Прогнозирование посещаемости кафе методами машинного обучения

Автор: Гук К.О.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 3 (59) т.15, 2023 года.
Бесплатный доступ
При развитии сферы обслуживания каждому владельцу ресторана важно максимизировать свой доход. Для этого нужно правильно распределять трудовые ресурсы и производить закупки. Чтобы это сделать, необходимо производить оценку потока покупателей. В данной работе было произведено исследование для предсказаний количества посетителей методами машинного обучения.
Прогнозирование, машинное обучение, сфера услуг, поток клиентов
Короткий адрес: https://sciup.org/142239459
IDR: 142239459 | УДК: 519.2
Predicting cafe attendance using machine learning methods
When designing a service area, it is important for every restaurant owner to maximize their income. To do this, it is necessary to correctly allocate labor resources and make purchases, and to do this, it is necessary to estimate the flow of customers. In this paper, a study was conducted on predicting the number of customers using machine learning techniques.
Текст научной статьи Прогнозирование посещаемости кафе методами машинного обучения
При развитии сферы обслуживания каждому владельцу ресторана, важно максимизировать свой доход. Для этого нужно правильно распределять трудовые ресурсы и производить закупки. Чтобы это сделать, необходимо производить оценку потока, покупателей. В данной работе было произведено исследование для предсказаний количества, посетителей методами машинного обучения.
2. Постановка задачи и методы
Рассматривается задача, прогнозирования числа, посетителей в ресторане по ежедневным данным о количестве реализованных чеков. Цель — разработка, модели, позволяющей оценить число посетителей на месяц вперед. Прогноз осуществляется на основании информации:
-
• о посещения в предыдущий день;
-
• о погоде;
-
• о праздниках;
-
• о бронирование столов и предзаказах.
Прогнозная точноств определяется по формуле МАРЕ (Mean Absolute Percentage Error) [1]:
1 n
At - F t
A t
МАРЕ = n t=i n - количество наблюдений, At - реальные значения, Ft - предсказанное значение.
Так как в модели участвуют лаги, то при предсказаниях на будущее нужно пользоваться «методом цепного предсказания» - делать предсказание на один день вперед и использовать это значение в дальнейшем.
3. Модели
В качестве первой модели рассматриваем модель из библиотеки Prophet. Библиотека Prophet [2] - это библиотека с открытым исходным кодом, предназначенная для прогнозирования одномерных наборов данных временных рядов. Он прост в использовании и предназначен для автоматического поиска хорошего набора гиперпараметров для модели, чтобы делать точные прогнозы для данных с тенденциями и сезонной структурой по умолчанию. Математическое уравнение [2], лежащее в основе модели Prophet, определяется как
W) = 9(t + s(t) + ^(t) + e(t), где g(t) представляет тренд; s(t) - периодические изменения (еженедельно, ежемесячно, ежегодно); h(t) - влияние праздников и e(t) - член ошибки. Модель Prophet строится только на данных о дате и целевой переменной.
Результаты подсчета метрик (табл. 1):
Таблица 1
Результаты Prophet
|
R2 |
MSE |
МАЕ |
МАРЕ |
|
|
Train |
0.517 |
1387.575 |
26.404 |
0.937 |
|
Test |
-0.069 |
1255.269 |
30.728 |
0.152 |
На основе модели были сделаны предсказания потока клиентов и построен график, изображенный на рис. 1, где непрерывная линия является предсказанием модели, точками отмечены реальные значения данных.
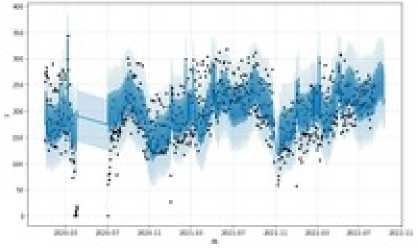
Рис. 1. График реальных и предсказанных значений
Вторая рассмотренная модель CatBoostRegression - это модель градиентного бустинга. Для работы с данной моделью произведено OneHot encoding для категориальных величин и произведена работа по замене «плохих значений». Для работы сформированы три да-тасета: два кафе находятся в одном и том же городе, но на разных улицах, а одно кафе располагается в другом городе. Это было сделано для того, чтобы показать, что расположение кафе влияет на предсказания для целевой характеристики, нельзя использовать одну модель без изменений для всех кафе.
Далее были проведены эксперименты. На основе модели CatBoost сделаны подсчеты основных характеристик при условии, что производится препроцесенг с вязанный с целевой характеристикой. Это значит, что были убраны все значения, которые меньше, чем 10%-quantile от данной характеристики. Данные пропуски насчитывают небольшое количество и заменены с помощью линейной регрессии. Далее на основе данного датасета производились эксперименты по подбору гиперпараметров, при дополнительном присутствии MinMaxScaler на целевой характеристике. Далее приведены данные экспериментов для одного из ресторанов (табл. 2).
Результаты CatBoostRegerssion
Таблица 2
|
Grid Search |
Grid Search scaler |
Hyperopt |
Hyperopt scaler |
CatBoost Regression model |
Scaler model |
|
|
МАРЕ train |
0.069163 |
0.579511 |
0.118369 |
0.914706 |
0.001616 |
0.021274 |
|
МАРЕ test |
0.130993 |
1.144692 |
0.141661 |
0.993262 |
0.127677 |
1.421219 |
|
МАЕ train |
6.641845 |
0.407208 |
11.326168 |
0.736196 |
0.153733 |
0.005740 |
|
МАЕ test |
11.838631 |
0.691044 |
12.545031 |
0.730116 |
11.524332 |
0.641509 |
|
R2 train |
0.777266 |
0.740106 |
0.378887 |
0.183957 |
0.999887 |
0.999955 |
|
R2 test |
0.142150 |
0.098998 |
0.072012 |
0.037930 |
0.199771 |
0.198759 |
4. Выводы
По результатам получается, что лучше всего использовать модель CatBoost без MinMaxScaler с добавленными данными о предзаказах. При работе было выявлено большое влияние праздников и появилась необходимость составления списка праздников по городу, так как от праздников часто зависят ограничения на продажу алкогольных напитков.
Список литературы Прогнозирование посещаемости кафе методами машинного обучения
- Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. Москва: Депо, 2004. 576 с. EDN: QQCVBX
- Taylor S.J., Letham В. Forecasting at scale. PeerJ Preprints 5:e3190v2. URL: , 2017. P. 25. DOI: 10.7287/peerj.preprints.3190v2
