Распознавание изображений с помощью искусственного интеллекта

Автор: Е. В. Хроль, К. С. Шаронова
Журнал: Современные инновации, системы и технологии.
Рубрика: Управление, вычислительная техника и информатика
Статья в выпуске: 3 (4), 2023 года.
Бесплатный доступ
В статье ставится задача рассмотрения процесса распознавания изображений с помощью сверточных нейронных сетей. Распознавание изображений — это ключевой компонент компьютерного зрения, который наделяет систему способностью распознавать и понимать объекты, места, людей, язык и поведение на цифровых изображениях. Системы с поддержкой компьютерного зрения используют алгоритмы распознавания изображений на основе данных для обслуживания широкого спектра приложений. В работе проведен анализ структуры рынка применения самых распространённых биометрических технологий в разных сферах бизнеса на отечественном рынке, а также сравнение с мировым рынком. Задача включает в себя рассмотрения сложностей, с которыми сталкивается машина при получении изображения для обработки, которые возможно отследить с помощью кривых обучения. Кривые обучения - отличный диагностический инструмент для определения смещения и дисперсии в контролируемом алгоритме машинного обучения. Поэтому понимание природы ошибок в обучении искусственного интеллекта в процессе распознавания изображений является необходимым знанием в современном мир, так как оно помогает избежать этапа повторного переобучения выборки.
Распознавание изображений, компьютерное зрение, кривые обучения, искусственный интеллект, сверточные сети, машинное обучение
Короткий адрес: https://sciup.org/14128904
IDR: 14128904 | УДК: 004.891.3 | DOI: 10.47813/2782-2818-2023-3-4-0311-0321
Текст статьи Распознавание изображений с помощью искусственного интеллекта
DOI:
В современном мире распознавание изображений нашло широкое применение в сфере информационных технологий, причем не только в управлении сложными машинными комплексами, но и в различных сферах бизнеса. Данное решение используется как при верификации личности пользователя с помощью отпечатка пальца, так и при поиске изображений в поисковых системах.
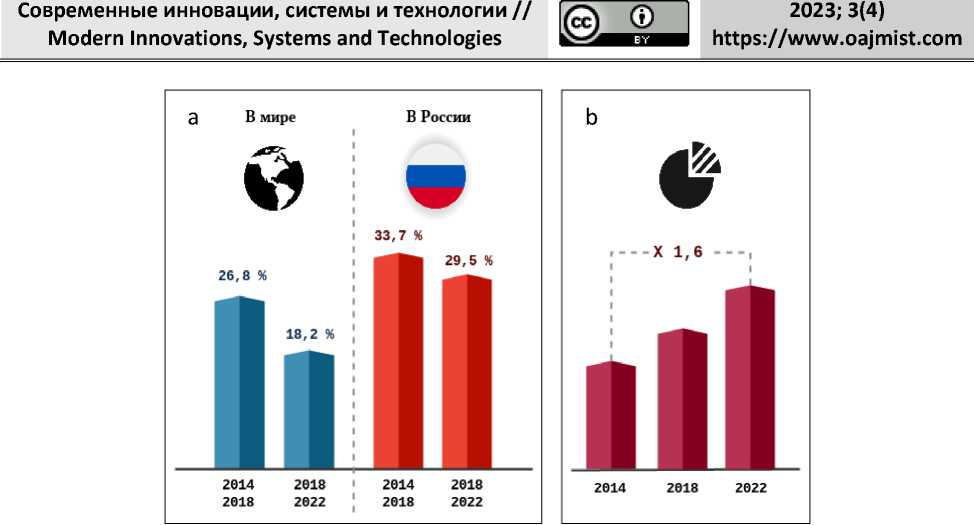
Рисунок 1. (а) Темпы роста мирового и российского рынка биометрии; (b) Доля России на глобальном рынке биометрии.
Figure 1. (a) Growth rates of the global and Russian biometrics market; (b) Russia's share in the global biometrics market.
Это свидетельствует о значительном потенциале и перспективах данной отрасли в России. Одним из ключевых факторов развития российского рынка биометрических технологий является платформа удаленной биометрической идентификации (ЕБС). Она создает безопасную среду для масштабирования рынка путем интеграции различных клиентских сценариев национального масштаба.
Структура российского рынка биометрических технологий отличается от мирового. В то время как в глобальном пространстве доминирующую долю продолжают занимать технологии Fingerprint (отпечатки пальцев), в России наблюдается активное проникновение технологии Facial Recognition (распознавание лица). За последние 3 года доля технологий распознавания лица в общем объеме российского биометрического рынка почти удвоилась и составила около 50%.
Это свидетельствует о растущей популярности и востребованности данной технологии среди потребителей и компаний. Одним из ключевых трендов развития рынка биометрических технологий в России является переход от внутрикорпоративного использования биометрии к активному освоению клиентскими сервисами. Этот тренд наблюдается практически во всех сферах, начиная от транспорта и спортивных объектов, где биометрия интегрируется с системами видеонаблюдения и билетными кассами, и заканчивая банковским сектором и розничной торговлей, где биометрические технологии используются для удаленной идентификации клиентов, платежных систем и персонализированных сервисов [2].
МАТЕРИАЛЫ И МЕТОДЫ
Кривая обучения является популярной концепцией в машинном обучении и относится к объему знаний или опыта, который необходим для того, чтобы иметь возможность изучать или использовать новый инструмент или технику. Она часто используется как показатель того, насколько проста или трудна задача, и может использоваться для сравнения различных методов обучения.
Путем анализа и программирования были объяснены различные типы кривых, с которыми сталкиваются при машинном обучении, а также сформулированы принципы их интерпретации для извлечения максимальной пользы из процесса обучения. К концу статьи у нас будут теоретические и практические знания, необходимые для того, чтобы избежать распространенных проблем при реальном обучении машинному обучению. Все кривые обучения описаны на языке Python и спроектированы на основе общедоступной базы данных «Real estate valuation data set». Набор рыночных исторических данных для оценки недвижимости собран в районе Синдиан, Нью-Тайбэй, Тайвань. "Оценка недвижимости" представляет собой регрессионную задачу. Набор данных был случайным образом разделен на набор обучающих данных (2/3 выборки) и набор данных тестирования (1/3 выборки).
Обучение означает пропускание небольших партий очищенных и аннотированных данных через усовершенствованную модель за определенное количество эпох. Эпоха — это количество раз, которое требуется алгоритму для обучения всему набору данных проекта. В течение первых нескольких эпох, алгоритм будет выдавать низкую точность и производительность сформированной модели, что является естественным результатом в начале обучения. Точно так же, как человеку нужно время для изучения нового языка, машине нужно время, чтобы разобраться в данных [3].
Есть две крайности, которых стоит избегать при обучении своего искусственного интеллекта, см. рисунок 3:
-
• Недостаточная подгонка возникает, когда количество эпох слишком мало. В результате алгоритм ML не может определить закономерности в предоставленных данных и не обеспечивает точных прогнозов.
-
• С другой стороны, переобучение происходит, если разработчики слишком много тренирует ИИ. Алгоритм ML обучается на конкретных примерах, но его основная задача - изучить общие концепции. Переоснащение приводит к ошибочным прогнозам из-за внимания, которое машина уделяет незначительным и не относящимся к делу деталям, см. рисунок 4. [4]
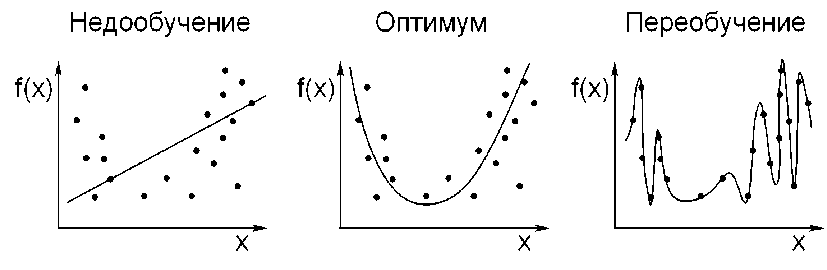
Рисунок 2. Последовательность алгоритма распознавания изображения ИИ.
-
Figure 2. Sequence of the AI image recognition algorithm.
Обучающие кривые — это графики, используемые для отображения производительности модели по мере увеличения размера обучающего набора. Другой способ их использования - показать производительность модели за определенный период времени. Обычно мы использовали их для диагностики алгоритмов, которые постепенно обучаются на основе данных. Это работает путем оценки модели на основе наборов данных для обучения и проверки, а затем построения графика измеренной производительности. Это означает, что на графике будут отображаться два разных результата:[5]
-
• Обучающая кривая: кривая, рассчитываемая на основе обучающих данных;
используется для информирования о том, насколько хорошо обучается модель.
-
• Кривая валидации: кривая, рассчитанная на основе данных валидации;
используется для информирования о том, насколько хорошо модель обобщается на невидимые экземпляры.
Эти кривые показывают нам, насколько хорошо модель работает в качестве данных растет, отсюда и название кривых обучения.
РЕЗУЛЬТАТЫ
Применим вышеуказанные метод с реальным набором данных, чтобы дать наглядное представление. Будет использована база данных: набор рыночных
Modern Innovations, Systems and Technologies исторических данных для оценки недвижимости. Эти данные были собраны в районе
Синдиан, Нью-Тайбэй, Тайвань, и состоят из рыночных исторических данных.[5]
Задача спрогнозировать оценку недвижимости с учетом следующих особенностей:
Таблица 1. Переменные рыночных исторических данных для оценки недвижимости.
Table 1. Variables of market historical data for real estate valuation.
|
Xn |
Значение переменной |
|
X1 |
Дата транзакции. |
|
X2 |
Возраст дома. |
|
X3 |
Расстояние до ближайшей станции метро. |
|
X4 |
Количество магазинов в шаговой доступности в living circle. |
|
X5 |
Географическая координата, широта. |
|
X6 |
Географическая координата, долгота. |
|
Y1 |
Цена дома за единицу площади. |
Цель, которая прогнозируется, непрерывна, поэтому для решения проблемы потребуются методы регрессии. Вот как выглядит окончательный набор данных перед разделением объектов и целевых меток:
Таблица 2. Набор данных.
Table 2. Data set.
|
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
Y |
|
|
0 |
2012.916667 |
32.0 |
84.87882 |
10 |
24.98298 |
121.54024 |
37.9 |
|
1 |
2012.916667 |
19.5 |
306.59470 |
9 |
24.98034 |
121.53951 |
42.2 |
|
2 |
2013.583333 |
13.3 |
561.98450 |
5 |
24.98746 |
121.54391 |
47.3 |
|
3 |
2013.500000 |
13.3 |
561.98450 |
5 |
24.98746 |
121.54391 |
54.8 |
|
4 |
2012.833333 |
5.0 |
390.56840 |
5 |
24.97937 |
121.54245 |
43.1 |
Чтобы продемонстрировать смещение, дисперсию и подходящие решения, будут построены три модели: регрессия дерева решений, метод опорных векторов для регрессии и случайный лес. После построения модели будут построены кривые обучения для каждой из них и поделимся некоторыми методами диагностики.[6]
Первая модель нелинейного алгоритма машинного обучения - регрессия дерева решений. Модель с высокой дисперсией отражает перегруженность. Она чрезвычайно хорошо изучает обучающие данные и случайный шум, что приводит к созданию модели, которая хорошо работает с обучающими данными, но не может быть обобщена на невидимые экземпляры. Такое поведение наблюдается, когда используемый алгоритм слишком гибок для решаемой задачи или когда модель обучается слишком долго.
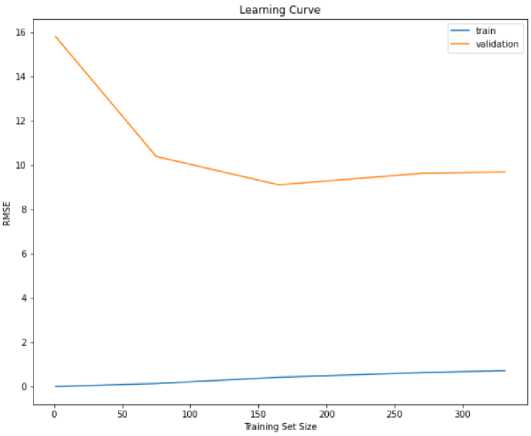
Рисунок 3. Модель регрессия дерева решений.
-
Figure 3. Decision tree regression model.
Модель допускает очень мало ошибок, когда требуется предсказать экземпляры, которые она видит во время обучения, но ужасно работает на новых экземплярах, с которыми она не сталкивалась. Вы можете наблюдать за этим поведением, замечая, насколько велика ошибка обобщения между кривой обучения и кривой проверки. Решением для улучшения этого поведения может быть добавление большего количества экземпляров в наш обучающий набор данных, что приводит к смещению. Другим решением может быть добавление регуляризации в модель (т. Е. ограничение роста дерева на всю глубину). [7]
Вторая модель линейного алгоритма машинного обучения – метод опорных векторов. Модель с высокой дисперсией отражает перегруженность. Модель с высокой погрешностью считается неподходящей. Она делает упрощенные предположения относительно обучающих данных, что затрудняет изучение лежащих в их основе шаблонов. В результате получается модель с высокой погрешностью в наборах данных для обучения и проверки. Можно наблюдать такое поведение, когда используемая модель слишком проста для решаемой задачи или когда модель обучается недостаточно долго.
Линейные алгоритмы обычно имеют высокую погрешность и низкую дисперсию. Это говорит о том, что делается больше предположений относительно формы целевой функции. Чтобы внести больше предвзятости в нашу модель, мы добавили регуляризацию, установив параметр C в нашей модели.
Продемонстрируем высокую погрешность с помощью нашей машины опорных векторов:
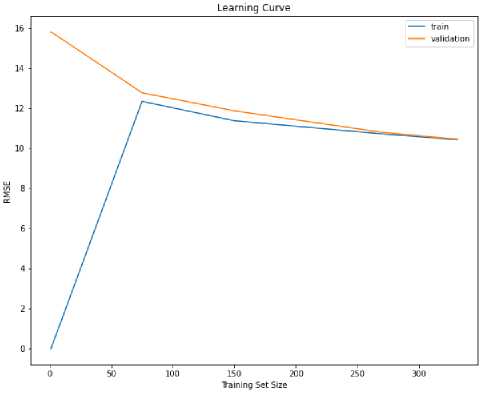
Рисунок 4. Модель метод опорных векторов.
-
Figure 4. Vector machine model.
Разрыв в обобщении кривой обучения и проверки становится чрезвычайно малым по мере увеличения размера обучающего набора данных. Это указывает на то, что добавление дополнительных примеров в нашу модель не улучшит ее производительность. Решением этой проблемы может быть создание большего количества функций или повышение гибкости модели, чтобы уменьшить количество сделанных предположений.
Третья модель – случайный лес. Модель хорошей подгонки существует в серой зоне между моделями недостаточной и избыточной подгонки. Модель, может быть, не так хороша для обучающих данных, как в экземпляре overfit, но она будет допускать гораздо меньше ошибок при работе с невидимыми экземплярами. Такое поведение можно наблюдать, когда ошибка обучения возрастает, но только до точки стабильности, по мере уменьшения ошибки проверки до точки стабильности. [7]
Случайный лес представляет собой совокупность деревьев принятия решений. Это означает, что модель также нелинейна, но смещение добавляется к модели путем создания нескольких различных моделей и объединения их прогнозов.
Также добавлена большая регуляризация, с помощью установления значение max_depth, которое управляет максимальной глубиной каждого дерева, равным трем.
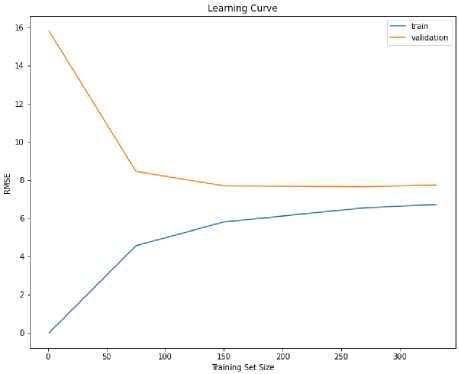
Рисунок 5. Модель случайный лес.
Figure 5. Random forest model.
Теперь вы можете видеть, что мы уменьшили ошибку в данных проверки. Это произошло за счет снижения производительности обучающих данных, но в целом это лучшая модель. Ошибка обобщения намного меньше, при этом совершается небольшое количество ошибок. Кроме того, обе кривые стабильны при размере обучающего набора более 250, что подразумевает, что добавление дополнительных экземпляров может не привести к дальнейшему улучшению этой модели. [8]
ЗАКЛЮЧЕНИЕ
Мы можем сделать вывод, что кривая обучения полезный инструмент, который позволяет избежать неграмотного обучения искусственного интеллекта. Вышеуказанные модели позволяют понять в каком именно аспекте обучения разработчики двигаются неправильно. Направление машинного обучения и искусственного интеллекта в настоящем времени является одной из самых бурно исследуемых направлений использования информационных технологий, поэтому данное исследование является важным для развития технологии компьютерного зрения не только в узконаправленных отраслях, но в простых задачах бизнеса.
