Распознавание автомобильных номеров на основе метода связных компонент и иерархической временной сети

Автор: Болотова Юлия Александровна, Спицын Владимир Григорьевич, Рудометкина Моника Николаевна
Журнал: Компьютерная оптика @computer-optics
Рубрика: Обработка изображений: Восстановление изображений, выявление признаков, распознавание образов
Статья в выпуске: 2 т.39, 2015 года.
Бесплатный доступ
В работе предложена технология распознавания автомобильных номеров, состоящая из следующих этапов: предобработка изображения, сегментация номера и его распознавание. Данная технология позволяет распознавать номерные знаки с хорошей точностью в условиях дня и ночи, а также при наличии значительного наклона номерной пластины. Для предварительной обработки изображений был выбран оператор Собеля и операция морфологического закрытия, что позволило увеличить эффективность последующей бинаризации номерной пластины. Сегментация выполнялась с помощью метода связных компонент, что позволило избежать поворота пластины и, как следствие, дополнительной потери качества. Применение иерархической временной сети позволило эффективно распознавать символы, изображённые под наклоном. Предложенная технология аналогично может быть применена для сегментации и распознавания различных текстовых данных.
Обработка изображений, распознавание символов, иерархическая временная сеть
Короткий адрес: https://sciup.org/14059358
IDR: 14059358
License plate recognition algorithm on the basis of a connected components method and a hierarchical temporal memory model
This paper proposes a license plate recognition algorithm that consists of three major steps: image preprocessing, segmentation, and recognition, which works efficiently with day- and nighttime images, as well as with the license plate being tilted. Pre-filtration allows the sequential binarization to be conducted efficiently. Typically, the license plate segmentation is realized by a histogram method with the preliminary plate de-rotation to the horizontal position, thus deteriorating the original image quality. In this paper the segmentation is implemented by a connected components method, enabling the rotation and a consequent loss of quality to be avoided. The hierarchical temporal network shows good results in rotated symbols recognition. The proposed method can be used in a similar way for segmentation and recognition of various text data. The proposed algorithms can also be used for distorted text segmentation and recognition.
Текст научной статьи Распознавание автомобильных номеров на основе метода связных компонент и иерархической временной сети
Задача распознавания автомобильных номеров часто решается в сложных условиях эксплуатации: при различных погодных условиях, освещении, загрязнении номерных знаков. Решение данной задачи требуется в таких приложениях, как управление автомобильным трафиком, автоматическая обработка дорожных аварий, автоматическая парковка.
Зашумление и наклон номерного знака являются серьёзными проблемами, возникающими при разработке подобных систем. В данной работе решение задачи происходит путём распознавания символов под наклоном, что позволяет избежать дополнительных искажений при приведении номера в горизонтальное положение. В статье рассматриваются алгоритмы, связанные с предобработкой, сегментацией и распознаванием номера.
К существующим методам сегментации относятся методы математической морфологии, выделения границ, преобразование Хафа, горизонтальное и вертикальное проецирование [1], алгоритм Adaboost [2], свёрточные нейронные сети (СНН) [3]. Для решения задачи распознавания часто применяются деревья решений, скрытые модели Маркова, машины опорных векторов, сопоставление с шаблонами [4], различные алгоритмы на базе искусственного интеллекта: многослойные персептроны, нейронные сети [5, 6], СНН и др.
Предлагаемая технология состоит из трёх основных этапов. На первом этапе происходит предобработка изображения, включающая применение оператора Собеля, морфологических операций, статистического анализа и бинаризации изображения. На следующем этапе происходит сегментация номера на основе метода связных компонент (МСК), позволяющая успешно сегментировать номерной знак без потери качества изображения. Третьим этапом является рас- познавание сегментированных символов иерархической временной сетью (ИВС).
Постановка задачи
В каждой стране существуют собственные правила оформления номерных знаков. Для получения наиболее достоверных результатов распознавания необходимо учитывать данные правила. В России существует 20 типов номерных знаков различных форм, размеров и цветов. В работе рассматриваются самые распространённые из них (рис. 1). Размер знака составляет 520×112 мм. Две группы символов разделены чёрной вертикальной линией. Левая часть представляет собой номер машины и состоит из следующих элементов: буква, затем 3 цифры и 2 буквы. Правая часть номера определяет код области, в которой машина была зарегистрирована, и состоит из 2 или 3 цифр. В номерных знаках нашей страны используются только буквы, имеющие эквиваленты как в кириллическом, так и в латинском алфавитах: “A”, “B”, “C”, “E”, “H”, “K”, “M”, “O” и “P”.
м976мм?о
Рис. 1. Пример номерной пластины РФ
Граничные условия для данной задачи перечислены в табл. 1 и соответствуют основным техническим условиям работы современных камер видеонаблюдения.
Табл. 1. Граничные условия для задачи распознавания
|
Показатель |
Значение |
|
Условия освещённости |
От 20 до 1000 лк |
|
Угол наклона по вертикали |
±40 |
|
Угол наклона по горизонтали |
±30 |
|
Угол наклона на плоскости |
±20 |
|
Минимальная высота номера |
25 пикселей |
Описание технологии распознавания номерных знаков
Общая схема предложенной технологии приведена на рис. 2, она включает в себя три основных этапа: предобработку, сегментацию и распознавание.
Предобработка, включающая оператор Собеля и морфологическое закрытие, необходима для определения позиции номерной пластины в исходном изображении. Бинаризация позволяет разделить номерную пластину на 2 части, отделив символы от фона. Для решения данной задачи был выбран метод бинаризации Отсу [7].
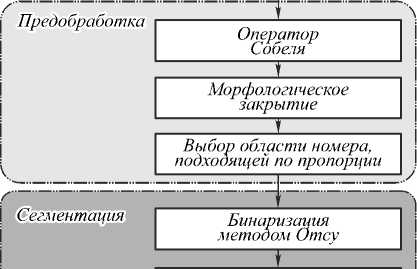
Метод связных компонент + RLE-сжатие
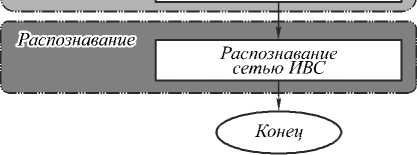
Рис. 2. Распознавание автомобильных номеров
После бинаризации происходит сегментация номерной пластины путём применения МСК, производящего поиск связных пикселей на основе 8 связности. Для ускорения этапа сегментации в данной работе МСК был реализован с помощью предварительного RLE-сжатия изображения [8]. При сохранении сегментированных символов их порядок определялся минимальной « x »-координатой на исходном изображении. Далее приводится подробное описание каждого этапа.
Предобработка
Исходные изображения представляют собой пластину номера на некотором фоне (рис. 3). Несмотря на то, что подобное изображение практически не содержит посторонних деталей, необходимо провести его первичную предобработку для непосредственного выделения номерной пластины.
Предобработка состоит из следующих шагов:
-
1) применение оператора Собеля для выделения вертикальных линий;
-
2) применение морфологического закрытия для слияния смежных областей номера;
-
3) применение метода связных компонент для определения количества связных областей;
-
4) если на изображении присутствует более чем один связный объект, то в качестве номерной пластины выбирается объект с ближайшей пропорциональной зависимостью высоты к длине;
-
5) выделение номерной пластины по минимальному и максимальному значению связной области.

Рис. 3. Пример исходного изображения
Бинаризация (метод Отсу)
Для осуществления бинаризации был выбран известный метод Отсу. Он является полностью автоматизированным и основывается на анализе распределения яркости пикселей изображения по его нормализованной гистограмме:
P i = ntl N , (1)
где N – общее число пикселей изображения, n i – число пикселей с уровнем яркости i , i = 0 .. L .
Метод позволяет разделить изображение на 2 класса относительно граничного значения t , где класс с 1 содержит пиксели с яркостями [0, 1, ... , t ], а класс c 2 – пиксели с яркостями [ t +1, ... , L– 1]. Поиск граничного значения основан на минимизации внутриклассового различия, представленного в виде суммы различий каждого кластера [3]:
с w 2( t) = P( t )c2( t) + P2( t )o2( t).(2)
Веса P i – это вероятности класса i , σ i 2 – внутриклассовые различия. Можно учитывать максимизацию межклассовых различий:
C (t) = c2 -cW(t) = P (t)P2 (tM (t) - Ц2 (t)]2,(3)
где σ 2 – совокупная дисперсия. Вероятность класса по данному порогу вычисляется по следующей формуле:
tL
P(t) = ^p(i), P2(t) =^ p(i) = 1 -P1.(4)
i=0
Среднее значение класса μ 1 ( t ) вычисляется как:
tL
Ц1( t) = [Eip (i )]/P1, ^2( t ) = [ E ip (i )]/P2.
i = 0 i = t + 1
Общий алгоритм бинаризации Отсу состоит из следующих этапов:
-
1) вычисление гистограммы исходного изображения;
-
2) для каждого возможного значения t :
-
2.1) рассчитать σ b 2 ( t );
-
2.2) если σ b 2 ( t ) больше текущего максимального значения, изменить максимальное значение на σ b 2 ( t ); сохранить значение t .
-
На рис. 4 изображён пример гистограммы изображения, представленного на рис. 3. Вертикальная чёрная линия показывает найденную граничную яркость t , разделяющую два класса.
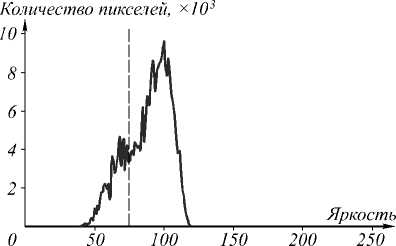
Рис. 4. Гистограмма изображения со значением выбранного порога методом Отсу
Выделенная номерная пластина и результат её бинаризации методом Отсу представлены на рис. 5.

Рис. 5. Исходное изображение (а) и результат его бинаризации методом Отсу (б)
Метод связных компонент
В работе представлена реализация сегментации номерного знака на основе двухпроходного метода связных компонент (МСК) с RLE-модификацией [8]. Базовый МСК сканирует изображение слева направо и сверху вниз. На первом проходе пикселю, отличному от фона, назначается минимальный номер из уже назначенных категорий его соседних пикселей либо
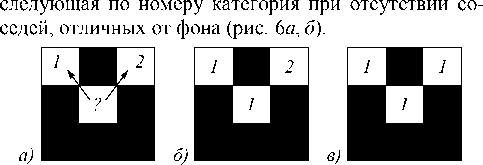
Рис. 6. Пример работы МСК на первом проходе (а, б). Результат работы МСК после второго прохода (в): «1», «2» – назначенные категории пикселей
На втором проходе ищутся связи между маркированными пикселями различных категорий. Если связь найдена, то все «старшие» метки заменяются на «младшие» (рис. 6 в ).
В данной работе была реализована модификация МСК на базе RLE-сжатия [8], что позволило ускорить работу алгоритма.
Ниже приводится алгоритм RLE-сжатия:
-
1) если текущий пиксель изображения [ i , j ] является пикселем объекта, то
-
1.1) если это первый пиксель объекта после фоновых пикселей, то initPos = j ; finalPos = j ;
-
1.2) иначе finalPos = j ;
-
-
2) если текущий пиксель является первым пикселем фона после пикселей объекта, то сохранить значения initPos и lastPos в RLE-массиве.
В результате бинаризированное изображение заменяется на RLE-массив, содержащий начальные и конечные позиции объектов в каждой строке. К полу- ченному массиву применяется метод связных компонент. Элементы меньше 5 пикселей в длину или ширину или больше, чем 0,2 от номерного знака, игно- рируются.
Оставшиеся элементы сохраняются в отдельные файлы, согласно их « x »-координате в исходном изображении (рис. 7). Подобные изображения и являются входными данными для ИВС на этапе распознавания.

Рис. 7. Пример сегментированных символов
Иерархическая временная сеть
ИВС является биологически-подобной сетью, основанной на двух принципах работы мозга: иерархического представления объектов и использования временной составляющей в процессе зрения [9]. Сеть представлена древовидной структурой, состоящей из n уровней. L 0 – входной уровень, L n –1 – выходной уровень.
Каждый уровень состоит из двухмерной решётки узлов, в которых и происходит процесс обучения и распознавания. Узлы одного уровня не связаны между собой, информация передаётся от нескольких со- седних узлов предыдущего уровня к одному закреплённому за ними узлу следующего уровня (рис. 8).
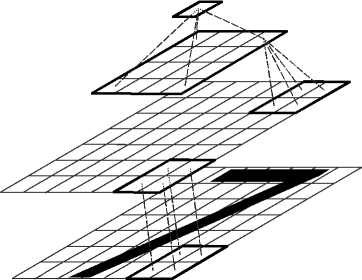
Рис. 8. Структура ИВС
В текущей реализации сеть состоит из 3 уровней. Размеры рецептивных полей узлов сети равны соответственно: m lev0 = 4×4, m lev1 = 2×2, m lev2 = 4×4. Подробная структура сети описана в нашей предыдущей работе [10]. Так как расположение символов на номерной пластине предопределено, то для повышения точности распознавания применяются две ИВС: одна – для распознавания символов, другая – для распознавания цифр.
Эксперименты
Предложенная технология была реализована и протестирована на 2 базах изображений зашумлённых номерных знаков, снятых в дневное (200 номеров: 1200 цифр и 600 букв, рис. 9 а ) и ночное время (200 номеров: 1200 цифр и 600 букв, рис. 9 б ). Можно заметить, что фотографии, снятые в ночное время, являются менее контрастными.
а)
б)

Рис. 9. Пример тестовых изображений
Обучающая выборка состоит из отдельных цифр и букв, сегментированных из незашумлённых изображений номерных знаков (рис. 10).
'A 092 A A Z--
Рис. 10. Пример номерного знака из обучающей выборки
Результаты распознавания приведены в табл. 2. Время распознавания включает предобработку, сегментацию и распознавание симоволов. Таким образом, использование RLE-сжатия во время сегментации ускоряет работу предложенного метода в 10 раз. Точность распознавания номерных знаков, снятых в дневное время, превышает точность распознавания «ночных» номерных знаков.
Табл. 2. Результаты распознавания номерных знаков предложенным алгоритмом
|
Предобработка |
Сегмента-ция |
Распо-знава-ние |
Точность распознавания, % |
Время распознавания (чч:мм:сс) |
|
|
«дневные» |
«ночные» |
||||
|
Бинаризация методом Отсу |
МСК на базе RLE |
ИВС |
94,1 |
92,1 |
00:00:03 |
|
МСК |
94,1 |
92,1 |
00:00:35 |
||
Произведено сравнение предложенной технологии с работами других авторов, основанных на скрытых моделях Маркова [11], методе сопоставления с шаблонами [12], методе Adaboost [13], сети Кохонена [14] и генетической нейронной сети [15]. Результаты сравнения приведены в табл. 3.
Табл. 3. Точность распознавания номерных знаков, достигнутая различными алгоритмами
|
Алгоритм |
Точность распознавания, % |
|
|
Ночная съёмка |
Дневная съёмка |
|
|
Скрытые модели Маркова |
90 |
90 |
|
Предложенный метод |
92,1 |
94,1 |
|
Метод Adaboost |
91 |
91 |
|
Сеть Кохонена |
95,8 |
94 |
|
Сопоставление шаблонами |
80 |
82,5 |
|
Нейронная сеть |
86,5 |
86,5 |
Заключение
В работе предложена технология сегментации и распознавания автомобильных номеров. Совместное использование модели иерархической временной памяти, метода связных компонент и бинаризации методом Отсу показало хорошие результаты распознавания номерных знаков как для «дневной», так и для «ночной» съёмки. Сравнение результатов распозна- вания различных алгоритмов, приведённое на рис. 11, показало, что предложенный алгоритм сравним с существующими и в большинстве случаев не уступает им по точности распознавания. Применение метода связных компонент для сегментации позволяет избежать потери качества исходного изображения. Выполнение сегментации на основе RLE-сжатия ускоряет процесс сегментации без потери качества изображения. ИВС позволяет распознавать символы и цифры под наклоном с приемлемой точностью.
Исследование выполнено при частичной финансовой поддержке РФФИ в рамках научного проекта № 12-08-00296, а также за счёт средств субсидии в рамках реализации Программы повышения конкурентоспособности ТПУ.
Список литературы Распознавание автомобильных номеров на основе метода связных компонент и иерархической временной сети
- Jia, W.J. Region-based license plate detection/W.J. Jia, H.F. Zhang, X.J. He//Journal of Network and Computer Applications. -2007. -Vol. 30(4). -P. 1324-1333.
- Zheng, L.H. Accuracy enhancement for license plate recognition/L.H. Zheng, X.J. He, B. Samali, L.T. Yang//Proceedings of the International Conference on Computer and Information Technology. -2010. -P. 511-615.
- Han, C.C. License plate detection and recognition using a dual-camera module in a large space/C.C. Han, C.T. Hsieh, Y.N. Chen, G.F. Ho, K.C. Fan, C.L. Tsai//41st Annual IEEE International Carnahan Conference on Security Technology. -2007. -P. 307-312.
- Глумов, Н.И. Метод быстрой корреляции с использованием тернарных шаблонов при распознавании объектов на изображениях/Н.И. Глумов, Е.В. Мясников, В.Н. Копенков, М.А. Чичёва//Компьютерная оптика. -2008. -Т. 32, № 3. -С. 277-282.
- Caner, H. Efficient embedded neural network-based license plate recognition system/H. Caner, H.S. Gecim, A.Z. Alkar//IEEE Transactions on Vehicular Technology. -2008. -Vol. 57(5). -P. 2675-2683.
- Park, S.H. Locating car license plate using neural networks/S.H. Park, K.I. Kim, K. Jung, H.J. Kim//Electronics Letters. -1999. -Vol. 35(17). -P. 1475-1477.
- Otsu, N. A threshold selection method from gray-scale histogram/N. Otsu//IEEE Transactions on System, Man, and Cybernetics. -1979. -P. 62-66.
- Стержанов, М. Методики выделения связных компонент в штриховых бинарных изображениях/М. Стержанов//20 Международная конференция по компьютерной графике и зрению (Графикон). -2010. -С. 169-174.
- Hawkins, J. Hierarchical temporal memory concepts, theory and terminology /J. Hawkins, D. George. -URL: http://www.nimenta.com/htm-overview/education/Numenta_HTM_concepts.pdf (дата обращения 19.11.2014).
- Bolotova, Yu.A. Analysis of hierarchically-temporal dependencies for handwritten symbols and gesture recognition/Yu.A. Bolotova, V.G. Spitsyn//Proceedings of 7-th International Forum on Strategic Technology (IFOST). -2012. -P. 1-6.
- Shridhar, M. License plate recognition using SKIPSM/M. Shridhar, F.M. Waltz, J.W.V. Miller, G. Houle, L. Bijnagte, R. Dibble//Proceedings of SPIE. The International society for Optical Engineering. -2001. -Vol. 4189. -P. 72-79.
- Kennady, C.N. A feature based approach for license plate recognition of Indian number plates/C.N. Kennady, S.T. Subramanian, K. Parasuraman//IEEE International Conference on Computational Intelligence and Computing Research. -2010. -P. 1-4.
- Dehshibi, M.M. Persian Vehicle License Plate Recognition Using Multiclass AdaBoost/M.M. Dehshibi, R. Allahverdi//International Journal of Computer & Electrical Engineering. -2012. -Vol. 4(3). -P. 355.
- Chang, S.-L. Automatic license plate recognition/S.-L. Chang, L.-S. Chen, Y.-Ch. Chung, S.-W. Chen//IEEE Transactions on Intelligent Transportation Systems. -2004. -Vol. 5(1). -P. 42-53.
- Sun, G. A new recognition method of vehicle license plate base on genetic neural network/G. Sun, C. Zhang, W. Zou, G. Yu//5th IEEE Conference on Industrial Electronics and Applications. -2010. -P. 1662-1666.
