разработке методики выделения примесных семян-засорителей по спектральным изображениям с помощью нейронных сетей. Эта методика отличается возможностью проведения анализа вороха семян, дифференциации близких по спектральным и морфологическим характеристикам зерен, а также оптимизацией основных этапов формирования обучающей выборки нейросетевой модели, регистрации и обработки данных. Предложена архитектура нейросетевой модели на основе последовательно идущих LSTM-ячеек и полносвязных слоев нейронов, а также подходы к выбору размера обучающей выборки, количества и положения центральных длин волн каналов видеоспектрометра, используемых в анализе, и способа сегментации спектральных изображений для формирования обучающей выборки. Разработанная методика отличается возможностью проведения анализа вороха зерна и простотой пополнения базы различаемых культур и примесей. Апробация методики на зернах пшеницы и ячменя показала высокую точность классификации (свыше 99 %) даже близких по спектральным и морфологическим признакам зерен. Предложенный подход повышает точность, производительность и объективность оценки чистоты семенного материала, не требует привлечения опытного персонала и потому будет способствовать ускорению внедрения видеоспектрометров для решения исследовательских и производственных задач агропромышленного комплекса.
Видеоспектрометрия, гиперспектральная съёмка, цифровая обработка изображений, спектральные характеристики, машинное обучение, нейронная сеть LSTM, семенной материал, сельское хозяйство
Короткий адрес: https://sciup.org/140310488
IDR: 140310488 | DOI: 10.18287/2412-6179-CO-1512
Seeds purity assessment by means of spectral imaging
In this work, we propose a technique for identifying impurity grains from spectral images using neural networks that is able to analyze a heap of seeds, grouping grains with similar spectral and morphological characteristics and optimizing the main stages of forming a training sample of a neural network model, recording and processing data. An architecture of the neural network model is proposed based on sequentially running LSTM layers and fully connected layers of neurons. Approaches are proposed for choosing the training sample size, the number and position of central wavelengths of video spectrometer channels used in analysis, and a method for segmenting spectral images to form a training sample. The developed methodology is distinguished by the ability to analyze a heap of seeds and the ease of replenishing the database of distinguished crops and impurities. Testing of the method on wheat and barley seeds showed high classification accuracy (over 99 %) even for grains with very similar spectral and morphological characteristics. The proposed approach increases the accuracy, productivity and objectivity of assessing the purity of seed material, does not require the involvement of experienced personnel and, thus, may be expected to facilitate the introduction of video spectrometers when addressing research and production problems of the agro-industrial complex.
Текст научной статьи Применение видеоспектрометрии и машинного обучения для оценки чистоты семенного материала
Одним из наиболее востребованных оптических методов исследования объектов является видеоспектрометрия, позволяющая бесконтактно получать изображения исследуемой поверхности в различных узких спектральных диапазонах. При этом активное развитие получила как разработка новых принципов, конструктивных и технологических решений для регистрации данных с наибольшими качеством и производительностью, так и создание алгоритмов цифровой обработки, использующих комбинацию морфологических и спектральных признаков объектов. Эффективность применения таких аппаратно-программных средств для научных и практических задач агропромышленного комплекса, биомедицины, неразрушающего контроля и экологического мониторинга показана в ходе многочисленных исследований [1–4].
Видеоспектрометрия уже более 20 лет используется для оценки качества семенного материала зерновых культур, в том числе выделения примесей среди зерен [5]. Наличие в семенном материале зерен других сельскохозяйственных культур или сорных растений, то есть культурной или сорной примеси соответственно, снижает итоговую урожайность посевов и качество зерна. Допустимое количество примесей регламентируется государственными стандартами [6], нарушение которых приводит к признанию партии семенного материала непригодной для использования и отправке ее на сортировку или утилизацию. Традиционными методами контроля чистоты семенного материала являются визуальный осмотр или анализ с помощью аналитического оборудования (ПЦР-анализ или электрофорез) отдельной пробы из партии. Более современным подходом к анализу семенного материала является использование фотосепараторов, выгодно отличающихся от традиционных методов по трудоемкости и производительности, а также зачастую объективности и точности. Наибольшую точность при различении зерна с близкими цветовыми и геометрическими характеристиками показывают ви-деоспектральные приборы, применяемые как для контроля, так и в системах сортировки [7– 10]. Ключевыми элементами таких методик являются схема регистрации и алгоритмы обработки данных. В большинстве работ для организации съемки семян требуется размещать зерна в исследуемой пробе без соприкосновения друг с другом или помещать их по одному в отдельные ячейки [10, 11]. Такой подход позволяет добиться высокой точности выделения примесей, поскольку исключает появление теней и искажения формы семян из-за их взаимного частичного перекрытия, наблюдающегося при случайном расположении зерна в так называемом ворохе семян, однако заметно снижает производительность анализа.
Для обработки спектральных данных применяются самостоятельно или совместно различные подходы, гарантирующие выделение спектральной примеси с требуемой точностью, среди которых анализ аномалий на изображениях при комбинации кадров нескольких каналов, сопоставление спектральных характеристик с эталонными из баз данных, а также применение машинного обучения, получающего в последние годы все большее распространение [12– 14]. Для работы с методами машинного обучения требуется организация подготовки данных, определение выбора алгоритма и оптимизация его параметров, при этом для конечного пользователя в практических задачах необходимо либо наличие готового решения, либо применение методов автоматического обучения [15, 16]. Разработаны подходы к автоматизации отдельных этапов обработки видеоспектральных данных, например, выбора регрессионных моделей [17, 18], однако создание алгоритма подбора оптимальных параметров всех этапов обработки все еще остается сложной задачей из-за значительного объема данных и разнообразия решаемых задач.
В большинстве работ, посвященных исследованию эффективности различных методов машинного обучения для рассматриваемой задачи, применение нейронных сетей выделяется как подход, обеспечивающий наибольшую точность классификации [19, 20]. Размер обучающей выборки и способ разметки и преобразования спектральных изображений в набор данных для обучения, как правило, указываются справочно и выбор оптимальных параметров остается открытым [21, 22]. При этом указанные характеристики значительно влияют не только на трудоемкость регистрации данных, но и на результаты обработки [23]. Другим важным аспектом анализа гиперспектральных данных является определение количества и положения центральных длин волн каналов, используемых в нейросетевой модели. Зачастую применение полного набора данных из сотен каналов, следующих непрерывно с малым шагом, для выделения одной примеси в зернах является избыточным, и сокращение числа каналов приводит к повышению скорости обработки и доступности оборудования для анализа [7, 10].
Настоящая работа посвящена разработке методики выделения примесных зерен по спектральным изображениям с помощью нейронных сетей, отличающейся возможностью проведения анализа вороха зерна, дифференциации близких по спектральным и морфологическим характеристикам зерен, а также оптимизацией основных этапов формирования обучающей выборки нейросетевой модели.
1. Материалы и методы 1.1. Схема эксперимента
Исследование состояло из двух этапов (рис. 1).
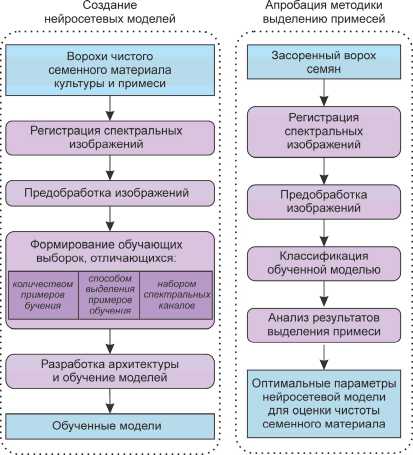
Рис. 1. Основные этапы разработки методики
На первом этапе проводилась разработка нейросетевой модели для выделения примесей по данным съемки видеоспектрометром и ее обучение на различным образом сформированных выборках. Выборки формировались из спектральных изображений ворохов чистого семенного материала пшеницы и ячменя. При этом рассматривались различное количество и положения центральных длин волн каналов, способы разметки и преобразования кадров для формирования обучающей выборки и объем обучающей выборки. Второй этап состоял из апробации предло- женного подхода и обученных моделей на спектральных изображениях засоренного вороха зерна и определения оптимального набора параметров для оценки чистоты семенного материала.
-
1.2. Экспериментальные образцы
В исследовании использовались зерна пшеницы и ячменя сортов Награда и Родник Прикамья, отобранные на территории агрополигона Пермского НИИСХ филиала ПФИЦ УрО РАН. Пшеница занимает ключевое место в агроиндустрии, являясь самой распространенной злаковой культурой, одним из основных элементов кормовой базы в животноводстве и источников питательных веществ для человека. Засоренность семенного материала пшеницы зернами ячменя является распространённым на практике случаем, а выделение такой примеси оказывается сравнительно сложным, так как зерна пшеницы и ячменя имеют близкие спектральные и морфологические характеристики (рис. 2).
Для размещения зерен использовались чашки Петри диаметром 10 см с белой подложкой, вмещающие около сотни зерен плотным слоем, имитирующим ворох на конвейере.
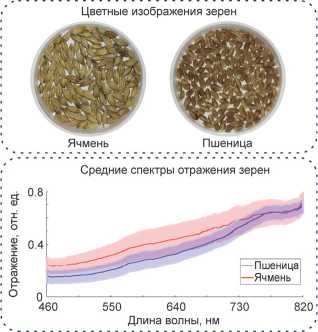
Рис. 2. Внешний вид и спектры отражения семян исследованных культур
Государственный стандарт ограничивает предельно допустимую величину содержания примесей в семенном материале двумя процентами [24]. При формировании образцов засоренного вороха в чашки Петри с чистым семенным материалом пшеницы добавлялись зерна ячменя массой 1, 2 и 3 % от общей массы семян пшеницы.
-
1.3. Оборудование
Наибольшее различие спектральных характеристик семян большинства злаковых культурных растений наблюдается в диапазоне 900– 1700 нм, а анализ в этой спектральной области обеспечивает наиболее надежный и точный результат [11, 25–28]. При этом показано, что при грамотном подборе методов обработки спектральных изображений сопоставимые по точности результаты могут быть получены при рабо-
- те в видимой и ближней инфракрасной области, а реализующие такую съемку приборы оказываются более доступными [10, 29]. В рамках исследования регистрация данных осуществлялась разработанным в НТЦ УП РАН акустооптическим видеоспектрометром (АОВС) [30] (спектральный диапазон – 450– 850 нм, минимальный интервал между каналами – 1 нм, ширина полосы пропускания – 2,5 нм при λ =650 нм, размер изображения – 800×800 пикселей, угловое поле - 15°), обладающим возможностью произвольной спектральной адресации, значительно повышающей производительность рутинной съемки при известных наиболее информативных длинах волн. Подсветка объектов проводилась галогенной лампой Dedolight DLH4.
-
1.4. Регистрация спектральных данных
Чашка Петри с зернами размещалась на платформе на расстоянии 0,5 м от первой поверхности объектива АОВС, что обеспечивало заполнение всего поля зрения прибора чашкой. Спектральные изображения регистрировались в диапазоне длин волн от 460 до 820 нм с шагом между каналами 2 нм, что позволяло за одну съемку получить набор из 181 кадра на разных длинах волн.
Для первого этапа эксперимента было получено по 40 наборов спектральных изображений чистого семенного материала ячменя и пшеницы. Для каждой съемки семена набирались в чашку Петри заново из общего контейнера. На втором этапе исследования проводилась регистрация спектральных изображений засоренного вороха зерна пшеницы. Каждый образец с различным содержанием примеси от 1 % до 3 % был отснят 6 раз. Перед каждой съемкой проводилось перемешивание зерен для учета наибольшего количества возможных наложений зерен. Для последующей корректировки неизбежных пространственноспектральных искажений [31] регистрировались спектральные характеристики белой однородной диффузно отражающей пластины в тех же условиях, что и при съемке образцов.
-
1.5. Предобработка данных
Все полученные наборы спектральных изображений проходили одинаковую предобработку. Для корректировки влияния на регистрируемые данные пространственной и спектральной неравномерности освещённости объектов, виньетирования оптической системы и неоднородности чувствительности матричного приемника излучения проводилось попик-сельное деление наборов кадров образцов на изображения пластины. Устранение шумовой составляющей осуществлялось последовательным применением медианной фильтрации (размер окна – 3×3 пикселя). Для выделения относящихся к зерну пикселей проводилась пороговая бинаризация итогового изображения, полученного делением спектрального изображе- ния на длине волны 750 нм на изображения 550 и 600 нм. В результате выделения пикселей со значением интенсивности выше 3 была получена маска, далее применяемая ко всему набору изображений отдельной съемки.
-
1.6. Формирование обучающих выборок
При формировании обучающей выборки было рассмотрено три аспекта, влияющих на результаты обучения нейросетевой модели и ее последующей точности классификации: количество и положения центральных длин волн каналов, в которых регистрировались используемые для обучения изображения; способы разметки и преобразования кадров в обучающую выборку; размер обучающей выборки. Для каждого из перечисленных аспектов было выбрано несколько вариантов реализации, рассмотрены их сочетания и определены предпочтительные варианты для решения поставленной задачи.
-
1.6.1. Сегментация изображения
В качестве отдельных наблюдений обучающей выборки использовались дискретные значения спектральной характеристики отражения образцов в виде вектора. Такой вектор представлял собой последовательность величин спектрального коэффициента отражения образца на различных длинах волн. Для преобразования набора спектральных кадров в указанные вектора использовалась сегментация изображения на отдельные элементы, каждому из которых соответствовало свое наблюдение.
В исследовании рассмотрено два подхода к процедуре сегментации, отличающихся отсутствием необходимости ручной разметки. Первый подход включал простое разделение на пиксели в пределах маски, определенной на этапе предобработки. Такая сегментация обеспечивает получение за одну съемку сравнительно большого количества примеров обучения, около 200000, со значительным разбросом значений среди них ввиду включения в выборку пикселей, относящихся к тени или блику на зернах.
В рамках второго подхода к сегментации проводилось разделение изображения на отдельные зерна с помощью алгоритма CellPose [32], определяющего центр зерна и принадлежащую ему окрестность пикселей на основе градиента интенсивности. Единичный пример обучения формировался из значений усредненной интенсивности пикселей, относящихся к отдельному зерну. Выборка, полученная при таком подходе, включала данные с меньшим разбросом, из набора спектральных изображений одной съемки могли быть получены около 100 наблюдений.
-
1.6.2. Размер выборки
Размер выборки, используемой при обучении нейросетевой модели, влияет как на точность последующей классификации, так и на трудоемкость ее формирования и дополнения. В настоящей работе рассмотрены выборки из 2500, 5000 и 10000 наблюдений, потребовавших 10, 20, и 40 съемок соответственно. При этом при сегментировании кадров на отдельные зерна в обучающую выборку были включены спектральные характеристики всех зерен из проведенных съемок, а при сегментировании по пикселям из всех наблюдений было случайным образом выбрано указанное количество реализаций.
-
1.6.3. Набор спектральных каналов
Регистрация спектральных характеристик отражения семян в сотнях каналов требует сравнительно большого времени накопления данных, при этом вклад в межклассовую дисперсию соседних каналов оказывается мал. Была исследована эффективность использования для выделения примесей всех спектральных данных, зарегистрированных в 181 канале, и кадров только на информативных для разделения зерен пшеницы и ячменя длинах волн. При этом в выборку включались вектора, состоящие либо из 181 значения коэффициента отражения образца, соответствующего 181 каналу видеоспектрометра, либо из 12 значений коэффициента отражения на наиболее информативных длинах волн. Съемка на выделенных каналах впоследствии может быть реализована с помощью мультиспектрального оборудования, отличающегося возможностью регистрации изображений во всех каналах за один кадр, а значит, высокой производительностью и сравнительно малыми габаритами.
Определение центральных длин волн информативных каналов и их количества проводилось с помощью алгоритма Competitive Adaptive Reweighted Sampling (CARS), показавшего свою высокую эффективность в подобных рассматриваемой задаче относительно вейвлет-преобразований, анализа главных компонент или других методов статистического анализа [33 – 35].
-
1.7. Разработка архитектуры, обучение и тестирование нейросетевой модели
Анализ данных осуществлялся с использованием нейросетевой модели на основе архитектуры Long short-term memory (LSTM), успешно применяемой для классификации зерен различных культур по спектральным характеристикам и показавшей точность классификации выше, чем у сверточных нейронных сетей [14, 25]. Основная особенность такой архитектуры заключается в выделении признаков в связной последовательности данных. В качестве такой последовательности, поступающей на вход нейросетевой модели, рассматривался вектор из связанных значений спектрального коэффициента отражения на различных возрастающих длинах волн. Модификация архитектуры нейронной модели состояла в увеличении количества рекуррентных узлов LSTM, а также в замене функции активации между полносвязными слоями нейронов. Используемая в работе архитектура модели (рис. 3) включала в себя рекуррентный блок, состоящий из четырех слоев LSTM с постепенно увеличивающимся количеством узлов, которые были разряжены пакетной нормализацией. После рекуррентного блок шел блок полносвязных слоев нейронов с функцией активации Leaky ReLU [36].
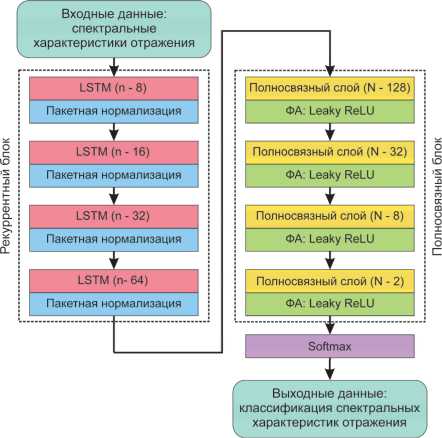
Рис. 3. Архитектура предложенной нейросетевой модели. N – количество нейронов, n – количество рекуррентных узлов, ФА – функция активации
При обучении нейросетевой модели использовались различные по размеру (2500, 5000 и 10000 наблюдений), набору спектральных каналов (181 и 12 спектральных каналов в каждом наблюдении) и способу сегментации изображения выборки (разделение на пиксели и разделение на зерна), всего 18 вариантов. Обучающие выборки формировались из 80% данных, имеющихся для каждого варианта, 10% использовалось для валидации во время обучения, оставшиеся 10% шли на тестирование, то есть проверку точности обученной модели. В качестве алгоритма обучения использовался алгоритм Adam [37], размер мини-батча составил 32 вектора спектральных характеристик. Число эпох определялось из условия достижения прироста в точности классификации после текущей эпохи, относительно предшествующей менее 1 %, после чего обучение прекращалось. Минимальное число эпох составило 1, максимальное – 4. Далее в ходе тестирования определялась точность классификации модели метрикой accuracy , характеризуемая процентом верно классифицированных наблюдений в тестовой выборке, а также значения функции ошибки.
1.8. Апробация предложенного подхода
2. Результаты и обсуждение
Апробация предложенного подхода к выделению примесных зерен осуществлялась с использованием изображения засоренного вороха зерна с различным содержанием примеси, зарегистрированных и пре- добработанных аналогично кадрам, использованным при формировании обучающих выборок. К изображениям также параллельно применялись два алгоритма сегментации, а полученные спектральные характеристики отражения единичных пикселей или зерен далее передавались для обработки нейросетевым моделям, обученным по соответствующим образом сегментированным изображениям. Нейросетевая обработка состояла в классификации отдельных пикселей или групп пикселей целых зерен, относящихся к зернам пшеницы или ячменя. Далее проводился анализ бинарного изображения, показывающего расположение пикселей, относящихся к примеси. Для результата попиксельной классификации осуществлялась морфологическая обработка, состоящая в удалении единичных пикселей, скелетизации второго порядка с последующей дилатацией, устранении связанных объектов малого размера (менее 6000 пикселей), то есть неверно классифицированных как примесь и наращивании оставшихся элементов для придания целостной формы зерну. На последнем этапе подсчитывалось количество определенных как примесь объектов, полученное значение переводилось в долю от зерен пшеницы в исследуемом образце и соотносилось с известным процентом содержания примеси в нем. По результатам анализа образцов в каждом варианте высчитывалось среднее значение и стандартное отклонение процента содержания примеси, определенного по описанной схеме.
В работе рассматривается подход как к автоматическому поиску примесей в ворохе зерна, так и к определению оптимальных параметров нейросетевой обработки для указанной задачи. На первом этапе работы были определены способы формирования образцов для обучения и тестирования нейросетевой модели и апробации подхода, схема регистрации спектральных данных, выбран алгоритм предобработки данных, а также набор параметров, изменяемых при формировании различных обучающих выборок, и непосредственно созданы и обучены модели. На втором этапе осуществлялась оценка эффективности работы полученных нейросетевых моделей при поиске примесных зерен при их малом содержании в пробе (рис. 4).

Рис. 4. Пример работы алгоритма выделения примеси
В ходе определения центральных длин волн наиболее информативных спектральных каналов и их количества с помощью алгоритма CARS было выделено 12 длин волн (460 нм, 570 нм, 582 нм, 586 нм, 694 нм, 696 нм, 708 нм, 710 нм, 766 нм, 768 нм, 770 нм, 820 нм), смоделированные изображения на которых были рассмотрены в одном из вариантов выборки.
Точность классификации с помощью нейросетевых моделей, определенный ими средний процент засоренности по 6 сериям и его стандартное отклонение для рассмотренных вариантов формирования обучающих наборов данных собраны в табл. 1. Предложенная архитектура нейросетевой модели показала довольно высокую точность классификации – свыше 90% для всех рассмотренных вариантов формирования обучающей выборки и последующей апробации.
Точности классификации при тестировании и валидации данных в конце обучения имели близкие значения с различием порядка 1 % и превышали 97% для всех моделей. Величины функции ошибки для всех моделей не превышали 0,1.
Одним из наиболее значимых результатов проведенной апробации является продемонстрированная близость точности классификации, а также значения абсолютной погрешности и разброса определяемого алгоритмом процента примеси для различного набора каналов. Так, подбор подходящих каналов позволяет без потери качества анализа сократить их количество в 15 раз и, как следствие, снизить время на регистрацию и обработку, а также значительно уменьшить требования к видеоспектрометру.
Табл. 1. Результаты дифференцирования культурной примеси в ворохе зерна пшеницы
|
Набор спектральных каналов |
Размер выборки, % |
Результаты апробации нейросетевых моделей, работающих с данными после сегментации кадров на отдельные зерна |
Результаты апробации нейросетевых моделей, работающих с данными после попиксельной сегментации кадров |
||||||
|
Точность классификации, % |
Определенное с помощью алгоритма содержание примеси при величине истинной засоренности |
Точность классификации, % |
Определенное с помощью алгоритма содержание примеси при величине истинной засоренности |
||||||
|
1 % |
2 % |
3 % |
1 % |
2 % |
3 % |
||||
|
Полный спектр (181 канал) |
100 |
99,9 |
1,83 ± 0,41 |
2,00 ± 0,63 |
3,53 ± 0,55 |
92,9 |
0,83 ± 0,41 |
1,83 ± 0,41 |
3,00 ± 0,00 |
|
50 |
99,8 |
1,67 ± 0,52 |
1,67 ± 0,52 |
3,50 ± 0,55 |
91,8 |
1,17 ± 0,41 |
2,00 ± 0,00 |
3,50 ± 0,55 |
|
|
25 |
97,6 |
1,17 ± 0,41 |
1,57 ± 0,55 |
3,17 ± 0,41 |
90,7 |
1,17 ± 0,41 |
2,00 ± 0,00 |
3,17 ± 0,41 |
|
|
CARS (12 каналов) |
100 |
99,9 |
1,33 ± 0,52 |
2,00 ± 0,00 |
3,50 ± 0,55 |
93,4 |
1,17 ± 0,41 |
1,83 ± 0,41 |
3,00 ± 0,00 |
|
50 |
99,4 |
1,67 ± 0,82 |
2,17 ± 0,41 |
3,67 ± 1,03 |
91,3 |
1,17 ± 0,41 |
2,00 ± 0,00 |
3,00 ± 0,00 |
|
|
25 |
99,4 |
1,67 ± 0,82 |
2,00 ± 0,00 |
3,83 ± 0,75 |
90,4 |
1,17 ± 0,41 |
2,00 ± 0,00 |
3,33 ± 0,51 |
|
Точность классификации, которая в большинстве схожих исследований является основным критерием оценки разрабатываемых моделей, в текущем исследовании оказалась выше для нейросетевых моделей, обученных на данных после сегментации кадров на отдельные зерна. Однако апробация на образцах вороха зерна с различной степенью засоренности показала, что в такой близкой к практике задаче лучшие значения абсолютной погрешности и разброса, определяемого алгоритмом процента примеси, достигаются при использовании сегментации кадров на отдельные пиксели и последующей морфологической обработки. Классификация спектра отражения в каждом пикселе требует почти на 70 % больше времени для выделения примеси, чем классификация групп пикселей отдельных зерен. Однако по-пиксельный способ сегментации обеспечивает на несколько порядков большее количество отдельных наблюдений за одну съемку для формирования обучающей выборки и таким образом ускоряет эту процедуру. Размер выборки оказывал большее влияние на итоговую точность классификации при использо- вании сегментации кадров на отдельные зерна, что связано с меньшим разнообразием значений наблюдений при таком подходе.
Одним из оригинальных решений работы является разработка подхода к проведению спектрального анализа засоренности произвольного вороха зерна, а не упорядоченно расположенных зерен. Такая задача намного ближе к практике, однако ранее в литературе не освещалась, поэтому при проведении обзора литературы и выборе реализации архитектуры модели нейронной сети рассматривались все близкие исследования, в которых применялись методы машинного обучения, такие как SVM, K-means, нейронные сети прямого распространения, сверточные сети, LSTM и т.д., в том числе и для многоклассовой классификации. При этом в значительном числе работ архитектура LSTM показала наилучшие значения оценочных метрик даже для сложных задач. Определение оптимальной модели нейронной сети для рассмотренной задачи по предложенным метрикам могло бы стать темой отдельного исследования, развивающего подходы текущей работы.
Предложенная методика сбора и обработки данных обеспечивает простое, не требующее разметки пополнение базы данных спектральных характеристик для обучения нейросетевой модели при необходимости расширения распознаваемых сочетаний культур и примесей. Такой процесс может быть реализован дополнительной съемкой новых образцов во всем спектральном диапазоне, определением количества и положения оптимальных для их выделения спектральных каналов и последующим дообучением модели. При этом использование АОВС с произвольной спектральной адресацией в дальнейшей рутинной съемке позволяет с помощью одного устройства гибко подстраивать каналы регистрации под рассматриваемые сочетания примесей и культур, сохраняя производительность и сравнительно небольшие объемы вычислений.
Заключение
В настоящем исследовании проведена разработка методики, позволяющей определять степень засоренности семенного материала злаковых культур на основе анализа спектральных изображений вороха зерна с применением методов машинного обучения. Предложена модификация архитектуры нейросетевой модели. Рассмотрены и оптимизированы основные этапы формирования обучающей выборки и проведения рутинной съемки и обработки спектральных данных, в том числе выбор количества и положения центральных длин волн каналов видеоспектрометра, способа сегментации спектральных изображений для формирования обучающей выборки и объема обучающей выборки. Предложенный подход отличается возможностью проведения анализа вороха зерна и простотой пополнения базы различаемых культур и примесей без разметки, а предусмотренный методикой выбор наиболее информативных для анализа длин волн позволяет сократить время регистрации и анализа данных. Апробация методики на семенах пшеницы и ячменя показала высокую точность классификации (свыше 99%) даже близких по спектральным и морфологическим признакам зерен. Использование АОВС с произвольной спектральной адресацией в рутинном выделении примесных зерен позволит гибко подстраивать каналы регистрации под рассматриваемые сочетания примесей и культур, сохраняя производительность и сравнительно небольшие объемы вычислений.
Предложенный подход не требует привлечения опытного персонала и потому будет способствовать ускорению внедрения видеоспектрометров для решения исследовательских и производственных задач агропромышленного комплекса.
Исследование проведено за счет субсидии Министерства образования и науки Пермского края в рам- ках реализации научного проекта «Разработка методических, аппаратных и программных средств для дистанционного мультиспектрального мониторинга земель сельскохозяйственного назначения» от 26 января 2024 года, № С-26/40.
Результаты работы получены с использованием оборудования Центра коллективного пользования Научно-технологического центра уникального приборостроения РАН [].
