Разработка языка анализа телеметрической информации

Автор: Махалов Д.А.
Журнал: Космическая техника и технологии @ktt-energia
Рубрика: Системный анализ, управление и обработка информации, статистика (технические науки)
Статья в выпуске: 3 (42), 2023 года.
Бесплатный доступ
В статье рассматривается разработанный в Центре управления полётами язык программирования, предназначенный для подготовки подпрограмм анализа телеметрической информации. Язык основан на современных языках программирования и содержит специальные средства для оперирования телеметрическими значениями. В статье приводится описание уникальных элементов языка, даются примеры программного кода. Для разработанного языка реализованы транслятор и интерпретатор, которые внедрены в телеметрический информационно-вычислительный комплекс Центра управления полётами и используются для телеметрического обеспечения управления полётом Российского сегмента Международной космической станции и других космических аппаратов.
Телеметрическая информация, язык программирования, обработка, анализ
Короткий адрес: https://sciup.org/143180348
IDR: 143180348 | УДК: 004.434:621.398
Developing a language for telemetry data analysis
The paper discusses a programming language developed at the Mission Control Center for preparing subroutines to analyze telemetry data. The language is based on modern programming languages and includes specialized tools for telemetry data handling. The paper provides a description of unique language elements, and examples of source code. Implemented for the language were a compiler and an interpreter, which were adopted by the telemetry data processing system at the Mission Control Center, and are used for telemetry support in controlling the missions of the Russian Segment of the International Space Station and other spacecraft.
Текст научной статьи Разработка языка анализа телеметрической информации
Обработка телеметрической информации (ТМИ) является одним из ключевых элементов обратной связи процесса управления полётами космических аппаратов (КА). В общем случае на вход программы обработки ТМИ поступает поток телеметрических кадров, принятых наземными приёмно-регистрирующими станциями. В процессе обработки выполняется раском-мутация этих кадров на отдельные значения телеметрических (ТМ) параметров, сборка массивов цифровой и регистровой информации. Осуществляется повышение достоверности и сокращение избыточности значений ТМ-параметров, перевод их в физические величины, приписывание текстовых значений, формирование обобщённых значений, различные формульные вычисления и автоматизированный анализ ТМИ.
В Центре управления полётами (ЦУП) ЦНИИмаш обработка выполняется совокупностью алгоритмов, организованных в виде направленного графа. На вход каждого алгоритма поступают значения ТМ-параметров и времени, на выходе формируются значения данных ТМ-параметров в физических единицах и (или) формируются значения обобщённых (производных от исходных) параметров. Алгоритмы подразделяются на базовые [1], используемые в различных КА, и специализированные. Преобразование значений ТМ-параметров с помощью базовых алгоритмов описано в работе [2]. В настоящей статье рассматривается разработанный язык программирования, предназначенный для задания специализированных алгоритмов обработки ТМИ — алгоритмов анализа ТМИ. Такие алгоритмы применяются на всех стадиях обработки ТМИ для выполнения преобразований, выходящих за рамки базовых алгоритмов, и решают следующие задачи:
-
• оценки и декодирования поступающих ТМ-кадров;
-
• сборки и обработки цифровых массивов, поступающих от бортовых вычислительных систем, аппаратуры спутниковой навигации и научной аппаратуры;
-
• формирования текстовых протоколов событий;
-
• сравнения поступающей ТМИ с эталонной;
-
• учёта наработки бортовых систем и др.
Синтаксис языка анализа ТМИ основан на синтаксисе популярных языков программирования С ++, C #, Java , а также содержит специальные средства, предназначенные для обработки ТМИ. Подпрограммы на языке анализа оперируют значениями, содержащими различные атрибуты, такие как время, достоверность, режим передачи, единицы измерения и др. При разработке языка анализа ТМИ, средств трансляции и интерпретации использовались материалы монографии [3]. В статье приводится описание отдельных элементов языка в виде грамматики в расширенных формах Бэкуса–Наура [4]. Для наглядности терминальные символы выделены коричневым цветом, нетерминальные — синим, комментарии — зелёным.
1. Организация обработки и анализа ТМИ
Задание на обработку и анализ ТМИ каждого КА в ЦУП готовится в текстовом виде на специальном декларативном языке подготовки исходных данных [2]. В этом языке ТМ-параметрам сопоставляются цепочки алгоритмов обработки, для каждого из которых задаются его атрибуты и коэффициенты, к которым относятся, например, коэффициенты масштабирования, формулы преобразования значений, названия физических единиц измерения ТМ-параметров, текстовые константы и т. п. Для алгоритмов анализа атрибутом является исходный код подпрограммы на языке анализа ТМИ. Такой подход позволяет интегрировать специализированные алгоритмы в цепочки обработки наравне с базовыми алгоритмами, т. е. подавать на вход обычным алгоритмам обработки результаты анализа, и наоборот:
ПАР1, ПАР2, ПАР3 = АЛГ1(_), АЛГ2(_);
В приведённом примере телеметрическим параметрам ПАР1, ПАР2, ПАР3 приписывается цепочка из двух алгоритмов обработки АЛГ1, АЛГ2. Вместо многоточия указываются атрибуты конкретного алгоритма — тело алгоритма.
При трансляции задания на обработку транслятор конвертирует атрибуты базовых алгоритмов в структуры их внутреннего представления, а атрибуты алгоритмов анализа — в байт-код, который затем интерпретируется программой обработки подобно виртуальным машинам в современных языках программирования.
Такой подход к обработке ТМИ позволил создать универсальное программное обеспечение, реализующее транслятор и интерпретатор задач анализа, а всю логику вычислений, требуемых при анализе ТМИ, задавать в виде исходных данных для задач анализа.
В каждой подпрограмме анализа перечисляются входные и выходные ТМ-параметры с указанием типа их значений. При поступлении нового значения одного из входных ТМ-параметров программа обработки ТМИ осуществляет выполнение байт-кода подпрограммы, передавая ему поступившее значение. Помимо поступающих значений входных параметров инициировать вызов подпрограммы анализа также могут различные события, например сигналы текущего времени.
-
2. Синтаксис алгоритмов анализа
-
2.1. Общий синтаксис алгоритмов анализа
-
-
2.2. Типы данных
Транслятор и интерпретатор подпрограмм на языке анализа ТМИ встроены в язык подготовки исходных данных для обработки ТМИ телеметрического информационно-вычислительного комплекса ЦУП в виде отдельного алгоритма обработки ТМИ. Алгоритм получил название ПРОЦЕДУР^ в силу того, что более подходящее имя ^Н^ЛИЗ было занято более ранней версией анализа, использовавшейся в комплексе. После имени алгоритма в круглых скобках описывается его тело:
Процедура = "ПРОЦЕДУР^ ( ",
Заголовок,
Объявление функций, Главная функция, ")";
Подпрограмма анализа состоит из трёх основных частей: заголовок, объявление функций и главная функция. В части Заголовок указывается способ запуска подпрограммы, перечисляются входные и выходные параметры, локальные переменные, объявляются пользовательские типы подпрограммы. Главная функция представляет из себя функцию без имени и аргументов — блок кода, заключённый в фигурные скобки. Главная функция вызывается при поступлении каждого значения каждого входного параметра (либо по условиям, указанным в заголовке подпрограммы).
Помимо базовых типов данных, основанных на типах языка C #, язык анализа поддерживает следующие специальные типы данных:
-
• КОД — кодовый тип, занимающий 9 байт, из них 8 байт (64 бита) отводятся под значение кода и 1 байт (8 бит) — под длину;
-
• M^C^H — массив анализа, особый тип массивов, содержащий дополнительную информацию о данных, предназначенную для передачи из одного алгоритма в другой;
-
• ТЕКСТ^Н — текст анализа, передающий текстовые сообщения в различных форматах;
-
• ASCII — тип коротких текстовых сообщений;
-
• КОРТЕЖ — неименованная совокупность элементов разных типов.
На объекты базовых типов с помощью символа «*» можно создать указатель, содержащий адрес объекта. По аналогии с языком C ++ допускается также создание ссылки на объекты базовых типов с помощью символа «&».
Локальным переменным, входным и выходным параметрам подпрограммы анализа назначаются конкретные типы данных. Для входных и выходных параметров доступны только те из описанных типов, которые совместимы с типами телеметрических параметров: byte, ushort, int, uint, long, ulong, double, M^C^H, ТЕКСТ^Н, ASCII, КОД. В качестве примера приведём грамматику объявления входных параметров подпрограммы:
Заголовок входных параметров = "ВХП^Р(",
Входной параметр, { ",", Входной параметр }, ")";
Входной параметр =
( "СТРУКТ" | Тип ),
( Имя | "ПРИШЕДШИЙ" ), [ "[ ]" ],
[ "AS", Имя2 ],
[ "=" Выра^ение ];
Отдельно стоит отметить возможность указать один и тот же телеметрический параметр с разными типами. В некоторых подпрограммах возникает необходимость принимать значения параметра с одним типом, а на выходе формировать с другим (например, на входе поступают целочисленные кодовые значения, а на выходе — вещественные). Либо для одного параметра на выходе подпрограммы могут поочерёдно формироваться значения разных типов. Для таких случаев после объявления параметра указывается ключевое слово AS, после которого параметру даётся альтернативное имя.
Ключевое слово СТРУКТ используется для объявления структурных параметров, которые на уровне описания телеметрического борта в исходных данных содержат дочерние параметры. Такие параметры можно включить в подпрограмму сразу со своими дочерними параметрами, к которым теперь можно обращаться как по имени, так и индексируя структурный параметр как массив.
Ключевое слово ПРИШЕДШИЙ позволяет объявить входной параметр, не указывая его имени в том случае, если он единственный. Тогда в тексте подпрограммы к нему также следует обращаться через это ключевое слово, а получившийся алгоритм можно будет приписать сразу нескольким параметрам:
П^Р1, П^Р2 = ПРОЦЕДУР^(
ВХП^Р(int ПРИШЕДШИЙ)
{ … });
-
2.3. Литеральные константы
-
2.4. Инструкции
Синтаксис задания литеральных констант в языке анализа аналогичен синтаксису языка C #. Кроме того, язык поддерживает задание даты и времени, которые сохраняются в виде чисел типа uint во внутренней системе отсчёта. В табл. 1 даны описания и примеры задания литеральных констант.
Тело любой функции подпрограммы на языке анализа, включая главную функцию и методы пользовательского типа, представляет собой последовательность инструкций, заключённую в фигурные скобки.
Инструкции бывают следующих видов:
-
• блок инструкций в фигурных скобках;
-
• пустая инструкция, состоящая из символа «;» или символов «{ }»;
-
• объявление локальной переменной;
-
• управляющая конструкция;
-
• выражение:
– присваивание;
– арифметическое выражение;
– вызов функции или алгоритма;
– выражение инкремента или декремента.
-
2.5. Операторы
Таблица 1
Описания и примеры задания литеральных констант
|
Название |
Описание |
Примеры |
|
Строковая (текстовая) |
Задаётся в кавычках « " » и может содержать базовые escape -последовательности для обозначения непечатных символов |
"Mассив сверок", "Номер\tЗначение\tВремя" |
|
Символьная |
Задаётся в апострофах « ' » |
'A', '\", '\\' |
|
Вещественная |
Может задаваться в десятичной и экспоненциальной формах с точкой в качестве разделителя дробной части. Либо целое число с суффиксом «d» |
–1.5 1E6 0.7292115853e-4 100d |
|
Целочисленная |
Содержит последовательность цифр без точки. Шестнадцатеричные начинаются с «0x». Двоичные начинаются с «0b». Суффикс «L» задаёт константу типа long |
4 0x1FF 0b10111111 32768L |
|
Логическая |
Название логического значения |
true, false |
|
Дата |
Константа в формате «дд.мм.гг» или «дд.мм.гггг» |
24.02.22 20.11.1998 |
|
Время |
Константа в формате «чч:мм:сс» или «чч:мм:сс.МММ» |
03:00:00 17:58:24.958 |
Для оперирования числовыми выражениями используются операторы, аналогичные операторам языка C #. Операторы выполняют преобразования над выражениями, которые могут иметь следующие характеристики:
-
• r-value выражение, значения которого можно читать, т. е. можно использовать справа от знака присваивания;
-
• l-value выражение, которому можно присваивать значения;
-
• инициализированная переменная — локальная переменная, которой было присвоено значение;
-
• инициализированный ТМ-параметр, значение которого поступило в подпрограмму или было сформировано в этой подпрограмме;
-
• инициализированное выражение, которое имеет определённое значение, полученное путём выполнения операций с инициализированными переменными или ТМ-параметрами. Результат выполнения любой операции, в которой хотя бы один аргумент является неинициализированным выражением, также является неинициализированным выражением.
Дополнительно к стандартным операторам введены операторы взятия битового поля и объединения битовых полей.
Оператор взятия битового поля определяется как объект[НП:ДП] или объект[НП].
Здесь объект принадлежит к одному из целочисленных типов; НП — начало поля, отсчитывается от нулевого, младшего разряда; ДП — длина поля в битах (рис. 1). Если длина поля не указана, оператор извлекает 1 бит.
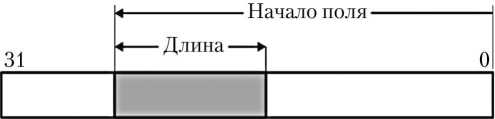
Рис. 1. Битовое поле в 32-разрядном значении [5]
Оператор порождает объект типа КОД, содержащий значение и длину поля.
Объединение битовых полей определяется как объект1[НП1:ДП1] $ объект2[НП2:ДП2]
и порождает объект типа КОД со значением, сформированным путём конкатенации битовых полей, и длиной, равной
ДП1+ДП2. Кроме битовых полей операндами оператора объединения могут выступать любые целочисленные переменные выражения, длина которых в битах определяется автоматически.
В задачах обработки ТМИ оперирование кодовыми выражениями является весьма распространённым, и введённые в язык операции существенно сокращают записи, повышают читаемость кода, снижают вероятность допущения ошибки. Практическое исследование показало, что операции взятия битового поля и объединения битовых полей сокращают соответствующие выражения на 17–39%. В табл. 2 приведено несколько примеров таких выражений из реальных подпрограмм анализа ТМИ, записанных в традиционном коде и с использованием новых операций.
Таблица 2
Примеры выражений из реальных подпрограмм анализа ТМИ в традиционном и новом кодах
|
Традиционный код |
Новый код |
|
БВС-П^К[7] >> 16 & 0x03FF |
БВС-П^К[7][25:10] |
|
(((ulong)БВС-П^К[2] & 0x00FFFFFF) << 16) | (БВС-П^К[3] >> 16) |
(ulong)БВС-П^К[2][23:24] $ БВС-П^К[3][31:16] |
|
(data[index + 6] << 24) | (data[index + 7] << 16) | (data[index + 8] << 8) | data[index + 9] |
data[index + 6] $ data[index + 7] $ data[index + 8] $ data[index + 9] |
|
if ((data[index] & 0x0080) == 0) |
if (data[index][7] == 0) |
-
2.6. Управляющие конструкции
К управляющим конструкциям относятся: if, if – else, for, switсh, break, continue, return.
Дополнительно введена конструкция кодового выбора codeswitсh, определяемая синтаксисом:
Инструкция codeswitch =
"codeswitch", Основание, "(", Выра^ение, ")", "{",
{ Вариант кодового выбора },
[ "else:", Инструкция ],
Основание = "Б" | "В" | "Ш";
Вариант кодового выбора =
Кодовое значение, ":", Инструкция;
Кодовое значение = {Цифра Б} -1 {Цифра В}- |{Цифра Ш}-;
Цифра Б = "0"|"1"|"-"; (* бинарные *)
Цифра В = "0".."7"|"-"; (* восьмеричные *)
Цифра Ш = "0".."9"|"A".."F"|"-"; (*шестнадцатеричные *)
В этой конструкции Выра^ение должно вырабатывать значение кодового типа, альтернатива else может отсутствовать. В отличие от классической конструкции switch, в данной конструкции в качестве символов кодового значения допускается символ безразличного состояния (символ «–»). Разряды, помеченные символом «–», не оцениваются. В конструкции значение выражения последовательно сопоставляется с кодовыми значениями, и в случае совпадения выполняется соответствующая
Инструкция. Если сопоставление отсутствует, выполняется альтернатива else (при её наличии).
Поясним применение конструкции codeswitch на конкретных примерах. При анализе ТМИ часто требуется выполнять различные действия в зависимости от значений некоторых управляющих сигналов, передающихся в составе пакетов ТМИ. Например, чтобы определить тип пакета ТMИ-Q, принятого от КА типа «Канопус-В», требуется выполнить следующий код:
@ Пакет ре^има ВП else
@ Неизвестный пакет
Существенно упростить подобные провер- кодового выбора codeswitch. Перепишем пре- ки позволяет новая управляющая конструкция дыдущий код, используя эту конструкцию:
codeswitch Б, (ТMИ-Q[6] $ ТMИ-Q[7]){
000001—0011----: { ... } @ Пакет технологического режима НП
000001----------: { ... } @ Пакет штатного режима НП
000000---0------: { ... } @ Пакет режима ВП else: { … } @ Неизвестный пакет
}
Два первых байта заголовка пакета ТМИ объединяются в одно 16-битовое значение (ТMИ-Q[6] $ ТMИ-Q[7]), которое проверяется на совпадение с кодовыми значениями (двоичными константами). В отличие от классической конструкции switch в конструкции codeswitch, во-первых, значения констант задаются в двоичном (Б), восьмеричном (В) или шестнадцатеричном (Ш) виде, во-вторых, разряды, значения которых несущественны для выбора, помечаются символом ‘–’.
В следующем примере по кодовому значению события event осуществляется печать его сообщения. Для удобства коды значений заданы в шестнадцатеричном виде. У двух последних событий в младшем байте передаётся дополнительная информация, следовательно, в операторе выбора их значения помечены несущественными:
codeswitch Ш, (event) {
8000: ИОК6 . WRITELINE("БВС переключила шину CAN");
A000: ИОК6 . WRITELINE("Низкое напря^ение батареи");
-
1001: ИОК6 . WRITELINE("Начался разворот СОС");
-
1002: ИОК6 . WRITELINE("Разворот СОС выполнен");
DEAD: ИОК6 . WRITELINE("Выполнение задачи завершено");
BEEF: ИОК6 . WRITELINE("Был запрошен пакет ИОК1");
01—: ИОК6 . WRITELINE("Возникло событие СТИ {0}", event & 0xff);
-
02—: ИОК6 . WRITELINE("Возникло маскированное событие СТИ {0}", event & 0xff);
-
2.7. Функции
ИН^ЧЕ: ИОК6 . WRITELINE("Неизвестное событие");
}
Параметр ИОК6 имеет тип текстового протокола. Его значения являются форматированными текстовыми строчками, формируемыми в коде анализа с помощью метода WRITELINE().
Как и в других языках программирования, функция является именованным фрагментом кода, к которому можно обратиться из других мест программы анализа. Объявление функций осуществляется до главной функции подпрограммы. Синтаксис объявления функции следующий:
Объявление функции = [Тип возврата], Имя функции, "(", ^ргумент, {",", ^ргумент}, ")", Инструкция;
Тип возврата = Тип | Корте^ возврата;
В языке предусмотрены две специальные функции:
-
1) ИНИЦИ^ЛИЗ^ЦИЯ — исполняется после загрузки программы обработки ТМИ, используется для инициализации подпрограмм, формирования некоторых управляющих значений, вывода статических текстовых сообщений (заголовков текстовых протоколов), загрузки результатов предыдущей работы и т. п.;
-
2) ФИН^ЛИЗ^ЦИЯ — исполняется в конце работы программы обработки ТМИ перед её завершением, используется для сохранения результатов работы, вычисления некоторых статистических данных, формирования значений параметров, говорящих об окончании сеанса обработки ТМИ и т. п.
-
2.8. Кортежи
Кортеж — упорядоченный набор данных фиксированной длины. В отличие от массива, элементы кортежа могут быть разного типа. Кортежи подобны неименованным структурам с открытыми полями и без методов. В современных языках программирования кортежи только набирают популярность. Они есть в языке Python . В языке C # кортежи появились с версии 7.0 в 2017 г. В таких языках, как С ++ или Java , кортежи реализуются при помощи классов, но на уровне языка не поддерживаются.
В большинстве случаев, когда функция должна вернуть упорядоченный набор данных, этот набор в целом имеет некий смысл, и под него объявляют отдельный тип данных. Если этот тип данных используется в программе мало, то вместо объявления отдельного типа можно воспользоваться кортежами.
В языке используется три разных вида кортежей.
-
1. Корте^ возврата описывает тип возврата функции. Содержит типы элементов и необязательные имена. Имена служат трём целям: во-первых, подсказывают читающему код, какое значение на какой позиции передаётся; во-вторых, позволяют обратиться к одному конкретному элементу кортежа при необходимости; в-третьих, делают более осмысленными сообщения транслятора о возможных ошибках. Синтаксис кортежа возврата следующий:
-
2. Корте^ выра^ений представляет собой упорядоченный набор конкретных значений, вырабатываемых выражениями. Используется для возврата из функции или выполнения над кортежем некоторых операций (для выражений l-value ). Типы значений вырабатываемых выражений должны быть совместимы по присваиванию с элементами того кортежа, в который передаётся кортеж возврата, либо с аргументами функции, в которую передаётся кортеж. Синтаксис кортежа выражения следующий:
-
3. Корте^ объявлений представляет собой упорядоченный набор объявлений переменных или l-value выражений, которым присваивается результат работы функции, возвращающей кортеж. Отметим, что любая позиция кортежа объявления может быть пустой. В этом случае данный элемент кортежа будет утерян. Можно чередовать объявление переменных, использование существующих переменных, обращение к элементам массива или полям сложных объектов в любом порядке. Синтаксис кортежа переменных следующий:
Корте^ возврата = "(",
Элемент возврата, {",", Элемент возврата}, ")";
Элемент возврата = Тип, [ Имя элемента ];
Корте^ выра^ения = "(", Выра^ение, {",", Вы-ра^ение}, ")";
Корте^ объявления = "(", Объявление, {",", Объявление}, ")";
Объявление = [ Тип, Имя переменной |
LValue выра^ение ];
Рассмотрим различные возможности по использованию кортежей на конкретных примерах. Одним из типичных примеров являются функции оперирования векторами и кватернионами при проведении баллистических расчётов.
@ Функция вычисления векторного произведения, результатом является корте^ (double c1, double c2, double c3) ВекторноеПроизведение( double x1, double y1, double z1, double x2, double y2, double z2){
} return (y1*z2 – z1*y2, z1*x2 – x1*z2, x1*y2 – y1*x2);
(double cx, double cy, double cz) = ВекторноеПроизведение(x,y,z,vx,vy,vz);
В этом примере используются три кортежа. В определении функции ВекторноеПроизведение в качестве возвращаемого значения указан кортеж возврата, в круглых скобках через запятую перечисляются типы и имена элементов кортежа. В инструкции return используется кортеж выраже- ний, элементами которого являются выражения, возвращающие значения. Результат вызова функции присваивается кортежу новых переменных (cx, cy, cz).
В общем случае в кортеже переменных могут использоваться не только переменные, но любые l-value выражения:
(tmci[i].apid, tmci[i].ntmci, tmci[i].time) = F2();
tmci[i].(apid, ntmci, time) = F2();
В первом примере элементы кортежа, возвращаемые функцией F1(), присваиваются переменной number, первому элементу массива data и полю name структуры info соответственно. Во втором примере элементы кортежа, возвращаемые функцией F2(), присваиваются полям tmci[i]. Третий пример является более короткой записью второго примера.
Кортежи могут использоваться в групповых операциях. Если у бинарной операции языка анализа в качестве одного из аргументов указать кортеж, то эта операция последовательно будет применена к каждому элементу кортежа в паре с другим операндом операции:
(i, У, k, m[4]) = 0;
tmci[i].(apid, ntmci, time) = 0;
sum /= (a, b, c); @ эквивалентно выполнению sum/=а; sum/=b; sum/=c;
(a, b) >>= 4;
(i, У)++;
(m1, m2)[i] = GetValue(); @ функция возвращает одно значение
(p, q, r) = i++;
Выполнение приведённых в примере операций осуществляется естественным образом. В последних двух примерах вычисление выражения справа от знака присваивания происходит однократно, а результат вычисления присваивается каждому элементу кортежа слева от знака присваивания.
Бинарные операции присваивания допустимо применять к парам кортежей. При этом кортежи слева и справа от знака присваивания должны быть одного размера, а элементы на соответствующих позициях должны быть совместимы по присваиванию:
(a, b) += (c, d);
3. Вывод текстовой информации
Одной из ключевых задач алгоритмов анализа является формирование различных текстовых протоколов. Передача текстовых данных в телеметрический информационно-вычислительный комплекс осуществляется в значениях ТМ-параметров. Для вывода текста в параметр текстового типа используются методы WRITE и WRITELINE. Первый просто дописывает фрагмент текста в текущую строку, а второй дописывает и отправляет завершённую строку на обработку.
Синтаксис метода WRITE следующий:
Частичный форматный вывод = "WRITE(",
Строка формата, ^ргументы формата ")";
Строка формата =
{
Символ строки - "{" |
"{{" | (* Означает один символ "{" *)
Обращение к аргументу
}, ......
^ргументы формата =
{ ",", Выра^ение };
Обращение к аргументу =
"{",
Целое число, (* Номер аргумента, начиная с 0 *)
[
Ширина поля |
Ширина поля, Код формата |
Код формата |
Код формата, Ширина поля
]
"}";
В строке формата указывается текст, предназначенный для печати, и обращение к аргументам, которые выводятся в различных форматах. В тексте могут использоваться специальные последовательности, управляющие форматированием текста от места задания и до конца строки:
\+b — включает полужирный шрифт;
\–b — выключает полужирный шрифт; \+u — включает подчёркивание текста;
\–u — выключает подчёркивание текста;
\+i — включает курсивный шрифт;
\–i — выключает курсивный шрифт;
\c* — задаёт цвет текста. Здесь вместо звёздочки задаётся номер цвета от ‘0’ до ‘9’ и от ‘ a ’ до ‘ f ’ из цветовой палитры CGA .
Продемонстрируем возможности форматного вывода на примерах:
лог . WRITELINE("\+bPldRspi::\–b{0} {1:d} {2:T}", источник, дата, время);
Приведённый код выводит в параметр, заданный переменной лог, текст «PldRspi::» полужирным шрифтом, далее текст, содержащийся в переменной источник, потом дату, закодированную в переменной дата в формате «дд.мм.сс», и, наконец, время, содержащееся в переменной время в формате «чч:мм:сс.МММ». Следует отметить, что переменные дата и время — обычные целочисленные, а способ их трактовки задаётся в строке формата через двоеточие после номера аргумента. В результате будет выведен, например, такой текст:
PldRspi::StatusEvent 21.07.21 17:58:24.958
В следующем примере
КМВ2М2 . WRITE(" {0:-#0.0}", TKMB2S);
в текстовый параметр КMВ2M2 выводится значение вещественного параметра ТКMВ2S, причём строка не завершается, и вывод в неё может быть продолжен. Для вещественных значений здесь задаётся конкретный формат: отводится позиция под знак, перед отрицательным значением будет выведен минус, перед положительным — пробел. До разделителя дробной части выводится две значащих цифры, после него — одна. Причём первая значащая цифра является необязательной (символ «#») — если она равна нулю, то вместо цифры выводится пробел. Такой способ форматирования текста позаимствован из языка C #.
4. Унификация языка программирования
Для оценки разработанного языка программирования предложен новый показатель унификации языка программирования . Cтепень унификации языка программирования определяется отношением U = |Eu| / |E |, где E — множество всех элементов рассматриваемого языка программирования, а Eu ⊂ E — множество унифицированных, заимствованных элементов языка, которые также присутствуют и в других популярных языках программирования, имеют такой же синтаксис и смысл и знакомы большинству программистов.
Для оценки степени унификации разработанного языка анализа ТМИ U 2 и использовавшегося ранее в ЦУП языка анализа ТМИ U 1 были выписаны все элементы этих языков с пометкой, является ли каждый элемент унифицированным (т. е. присутствует в других современных популярных языках программирования) или нет. Результаты оценки приведены в табл. 3.
Таблица 3
Результаты оценки степени унификации разработанного языка анализа ТМИ
|
Язык |
Количество элементов языка | E | |
Количество унифицированных элементов | Eu | |
Степень унификации U |
|
Старый язык анализа ТМИ U 1 |
477 |
53 |
11,1 % |
|
Разработанный язык анализа ТМИ U 2 |
151 |
107 |
71,8 % |
Таким образом, разработанный язык анализа ТМИ имеет существенно более высокую степень унификации, чем использовавшийся ранее язык.
5. Построение программного обеспечения для реализации анализа ТМИ
Программное обеспечение анализа ТМИ состоит из транслятора , осуществляющего перевод программного кода анализа из текстового представления в байт-код, и интерпретатора , исполняющего байт-код в процессе обработки ТМИ. Байт-код состоит из двух частей: блока данных , содержащего описание входных и выходных ТМ-параметров, переменных, используемых типов и алгоритмов, и блока кода , состоящего из инструкций, объединённых в функции.
Все инструкции байт-кода кодируются и исполняются в обратной польской нотации: сначала вычисляются операнды, помещаются в стек вычислений, затем к значениям на вершине стека применяется операция, результат которой также записывается в стек. Через стек также осуществляется передача аргументов в функцию и возврат значения из функции, при этом скаляр занимает одну ячейку на вершине стека, а кортеж — по одной ячейке на каждый свой элемент.
Дополнительно в программе можно подписаться на временные события, в этом случае указанная программистом функция будет вызываться с заданной периодичностью.
6. Результаты практического применения языка анализа ТМИ в ЦУП
В качестве одного из примеров применения разработанного языка анализа ТМИ для решения практических задач приведём подпрограмму оценки рассогласования уровня окислителя (УО) и горючего (УГ) в блоке «И» ракеты-носителя «Союз-ФГ»:
РАССУОГи = ПРОЦЕДУРА (
ЗАПУСК (ВСЕ, НП)
ВХПАР ( int УО , int УГ )
ВЫХПАР ( int РАССУОГи )
{ if (ABS((int)(УО . ВРЕМЯ - УГ . ВРЕМЯ)) < 2000) РАССУОГи = (int)(УО . ВРЕМЯ - УГ . ВРЕМЯ); }),
ФОРМАТ (МСЕК);
На вход алгоритма подаются сигнальные параметры УО и УГ (рис. 2), изменение которых сигнализирует о прохождении контрольных точек окислителем и горючим соответственно.
Представленный алгоритм вычисляет разницу между временем прохождения близких контрольных точек в миллисекундах и выдаёт её в параметре РАССУОГ (рис. 3). Базовый алгоритм ФОРМАТ приписывает значениям этого параметра размерность МСЕК.
Код подпрограмм на разработанном языке может формироваться автоматически на основе исходных данных, полученных от разработчика КА в формализованном виде. Например, на основе базы данных, содержащей структуру цифровых подмассивов КА «Ресурс-П», или базы данных, содержащей структуру цифровых массивов научной терминальной вычислительной машины служебного модуля Российского сегмента Международной космической станции, формируется код, осуществляющий разбор этих подмассивов и формирование текстовых событийных протоколов.
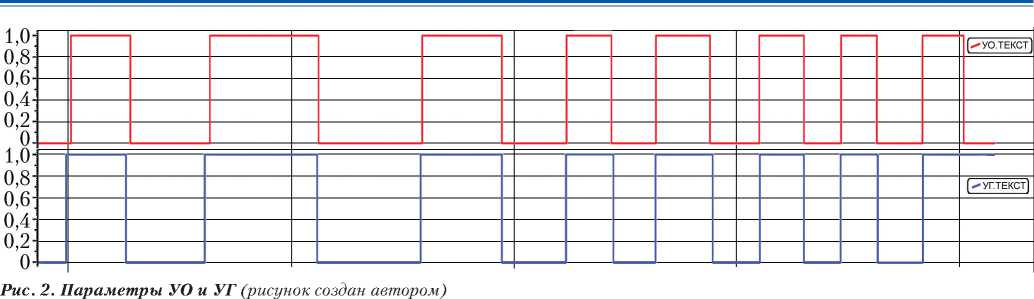
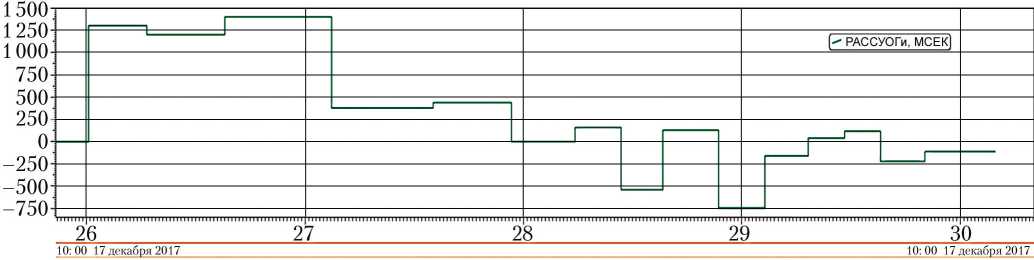
Рис. 3. Вычисленное рассогласование расхода окислителя и горючего (рисунок создан автором)
Заключение
В Центре управления полётами ЦНИИмаш разработан язык задания подпрограмм анализа ТМИ, основанный на синтаксисе современных высокоуровневых языков программирования. Язык позволяет без необходимости изменения кода программного обеспечения задавать в составе исходных данных подпрограммы обработки и анализа ТМИ практически любой сложности для различных КА и выполнять их в ходе сеансов управления КА.
Реализованы транслятор и интерпретатор подпрограмм на языке анализа в составе штатных средств обработки ТМИ, что позволяет комбинировать базовые алгоритмы обработки ТМИ с алгоритмами анализа. Разработанные средства применяются для телеметрического обеспечения управления полётом Российского сегмента МКС и ряда автоматических космических аппаратов.
Язык анализа ТМИ ориентирован на оперирование значениями ТМ-параметров, поддерживает событийную обработку потока телеметрических значений, содержит специализированные операции для преобразования кодовых значений и форматного вывода текстовой информации. Язык обладает высокой степенью унификации в сравнении с использовавшимся ранее в ЦУП языком анализа ТМИ, что существенно снижает трудоёмкость технологического процесса подготовки телеметрического обеспечения управления КА.
Список литературы Разработка языка анализа телеметрической информации
- Матюшин М.М., Кутоманов А.Ю., Иванов А.А., Котеля В.В. Анализ путей повышения эффективности управления космическими аппаратами различного целевого назначения за счёт унификации и интеграции средств управления полётом // Инженерный журнал: наука и инновации. 2021. Вып. 11. 16 с.
- Матюшин М.М., Титов А.М. Теоретические основы обработки телеметрической информации. М.: Машиностроение-Полёт, 2018. 508 с.
- Пратт Т., Зелковиц М. Языки программирования: разработка и реализация. 4-е издание. СПб.: Питер, 2002. 688 с.
- ISO/IEC 14977 Information technology - Syntactic metalanguage -Extended BNF. 1996.
- Махалов Д.А., Титов А.М. Автоматизированный анализ телеметрической информации // Космонавтика и ракетостроение. 2017. № 2(95). С. 14б-155.
