Программный комплекс для анализа текстов на изображениях и их преобразования в документ на основе машинного обучения

Автор: Д. Пардаев, С. Сидиков
Журнал: Современные инновации, системы и технологии.
Рубрика: Прикладные вопросы и задачи применения систем и технологий
Статья в выпуске: 5 (2), 2025 года.
Бесплатный доступ
В данной статье рассматривается проблема оптического распознавания символов (OCR) и методы его улучшения с использованием технологий глубокого обучения и постобработки. Особое внимание уделено применению различных алгоритмов, таких как сверточные нейронные сети (CNN), для повышения точности распознавания текста. Также рассматриваются современные подходы к интеграции OCR-систем с другими интеллектуальными системами, а также методы коррекции ошибок в процессе распознавания. В статье представлена подробная методология и результаты экспериментов, подтверждающие эффективность предложенных решений. Целью работы является создание системы для автоматического преобразования изображений в текстовый формат с минимальными ошибками, что может быть полезно в различных областях, включая медицинские исследования, архивирование документов и обработку изображений.
Оптическое распознавание символов (OCR), глубокое обучение, постобработка, сверточные нейронные сети (CNN), коррекция ошибок, автоматическое преобразование изображений в текст, интеллектуальные системы, обработка изображений
Короткий адрес: https://sciup.org/14133033
IDR: 14133033 | DOI: 10.47813/2782-2818-2025-5-2-5011-5020
Текст статьи Программный комплекс для анализа текстов на изображениях и их преобразования в документ на основе машинного обучения
DOI:
Машинное обучение (Machine Learning) является одной из ключевых областей искусственного интеллекта (AI), активно развивающихся по всему миру. Эта технология позволяет системе обучаться и принимать решения без необходимости программирования каждого шага. Основное преимущество машинного обучения заключается в том, что оно может делать выводы и принимать решения на основе ранее полученных данных, а также адаптироваться к новым ситуациям без вмешательства человека. В настоящее время машинное обучение находит широкое применение в различных сферах, включая распознавание изображений, обработку естественного языка и медицину [1].
Одной из важных технологий в данной области является оптическое распознавание символов (OCR). OCR — это метод, позволяющий извлекать текст из изображений или отсканированных документов и преобразовывать его в цифровой формат. Эта технология имеет большое значение не только для обработки текста, но и для множества других областей, таких как цифровизация документов, восстановление исторических материалов, а также для юридической и научной работы, где необходимо быстрое и точное извлечение текстовой информации.
Однако системы OCR сталкиваются с рядом проблем, таких как неправильное освещение, угол сканирования или сложный фон изображения. Эти факторы могут значительно снизить точность распознавания текста. Поэтому для улучшения эффективности и точности работы OCR-систем разрабатываются новые алгоритмы и методы. В данном исследовании рассматриваются принципы работы OCR-систем, а также современные подходы и алгоритмы, направленные на повышение их точности и эффективности в практическом применении.
АНАЛИЗ ЛИТЕРАТУРЫ И МЕТОДОЛОГИЯ
OCR-технологии развиваются с конца 20 века, начиная с методов шаблонного сопоставления, которые ограничивались точностью распознавания. С развитием нейронных сетей, таких как свёрточные нейронные сети (CNN), точность значительно улучшилась. Архитектуры, как ResNet и VGG, активно применяются в OCR, обеспечивая высокую производительность при распознавании текста. Современные методы также используют постобработку для уменьшения ошибок распознавания и борьбы с искажениями изображений.
Методология исследования. Исследование включает несколько этапов:
-
• Предобработка изображений: улучшение
качества изображений через бинаризацию, фильтрацию шума и коррекцию наклона.
-
• Распознавание текста: использование
свёрточной нейронной сети (CNN), обученной на различных текстах и шрифтах.
-
• Постобработка: применение алгоритмов на основе машинного обучения для исправления ошибок, таких как HMM и словарные модели.
-
• Оценка производительности: измерение
точности, полноты и времени обработки.
РЕЗУЛЬТАТЫ
Машинное обучение является частью искусственного интеллекта, и исследования в этой области продолжают расти по всему миру. Оно обладает способностью обучаться самостоятельно без помощи людей и без явного программирования, основанного на предыдущем опыте или знаниях. В основном оно может принимать решения или делать предсказания на основе соответствующего набора входных данных и обучающего набора для выполнения конкретных задач. Машинное обучение используется в различных приложениях в реальном времени в нашей повседневной жизни. Одним из важнейших приложений является распознавание текста и извлечение текста, которое извлекает ценную информацию из изображений, полученных из различных источников. Тексты, имеющие различные изменения, могут отличаться по размеру, ориентации, выравниванию, стилю, низкой яркости или контрасту на изображениях с сложным фоном. Из-за различных изменений текста на изображениях многие сталкиваются с проблемами при чтении. Поэтому распознавание текста и извлечение текста в настоящее время является важной и сложной задачей. Цель заключается в том, чтобы помочь людям с разных уголков мира, говорящим на других языках, легко читать и понимать любой написанный текст. Исследователи используют различные алгоритмы машинного обучения и инструменты для распознавания рукописных и текстовых изображений, чтобы преобразовать их в цифровой формат. Оптическое распознавание символов — это метод машинного обучения, который помогает распознавать и извлекать текстовую информацию или данные из документа и преобразовывать их в редактируемую и доступную для поиска информацию [2].
OCR — это область исследований распознавания шаблонов, искусственного интеллекта и компьютерного зрения. Первоначальные версии требовали обучения на изображениях каждого символа и работы с одним шрифтом одновременно. Современные системы, которые могут достигать высокой точности для множества шрифтов, поддерживают различные форматы входных изображений и стали широко распространены. Некоторые системы способны воспроизводить отформатированные выходные данные, близкие к исходной странице, включая изображения, столбцы и другие не текстовые компоненты. OCR-системы используют комбинацию аппаратного обеспечения и программного обеспечения для преобразования физических печатных документов в машиночитаемый текст. Дополнительные устройства, такие как оптические сканеры или специализированные электронные платы, копируют или считывают текст, после чего программное обеспечение обычно выполняет дальнейшую обработку.
Технология оптического распознавания символов используется для автоматического преобразования текста с различных изображений и документов в цифровой формат. Этот процесс позволяет распознавать и обрабатывать рукописный или напечатанный текст. OCR-программное обеспечение может использовать методы искусственного интеллекта (AI) и интеллектуального распознавания символов (ICR) для более сложных задач, таких как распознавание рукописных текстов. Организации часто используют процесс OCR для преобразования печатных юридических или исторических документов в PDF-документы, что позволяет пользователям редактировать, форматировать и искать в документах, как если бы они были созданы в текстовом процессоре. OCR используется для следующих целей: преобразование бумажных документов в электронный формат; цифровизация архивных и библиотечных материалов; автоматическая обработка банковских и государственных документов; внесение научных и образовательных ресурсов в цифровую базу данных [3].
Технология оптического распознавания символов включает в себя несколько последовательных этапов, обеспечивающих максимально точное извлечение текстовой информации из изображений документов. На первом этапе осуществляется предобработка изображения, целью которой является улучшение качества изображения и подготовка его к последующему анализу. В рамках предобработки выполняется снижение шума, то есть удаление лишних пикселей, дефектов и артефактов, которые могут мешать распознаванию символов. Далее проводится бинаризация изображения — процесс преобразования цветного или полутонового изображения в черно-белый формат, что значительно облегчает распознавание текста. Ещё одной важной процедурой является коррекция наклона: если отсканированный документ размещён под углом, изображение выравнивается, чтобы строки текста были строго горизонтальными. После этого осуществляется определение границ документа, то есть выявление контуров страницы для удаления фона или лишних участков изображения.
На следующем этапе выполняется сегментация изображения, то есть разделение его на отдельные логические элементы. Прежде всего, система отделяет текстовые блоки от графических элементов (например, логотипов, диаграмм или изображений). Также производится идентификация и выделение таблиц и встроенных изображений, если таковые имеются. После этого происходит разделение текста на отдельные компоненты: сначала выделяются строки текста, затем слова, а затем каждый символ по отдельности. Такая последовательная сегментация позволяет повысить точность распознавания даже в сложных документах со смешанным содержимым. Всё это создает основу для успешного применения алгоритмов OCR и получения качественного текстового результата [4].
Ниже подробно объясняются основные алгоритмы, используемые для анализа текстов на изображениях и их преобразования в документ, а также их математические формулы и принципы работы. Перед распознаванием и чтением текста, изображение должно быть оптимизировано. Для этого используются следующие алгоритмы
Уменьшение шума (Gaussian Blur) — это свертка, используемая для уменьшения шума на изображении и размытия. Этот фильтр смягчает изображение, теряя мелкие детали и немного размывая крайние (edge) детали. Фильтр Gaussian Blur воздействует на изображение, распределяя веса согласно функции Гаусса. При этом каждый пиксель заменяется средним значением своих соседних пикселей с учетом весов. Gaussian Blur используется для размытия изображения [5].
x^+y^
^У^^ 6 (1)
Здесь x, y — координаты изображения, σ — дисперсия (чем больше sigma, тем сильнее фильтр).
Бинаризация текста (Otsu Thresholding) — это адаптивный алгоритм бинаризации, используемый для автоматического разделения текста и фона на изображении. Этот метод автоматически выбирает оптимальное пороговое значение (T) изображения на основе анализа гистограммы. Этот метод особенно полезен, когда яркость фона неравномерна или на изображении присутствует шум. Otsu thresholding автоматически выбирает оптимальное пороговое значение (T) изображения.
0 2 (T) = ) i (TM (T) (g i (T) - [ 2 (T)) (2)
Здесь 0)1,0)2 — вероятностные веса двух классов, [1 1 ,11 2 — средние значения яркости для каждого класса. Цель состоит в том, чтобы найти T, максимизируя О (T)
Обнаружение текста (Text Detection) — это процесс нахождения и выделения местоположения текста на изображении. Этот этап является частью OCR (оптического распознавания символов), и точное определение местоположения текста улучшает последующий процесс распознавания. Для определения местоположения текста на изображении используются следующие алгоритмы. EAST (Efficient and Accurate Scene Text Detection) — модель EAST работает на основе сверточных нейронных сетей (CNN) и определяет текстовые блоки в виде ограничивающих прямоугольников. Для обнаружения текстовых блоков в модели EAST используется комбинация ConvNet + RNN + FCN. Выход модели предоставляет следующие значения [6].
S(x,y) = Sigmoid(C(x,y)) (3)
Здесь S(x, y) — вероятность текстового блока, C(x, y) — карта корреляции модели, координаты ограничивающего прямоугольника (x, y, ω, h, θ).
Алгоритм MSER (Maximally Stable Extremal Regions) основан на определении стабильных регионов (текстовых блоков) на изображении. Он ищет участки, где изменения интенсивности света минимальны. Алгоритм MSER находит области с постоянными границами на изображении, основываясь на градиентных и граничных функциях.
R=^ (4)
Здесь ∂I — длина границ, |I| — количество пикселей внутри региона. Цель состоит в том, чтобы выбрать области с минимальным значением R.
Таблица 1. Сравнительная характеристика популярных алгоритмов, используемых для оптического распознавания СИМВОЛОВ (OCR).
Table 1. Comparative characteristics of popular algorithms used for optical character recognition (OCR).
|
Алгоритм |
Подход |
Преимущества |
Недостатки |
|
MSER |
Геометрический |
Быстро работает, простой |
Не работает хорошо с сложным фоном |
|
CCA |
Сегментация |
Хорошо для маленьких текстов |
Может возникнуть ошибка, если разница между символом и фоном маленькая |
|
EAST |
На основе CNN |
Хорошо работает при обнаружении крупных изображений |
Проблемы с распознаванием очень маленьких текстов |
|
YOLO |
Обнаружение объектов |
Быстро и работает в реальном времени |
Не работает хорошо с наклонными или маленькими текстами |
|
Transformer |
Self-Attention |
Точно работает даже в сложных условиях |
Требует вычислительных ресурсов |
Распознавание текста (OCR - optical character recognition) – это технология, которая автоматически определяет текст на изображениях или сканированных документах и преобразует его в цифровой формат. OCR выделяет буквы, цифры и специальные символы, превращая их в машиночитаемый вид. Технология OCR широко применяется в оцифровке документов, автоматическом вводе данных, мобильных приложениях, распознавании паспортов или удостоверений личности. Для распознавания текста используются OCR-системы. Tesseract OCR – это система OCR с открытым исходным кодом, разработанная Google. Она работает на основе LSTM (Long Short-Term Memory) + Feature Extraction. LSTM (Long Short-Term
Memory) – это вид рекуррентной нейронной сети (RNN), используемой для изучения последовательных данных. В отличие от обычных RNN, LSTM обладает способностью запоминать долгосрочные зависимости.
Математическое выражение LSTM [7]:
ft = a (Wf • [ht -i ,xt] + bf) it = а(Щ • [h t-i ,x t ] + bt) O t = a(W0 • [ht _i ,xt] + b0). (5)
Здесь ft , it, Ot - это забывающие, входные и выходные ворота соответственно, W ^ , Wi,W0- матрицы весов, ht-1- предыдущее скрытое состояние.
Tesseract использует CTC (Connectionist Temporal Classification):
p(y|x) = n [=i P(y t |X t ) (6)
Здесь xt - входной символ, yt - выход модели.
Преобразование текста в документ (Postprocessing) – это заключительный этап OCR-системы, на котором распознанный текст сохраняется в правильном формате, уменьшается количество ошибок и оформляется как документ. Для очистки и исправления текста, полученного с OCR, используются следующие алгоритмы, Levenshtein Distance (Исправление текста) – применяется для определения минимального количества изменений между двумя текстами [8].
{ D(i — 1,j - 1) Если st = t j
IC — 1J^ (7)
1 +min< D (i, j - 1) , иначе
D D(i-1,j-1)
Здесь S i - i-я буква первого текста, t j - j-я буква второго текста, (D(i, j) – расстояние между текстами.
Рассмотрим глубокое обучение на основе OCR (Deep Learning OCR). CRNN (Convolutional Recurrent Neural Network) состоит из 3 основных частей. Convolutional Neural Network (CNN) – это модель глубокого обучения, предназначенная для автоматического извлечения признаков из изображений и последовательных данных. CNN в основном используется для анализа изображений, извлечения признаков и преобразования их в более высокоуровневые концепции. CNN (Извлечение признаков):
F = CNN(I) (8)
Рекуррентная нейронная сеть (RNN) – это тип нейронной сети, предназначенный для работы с временными рядами (time series). В отличие от обычных нейронных сетей, RNN запоминает результаты предыдущих временных шагов (time steps), что позволяет моделировать данные во времени. RNN (Моделирование временных зависимостей):
h t = a(Whh t-i + Wxx t ) (9)
CTC (Connectionist Temporal Classification) Loss – это специальная функция потерь, используемая в нейронных сетях, работающих с временными рядами, особенно когда символы (буквы, слова) не имеют четких границ, для их выравнивания и распознавания. CTC Loss (Выходной слой):
£ ctc = —logP(y\x) (10)
CRNN использует комбинацию EAST + LSTM + CTC Loss.
Рассмотрим OCR на основе Transformer (TrOCR - Microsoft). Определение текста на основе Transformer состоит из следующих этапов, Механизм внимания (Attention Mechanism) [9]:
Attention(Q, К, V) = softmax (^^) V (11) ^d k
Q, K, V - входные векторы, dk - коэффициент масштабирования (скалирующий фактор). MultiHead Attention (MHA) – основной компонент моделей Transformer, который позволяет анализировать информацию с разных точек зрения путем параллельного использования нескольких механизмов внимания. Многоголовое внимание (Multi-Head Attention):
MultiHead(Q,K,V) =
Concat(head 1 ,. ,headh)W0 (12)
Таблица 2. Сравнительная таблица типов нейронных сетей, их описания и основных областей применения. T ABLE 2. Comparative table of neural network types, their descriptions and main areas of application.
|
Тип сети |
Описание |
Применение |
|
FNN (Forward Neural Network) |
Данные передаются только вперед |
Обычная классификация и регрессия |
|
CNN (Convolutional Neural Network) |
Специально для анализа изображений и фотографий |
Компьютерное зрение (OCR, распознавание лиц) |
|
RNN (Recurrent Neural Network) |
Работает, запоминая предыдущие данные |
NLP, распознавание речи |
|
LSTM (Long Short-Term Memory) |
Тип RNN, сохраняющий долгосрочные зависимости |
Перевод текста, распознавание голоса |
|
Тип сети |
Описание |
Применение |
|
GAN (Generative Adversarial Network) |
Создание новых изображений и данных |
Deepfake, создание искусства |
|
Transformer tarmoqlari |
Работает на основе параллельных вычислений |
Чат-боты, системы перевода (GPT, BERT) |
Следует отметить роль моделей машинного обучения в OCR. Используются сверточные нейронные сети (CNN) – для распознавания текста на изображениях. Модели CNN, в основном, используются для нахождения областей, где расположен текст на изображении. CNN анализирует изображение через следующие операции. Операция свертки – используется для проверки частей изображения (фильтры), и для этого применяется следующая формула [10]:
S(i,f) = XmZnt(i + m,j + n) • K(m,n) (13)
Здесь I(i, j) – входное изображение; K(m, n) – ядро свертки (фильтр); S(i, j) – результат свертки.
Пулинг используется для выбора максимального или среднего значения). Операция пулинга уменьшает размер изображения, сохраняя при этом основные характеристики.
Рассмотрим полносвязанный слой (Fully Connected Layer, FCL). На последнем слое нейронная сеть распознает буквы или слова. Рекуррентные нейронные сети (RNN, LSTM) используются для понимания текста. В OCR-системах используются модели RNN или LSTM для правильного распознавания последовательных символов. Клетки LSTM работают следующим образом:
ft = a(Wf • [ht -i ,xt] + bf) it = a(Wl^[ht —i ,xt]+bl)
C t = f t • C t-i + i t • tan h (W • [h t-i , x t ] + bc) O t = a(W0 • [h t—i ,X t ] + b0)
ht = ot • tanh(Ct) (14)
Здесь ft - степень забывания (forget gate), it -степень принятия новой информации, Ct -долгосрочная память (cell state), ot - выходной вектор, ht - скрытое состояние. Модели LSTM обычно используются для понимания последовательности слов и символов.
Модели Transformer (TrOCR) – это современный подход в OCR. Модели Transformer достигли большого успеха в OCR, так как они хорошо понимают контекст. Основная часть модели Transformer – это механизм самовнимания (Self-Attention Mechanism). Формула для вычисления самовнимания [11]:
Attention(Q, К, V) = softmax №==} V (15) ^^ k
Здесь Q – запрос (query), K – ключ (key), V – значение (value), dk - длина вектора. Модели Transformer, включая TrOCR, позволяют более точно распознавать текст в OCR системах.
RNN (recurrent neural network – рекуррентная нейронная сеть) – это модель искусственных нейронных сетей, предназначенная для работы с последовательными (временными) данными. RNN имеет способность запоминать информацию о предыдущих шагах, что делает её подходящей для обработки данных, таких как текст, речь и временные ряды.
Принцип работы RNN заключается в следующем. Данные поступают в сеть. На каждом шаге сеть запоминает результат предыдущего шага. Генерируется выходной результат (output) и передается на следующий шаг. Сеть выполняет обратное распространение ошибки во времени (BPTT) и обновляет веса. Важная особенность – каждый нейрон использует свое предыдущее состояние для последующих вычислений, что позволяет хорошо обрабатывать последовательные данные.
Сети RNN (recurrent neural network) используются для обработки звука и текста (NLP); машинного перевода; создания музыки. Принцип работы – RNN сохраняет память и запоминает предыдущее состояние; модель на каждом временном шаге принимает новые данные и связывает их с предыдущими. Математическая модель отражает принцип, когда на каждом временном шаге вычисления происходят следующим образом [12]:
h t = f(Whh t-i + WxX t + b) (16)
Здесь ht - текущее состояние во времени, xt -входные данные, Wh, Wx - матрицы весов.
Таблица 3. Сравнительный анализ моделей глубокого обучения: преимущества и недостатки.
Table 3. Comparative analysis of deep learning models: advantages and disadvantages.
|
Модель |
Преимущества |
Недостатки |
|
CNN |
- Хорошо работает с изображениями и пространственными данными. - Высокая скорость параллельной обработки. |
- Не может обрабатывать последовательные данные. |
|
RNN |
- Хорошо работает с последовательными данными. - Подходит для обработки речи и текста. |
- Медленный из-за последовательной обработки. - Проблема исчезновения градиента. |
|
Transformer |
|
- Требует очень больших ресурсов. - Для обучения необходимы большие наборы данных. |
Сеть CNN используется для работы с изображениями или данными, связанными с пространством (например, OCR, распознавание лиц) [13].
RNN используется для работы с последовательными данными (текст, звук, временные ряды). Transformer – если вы работаете с NLP или большими объемами текстовых данных (перевод, чат-боты, генерация
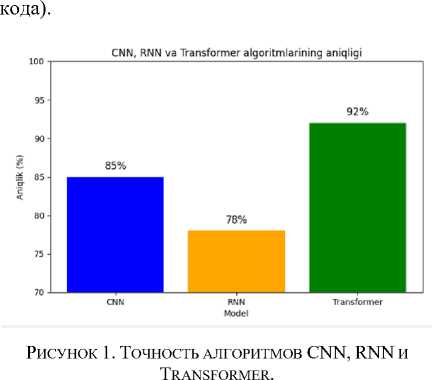
Figure 1. Accuracy of CNN, RNN and Transformer algorithms.
ОБСУЖДЕНИЕ
С помощью разработанной программы, после загрузки изображения пользователем, текст автоматически извлекается и сохраняется в формате .docx. Это позволяет упростить процесс цифровизации документов и предоставить пользователям удобный интерфейс.
Программа генерирует следующие результаты: извлечение текста с изображения; загруженное пользователем изображение анализируется. Текст на изображении извлекается с помощью Tesseract OCR. Отображение извлечённого текста пользователю осуществляется следующим образом. Результат OCR возвращается пользователю в формате JSON. Пользователь может увидеть текст в веб-интерфейсе. Сохранение извлечённого текста происходит в формате .docx. Результат OCR сохраняется в виде документа .docx с помощью python-docx. Файл загружается в папку static/output/ на сервере. Имеется возможность скачать файл. Пользователь может скачать документ .docx [14].
Этапы работы программы следующие. Пользователь загружает изображение. Через вебстраницу пользователь загружает изображение, нажимая кнопку "Загрузить файл". Загруженный файл отправляется на сервер Flask. Сервер Flask сохраняет файл в папку static/uploads/.

Алишер Навои (nepCjJ^ ^«шХь, узб. AUsher Navoiy) (Низамлддин Мир Алишер) [9 феврали 1441, Герат — 3 январи 1501, там же) — выдающийся поэт Бостона, философ суфийского наПранлоння государственный деятель тИмуридского Хорасана. Под псевдонимом Фани (бренный] писал на языке фарси, однако главные произведения создал под псевдонимом Навои (мелодичный) на литературном чагатайском языке, на развитие которого оказал заметное влияние. Его творчество дало мощный стимул эволюции литературы на тюркских языках, в особенности чагатайской и воспринявшей ел традиции узбекской.
Рисунок 2. Изображение, выбранное для ТЕСТИРОВАНИЯ .
Figure 2. Image selected for testing.
Обработка изображения и извлечение текста. Изображение открывается с помощью библиотеки OpenCV. Изображение анализируется с помощью pytesseract. Поддержка языков: OCR распознает текст на языках "английский + узбекский" [15].
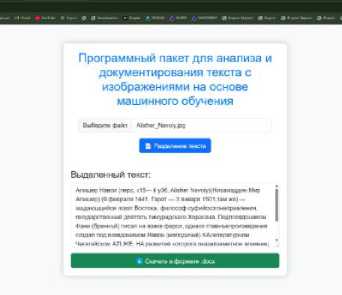
Рисунок 4. Результат работы программы.
Figure 4. Result of the program.
Разделение текста
Выделенный текст:
Сохранение текста возможно в документ .docx. Текст сохраняется в формате .docx с помощью python-docx.
Рисунок 3. Интерфейс программы.
Figure 3. Program interface.
Возможен возврат текста в формате JSON пользователю. Извлечённый текст возвращается пользователю в формате JSON. Пример:
{
"text": "Это
тестовый
текст",
"doc_url":
}
Документ загружается в папку static/output/.
Рисунок 5. Загрузка результата программы.
Figure 5. Loading the program result.
Пользователь загружает .docx файл.
Пользователь нажимает кнопку "Скачать".Сервер Flask отправляет файл через функцию send_file().
Рисунок 5. Адрес сохранения результата программы.
Figure 5. Address for storing the program result.
Данный программный продукт основан на технологии оптического распознавания символов, что позволяет автоматически извлекать и обрабатывать текст. Он разработан на основе веб-приложения Flask и предоставляет пользователям удобный интерфейс и автоматизированную услугу создания документов. В будущем программа может использовать искусственный интеллект для более точного распознавания и обработки текста [16].
Приведем пошаговую последовательность этапов работы программы:
-
1. Алгоритм приема файла, загруженного пользователем. На первом этапе реализуется процесс получения изображения, отправленного пользователем через веб-интерфейс. Сначала файл принимается сервером через HTTP-запрос, после чего выполняется проверка на наличие самого файла в запросе. Если файл существует, дополнительно проверяется, чтобы имя файла не было пустым. Эти меры необходимы для предотвращения ошибок, связанных с обработкой некорректных или отсутствующих данных. После успешного прохождения валидации файл сохраняется в заранее определённую директорию, обозначенную как UPLOAD_FOLDER. По завершении сохранения возвращается путь к файлу, что позволяет использовать его на последующих этапах обработки. Такой подход обеспечивает упорядоченное хранение пользовательских данных и облегчает управление файлами в системе.
-
2. Алгоритм обработки изображения. После загрузки изображение требует предварительной обработки перед подачей на OCR-анализ (распознавание текста). На данном этапе используется библиотека OpenCV, с помощью которой изображение загружается в память. По умолчанию OpenCV открывает изображение в цветовом формате BGR, тогда как большинство OCR-систем требуют формат RGB. Поэтому изображение преобразуется в нужный формат с использованием функции cv2.cvtColor. Эта операция обеспечивает корректную цветовую интерпретацию изображения, необходимую для повышения точности последующего распознавания текста. Подготовленное изображение передаётся на следующий этап — извлечение текста с помощью OCR [17].
-
3. Алгоритм извлечения текста с использованием OCR. На данном этапе выполняется основная задача — извлечение текстовой информации из изображения. Для этого применяется система оптического распознавания символов (OCR), в частности, библиотека Tesseract, обладающая поддержкой множества языков, включая английский и узбекский. Обработанное изображение передаётся
-
4. Алгоритм сохранения текста в формате .docx. После получения текста возникает необходимость представить его в удобном для пользователя формате — текстовом документе. Для этого используется библиотека pythondocx, позволяющая программно создавать и редактировать файлы формата .docx. На основе извлечённого текста создаётся новый документ, куда текст добавляется по абзацам, сохраняя читаемую структуру. Документ сохраняется в заранее заданной директории OUTPUT_FOLDER, а путь к файлу фиксируется для последующей передачи пользователю. Таким образом, обеспечивается автоматическое преобразование изображения в полноценный текстовый документ.
-
5. Алгоритм отправки пользователю документа для скачивания. На заключительном этапе пользователь получает возможность скачать готовый файл. Это реализуется посредством повторного HTTP-запроса со стороны клиента, в ответ на который сервер, используя функцию send_file из фреймворка Flask, отправляет созданный документ. Файл передаётся с соответствующими HTTP-заголовками, указывающими имя, тип и размер, что обеспечивает корректное отображение процесса скачивания в браузере пользователя.
в Tesseract, который анализирует визуальное содержимое и преобразует его в текст. После распознавания извлечённый текст проходит процедуру очистки от лишних символов, пробелов и возможных ошибок. При необходимости осуществляется разделение текста по языкам. Итоговый результат оформляется в формате JSON, что упрощает его дальнейшее использование в цифровых системах хранения, анализа или визуализации.
Таким образом, цикл обработки от загрузки изображения до получения текстового документа завершается полным автоматическим сервисом.
ЗАКЛЮЧЕНИЕ
В результате проведенного исследования был разработан эффективный метод для автоматического распознавания текста с изображений с использованием современных технологий OCR. Предложенная методология включает в себя этапы предобработки изображений, распознавания текста с использованием свёрточных нейронных сетей и постобработки для коррекции ошибок. Результаты показывают, что использование машинного обучения и нейронных сетей значительно повышает точность распознавания и снижает количество ошибок. Таким образом, данная система может быть успешно применена в реальных условиях для преобразования текстовых данных из изображений в машиночитаемый формат [18].
