Прогнозирование результатов экспертного оценивания точек продаж с помощью нейронной сети

Автор: Булычев Дмитрий Михайлович
Рубрика: Управление сложными системами
Статья в выпуске: 4, 2019 года.
Бесплатный доступ
Сформировано признаковое пространство экспертной оценки точек продаж на основе агрегированных данных. Введена гипотетическая формула оценки параметров и приведен пример отображения признакового пространства в пространство экспертных оценок специалистов. Разработан адаптивный алгоритм обработки больших данных, спроектирована и оптимизирована нейронная сеть, обучена модель, обеспечивающая прогноз с абсолютной средней ошибкой 0,448.
Анализ данных, искусственные нейронные сети, геомаркетинг, полносвязная нейронная сеть, большие данные
Короткий адрес: https://sciup.org/148309049
IDR: 148309049 | УДК: 004.032.26 | DOI: 10.25586/RNU.V9187.19.04.P.065
Prediction the results of expert evaluation of points of sale using a neural network
The features space of expert evaluation of sales points is formed on the basis of aggregated data. A hypothetical formula for parameter estimation is introduced and an example of mapping the feature space to the expert evaluation space is given. The adaptive algorithm of big data processing is developed, the neural network is designed and optimized, the model providing the prediction with an absolute average error of 0,448 is trained.
Текст научной статьи Прогнозирование результатов экспертного оценивания точек продаж с помощью нейронной сети
В настоящее время точки продаж в большинстве случаев выбираются на основе опыта и интуиции экспертов, которые подкрепляют свой выбор абстрактными оценками, построенными на эвристиках, причем разные эксперты используют различные эвристики [3]. Представляется целесообразным, используя методы машинного обучения, стандартизировать и упростить получение оценки, обучив модель на оценках экспертов, использующих одинаковые или похожие способы оценивания. В настоящее время чаще всего геомаркетинговые компании продают данные и предоставляют услуги по прогнозированию определенных характеристик, таких как ожидаемая выручка, клиентский поток и др. Эти исследования проводятся экспертами вручную на основе статистических расчетов, а выводы делаются на небольшом наборе данных с привлечением эвристических оценок [2; 3].
Целью настоящей работы является разработка алгоритма машинного обучения, позволяющего предсказывать экспертные оценки коммерческого потенциала точек продаж на основе существующих результатов оценивания действующих экспертов. В качестве такого алгоритма была выбрана нейронная сеть. Данный выбор обусловлен способностью нейронных сетей к автоматическому отбору признаков и способностью дообучаться. Помимо этого, нейронные сети относительно легко масштабируются [5].
Автоматический отбор признаков позволит экспериментировать с различными данными без необходимости тщательного ручного подбора значимых признаков. То есть появляется устойчивость к информационному шуму.
Возможность дообучения – чрезвычайно важное свойство алгоритма в рамках рассматриваемой задачи. Это позволит модели при появлении новых данных сразу учитывать их, что открывает возможность постоянно улучшать качество прогноза и сглаживать сезонные эффекты.
Структура экспертной оценки
Исходя из практики маркетинговых исследований [4; 6; 7], можно выявить следующие существенные параметры, которые используются для оценивания точек продаж:
-
1) престижность района;
-
2) арендная плата;
Булычев Д.М. Прогнозирование результатов экспертного оценивания точек... 67
-
3) стоимость строительства;
-
4) численность населения в окрестности;
-
5) доступность для личного транспорта;
-
6) близость к крупным торговым точкам другого типа;
-
7) видимость торговой точки;
-
8) потребительский потенциал;
-
9) суммарная площадь предприятий;
-
10) конкуренция;
-
11) размер офисов в окрестности;
-
12) автомобильный трафик;
-
13) пешеходный трафик.
Набор данных
В геомаркетинге данные обладают низкой доступностью, а их получение является сложной и дорогостоящей операцией, поэтому в открытом доступе находится мало полезной информации. Маркетологи для своих исследований покупают данные у геомаркетинго-вых сервисов или обеспечивают их поступление посредством организации собственных исследований. И то и другое требует значительных ресурсов. В связи с этим в настоящей работе будет рассматриваться довольно ограниченный набор данных, которые тем не менее было весьма непросто подготовить. Наборы данных, подготовленные для этой работы и актуальные на январь 2019 г., приведены в таблице 1. Указанные наборы ограничивают область исследований продуктовыми магазинами Москвы.
Таблица 1
Описание наборов данных, ед.
|
Набор данных |
Количество записей |
|
Магазины Москвы |
10 107 |
|
Остановки наземного транспорта Москвы |
11 414 |
|
Вестибюли метро Москвы |
221 |
|
Объявления о сдаче жилой площади Москвы |
1683 |
|
Бизнес-центры Москвы |
1314 |
|
Торговые центры Москвы |
669 |
Признаковое пространство
В таблице 2 указаны полезные признаки точек продаж, извлеченные из имеющихся данных (в скобках приведены переменные, которыми обозначаются параметры далее в формулах).
Таблица 2
Описание признаков
|
Признак модели |
Связанные экспертные параметры оценки |
|
Конкуренция в радиусе 500 м p 0 |
Конкуренция x 9 |
|
Конкуренция в радиусе 1000 м p 1 |
Конкуренция x 9 |
|
Доступность для личного транспорта x 4 |
|
|
Конкуренция в радиусе 1500 м p 2 |
Конкуренция x 9 |
|
Доступность для личного транспорта x 4 |
68 в ыпуск 4/2019
Окончание табл. 2
|
Признак модели |
Связанные экспертные параметры оценки |
|
Количество станций метро в радиусе 500 м p 3 |
Пешеходный трафик x 12 |
|
Автомобильный трафик x 11 |
|
|
Престижность района x 0 |
|
|
Арендная плата x 1 |
|
|
Стоимость строительства x 2 |
|
|
Доступность для личного транспорта x 4 |
|
|
Количество маршрутов, проходящих через остановки в радиусе 300 м p 4 |
Численность населения в окрестности x 3 |
|
Пешеходный трафик x 12 |
|
|
Средняя стоимость аренды одного квадратного метра жилья в радиусе 500 м p 5 |
Престижность района x 0 |
|
Арендная плата x 1 |
|
|
Стоимость строительства x 2 |
|
|
Потребительский потенциал x 7 |
|
|
Количество офисов в радиусе 500 м p 6 |
Престижность района x 0 |
|
Арендная плата x 1 |
|
|
Стоимость строительства x 2 |
|
|
Потребительский потенциал x 7 |
|
|
Конкуренция x 9 |
|
|
Размер офисов в окрестности x 10 |
|
|
Пешеходный трафик x 12 |
|
|
Автомобильный трафик x 11 |
|
|
Доступность для личного транспорта x 4 |
|
|
Количество торговых центров в радиусе 300 м p 7 |
Арендная плата x 1 |
|
Стоимость строительства x 2 |
|
|
Потребительский потенциал x 7 |
|
|
Конкуренция x 9 |
|
|
Пешеходный трафик x 12 |
|
|
Доступность для личного транспорта x 4 |
|
|
Суммарная площадь предприятий x 8 |
|
|
Близость к крупным торговым точкам другого типа x 5 |
|
|
Видимость торговой точки x 6 |
Как видно, признаковое пространство, включающее 8 признаков, косвенно охватывает все абстрактные параметры экспертизы точек продаж из привлеченных маркетинговых исследований. Связь между ними установлена на основе фактов, приведенных в рассмотренных исследованиях, и не является окончательной, тем не менее она вполне достаточна для формирования целевого признака.
Выбор радиусов оценки был произведен согласно следующей эвристике:
-
• 300 м – радиус пешей доступности;
-
• 500 м – радиус пешей доступности при наличии точек интереса;
-
• 1000 м – радиус пешей доступности при наличии общественного транспорта и доступности для личного транспорта;
-
• 1500 м – радиус доступности для автомобиля.
Булычев Д.М. Прогнозирование результатов экспертного оценивания точек... 69
Целевой признак
Прежде чем перейти к описанию целевого признака, необходимо преобразовать признаковое описание точек в параметры экспертного оценивания. Для этого, помимо установленной ранее связи между упомянутыми признаками и параметрами, нужно оценить их значимость. Весовые коэффициенты, соответствующие установленным связям, подобраны эвристически с учетом рассмотренных исследований:
x 0 = p 3 +
1,1 p 5
750 ;
2 p
X 1 = 1,5 p 3 + 750 + 1,4 p 6 + 2,1 p 7 ;
x 2 = 0,8 x 1 ;
-
x 3 = p 4 ;
-
x 4 = 2 p 3 + 1,5 p 4 ;
-
x 5 = p 7 ;
x 6 = p 7 ;
x
1,5 p 5 750
+ 3 p 6 ;
-
x 8 = p 7 ;
x 9
0,4 p
= 2 p 0 + p + 0,5 p 2 -^ 1 + 0,8 p 4 + + 2 p 7 + 1,1 p 6 J ;
-
x 1 0 = p 6 ;
0,7 p
-
x 11 = ^50 - + 0,5 p 6 + 0,6 p 7 ;
x 12 = p 7 .
Все признаки, кроме p5 (cредняя стоимость аренды одного квадратного метра жилья в радиусе 500 м), количественные, поэтому каждый коэффициент напрямую отображает значимость признака для параметра. Чтобы достичь такого же эффекта для признака p5, нужно разделить его на близкое к среднему значение этого признака. Следовательно, мож- но рассматривать p5 как степень отклонения среднего выборки стоимостей арендной платы квартир от среднего генеральной совокупности всех стоимостей. Таким образом, оценки экспертных параметров получаются как взвешенная сумма признаков модели.
В качестве целевого признака используется гипотетическая эвристическая оценка экс- перта, которая складывается на основе оценки экспертных параметров:
У = 10 ( 2 x 0 — 1,5 x 1
- 1,2 x 2 + 1,3 x 3 + 0,75 x 4 + 0,55 x 5 + 1,1 x 6 +
+ 2,5 x 7 - 1,4 x 8 - 2,5 x 9 + 1,4 x 10 + 1,2 x n + 1,4 x 12 ) . (2)
Гипотетическая экспертная оценка моделируется так же, как и отдельные оценки параметров, как взвешенная сумма, где веса подбираются эвристически. Оценка получается
70 в ыпуск 4/2019
в диапазоне от 0 до 100 и для удобства восприятия делится на 10. Таким образом, нейронная сеть будет оценивать каждую точку по 10-балльной ранговой шкале.
Результирующая оценка охватывает все значения введенной шкалы. Для того чтобы оценка в большей степени соответствовала реальной ситуации, к вычисленной оценке добавляется гаусовский шум без смещения с σ = 0,6. Получившееся распределение оценок (рис. 1) похоже на распределение логорифмически нормальной случайной величины, что является совершенно естественным в рамках рассматриваемой задачи и косвенно указывает (но не доказывает) на адекватность выведенной оценки [1].
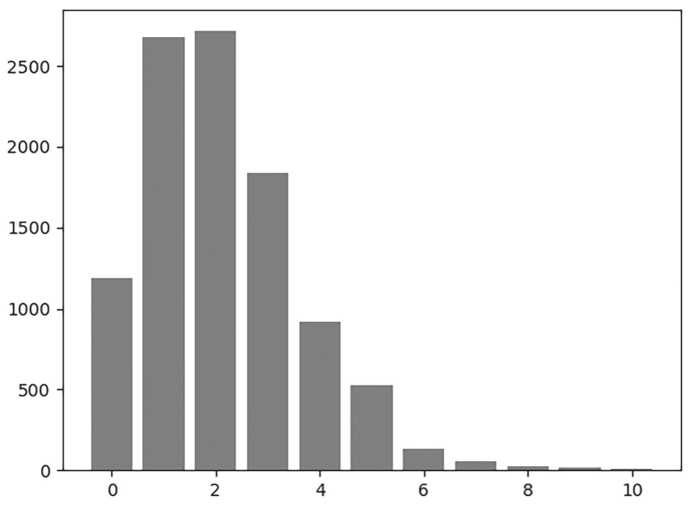
Рис. 1. Распределение значений оценки по шкале
Извлечение признаков
Вследствие большого объема данных, которые необходимо обработать для извлечения признаков, с учетом их разнородности задача обработки данных переходит в область Big Data. Помимо этого, все данные относятся к категории геоданных. Обработка геоданных – нетривиальная задача, требующая дополнительных вычислений в условиях отсутствия стандартных методов. Все это накладывает существенное ограничение на использование классических подходов, поэтому возникла необходимость создания собственного алгоритма обработки данных.
Для разработки был выбран язык Python, так как он обладает большим количеством библиотек как для машинного обучения, так и для обработки данных. Одной из таких библиотек является Dask. С ее помощью можно параллельно обрабатывать большие объемы данных, однако в рамках этой задачи, как показал опыт, использование стандартных средств Dask без существенной доработки оказывается неэффективным (см. табл. 3). Проблемы, возникающие при использовании класических подходов, указаны в таблице 3.
Для решения обозначенных проблем разработан адаптивный алгоритм на Dask (рис. 2). Алгоритм организует пакетную обработку данных Dask следующим образом: определяет количество доступной оперативной памяти, вычисляет размер пакета так, чтобы задействовать оптимальное количество оперативной памяти, и обрабатывает весь набор данных пакетами.
Булычев Д.М. Прогнозирование результатов экспертного оценивания точек...
Таблица 3
Проблемы класических алгоритмов
|
Алгоритм |
Время работы, ч |
Проблема алгоритма |
|
Сопоставление записей в цикле и обработка |
13 |
Неприемлемо долго работает |
|
Распараллеленное по процессам сопоставление записей в цикле и обработка |
6 |
Все еще слишком долго работает |
|
Параллельное сопоставление записей декартовым произведением, построчная обработка и группировка средствами Dask |
12 |
Из-за декартова произведения требуется большой объем оперативной памяти (55 Гб) для обработки данных, что делает алгоритм слишком требовательным к аппаратному обеспечению |
За счет оптимизации использования оперативной памяти удалось ускорить обработку данных до 400 с. Помимо этого, алгоритм стал менее требователен к аппаратному обеспечению и может работать как на 32-разрядных, так и на 64-разрядных системах.
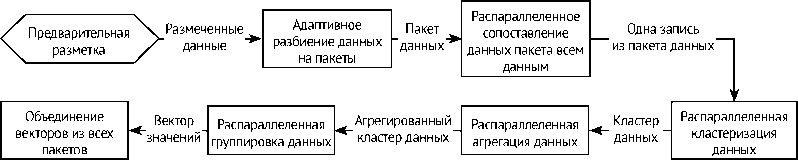
Рис. 2. Схема адаптивного алгоритма
Геоданные в наборах представлены широтой, долготой и адресом. Однако признаки привязаны к метрической системе, поэтому необходима конвертация. Переход от долготы и широты к метрам происходит в процессе вычисления расстояния между объектами по следующей формуле [8]:
8 1 = l i - 1 2 ,
J ( sin ф 1 cos ф 2 ) 2 + ( cos ф 1 sin ф 2 cos 8 1 ) 2
8o = arctan----------------------------------, (3)
sin ф 1 sin ф 2 + cos ф 1 cos ф 2 cos 8 1
r = R 8o, где l1 и l2 – долгота первой и второй точек соответственно; φ1 и φ 2– широта первой и второй точек соответственно; R – радиус Земли.
Данная формула позволяет получить точный результат даже на малых расстояниях. Если использовать внешние сервисы или дополнительные наборы данных, можно извлечь больше полезных признаков из геоданных. Однако в настоящей работе геоданные используются только для измерения расстояний.
Базовая модель нейронной сети
Предсказание оценки – задача регрессии, так как необходимо восстановить функцию получения оценки по входным данным.
Прежде всего следует определиться со структурой слоев нейронной сети.
72 в ыпуск 4/2019
Для различных задач и входных данных используются различные структуры слоев. Для решения задачи регрессии используется полносвязный персептрон. В качестве функции потерь – среднеквадратичная ошибка. Функция RMSprop выбрана как оптимизатор, так как она задает адаптивную скорость обучения и при этом устойчива к затуханию. На выходном слое активационная функция отсутствует, поскольку особых преобразований не требуется. На скрытых слоях используется активационная функция – гиперболический тангенс (tanh). Это обусловлено следующими причинами:
-
• функция симметрична, что обеспечивает быструю сходимость;
-
• функция имеет непрерывную первую производную;
-
• функция имеет простую производную, которая может быть вычислена через ее значение, что упрощает вычисления.
После извлечения признаков из данных формируется матрица признаков, где векторы-строки – это экземпляры записей о конкретных точках со всеми признаками. Перед тем как передавать матрицу в нейронную сеть, ее необходимо подготовить, а именно: признаки нужно нормализовать и центрировать. Для этого из каждого значения признака вычитается среднее всех его значений, а затем делится на стандартное отклонение. После такой обработки матрицу можно подавать на вход нейронной сети. За основу базовой модели было взято 4 скрытых слоя по 16 нейронов в каждом (рис. 3).
Рис. 3. Базовая модель нейронной сети
Чтобы использовать большее количество данных, тестирование модели проводится при помощи кросс-валидации по 4 блокам. Чтобы заведомо обнаружить момент переобучения, первый прогон будет длительностью 2000 эпох.
На рисунке 4 видно, что переобучение наступает примерно на 200-й эпохе. Для уточнения момента начала переобучения второй прогон был проведен на 250 эпохах (рис. 5). Как оказалось, переобучение наступает уже в окрестности 100-й эпохи.
После этого базовая сеть была обучена в 100 эпох и выдала прогноз со средней абсолютной ошибкой 0,459, что является приемлемым результатом. Тем не менее его можно улучшить посредством вариации количества нейронов и слоев (табл. 4).
0,53
0,52
0,51
s 0,50
0,49
0,48
0,47
0,46
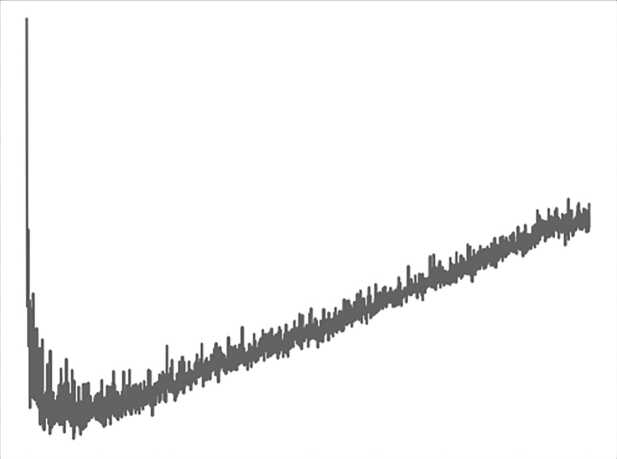
О 250 500 750 1000 1250 1500 1750 2000
Epochs
Рис. 4. Прогон базовой нейронной сети на 2000 эпохах
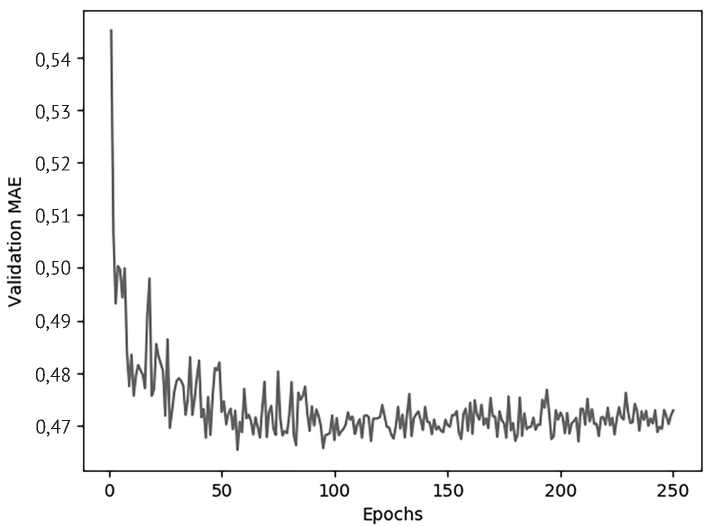
Рис. 5. Прогон базовой нейронной сети на 250 эпохах
Таблица 4
|
Слои |
Количество эпох |
Абсолютная средняя ошибка |
|
16-16-16-16 |
100 |
0,459 |
|
32-32-32-32 |
70 |
0,466 |
|
32-32-32-23 |
80 |
0,448 |
|
32-32-23-23 |
80 |
0,463 |
|
16-16-16-8 |
100 |
0,474 |
|
16-16-16-16 |
50 |
0,474 |
|
8-8-8-8-8 |
80 |
0,475 |
Вариация нейронов
По данным таблицы 4 видно, что точность модели варьируется несущественно, а оптимальной является конфигурация 32-32-32-23 с абсолютной средней ошибкой 0,448.
74 в ыпуск 4/2019
Заключение
В результате проведенного исследования была разработана нейронная сеть, решающая поставленную цель – прогнозирование экспертной оценки. Для практического применения построенной модели необходимо обучить ее на реальных экспертных оценках. В зависимости от того, как строится эта оценка, может потребоваться модификация модели, так как ее структура зависит от данных, используемых при обучении. В частности, в рассмотренном случае линейная модель машинного обучения могла бы дать более точные прогнозы и обучалась бы быстрее, поскольку предложенная гипотетическая оценка изначально построена как линейная модель. Однако такой подход сделал бы модель гораздо менее гибкой: при появлении новых данных ее необходимо было бы обучать заново, а изменение структуры данных приведет к необходимости изменения модели, да и подготовка этих данных потребует гораздо больших усилий.
В перспективе для улучшения работы нейронной сети можно расширить признаковое пространство посредством добавления источников данных или извлечения большего количества признаков из имеющихся.
Автор благодарит профессора И.С. Клименко за полезное обсуждение.
Список литературы Прогнозирование результатов экспертного оценивания точек продаж с помощью нейронной сети
- Айвазян С.А., Енюков И.С., Мешалкин Л.Д. Прикладная статистика: Основы моделирования и первичная обработка данных. М.: Финансы и статистика, 1983. 487 с.
- Андрианов В., Леонов А., Бредюк К. Геомаркетинг: на стыке маркетинга и географии // Маркетинг Менеджмент. 2010. № 7-8.
- Угаров А.С. Методы выбора местоположения торговой точки // Маркетинг в России и за рубежом. 2005. № 6.
- Applebaum W. Can Store Location Be a Science? // Economic Geography. 1965. № 41. P. 234-237.
- Chollet F. Deep Learning with Python. N. Y.: Manning Publications, 2018.
- Kane B.J. A Systematic Guide to Supermarket Location Analysis. N. Y.: Fanchild Publications, 1966.
- Nelson R. The Selection of Retail Locations. N. Y.: F.W. Dodge Corp., 1958.
- Vincenty T. Direct and Inverse Solutions of Geodesics on the Ellipsoid with Application of Nested Equations // Survey Review. 1975. № 23. P. 88-93.
