Программная реализация конвейерной обработки данных в распределенной информационной системе

Автор: Кудряшов К.А.
Журнал: Вестник Красноярского государственного аграрного университета @vestnik-kgau
Рубрика: Математика и информатика
Статья в выпуске: 7, 2012 года.
Бесплатный доступ
В статье рассматривается вопрос об ускорении обработки данных. Выделены основные этапы процесса, рассмотрены алгоритмы, позволяющие формировать многомашинные конвейерные планы.
Конвейерная обработка, асу, информационная система, алгоритм джонсона
Короткий адрес: https://sciup.org/14082534
IDR: 14082534 | УДК: 62.529
Technology modeling for increase of the pipelined processing network capacity in ACS
The issue on data processing speedup is considered in the article. The process main steps are emphasized; the algorithms that allow to develop the multiple- machine pipelined plans are considered.
Текст научной статьи Программная реализация конвейерной обработки данных в распределенной информационной системе
Введение. Всегда существовала проблема нахождения наиболее быстрого выполнения задачи. Оператору и конвейерной информационной системе необходимо программное обеспечение, позволяющее детально проанализировать все факторы, влияющие на скорость обработки данных. Наилучшее выполнение задачи подразумевает определенную совокупность факторов процесса, при которой он выдает минимальное время выполнения задачи. Эта совокупность есть целый ряд параметров с определенными характеристиками. Их необходимо учесть и подобрать такие значения, с которыми результат решения задачи будет наибыстрейшим.
Одним из наиболее перспективных подходов к реализации данного программного обеспечения может быть использование современных языков компьютерного программирования, в нашем случае, Borland Delphi 7 [1].
Целью данной статьи является ускорение конвейерной обработки данных в распределенной информационной системе с помощью программного обеспечения.
Моделирование конвейерной обработки данных
Планирование процесса выполнения задач подразумевает, что задания (или задачи) должны быть назначены конкретному процессору для исполнения в конкретное время. Так как для выполнения может рассматриваться много задач или заданий (взаимозаменяемые термины), необходимо представить набор этих задач в виде их взаимосвязи друг с другом [2]. Представление наборов заданий с использованием ориентированного графа или графа предшествования является наиболее распространенным.
При рассмотрении видов классификации основным является вопрос: должен ли граф задачи обрабатываться одним процессором или информационной системой, содержащей более одного процессора? Решение разграничить планы обработки данных именно таким образом не является очевидным ввиду большого количества факторов, которые могут использоваться при классификации [3]. Были определены следующие факторы: количество процессоров; продолжительность задачи; структура графа предшествования; прерывание задач; периодичность выполнения конвейерного плана обработки данных; наличие и отсутствие пределов; планирование с ограниченными ресурсами; гомогенные и гетерогенные процессоры; показатели эффективности (время окончания или завершения; количество используемых процессоров; среднее время реализации конвейерного плана обработки задач; загрузка процессора; время простоя процессора); эффективность алгоритмов в целом.
Существует класс планов (конвейерные планы), в которых более чем один процессор включен в совместное выполнение ряда задач и в которых существует последовательная взаимосвязь между процессорами, однако, это не случай многопроцессорного планирования, так как задача, которую необходимо выполнить, должна быть обслужена одним из процессоров, а потом другими. Это чередование должно соблюдаться для всех задач, входящих в план, но требования идентичности процессоров нами не вводится.
Построение системы выполнения задач в конвейерной информационной системе
Программное обеспечение позволяет реализовать алгоритм Джонсона (JO) для формирования двухмашинных конвейерных планов обработки данных [4]. Предложена процедура сравнительного анализа конвейерных планов с начальной очередностью, с минимальным временем потока, SPT-план (рис. 1).
Установка модели Показатели эффективности Диаграммы Ганта
Планы Длительность плана Время простоя Загрузка процессора
|
Р1 |
Р2 |
Р1 |
|||
|
1. План по алгоритму Джонсона |
23 |
2 |
7 |
81,30 |
68,57 |
|
2. SPT план на основе Ai |
27 |
е |
11 |
77,78 |
58,26 |
|
3. План основанный на очередности в; начальной таблице |
23 |
5 |
10 |
80,77 |
61,54 |
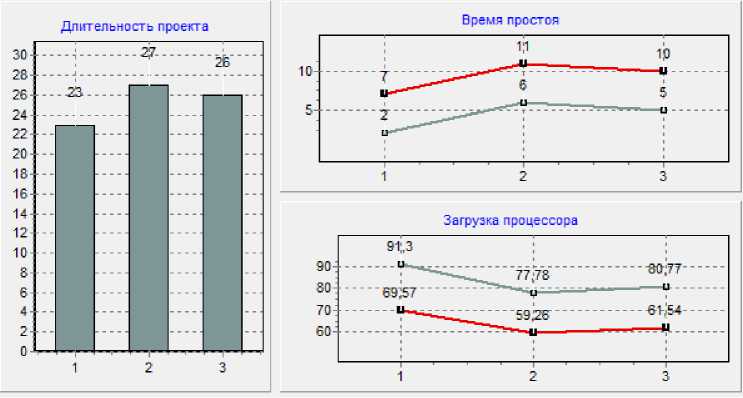
Рис.1. Показатели эффективности (2 процессора)
Ниже представлен сформированный план с минимальным временем потока (рис. 2).
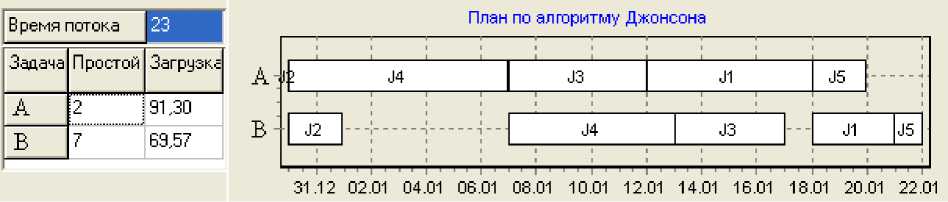
Рис. 2. Двухмашинный конвейерный план с минимальным временем потока
Следует отметить, что алгоритм Джонсона упорядочивает задачи, одновременно доступные на двухмашинном конвейерном плане, таким образом, чтобы минимизировать максимальное время потока. По алгоритму Джонсона задача Ji предшествует Jj, если A. + B . > A j + B j и A. < A j , где Ai и Bi представляют требования Ji для процессора класса А и класса В соответственно.
Предложена модификация алгоритма Джонсона (MJO), позволяющая формировать многомашинные конвейерные планы.
Процедуры предыдущего алгоритма обобщены для ситуации, когда более чем один процессор может существовать в каждом из двух классов – А и В. Для модифицированного алгоритма Джонсона (MJO) в конвейерной среде с m процессорами класса А и n процессорами класса В задача Ji предшествует Jj , в соответствии с (MJO), если mП г ( AjmB j/ n ) < min ( A j /m.Bjn ) .
Эта модификация фактически ослабляет действие нескольких ограничений, используемых в общем алгоритме Джонсона. Во-первых, допускается наличие более чем двух машин, а, во-вторых, предполагается, что объем доступной промежуточной памяти равен нулю.
Предложена процедура сравнительного анализа трехмашинных конвейерных планов: FSIIS-план с бесконечной промежуточной памятью, FSFIS-план с ограниченной промежуточной памятью (рис. 3).

Рис. 3. Показатели эффективности (3 процессора)
Ниже представлен сформированный FSIIS-план с бесконечной промежуточной памятью (рис. 4) .

Рис. 4. Трехмашинный конвейерный FSIIS-план с бесконечной промежуточной памятью
Инструментальной средой для реализации данного компонента программного обеспечения является Borland Delphi 7. В программной реализации приводятся показатели эффективности для построенных многомашинных конвейерных планов обработки данных: длительность конвейерного плана обработки данных, время простоя процессора, загрузка процессора.
Построение системы программной реализации при формировании информационной системы конвейерного типа
Система обработки данных состоит из пяти блоков (рис. 5). В первом блоке информационной системы производится сбор и запись информации обо всех проявившихся признаках, сопутствовавших поступившему требованию; во втором блоке на основании результатов анализа информации о признаках формулируется проблема или описывается событие, обусловившее требование; в третьем блоке – составляется список задач, решение которых должно привести к решению проблемы или соответствовать событию, обусловившему требование (рис. 6).
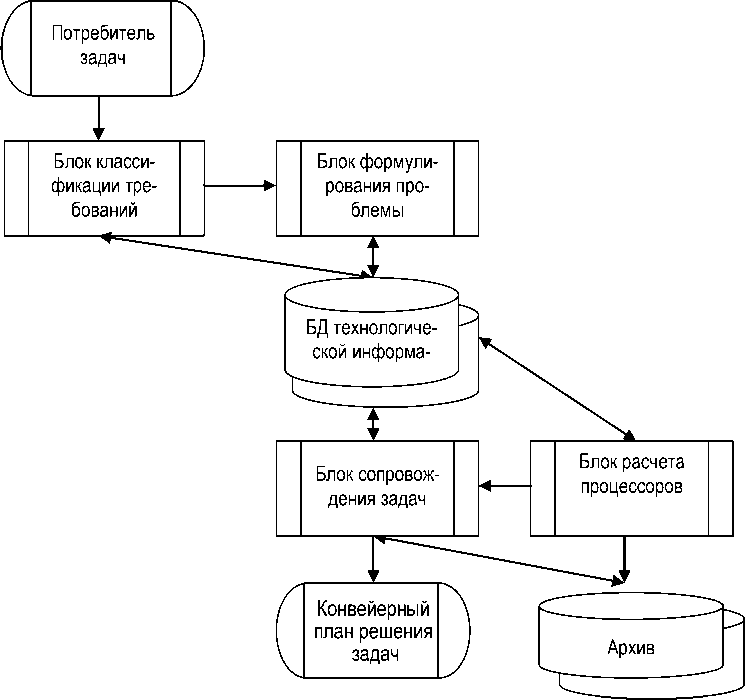
Рис. 5. Структурная схема реализации распределенной информационной системы конвейерного типа
2 процессора 3 процессора
Установка модели Показал
Количество задач
Рис. 6. Ввод параметров
В четвертом блоке выполняется расчет количества процессоров 1, 2 и последующих уровней, определяются основные показатели конвейерного плана (рис. 7).
Рис. 7. Расчеты
В пятом блоке уточняется принятое решение, регистрируются учетные записи и составляется конвейерный план решения задачи.
Предоставляется возможность сохранения информационных элементов рассмотренной модели, создания архива для более удобного поиска раннее рассмотренных моделей. Предлагается вариант воспроизведения модели при обработке похожей производственной ситуации.
Заключение
Описанное программное обеспечение увеличивает пропускную способность конвейерной распределенной информационной системы, а также обеспечивает однородность функций, что позволяет уменьшить требования к информационной системе.
Помимо этого пользователи в режиме реального времени могут отслеживать загруженность информационной системы конвейерного типа на текущий момент времени, что позволяет оперативно реагировать на возникающие проблемы.
Также программное обеспечение предоставляет возможность формирования показателей эффективности работы отдельных процессоров, реализующих конвейерные планы.
