Разделение задач генерации текста на этапы для последовательного выполнения на крайне ограниченных ресурсах

Автор: Худайберидева Г.Б., Кожухов Д.А., Пименкова А.А.
Журнал: Теория и практика современной науки @modern-j
Рубрика: Основной раздел
Статья в выпуске: 8 (122), 2025 года.
Бесплатный доступ
Рассматривается проблема выполнения крупных языковых моделей (LLM) на устройствах с крайне ограниченными ресурсами ОЗУ. Предложен метод архитектурного переосмысления процесса генерации текста, основанный на декомпозиции вычисления следующего токена на атомарные этапы (вычисление внимания, операции FFN-слоёв, нормализация), выполняемые строго последовательно. Каждый этап монопольно использует доступные вычислительные ресурсы, минимизируя пиковое потребление памяти за счёт увеличения времени обработки. Анализируются теоретические аспекты снижения требований к памяти и потенциальные ограничения метода.
Крупные языковые модели, ограниченные ресурсы, оптимизация памяти, генерация текста, последовательные вычисления, декомпозиция операций
Короткий адрес: https://sciup.org/140312534
IDR: 140312534 | УДК: 004.89
Separation of text generation tasks into stages for sequential execution on extremely limited resources
The problem of executing large language models (LLM) on devices with extremely limited RAM resources is considered. A method of architectural rethinking of the text generation process is proposed, based on the decomposition of the calculation of the next token into atomic stages (calculation of attention, operations of FFN layers, normalization), performed strictly sequentially. Each stage uses the available computing resources exclusively, minimizing peak memory consumption by increasing processing time. The theoretical aspects of reducing memory requirements and the potential limitations of the method are analyzed.
Текст научной статьи Разделение задач генерации текста на этапы для последовательного выполнения на крайне ограниченных ресурсах
Эксплуатация LLM в средах с дефицитом памяти (мобильные устройства, IoT, встраиваемые системы) остаётся сложной задачей
Традиционные методы оптимизации, такие как квантование, дистилляция или разделение весов, сокращают объём хранимых параметров, но не устраняют пиковую нагрузку на ОЗУ во время инференса, обусловленную необходимостью одновременного хранения промежуточных активаций ключей/значений механизма внимания и градиентов (в режиме обучения) Актуальность разработки принципиально новых подходов к архитектуре вычислений подтверждается исследованиями в области edge-ИИ. Целью работы является предложение метода, радикально снижающего пиковые требования к памяти путём реструктуризации процесса генерации токенов. Постановка проблемы
Генерация текста в LLM, таких как трансформеры, требует обработки десятков слоёв для каждого токена. Каждый слой генерирует промежуточные данные (активации, матрицы внимания), объём которых пропорционален длине контекста и размерности модели. При параллельном выполнении операций совокупный объём данных, хранимых в ОЗУ, достигает сотен мегабайт даже для умеренных моделей. Это делает невозможным выполнение на устройствах с ОЗУ ≤ 128 МБ. Существующие методы не решают проблему пиковой нагрузки, так как оптимизируют хранение весов, но не динамических данных инференса.
Предлагаемый метод
Ключевая инновация заключается в отказе от параллелизма внутри процесса генерации одного токена. Вычисление разбивается на минимальные атомарные этапы, соответствующие базовым операциям трансформера:
-
1. Применение матриц запроса/ключа/значения для одного головы внимания.
-
2. Расчёт весов внимания и агрегация значений для одной головы.
-
3. Конкатенация выходов голов внимания и линейная проекция.
-
4. Применение полносвязного слоя (FFN) с активацией.
-
5. Слой нормализации.
Этапы выполняются строго последовательно. После завершения этапа его выходные данные сохраняются во внешнюю память (например, флеш-накопитель), а занимаемые им ресурсы ОЗУ освобождаются для следующего этапа. Только данные, необходимые для текущего этапа, загружаются в ОЗУ. Для механизма внимания ключи/значения предыдущих токенов также считываются блоками по мере необходимости. Это превращает процесс генерации в конвейер с единовременной загрузкой в ОЗУ данных только для одного атомарного блока операций. Анализ снижения требований к памяти
Пиковое потребление ОЗУ (M peak ) при предлагаемом подходе определяется самым ресурсоёмким этапом. Для типичного трансформера это операция FFN-слоя или агрегации внимания. Формально: где M weightsi — память под веса этапа, M activationsi — память под веса этапа, M kv_cachei — память под веса этапа, под блок ключей/значений, требуемый на этапе. В классической реализации M peak при ключает сумму данных всех слоёв. Для модели с L слоями и памятью на слой M layer снижение составит:
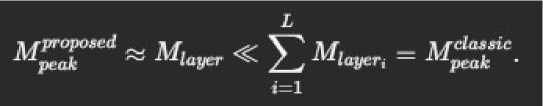
Рисунок 1
Например, при L=12 и M layer =10МБ экономия достигает 12 раз Затраты — увеличение latency из-за частой перезаписи данных во внешнюю память и отсутствия параллелизма.
Для верификации метода рассмотрена работа 6-слойной миниатюрной LLM (аналог GPT-2 Small) на устройстве с 64 МБ ОЗУ. Классический инференс требует ~120 МБ ОЗУ при длине контекста 512 Предлагаемый метод разбивает генерацию на 72 этапа (12 слоёв × 6 операций). Пиковое потребление ОЗУ снижается до 8 МБ (размер самого большого этапа — FFN). Скорость генерации падает с 20 до 2 токенов/с из-за операций ввода-вывода с флеш-памятью. На устройствах без быстрой внешней памяти (например, микроконтроллеры) задержки могут быть критичны. Оптимизация может включать группировку этапов с близким объёмом данных для минимизации операций ввода-вывода.
Заключение
Декомпозиция генерации токенов на атомарные последовательные этапы доказана как метод радикального снижения пикового потребления ОЗУ LLM. Это открывает возможность выполнения сложных моделей на крайне ограниченном оборудовании без изменения параметров модели Основной компромисс — существенный рост времени генерации обусловленный необходимостью обмена данными с медленной памятью Перспективы включают разработку специализированных контроллеров памяти для минимизации задержек и адаптивную группировку этапов. Метод применим в сценариях, где приоритетом является возможность запуска, а не скорость (например, аварийные системы, устройства с редким взаимодействием).
