Прогнозирование сроков доставки товаров в цепях поставок с использованием методов машинного обучения

Автор: Резванов В.К., Ромакина О.М., Зайцева Е.В.
Журнал: Advanced Engineering Research (Rostov-on-Don) @vestnik-donstu
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 2 т.25, 2025 года.
Бесплатный доступ
Введение. Развитие торговли требует внедрения технологий искусственного интеллекта и машинного обучения для повышения точности прогнозов доставки. Опубликованные на сегодня научные изыскания в этой области представляются недостаточными по двум причинам. Первая: рассматриваются главным образом глобальные цепи поставок, хотя вопрос актуален и для локальных бизнесов. Вторая: прогнозирование, как правило, требует больших объемов данных для машинного обучения и значительных вычислительных ресурсов, недоступных основной массе компаний. Представленное исследование призвано восполнить эти пробелы и показать эффективность использования открытых, доступных данных и известных алгоритмов. Цель работы — описать схему обоснованного выбора наименее ресурсоемкой модели прогнозирования доставки на основе анализа алгоритмов машинного обучения. Материалы и методы. Использовался набор открытых данных DataCo Smart supply chain for big data analysis о поставках в онлайн-торговле. Для обработки и анализа информации задействовали методы очистки данных, устранения мультиколлинеарности, нормализации и кодирования категориальных признаков. С очищенными данными работали алгоритмы: Decision tree, Random forest, K-nearest neighbors, Naive Bayes, Linear discriminant analysis, XGBoost, CatBoost, LightGBM, AdaBoost и Perceptron. Результаты исследования. Базовым алгоритмом для модели прогнозирования доставки стал алгоритм дерева решений (Decision Tree). Этот выбор обусловлен высокой точностью, простотой использования и низким риском переобучения. Оценка модели показала высокий и близкий к единице коэффициент детерминации (0,986). При этом фиксируются низкие значения среднеквадратичной ошибки (0,0367) и средней абсолютной ошибки (0,0324). Модель показала удовлетворительные результаты по времени, затраченному на обучение (3,3087 с) и на прогнозирование (0,0051 с). Фактические и предсказанные значения почти идеально совпали. Отклонения от фактических значений оказались минимальными. Обсуждение и заключение. Предложенная модель эффективна и обладает высокой предсказательной способностью. Качественное прогнозирование сроков доставки товара возможно без привлечения обширных баз данных и мощных вычислительных ресурсов. Исследование открывает перспективу качественной организации логистических операций для средних и малых предприятий. В дальнейших изысканиях целесообразно интегрировать в модель данные о погоде, дорожной ситуации и другие показатели. Использование такой информации в режиме реального времени повысит адаптивность и точность прогнозирования.
Модель прогнозирования сроков доставки, прогноз доставки для малых и средних предприятий, ошибка в прогнозировании доставки, дерево решений для логистических задач
Короткий адрес: https://sciup.org/142244845
IDR: 142244845 | УДК: 004.8 | DOI: 10.23947/2687-1653-2025-25-2-120-128
Forecasting Delivery Time of Goods in Supply Chains Using Machine Learning Methods
Introduction. Trade development requires the implementation of artificial intelligence and machine learning technologies to improve the accuracy of delivery forecasts. The scientific research published to date in this area appears insufficient for two reasons. First, it focuses primarily on global supply chains, although the issue is relevant for local businesses as well. Second, forecasting typically requires large amounts of data for machine learning and significant computing resources that are not available to the majority of companies. The presented study aims to fill these gaps and demonstrate the efficiency of using open, accessible data and known algorithms. The research objective is to describe a pattern of appropriate selection of the least resource-intensive delivery forecasting model based on the analysis of machine learning algorithms. Materials and Methods. The open data set DataCo Smart supply chain for big data analysis on deliveries in online trade was used. To process and analyze the information, methods of data cleaning, eliminating multicollinearity, normalization and coding of categorical features were applied. The following algorithms were used with the cleaned data: Decision tree, Random Forest, k-nearest neighbors, Naïve Bayes, Linear discriminant analysis, XGBoost, CatBoost, LightGBM, AdaBoost, and Perceptron. Results. The basic algorithm for the delivery forecasting model was the Decision Tree algorithm. This choice was due to its high accuracy, ease of use, and low risk of overfitting. The model evaluation showed a high determination coefficient close to one (0.986). Low values of the mean square error (0.0367) and mean absolute error (0.0324) were recorded. The model showed satisfactory results in terms of time spent on training (3.3087 s) and forecasting (0.0051 s). Actual and predicted values almost perfectly matched. Deviations from actual values were minimal. Discussion and Conclusion. The proposed model is efficient and has a high predictive ability. High-quality forecasting of delivery time is possible without the use of extensive databases and powerful computing resources. The study opens up the prospect of high-quality organization of logistics operations for small and medium enterprises. In further research, it is advisable to integrate weather data, traffic conditions and other indicators into the model. Using such information in real time will increase the adaptability and accuracy of forecasting.
Текст научной статьи Прогнозирование сроков доставки товаров в цепях поставок с использованием методов машинного обучения
УДК 004.8 Оригинальное эмпирическое исследование
Введение. Развитие торговли требует внедрения технологий искусственного интеллекта и машинного обучения для повышения точности прогнозов доставки. Опубликованные на сегодня научные изыскания в этой области представляются недостаточными по двум причинам. Первая: рассматриваются главным образом глобальные цепи поставок, хотя вопрос актуален и для локальных бизнесов. Вторая: прогнозирование, как правило, требует больших объемов данных для машинного обучения и значительных вычислительных ресурсов, недоступных основной массе компаний. Представленное исследование призвано восполнить эти пробелы и показать эффективность использования открытых, доступных данных и известных алгоритмов. Цель работы — описать схему обоснованного выбора наименее ресурсоемкой модели прогнозирования доставки на основе анализа алгоритмов машинного обучения.
Материалы и методы. Использовался набор открытых данных DataCo Smart supply chain for big data analysis 1 о поставках в онлайн-торговле. Для обработки и анализа информации задействовали методы очистки данных, устранения мультиколлинеарности, нормализации и кодирования категориальных признаков. С очищенными данными работали алгоритмы: Decision tree, Random forest, K-nearest neighbors, Naive Bayes, Linear discriminant analysis, XGBoost, CatBoost, LightGBM, AdaBoost и Perceptron 2 .
Результаты исследования. Базовым алгоритмом для модели прогнозирования доставки стал алгоритм дерева решений (Decision Tree). Этот выбор обусловлен высокой точностью, простотой использования и низким риском переобучения. Оценка модели показала высокий и близкий к единице коэффициент детерминации (0,986). При этом фиксируются низкие значения среднеквадратичной ошибки (0,0367) и средней абсолютной ошибки (0,0324). Модель показала удовлетворительные результаты по времени, затраченному на обучение (3,3087 с) и на прогнозирование (0,0051 с). Фактические и предсказанные значения почти идеально совпали. Отклонения от фактических значений оказались минимальными.
Обсуждение и заключение. Предложенная модель эффективна и обладает высокой предсказательной способностью. Качественное прогнозирование сроков доставки товара возможно без привлечения обширных баз данных и мощных вычислительных ресурсов. Исследование открывает перспективу качественной организации логистических операций для средних и малых предприятий. В дальнейших изысканиях целесообразно интегрировать в модель данные о погоде, дорожной ситуации и другие показатели. Использование такой информации в режиме реального времени повысит адаптивность и точность прогнозирования.
Original Empirical Research
Forecasting Delivery Time of Goods in Supply Chains Using Machine Learning Methods
Vladislav K. Rezvanov1 , Oksana M. Romakina 1 О , Ekaterina V. Zaytseva2
-
1 National Research University ITMO, Saint Petersburg, Russian Federation
-
2 Empress Catherine II Saint Petersburg Mining University, Saint Petersburg, Russian Federation
Introduction . Trade development requires the implementation of artificial intelligence and machine learning technologies to improve the accuracy of delivery forecasts. The scientific research published to date in this area appears insufficient for two reasons. First, it focuses primarily on global supply chains, although the issue is relevant for local businesses as well. Second, forecasting typically requires large amounts of data for machine learning and significant computing resources that are not available to the majority of companies. The presented study aims to fill these gaps and demonstrate the efficiency of using open, accessible data and known algorithms. The research objective is to describe a pattern of appropriate selection of the least resource-intensive delivery forecasting model based on the analysis of machine learning algorithms.
Materials and Methods. The open data set DataCo Smart supply chain for big data analysis on deliveries in online trade was used. To process and analyze the information, methods of data cleaning, eliminating multicollinearity, normalization and coding of categorical features were applied. The following algorithms were used with the cleaned data: Decision tree, Random Forest, k-nearest neighbors, Naïve Bayes, Linear discriminant analysis, XGBoost, CatBoost, LightGBM, AdaBoost, and Perceptron.
Results . The basic algorithm for the delivery forecasting model was the Decision Tree algorithm. This choice was due to its high accuracy, ease of use, and low risk of overfitting. The model evaluation showed a high determination coefficient close to one (0.986). Low values of the mean square error (0.0367) and mean absolute error (0.0324) were recorded. The model showed satisfactory results in terms of time spent on training (3.3087 s) and forecasting (0.0051 s). Actual and predicted values almost perfectly matched. Deviations from actual values were minimal.
Discussion and Conclusion. The proposed model is efficient and has a high predictive ability. High-quality forecasting of delivery time is possible without the use of extensive databases and powerful computing resources. The study opens up the prospect of high-quality organization of logistics operations for small and medium enterprises. In further research, it is advisable to integrate weather data, traffic conditions and other indicators into the model. Using such information in real time will increase the adaptability and accuracy of forecasting.
Информатика, вычислительная техника и управление
Введение. В условиях развития торговли повышается актуальность точного прогнозирования сроков доставки. Недостаточная эффективность традиционных методов планирования обусловлена неопределенностью, связанной с влиянием различных факторов. Очевидно, что применение в логистике искусственного интеллекта (ИИ) может значительно улучшить точность прогнозов и сократить операционные затраты. По данным международной консалтинговой организации McKinsey & Company, предприятия, использующие ИИ для управления цепочками поставок, могут сократить ошибки прогнозов на 20–50 %, что в конечном итоге снижает издержки на 10–15 % 3 .
Опубликованные научные работы, посвященные этой теме, рассматривают главным образом масштабные, глобальные цепи поставок [1] . Активно обсуждаются различные подходы к прогнозированию сроков доставки, однако исследования концентрируются, как правило, на сложных и ресурсоемких моделях, недоступных основной части предприятий — малых и средних. При этом проблема, безусловно, актуальна и для локальных, небольших бизнесов, остро нуждающихся в сбережении ресурсов. Этому способствуют в целом лучшие настройки логистических процессов и, в частности, точное прогнозирование сроков доставки. У компаний с ограниченными информационными и вычислительными возможностями мало инструментов для улучшения ситуации. Представленное исследование призвано восполнить этот пробел. Цель работы — определение наиболее эффективной и наименее ресурсоемкой модели машинного обучения для прогнозирования сроков доставки.
Материалы и методы. В исследовании использовался набор структурированных данных о продажах, доставках, клиентах и финансовых показателях. Открытый набор данных DataCoSupplyChainDataset размещен компанией DataCo Global в бесплатном коллективном облачном репозитории Mendeley Data. Основные сведения этого набора: даты заказа и доставки, информация о клиентах, финансовые показатели заказов и статус доставки.
До анализа и моделирования данные прошли предварительную обработку — очистку и преобразование. Для достижения поставленной цели в первую очередь выявили корреляции и устранили мультиколлинеарность на основе матрицы корреляции (рис. 1).
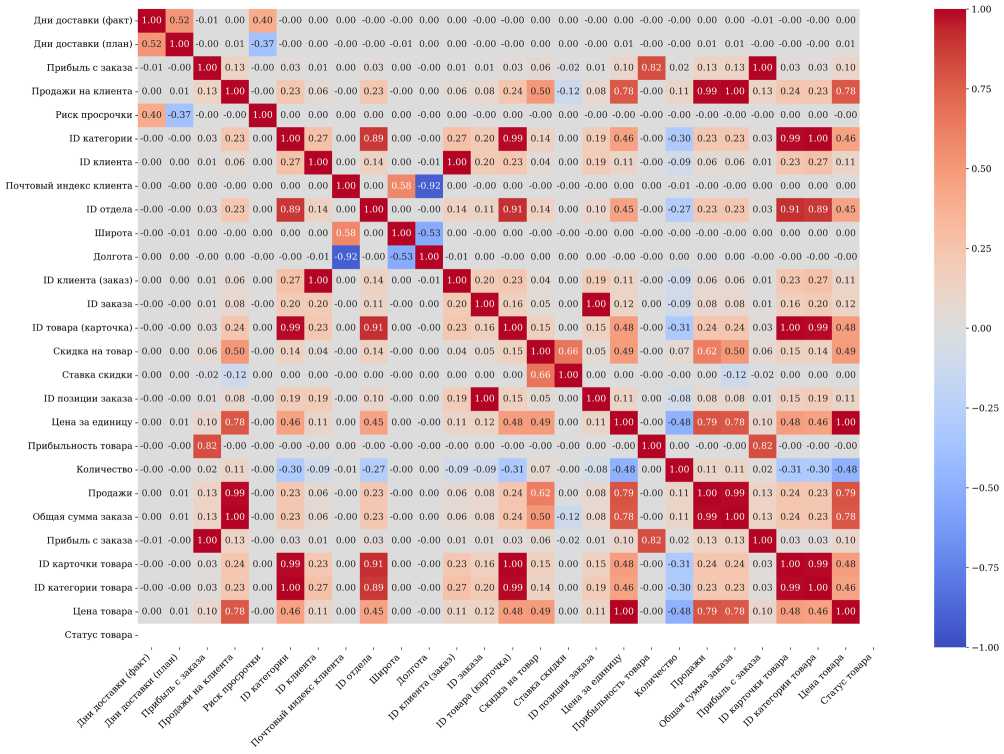
Рис. 1. Матрица корреляции
Матрица позволила выявить несколько пар признаков с коэффициентом корреляции, равным 1. Это указывает на их полное дублирование. Ниже представлены эти пары признаков.
-
1. Customer_id (идентификатор клиента) и order_customer_id (идентификатор клиента для заказа).
-
2. Sales_per_customer (продажи на клиента) и order_item_total (сумма за заказанный товар).
-
3. Benefit_per_order (прибыль с заказа) и order_profit_per_order (прибыль на заказ).
-
4. Order_item_cardprod_id (идентификатор карточки товара в заказе) и product_card_id (идентификатор карточки товара).
-
5. Category_id (идентификатор категории) и product_category_id (идентификатор категории продукта).
-
6. Order_item_product_price (цена товара в заказе) и product_price (цена продукта).
Для устранения дублирования удалены следующие признаки:
-
- benefit_per_order (прибыль с заказа);
-
- sales_per_customer (продажи на клиента);
-
- order_item_cardprod_id (идентификатор карточки товара в заказе);
-
- order_item_product_price (цена товара в заказе);
-
- product_category_id (идентификатор категории продукта);
-
- order_customer_id (идентификатор клиента для заказа).
Также было обнаружено, что признак product_status (доступность товара) имеет только одно уникальное значение (0), то есть товар всегда доступен. Этот признак также удалили.
Для анализа мультиколлинеарности между числовыми признаками использовали коэффициент инфляции дисперсии (англ. variance inflation factor, VIF) [2] . Признаки с VIF выше 5 указывают на сильную взаимосвязь с другими признаками, что может исказить результаты анализа и моделей. Во избежание этой проблемы такие признаки удаляются или объединяются. Таким образом сокращается избыточность данных и повышается стабильность модели.
После предварительной обработки выбрали основные числовые и категориальные признаки для дальнейшего анализа и построения модели.
Числовые признаки включают такие показатели, как продажи, прибыль, скидки и количество товаров в заказе. Категориальные признаки включают статус доставки, сегмент клиентов и режим доставки.
По признакам с VIF выше 5 провели дальнейший анализ для выявления избыточных взаимосвязей. Если признак мог быть выражен через другие, его заменяли комбинацией более простых признаков. Примеры представлены ниже.
-
1. Sales = product_price * order_item_quantity. Поскольку выручка с продажи (sales) напрямую зависит от цены продукта (product_price) и количества товара (order_item_quantity), решено использовать это выражение для замены избыточных признаков.
-
2. Order_item_discount = sales * order_item_discount_rate. Скидка на товар (order_item_discount) напрямую зависит от объема выручки с продажи и ставки скидки (order_item_discount_rate), что делает этот признак также избыточным.
-
3. Order_item_total = sales – order_item_discoun. Здесь общая сумма заказа (order_item_total) выражена через выручку с продажи и скидку на товар, что позволило уменьшить дублирование данных.
-
4. Order_profit_per_order = order_item_total * order_item_profit_ratio. Прибыль на заказ (order_profit_per_order) связана с общей стоимостью товара и коэффициентом прибыли на товар (order_item_profit_ratio), что делает возможным ее вычисление через другие признаки.
Отсутствующие значения в столбце order_zipcode (почтовый индекс заказа) заменили на customer_zipcode (почтовый индекс клиента).
Данные в столбце days_for_shipping_real (дней для доставки, фактически) привели к нормальной форме вещественного числа с плавающей запятой.
Информатика, вычислительная техника и управление
В исходном наборе данных признаки «статус доставки», «сегмент клиентов» и «режим доставки» были категориальными, что существенно затрудняло использование числовых моделей машинного обучения. С помощью метода Label Encoder 4 эти признаки были преобразованы в числовой формат:
-
- категориям «отправлено», «в пути» и «доставлено» признака delivery_status были сопоставлены значения 0, 1 и 2 соответственно;
-
- категориям признака customer_segment также были сопоставлены уникальные числовые значения.
Описанный подход позволяет сохранить различия между категориями и при этом использовать категории в процессе машинного обучения.
При выборе оптимальной модели машинного обучения для прогнозирования сроков доставки реализовали ряд алгоритмов машинного обучения. Decision tree [3] — один из наиболее распространенных алгоритмов машинного обучения, применяющийся для задач, связанных с принятием решений на основе набора признаков. По значениям некоторых признаков алгоритм разбивает данные на меньшие подгруппы и затем структурирует в виде дерева решений.
Алгоритм работает следующим образом.
-
1. Перед первым шагом в корневом узле дерева решений содержится исходный набор данных.
-
2. На каждом шаге алгоритма выбирается признак, позволяющий наиболее эффективно разделить данные на подмножества и одно или несколько его пороговых значений. Данные разделяются на группы в соответствии с выбранными значениями признака. Процесс повторяется до тех пор, пока не будут достигнуты листовые узлы, содержащие итоговые решения и не подлежащие дальнейшей декомпозиции.
Таким образом, каждый узел дерева — это точка принятия решения, в которой происходит разделение данных на основе значения некоторого признака. Ветви дерева соответствуют возможным результатам такого разделения.
Ключевой момент работы алгоритма — определение признака разбиения данных на каждом шаге.
Предварительные эксперименты показали, что критерий Джини обеспечивает наилучшую точность разбиения данных в рамках поставленной задачи, поэтому именно он использовался в представленной работе.
Для определения оптимального алгоритма на подготовленном наборе данных протестировали Random Forest [4] , K-Nearest Neighbors [5] , Naive Bayes [6] , Linear Discriminant Analysis [7] , XGBoost [8] , CatBoost [9] , LightGBM [10] , AdaBoost [11] и Perceptron [12] . Эти алгоритмы выбрали благодаря их распространенности и подтвержденной эффективности для решения задач прогнозирования. Каждую модель тестировали на одном и том же наборе данных после одинаковой процедуры предварительной обработки. Для оценки эффективности моделей использовались метрики R 2 (коэффициент детерминации), средняя квадратичная ошибка (англ. mean square error, MSE), средняя абсолютная ошибка (англ. mean absolute error, MAE), а также время, затраченное на обучение и прогнозирование. Перечисленные метрики позволяют объективно сравнить точность и ресурсоемкость алгоритмов и выбрать оптимальную модель для прогнозирования сроков доставки.
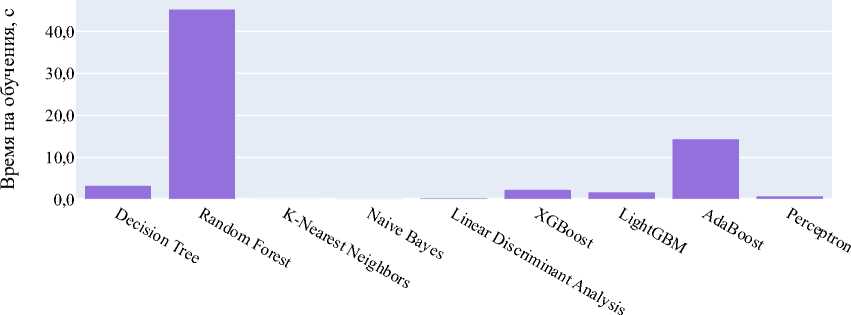
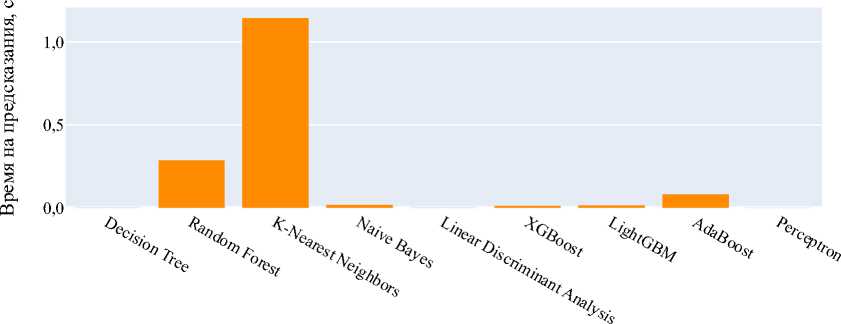
Результаты исследования. На рис. 2 показана оценка качества описанных выше моделей с помощью перечисленных метрик. Decision Tree и Random Forest продемонстрировали наиболее высокую точность. Однако следует учитывать простоту и интерпретируемость Decision Tree, а также его меньшую склонность к переобучению [13] по сравнению с более сложными моделями. В связи с этим для прогнозирования сроков доставки товаров использовался алгоритм Decision Tree.
1,0
0,5
0,0
lllllllll
st
X X
Чу
а )
sj W 40 К a о
w
К т
Oh 4 S3 ca w о §
1,0
0,5
0,0
III..II
X X *
XX v
^
б )
sj W ю S
0,6
к
0,4
§
0,2
0,0
Ill»ll
А
ч
°ъ
в )
г )
д )
Рис. 2. Оценка качества моделей: а — оценка качества моделей с помощью метрики R ²;
б — оценка качества моделей с помощью метрики MSE; в — оценка качества моделей с помощью метрики MAE; г — время, затраченное моделями на обучение, с; д — время, затраченное моделями на предсказание, с
Итак, тестирование модели Decision tree дало следующие результаты:
-
- коэффициент детерминации — 0,986;
-
- среднеквадратичная ошибка (MSE) — 0,0367;
-
- средняя абсолютная ошибка (MAE) — 0,0324;
-
- время на обучение — 3,3087 с;
-
- время на предсказание — 0,0051 с.
Информатика, вычислительная техника и управление
Высокое значение R ² и низкие значения MSE и MAE указывают на высокую точность и эффективность модели.
Рассмотрим соответствие фактических значений и значений, предсказанных моделью (рис. 3).
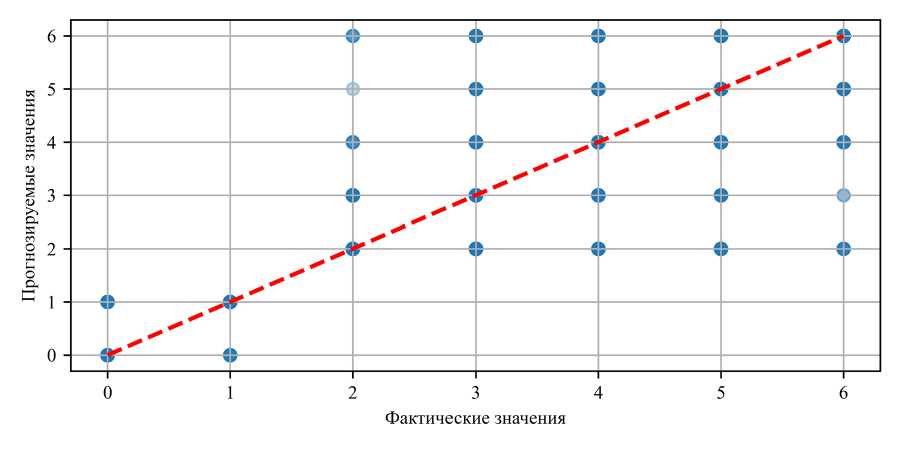
Рис. 3. График фактических и предсказанных значений
Как видим, синие точки (предсказанные значения) расположены близко к красной штриховой линии, которая представляет собой линию идеального совпадения между фактическими и предсказанными значениями. Это указывает на высокую точность предсказания значений.
Плотное расположение точек вдоль штриховой линии говорит об отсутствии значительных смещений в сторону завышения или занижения показателей. Это указывает на баланс между предсказанными и фактическими значениями.
Группировка точек вдоль диагонали показывает, что отклонения от фактических значений минимальны. Таким образом, можно обоснованно говорить о крайне незначительных ошибках и высокой предсказательной способности модели.
Обсуждение и заключение. Результаты экспериментов показали, что модель на основе дерева решений способна с высокой точностью предсказывать сроки доставки товаров. Это подтверждается высокими значениями R ² и низкими значениями MSE и MAE. Установлено также, что модель достаточно быстро обучается и выполняет прогноз, то есть хорошо подходит для использования в реальных условиях. В этом смысле особенно ценно то, что операции реализуются при минимальных затратах вычислительных ресурсов.
Отметим основные условия достижения хороших результатов:
-
- качественная предварительная обработка данных;
-
- устранение мультиколлинеарности;
-
- применение оптимального критерия разбиения данных.
Научную значимость представленной работы следует рассматривать как с теоретической, так и с прикладной точки зрения. В первом случае речь идет о возможности успешного применения простых и эффективных моделей машинного обучения в логистике. Показано, что эти модели могут обеспечить необходимую точность прогнозов, существенно снизить операционные расходы и оптимизировать ресурсы предприятий. Авторы представленной статьи выбирали из девяти алгоритмов, каждый из которых может оказаться оптимальным для решения той или иной логистической (или, шире, — экономической) проблемы предприятия. Перечислим лишь некоторые логистические задачи, которые можно попытаться решить с помощью подхода, описанного в данной статье:
-
- выбор схемы доставки с учетом требований к свежести товара;
-
- выбор схемы доставки с учетом затрат на горюче-смазочные материалы;
-
- оптимизация закупок с учетом расходов по складированию;
-
- формирование зарплатной политики в логистическом подразделении;
-
- прогнозирование ликвидности товаров.
Это подводит ко второму — прикладному — потенциалу описанных в статье научных изысканий. Ожидаемый итоговый практический эффект — лучшая управляемость и рентабельность логистики. Это особенно важно для малого и среднего бизнеса. Крупные корпорации для выстраивания эффективной логистики содержат собственные штаты аналитиков и программистов, формируют собственные базы данных или закупают эксклюзивную информацию. Небольшие компании могут для этих же целей воспользоваться накопленными ими в ходе работы наборами данных и известными алгоритмами. Отметим, однако, что предложенный подход также можно задействовать в качестве базовой модели для более сложных систем управления цепями поставок.
Дальнейшие исследования могут быть направлены на интеграцию дополнительных источников данных, таких как текущая дорожная ситуация, погодные условия и макроэкономические показатели. Использование такой информации в режиме реального времени может обеспечить увеличение точности прогнозирования и адаптивности моделей.
