Разработка инструментария для интеллектуального анализа технической документации

Автор: Наместников А.М., Филиппов А.А., Субхангулов Р.А.
Журнал: Известия Самарского научного центра Российской академии наук @izvestiya-ssc
Рубрика: Современные технологии в промышленности, строительстве и на транспорте
Статья в выпуске: 4-4 т.13, 2011 года.
Бесплатный доступ
Данная статья является результатом исследования возможности применения онтологического подхода к индексированию и кластеризации технических документов машиностроительной отрасли. В работе рассмотрен процесс создания предметно-ориентированной онтологии, модели концептуального индекса проектного документа и модифицированного fcm-метода кластеризации концептуальных индексов.
Онтология, концептуальный индекс, кластеризация, проектный документ
Короткий адрес: https://sciup.org/148200300
IDR: 148200300 | УДК: 681.3
Development of toolkit for the intellectual analysis of engineering specifications
Given article is a result of researching the possibility of application the onthologic approach to codeindexing and clusterization of technical documentation in machine-building branch. In work the process of creation the subject-oriented onthology, models of conceptual index of design document and the updated fcm-method in clusterization the conceptual indexes is considered.
Текст научной статьи Разработка инструментария для интеллектуального анализа технической документации
-
• слова текста считаются независимыми друг от друга, что не соответствует словам связанного текста;
-
• многозначность слов – поскольку многозначные слова могут рассматриваться как дизъюнкция двух или более понятий, выражающих различные значения многозначного слова, то маловероятно, что все элементы этой дизъюнкции интересуют пользователя.
Этих недостатков лишено так называемое концептуальное индексирование, то есть такое индексирование, когда текст индексируется не по словам [1], а по понятиям, которые обсуждаются в данном тексте. При такой технологии
-
• все синонимы сведены к одному и тому же понятию,
-
• многозначные слова отнесены к разным понятиям,
-
• связи между понятиями и соответствующими словами (терминами) описаны и могут быть использованы при анализе документа.
Результатом концептуального индексирования проектного документа (ПД) в интеллектуальном проектном репозитории (ИПР) машиностроительного предприятия будем считать такое описание ПД, которое состоит из множества понятий с соответствующими степенями выраженности данных понятий в документе. Исходный ПД d поступает на вход анализатора структуры проектного документа, который на основе данных структурного уровня онтологии интеллектуального проектного репозитория выделяет отдельные структурные единицы, которые являются неделимыми (раз-d делы, не имеющие подразделов), sj , j — раздел ПД d. По каждому такому разделу концептуальный индексатор формирует свой индекс на основе состава понятий и терминов, связанных с понятиями в онтологии ИПР. Основу концептуального индексатора составляет следующая функция:
Fa : s' ^ cl j
где cI d — концептуальный индекс j -го раздела ПД d .
Концептуальный индекс каждого раздела ПД поступает на вход синтезатора концептуального индекса проектного документа. Аналитически он может быть представлен следующей функцией преобразования [3]:
Fsyn : {clj } ^ cId где cId — концептуальный индекс ПД d.
Непосредственно модель концептуальной индексации будем представлять с использованием теории графов. В онтологии ИПР каждый термин wt е W связан с понятиями C j е C отношением ассоциации ra : wiRAc j . Понятия C связаны друг с другом отношениями обобщения, образуя таксономию понятий предметной области. Понятийный уровень онтологии интеллектуального проектного репозитория можно представить в виде ориентированного графа:
G = ( C,E )
где С - множество вершин графа, каждая вершина - это понятие онтологии; E - множество дуг вида E = { ci,ck )} , для всех c i ,c k е C , для которых имеет место отношение c i R G c k . Реализацию функции концептуального индексатора будем представлять в виде следующего алгоритма:
Шаг 1. Вычисление степеней выраженности понятий в разделе документа. Каждое отношение ассоциации между термином w и понятием c j имеет вес, который характеризует частоту встречаемости термина W в описании понятия c j . Такой вес определяется в процессе формирования текстового входа каждого из понятий ИПР для каждого отношения ассоциации между термином и понятием. Терминологическая составляющая j -го раздела ПД записывается в виде множества пар «термин-частота»:
Wjpfi^.^ Wjpf^.: , (wjpf/)} vx 1J 1 / \ 2 J J 2 / \ ljj J lj , где lj — количество выделяемых терминов в j-м разделе ПД.
Текстовый вход W k понятия c k представим следующим образом:
kk kk kk
{( w 1 ,f ! )( w 2 ,f 2 , ( w k ,f k )}
, где 1к — количество терминов текстового входа к-го понятия.
Степень выраженности понятия c k в j -м разделе ПД d будем вычислять по следующей формуле:
М d (ck) = 1 - T^lfS - fsj I
sj l k s= 1
где sj - j-й раздел проектного документа d; fsj ,fk - частоты встречаемости термина s в j-м разделе документа и в описании k-го понятия онтологии соответственно; lk - мощность текстового входа понятия ck . В том случае, если термин s отсутствует в j-м разделе документа d, тогда f принимается равным нулю.
Шаг 2. Определение значимых понятий. Степень выраженности каждого понятия, вычисленная по формуле 4, сравнивается с пороговым значением параметра п = [0,1]. Если Msd C) “ п, тогда понятие ck включается в состав концептуального индекса раз-d дела sj со своей степенью выраженности.
Шаг 3. Формирование концептуального индекса. Зная состав значимых понятий со степенями выраженности, концептуальный индекс j -го раздела ПД d формируется как нечеткий граф следующего вида:
сГ = ( C,E )
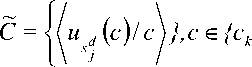
u d ( c k ) ^ n ' , sj
{ c i ,c k } }>cc,>ck) е CC
где
E=
Очевидно, что концептуальный индекс cId является вершинным подграфом графа G, определяемого выражением 3. Поскольку в общем случае в концептуальном индексе могут отсутствовать любые понятия из состава понятий онтологии ИПР, результирующий граф концептуального индекса cI dj может состоять из несвязанных деревьев и/или изолированных понятий.
Функция синтезатора концептуального индекса ПД FSYN (2) состоит в объединении отдельных концептуальных индексов, соответствующих разделам ПД. Такое объединение выполняется поэтапно «снизу-вверх» и соответствует структуре ПД. Иерархия разделов и подразделов ПД зафиксирована в онтологии ИПР на структурном уровне (S). Поскольку в процессе интеллектуального анализа содержимого проектного репозитория может потребоваться рассмотрение не только отдельно взятых ПД, но и их разделов (например, произвести сравнительную оценку функциональных требований из разных технических заданий), синтез концептуального индекса ПД выполняя-ется по следующему алгоритму:
-
1. Объединение концептуальных индексов разделов, соответствующих листовым вершинам самого нижнего уровня дерева структуры ПД.
-
2. Если не достигнута корневая вершина дерева структуры ПД, то объединение концептуальных индексов выполняется на текущем уровне иерархии и осуществляется переход к п.3, иначе – к п.4.
-
3. Перейти на шаг выше по иерархии ПД и выполнить п.2.
-
4. Произвести объединение концептуальных индексов, полученных на предыдущем шаге алгоритма, сформировав таким образом концептуальный индекс ПД, и остановить процесс синтеза.
Пусть cIi d и cI d j - концептуальные индексы i -го и j -го разделов ПД d соответственно. Объединение cIi d и cI d j определим как объединение нечетких графов:
cI id ∪ cI dj = ( C i , E i ) ∪ ( C j , E j ) = ( C i ∪ C j , E i ∪ E j ) причем
C~i ∪C~j = {µd(c)∨µd(c)/c}, j si s j c∈{ck :µd(ck)≥η}∪{cm :µd(cm)≥η}. si m s j m
Другими словами, объединение концептуальных индексов есть объединение вершин и дуг нечетких графов, которые их представляют. При этом результирующая степень выраженности понятия есть дизъюнкция исходных степеней. В частности, для нечеткой интерпретации можно записать следующим образом:
~~
Ci ∪Cj = {max(µd(c) ∨ µd(c)) /c}, si s j c∈{ck :µd(ck)≥η}∪{cm :µd(cm)≥η}. si m s j m
Таким образом, получаем, что ПД в ИПР представляется не в лексическом пространстве терминов, которые удается выделить в документе, а в пространстве понятий предметной области, которые зафиксированы в онтологии ИПР.
Модифицированный метод кластеризации концептуальных индексов. Fuzzy c-means (FCM) является методом кластеризации, который позволяет одному объекту принадлежать двум или более кластерам с определенной степенью принадлежности. Этот метод (разработанный J.C. Dunn в 1973 г. и улучшенный J.C. Bezdek в 1981 г.) часто используется при решении задачи распознавания образов. Алгоритм основан на минимизации следующей целевой функции:
NC 2
Jm = ∑ ∑uimj IIcIi - cIcj II 2 ,1 ≤ m < ∞ i=1 j=1
где N – количество концептуальных индексов для кластеризации, C – количество кластеров, m – любое действительное число больше 1, u ij
– степень принадлежности концептуального индекса cIi кластеру j , cI i – i -ый концептуальный индекс, cI cj – центр j -го кластера, ||*||
– нормализованное расстояние между концептуальным индексом и центром кластера. Так как структура для всего набора концептуальных индексов одинакова (в случае нахождения меры сходства содержимого – являются нечеткими вершинными подграфами одного и того же графа – онтологии ИПР, в случае нахождения меры сходства структуры – добавляются недостающие вершины), будем рассматривать нечёткий граф концептуального индекса, как вектор, содержащий значения понятий и их степеней выраженности, либо метки разделов со значениями структурных индексов данных разделов.
FCM алгоритм состоит из следующих шагов:
Шаг 1. Инициализация. Задаются параметры кластеризации и инициализируется первоначальная матрица принадлежности концептуальных индексов кластерам U = [ uij ] .
Шаг 2. Вычисление центров кластеров.
Вычисляется новое значение центров
кластеров:
N z um * cii cIj=— z um i=1
Шаг 3. Формирование новой матрицы принадлежности. Формируется новая матрица принадлежности с учетом вычисленных на предыдущем шаге центров кластеров:
u
ij
C z l = 1
V
ci i - cl j ci- cI l
m - 1
где u ij – степень принадлежности i -го концептуального индекса кластеру j , cI cj – концептуальный индекс центра j -го кластера, cI lc – концептуальный индекс центра l -го кластера.
Шаг 4. Вычисление целевой функции. Вычисляется значение целевой функции, и полученное значение сравнивается со значением на предыдущей итерации. Если разность не превышает заданного в параметрах кластеризации порогового значения, считаем, что кластеризация завершена. В противном случае переходим ко второму шагу алгоритма. Для определения расстояния между содержимым ПД в ИПР необходимо измерить степень близости, похожести между концептуальными индексами ПД. В рамках данного исследования можно выделить две меры сходства ПД: мера сходства содержимого ПД; мера сходства структур ПД.
Будем рассматривать концептуальный индекс ПД как иерархию. Тем самым, расстояние между содержимым ПД находится через сложность превращения одной иерархии в другую, путем вычисления разности между степенями выраженности понятий, имеющих одинаковые метки (имя) [2]. Рассмотрим определение понятия иерархия , представленное в работе [2]. Обозначим через W конечное множество объектов, W = w 1 , w2,..., w l ,..., w q , а через H – множество непустых частей множества W , называемых таксонами и обозначаемых через h . Иерархией H множества W называется множество подмножеств W таких, что:
• V w e W { w} e H (терминальные вершины (листья) – одноэлементные множества);
-
• W e H (наибольший таксон (корень)
содержит все элементы W );
-
• для любых вершин h, h ' e H мы имеем либо h n h ' = 0 , либо h c h ' , либо h ' c h .
Таким образом, иерархия – это многоуровневая структура, в которой объекты, находящиеся в одном таксоне на некотором ( j -м) уровне, остаются в одном таксоне на ( j +1)-м и всех других более высоких уровнях. Первому уровню соответствуют терминальные вершины (п. 1 в определении иерархии), а последнему, максимальному, уровню обозначим его через m ) – наибольший таксон, содержащий все элементы W ; этот таксон можно обозначить тем же символом W (п. 2 в определении иерархии). На каждом уровне происходит или не происходит объединение таксонов (п. 3 в определении иерархии).
Практическая реализация интеллектуального проектного репозитория. Для решения задачи кластеризации концептуальных индексов проектных документов была выполнена работа над программной реализацией ИПР. Языком разработки был выбран язык Java. В качестве хранилища исходных и проиндексированных документов используется XML-ориентированная СУБД Tamino (Software AG), доступ к которой осуществляется с помощью Tamino API. В качестве хранилища онтологий используется Java фреймворк Sesame в связке с веб-сервером Apache Tomcat. Структура приложения представлена на рис. 1.
Для построения онтологии интеллектуального проектного репозитория было выбрано хранилище Sesame - открытая (open source) база данных RDF с поддержкой логического вывода по RDF-тройкам и запросов. Оно предлагает большой набор инструментов для разработчиков для использования RDF и RDF Schema. Рассмотрим пример части онтологии ИПР. В онтологии представлены описания понятий, терминов, из которых состоят понятия, и их отношения. В рассматриваемой онтологии
-
• понятия описываются с помощью класса
, -
• термы с помощью класса
, -
• концепт-термы (объекты, представляющие отношения между понятиями и термами) с помощью класса
, -
• отношения между понятиями с помощью свойства
-
• отношения между концепт-термами и понятиями с помощью свойства
,
-
• отношения между концепт-термами и термами с помощью свойства
,
-
• относительная частота встречаемости терма в понятии с помощью свойства
.
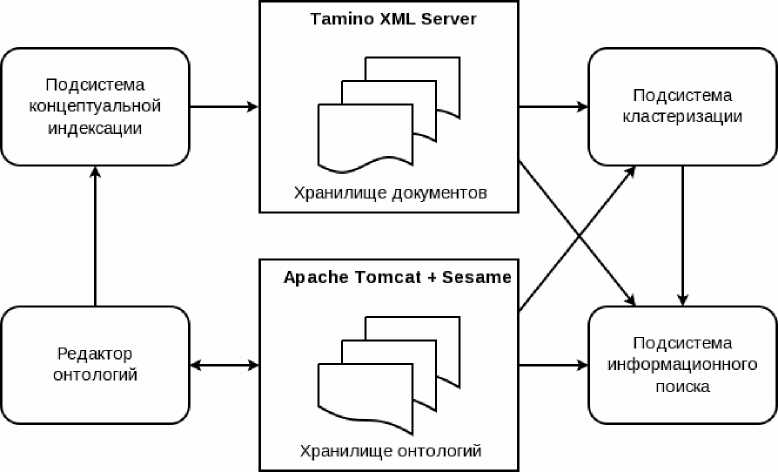
Рис. 1. Архитектура ИПР
Этапы индексации проектных документов:
-
• загрузка документов;
-
• анализ структуры документов;
-
• удаление стоп-слов;
-
• стемминг;
-
• подсчёт относительной частоты встречаемости термов;
-
• расчёт степени выраженности понятий;
-
• построение концептуальных индексов для разделов и документов.
Для работы с xml документами используется SAX-парсер («Simple API for XML») из стандартной поставки Java. Для реализации функции стемминга используется стеммер Snowball. Стемминг – это процесс нахождения основы слова для заданного исходного слова. В результате работы механизма стемминга получается документ, состоящий из термов. Под термом стоит понимать лексическую единицу, полученную в результате процесса стемминга.
Для работы с графом был разработан класс JGraph. Методы данного класса позволяют добавлять и удалять вершины из графа, а также устанавливать степень выраженности каждой вершине. Также существует возможность сохранять и загружать граф из XML файла. Ниже представлен пример XML файла, содержащего граф:
parent="ROOT" />
value="0.7" parent="система" />
value="0.3" parent="система" />
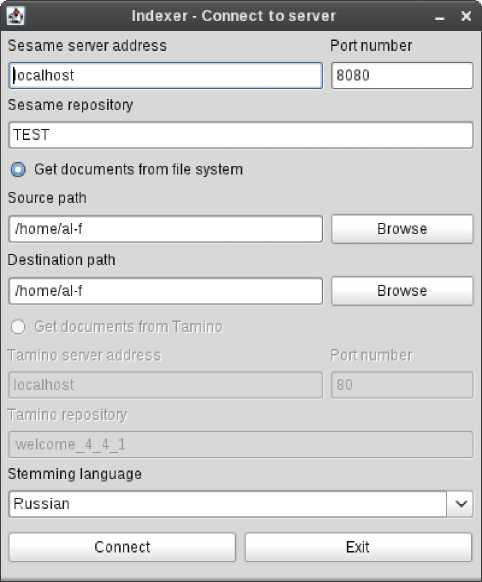
value="0.1" parent="информационная система" /> . Ниже представлены основные экранные формы подсистемы концептуальной индексации ПД (рис. 2, 3) и подсистемы нечеткой кластеризации концептуальных индексов ПД (рис. 4).
Рис. 2.
Диалоговое окно настройки подсистемы концептуальной индексации
Выводы:
разработанные модели и методы нечеткого индексирования и кластеризации проектных документов машиностроительного предприятия позволяют использовать онтологическое описание предметной области в качестве средства управления процессом интеллектуального анализа проектных документов. Результаты концептуального индексирования и кластеризации проектных документов определяются тем набором понятий предметной области, который представлен в онтологии. Экспериментальные исследования с разработанными программными модулями редактирования онтологии, концептуального индексирования и кластеризации подтверждают адекватность представленных в статье теоретических моделей.
Список литературы Разработка инструментария для интеллектуального анализа технической документации
- Наместников, А.М. Интеллектуальный сетевой архив электронных информационных ресурсов/А.М. Наместников, А.В. Чекина, Н.В. Корунова//Программные продукты и системы. 2007. № 4. С. 10-13.
- Загоруйко, Н.Г. Прикладные методы анализа данных и знаний. -Новосибирск: ИМ СО РАН, 1999. 270 с.
- Наместников, А.М. Концептуальная индексация проектных документов/А.М. Наместников, А.А. Филиппов//Автоматизация процессов управления. 2010. №2(20). С. 34-39.
