Разработка метода выбора моделей машинного обучения распознавания объектов на изображениях с применением логики продукционных правил

Автор: Сметанин А.А., Духанов А.В., Герасимчук М.Ю.
Журнал: Компьютерная оптика @computer-optics
Рубрика: Численные методы и анализ данных
Статья в выпуске: 5 т.49, 2025 года.
Бесплатный доступ
На сегодняшний день технологии в области фото- и видеообработки данных значительно продвинулись, что позволило алгоритмам распознавания и классификации объектов достигать точности выше 90%. Такие прорывные решения стали широко использоваться в личных и профессиональных целях. Вместе с тем расширение областей применения данных решений привело к увеличению влияющих факторов и их вариаций. От таких факторов зависит качество получения и обработки изображений, включая динамику и деформацию объектов в кадре, что усложняет практическое применение соответствующих алгоритмов. Настоящая статья предлагает подход к разработке рекомендательной системы для выбора моделей машинного обучения в целях решения широкого спектра задач, связанных с обнаружением объектов в кадре изображения, полученных в различных условиях. Данный подход основан на механизме продукционных правил, которые формируются по результатам выполненных ранее исследований, а также анализа научных источников (статьи, репозитории научных программных библиотек и пр.). Результатом функционирования разрабатываемой системы является не просто перечень моделей глубокого обучения с указанием их релевантности к применению в задаче пользователя и априорными оценками значений метрик качества. Предлагаемый подход позволяет формировать предложения по созданию конвейеров машинного обучения и рекомендаций по установке и использованию соответствующих программных библиотек.
Модели и конвейеры машинного обучения, детектирование объектов, продукционные правила, рекомендательная система
Короткий адрес: https://sciup.org/140310603
IDR: 140310603 | DOI: 10.18287/2412-6179-CO-1583
Development of a methodology for selecting machine learning models for recognizing moving objects in a video stream based on production rules
To date, technologies in the field of photo-video data processing, algorithms for recognizing and classifying objects in images, have become more accurate, often exceeding the accuracy threshold of 90%. Such technological breakthroughs have led to extensive use of these innovations for professional and personal purposes. However, the variation of factors such as the conditions for obtaining and processing images, the dynamics and deformation of objects in the frame, can complicate the practical application of these algorithms. The presented scientific research focuses on the development of a recommendation system for choosing optimal machine learning models in order to solve a wide range of tasks related to object recognition. The principle of forming recommendations is generated on the basis of production rules, which are developed taking into account experimental data and analysis of academic sources. The result of the proposed system is not just a list of models indicating their relevance, but also proposals for the creation of machine learning pipelines and recommendations for the installation and use of appropriate program libraries. The current article describes a methodology for automating the formation of recommendations, including a priori estimation of metric values in the context of object classification tasks in images.
Текст научной статьи Разработка метода выбора моделей машинного обучения распознавания объектов на изображениях с применением логики продукционных правил
В настоящее время объем и скорость генерации данных стремительно растет, что приводит к повышению значимости машинного обучения (МО) в широком разнообразии классов задач и их параметров. В данном контексте использование конвейеров МО и ансамблей моделей/архитектур становится актуальным. На текущий момент разработано множество наукоемких решений в части детектирования и(или) распознавания объектов как на статических изображениях, так и на видео, в том числе в режиме реального времени с заданными параметрами реактивности [1, 2]. В то же время конечному пользователю, например, специалисту по данным, сложно подобрать нужное решение для его ситуации, которая характеризуется открытым набором параметров с соответствующими множествами допустимых значений. Одним из развивающихся направлений в данной области является разработка рекомендательных систем (РС), которые на основе имеющихся наборов данных (НД) способны находить подходящее решение для конкретных задач [3, 4].
Целью настоящего исследования является разработка метода автоматизации формирования рекомендаций по выбору моделей глубокого обучения в зависимости от обучающего набора данных и требований к детектированию объектов в видеопотоке. Обучающий набор данных характеризуется такими свойствами, как объем, баланс по классам, разрешение изображений, размеры объектов заданного класса, условия получения изображений и другие. Требования к детектированию включают диапазоны точности, вычислительной реактивности распознающей системы, параметры вычислительной среды и другие.
При выборе моделей мы учитываем результаты решения задач детектирования объектов, полученные в прошлых исследованиях на различных наборах данных. Такие результаты аккумулируются в специальной базе знаний.
Разработка и реализация метода автоматизации формирования рекомендаций позволит специалистам компьютерного зрения и смежных областей ускорить разработку соответствующих решений. Также специалисты смогут за одно и то же время исследовать несколько архитектур глубокого обучения, применимых к основной и смежным задачам.
В оставшейся части статьи будет представлен обзор релевантных исследований, на основе которого будет уточнена основная задача исследования. Затем в параграфе «Метод автоматизации формирования рекомендаций» будет рассмотрен принцип формирования продукционных правил и алгоритм получения рекомендаций. В параграфе «Проведение экспериментальных исследований и результаты» представлены результаты проверки разработанной методики на различных НД с применением метрик для оценки точности и скорости моделей МО. Для проведения эксперимента в качестве виртуальной экспериментальной установки на языке программирования Python разработано программное средство, а также была подготовлена и наполнена база знаний продукционных правил. Статья завершается заключением и информацией о будущих исследованиях.
1. Обзор существующих научно-технических решений
Обзор нацелен на представление ассортимента современных архитектур глубокого обучения для решения задач детектирования объектов, который быстро расширяется. Также рассмотрены работы и решения в области автоматизации формирования конвейеров компьютерного зрения на основе автоматического машинного обучения (AutoML). Обзор завершается качественным сравнительным анализом выявленных решений.
Детектирование, распознавание движущихся объектов в видеопотоке является одной из фундаментальных задач в различных областях [1]. Методы детектирования объектов, основанные на глубоком обучении, широко применяются в различных областях, например, распознавании лиц, мониторинге дефектов продукции, отслеживании качества работы, оценивании эмоционального состояния человека и многих других. Одними из самых популярных архитектур, используемых для этих задач, являются YOLO (You Only Look Once) [5]. Эти архитектуры адаптируются к различным размерам объектов и экономично используют ресурсы, что делает их популярными для встраиваемых систем детектирования [5, 6]. Для задач распознавания объектов различного масштаба подходит нейросетевая архитектура SSD (Single Shot MultiBox Detector), она представляет собой одну нейронную сеть, способную прогнозировать разные размеры и классы объектов с разных слоев в сверточной архитектуре, что позволяет эффективно обнаруживать объекты разных масштабов [7]. Также одними из эффективных архитектур являются рекуррентные сверхточные сети (R-CNN) [8, 9].
Для объективного сравнения моделей детектирования объектов широко используются две ключевые метрики: mean Average Precision (mAP) для оценки точности и кадры в секунду (FPS) для оценки скорости. Метрика mAP учитывает точность и полноту модели, что позволяет оценить её способность правильно классифицировать и детектировать объекты. Показатель FPS, в свою очередь, отражает скорость работы модели и демонстрирует, сколько кадров в секунду она способна обрабатывать. Для задач детектирования в реальном времени скорость имеет важнейшее значение, поскольку задержки в обработке могут негативно сказаться на общей производительности системы. Использование FPS в качестве метрики позволяет оценить, насколько эффективно модель справляется с потоками данных в условиях ограниченных вычислительных ресурсов, что особенно актуально для встраиваемых систем [10].
С ростом числа нейронных архитектур специалистам становится сложнее быстро выбирать наилучшие архитектуры для создания эффективных решений. В результате возникли фреймворки AutoML, реализующие автоматизированные методы выбора подходя-щих/оптимальных решений с использованием собственных алгоритмов[11]. Методы автоматического машинного обучения охватывают разнообразные подходы, включая эволюционные алгоритмы, оптимизацию параметров и адаптивные исследования пространства параметров. Такие подходы позволяют более эффективно исследовать пространство параметров и архитектур, обнаруживая оптимальные решения для разнообразных задач машинного обучения.
В табл. 1 представлен общий сравнительный анализ современных решений как в России, так и за рубежом. В данной работе предложен метод, который отличается от существующих подходов AutoML. Основными преимуществами предлагаемого решения являются уникальный метод рекомендаций моделей, основанный на пользовательском опыте, собранном в базе знаний, и механизме продукционных правил. В числе прочих особенностей: открытый исходный код, возможность работы в офлайн-режиме, гибкая настройка параметров.
Предлагаемое решение позволяет повысить эффективность специалистов за счет сокращения временных затрат на рутинные процессы, глубже погрузиться в свое исследование на творческом уровне.
2. Метод автоматизации формирования рекомендаций
Для формирования композиций моделей МО и подходящего конвейера, нацеленных на решение конкретных задач пользователей, мы прибегаем к использованию механизма продукционных правил. Он базируется на создании набора правил, основанных на знаниях, полученных в результате проведения экспериментов с нейросетевыми архитектурами на различных наборах данных. Эти правила позволяют предоставлять рекомендации, адаптированные под конкретные задачи и требования. Тем самым, при наличии релевантного пользовательского опыта, отраженного в базе знаний, метод обеспечивает предоставление реко- мендаций, пригодных для высокоточного решения вышеуказанных задач идентификации объектов в разнообразных областях применения.
Табл. 1. Наборы данных, используемые для составления базы знаний
|
Параметр |
Предлагаемое решение |
Robo Flow |
H2O AutoML |
Azure Custom Vision |
AutoML Vision |
Fedot Industrial |
LAMA |
|
Поиск оптимальной модели |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
|
Решение задач распознавания объектов |
+ |
+ |
+ |
+ |
+ |
+ |
- |
|
Открытый исходный код |
+ |
- |
- |
- |
- |
+ |
+ |
|
Возможность настройки модели и набора данных |
+ |
- |
+ |
+ |
+ |
+ |
+ |
|
Возможность офлайн-использования |
+ |
- |
- |
- |
- |
+ |
+ |
|
Веб-интерфейс |
+ |
+ |
+ |
+ |
+ |
- |
+ |
|
Страна |
РФ |
США |
США |
США |
США |
РФ |
РФ |
2.1. Общая схема формирования рекомендаций
Процесс формирования рекомендаций начинается с анализа исходных данных пользователя и его требований. Данные преобразуются в список параметров, который затем обрабатывается алгоритмом DLAS-RA (рис. 1). Алгоритм использует продукционные правила для формирования рекомендаций, которые подбираются на основе знаний, полученных из предыдущих экспериментов.
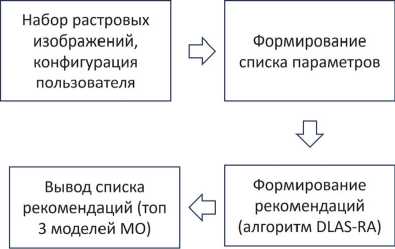
Рис. 1. Общая блок-схема алгоритма формирования рекомендаций
Подробная схема описания алгоритма представлена на сайте проекта и в репозитории [12].
-
2.2. Механизм продукционных правил
Исследовательский опыт отражен в параметрах задачи детектирования объектов и набора данных, а также результатах ее решения: выбранная модель, значения заданных метрик. Иными словами, имеются причинно-следственные связи «какой результат вытекает, если …». Поэтому предлагаемый метод основан на логике продукционных правил. Данные правила определяют связь между свойствами задачи, набора данных, диапазонов метрик качества и рекомендациями в выборе модели. Для формирования условной части правила используется перечень параметров, а в качестве выхода выступает модель машинного обучения, отвечающая входному списку параметров (алгоритм 1).
Если (
(<параметр 1> = <значение 1>) и
(<параметр М> = <значение M>) )
то
(модель обнаружения объектов)
Алгоритм 1. Шаблон продукционного правила
Множество таких правил является базой знаний, на основе которой формируется рекомендация – подбирая наиболее подходящие правила в зависимости от требований и набора данных в задаче детектирования. Процесс составления таких правил для решения задач выбора моделей машинного обучения распознавания движущихся объектов описан в пункте 3.2.
-
2.3. Алгоритм рекомендаций DLAS-RA
-
2.3.1. Схема алгоритма
-
Алгоритм рекомендации архитектуры глубокого обучения (DLAS-RA – Deep Learning Architecture Selection Recommendation Algorithm) основан на интеграции параметров набора данных X (1), аннотации изображений B (2) и требований пользователя U (3) для формирования рекомендации по выбору моделей машинного обучения (глубокого обучения).
X определяется кортежем параметров набора данных (1):
X ( s , b , d , br , e , wb , nc , ni ), (1)
где:
s – размер фотографии в наборе (ширина и высота);
b – коэффициент баланса распределения изображений;
d – количество уникальных цветов в изображении и имеет ограниченное число 256;
br – средняя интенсивность пикселей в градациях серого, показывает общую яркость изображения;
e – энтропия изображений в наборе показывает степень неупорядоченности распределения цветовых пикселей (энтропия измеряется в битах на пиксель и представляет степень случайности распределения цветовых пикселей)[13];
wb – баланс белого;
nc – количество классов, представленных в наборе; ni – количество изображений в наборе.
Зададим параметры аннотаций B , которые определяются лейблами для изображений в наборе:
B ( s , ai , ar , no ), (2)
s ( min , max , avg ) – размер рамки параметров определяют размеры объектов на изображении (ширина и высота ограничивающей рамки);
ai – усредненное количество пересечений рамок;
ar – усредненное cоотношение высоты и ширины рамок;
no ( min , max , avg ) – количество объектов на одном изображении.
U определяется кортежем параметров требований пользователя (3):
U ( a , s , r ), (3)
-
a – ожидаемая точность;
-
s – ожидаемая скорость;
-
2.3.2. Математическое описание алгоритма
r – режим работы (GPU – CPU).
В качестве метрик качества представлены: средний показатель mAP@0,5 учитывает качество обнаружения для всех классов и является одной из ключевых метрик для оценки эффективности алгоритмов обнаружения объектов. Метрика mAP@0,95 учитывает качество обнаружения объектов для каждого класса с высоким порогом IoU (Intersection over Union) в 0,95. Это позволяет оценить точность обнаружения объектов с более строгими критериями сравнения границ. Эти метрики позволяют оценить, насколько точно и полно модель распознает объекты, а также насколько она достоверно классифицирует их. Для метрики скорости работы оценивали время выполнения модели на графическом процессоре (GPU) и центральном процессоре (CPU), чтобы определить, какая модель обладает наилучшей производительностью с точки зрения скорости обработки данных. Кроме того, мы учитывали частоту кадров в секунду (FPS), которая указывает на количество кадров, обрабатываемых моделью в единицу времени.
На основе векторов X, B, U формируется массив параметров, на основе которого формируется рекомендация, а именно выбирается наиболее подходящее правило из базы знаний. В качестве алгоритм выбора нужного правила используется метод k -ближайших соседей (рис. 2).
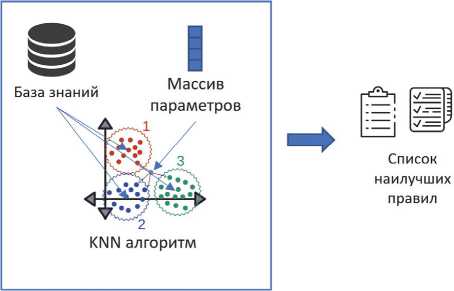
Рис. 2. Общая схема алгоритма DLAS-RA
Математически алгоритм формулируется следующим образом.
В состав входных данных алгоритма включены характеристики входного набора данных (массив изображений) X in , B in и требования пользователя U in . Обозначим такие данные через C in :
С =(х В U- 1
in ( in , in , in ) .
Обозначим банк продукционных правил:
BPR = { R i ,R 2 , ..., R n } , (5)
где BPR (5) – банк продукци о нных правил, R j – j -e, продукционное правило, j e 1, n . Каждое правило R j сформировано для вектора C j = ( X j , B j , U j ). Иными словами, каждое правило получено путем применения соответствующего конвейера машинного обучения с архитектурой (модели) глубокого обучения ML j . Применим алгоритм kNN ( k -ближайших соседей) для поиска оптимального подходящего правила из банка. Чтобы использовать указанный алгоритм, для каждого правила вычисляется метрика близости к заданным данным Cin (4): 5 ( Cin , C j ) - расстояние между векторами Cin и C j в Евклидовом пространстве. Результат работы алгоритма DLAS-RA формулируется через отображение: kNN(k ): C in ^ ( ML out , RS), где kNN(k ) - алгоритм k ближайших соседей ( k – параметр алгоритма – число выбираемых «лучших» соседей); ML out – выбранная архитектура глубокого обучения с точки зрения kNN ( k ); RS = { R i 1 , …, R i k } – выбранные с применением ал горитма kNN ( k ) «лучшие» k соседи, R l e BPR , l e 1, k .
Обратим внимание, кроме лучшей с точки зрения kNN(k) архитектуры глубокого обучения, имеем список правил RS, которые соответствуют ближайшим к Cin = (Xin, Uin) векторам по метрике 5. Это означает, что, кроме указанного алгоритмом архитектуры MLout, может быть одна или несколько архитектур MLil = {MLi1, …, MLik}, l∈ 1, k, которые соответствуют более ближним к Cin векторам Cil по отношению к Cout. Здесь Cout – вектор, соответствующий рекомендованной архитектуре глубокого обучения MLout, Cil – вектор, соответствующий архитектуре, следуемой по правилу Ril € RS, l е 1, k . Таким образом, кроме основной архитектуры MLout, полученной с помощью kNN(k), мы можем предложить альтернативные архитектуры, соответствующие в том числе более ближним к Cin векторам. Окончательное решение по выбору архитектуры принимает разработчик.
3. Проведение экспериментальных исследований и результаты
Для оценки эффективности разработанной методики мы провели эксперимент, которые состоит из двух стадий. На первой стадии мы вывели продукционные правила, опираясь на НД, которые приведены ниже. Вторая стадия была нацелена на оценку эффективности методики на нескольких режимах: когда по заданному НД и значениям параметров возможно подобрать однозначную модель (одно правило с весом единица) или когда приходится подбирать несколько правил с заданными весами и давать рекомендации как по отдельному, так и совместному их применению. Чтобы реализовать вышеобо-значенные шаги, был разработан виртуальный экспериментальный стенд (ВЭС) в форме репозитория GitHub [12].
-
3.1. Программная реализация. Фреймворк ODRS
-
3.2. Формирование базы знаний – набора продукционных правил (шаг 1)
Для обеспечения более удобного и эффективного взаимодействия с пользователем нами был реализован фреймворк ODRS (Object Detection Recommendation System). В основе фреймворка лежит предложенный метод автоматического формирования рекомендаций. Инструменты фреймворка позволяют получать конвейеры МО по заданным наборам данных и параметрам пользователя, а также обучать предложенные модели по средствам API. Для взаимодействия в ODRS доступен веб-интерфейс, предоставляющий собой удобную платформу, где пользователи могут загружать размеченные наборы данных и получать подробные рекомендации с соответствующей информацией [14]. В качестве примера получения рекомендаций через API фреймворка ODRS были проведены запуски программных сценариев на наборе данных Aerial Maritime Drone Dataset [15] (снимки с дронов). Полный эксперимент представлен в разделе Wiki проекта ODRS на GitHub [12].
Для составления базы знаний рекомендаций были выбраны различные открытые бенчмарки (табл. 2), которые представляют собой стандартные наборы данных и метрики для оценки производительности моделей рекомендаций. Для проведения экспериментов были подобраны наборы данных, оптимально подходящие для решения разнообразных задач в данной области исследования. В основном уделено внимание средним (до 15000 изображений) и небольшим (до 1000 изображений) наборам данных, учитывая, что у большинства пользователей может отсутствовать достаточное количество ресурсов для формирования крупного НД. В таблице представлен фрагмент списка выбранных наборов данных, а также их краткие характеристики.
Оценка моделей производилась на основе различных критериев, представленных в п. 2.1.
Мы также использовали современные и высокоэффективные модели машинного обучения семейства YOLO, RNN-сети и сеть SSD. Результаты экспериментов для набора №1 (табл. 3) представлены в табл. 2, полная версия таблицы экспериментов и ссылки на наборы доступны в нашем репозитории [12].
Табл. 2. Наборы данных, используемые для составления базы знаний
|
Название набора |
Краткое описание |
Характеристики данных |
|||
|
Размер |
Баланс |
Количество классов |
Количество изображений |
||
|
WARP |
Набор промышленных изображений твердых коммунальных отходов |
1920×1080 |
94 |
28 |
5948 |
|
Aerial-maritime |
Размеченные снимки доков, лодок, подъемников, автомобилей и других объектов с беспилотного летательного аппарата |
800×600 |
64 |
5 |
1016 |
|
Food |
Размеченные изображения еды |
256×256 |
85 |
7 |
802 |
|
Plantdoc |
Снимки поверхностей больных и здоровых растений |
416×416 |
95 |
30 |
2567 |
|
Website Screenshot |
Скриншоты с различных популярных вебсайтов с размеченными элементами (картинки, кнопки, текст и другие) |
1024×768 |
77 |
8 |
4824 |
Табл. 3. Результаты экспериментов по обучению моделей МО на выбранных НД
|
Модель |
Набор № |
mAP_50 |
mAP_95 |
FPS_GPU |
FPS_CPU |
|
yolov5l |
1 |
0,503 |
0,386 |
50 |
4 |
|
yolov5m |
1 |
0,444 |
0,333 |
61 |
7 |
|
yolov5n |
1 |
0,452 |
0,321 |
80 |
18 |
|
yolov5s |
1 |
0,52 |
0,402 |
79 |
13 |
|
yolov5x |
1 |
0,512 |
0,404 |
42 |
2 |
|
yolov7x |
1 |
0,555 |
0,435 |
15 |
4 |
|
yolov7 |
1 |
0,53 |
0,41 |
15 |
6 |
|
yolov7-tiny |
1 |
0,473 |
0,344 |
14 |
12 |
|
yolov8x6 |
1 |
0,536 |
0,433 |
35 |
2 |
|
yolov8x |
1 |
0,478 |
0,388 |
40 |
2 |
|
yolov8s |
1 |
0,51 |
0,382 |
72 |
11 |
|
yolov8n |
1 |
0,466 |
0,351 |
75 |
17 |
|
yolov8m |
1 |
0,512 |
0,409 |
57 |
5 |
|
Faster-vgg16 |
1 |
0,461 |
29 |
4 |
|
|
SSD |
1 |
0,467 |
0,435 |
45 |
4 |
По итогам проведения экспериментов из данных о наборах и метриках была сформирована база знаний, содержащая сведения о метриках качества моделей обнаружения объектов на различных наборах данных. На основе данных из базы знаний был сформулирован набор из 75 правил для составления рекомендации выбора моделей. Продукционные пра- вила позволяют полу- и (или) автоматически выбирать наилучшую модель для конкретной задачи на основе имеющихся данных и «банка» моделей. Полный список правил представлен в нашем репозитории. Пример фрагмента некоторых правил, составленных на основе набора данных №1, представлен в табл. 4.
Табл. 4. Пример продукционных правил, сформированных на основе базы знаний
|
Размер |
Баланс |
Количество классов |
Количество изображений |
mAP50 |
mAP_95 |
FPS_GPU |
FPS_CPU |
Модель |
|
1920×1080 |
94 |
28 |
5948 |
0,512 |
0,404 |
42 |
2 |
Yolov5x |
|
1920×1080 |
94 |
28 |
5948 |
0,555 |
0,435 |
15 |
4 |
Yolov7x |
|
1920×1080 |
94 |
28 |
5948 |
0,53 |
0,41 |
15 |
6 |
Yolov7 |
|
1920×1080 |
94 |
28 |
5948 |
0,473 |
0,344 |
14 |
12 |
Yolov7-tiny |
|
1920×1080 |
94 |
28 |
5948 |
0,536 |
0,433 |
35 |
2 |
Yolov8x6 |
Для обучения наилучшего классификатора КNN было произведено несколько экспериментов. Для достижения наилучшего результата набор правил был разделен на две подвыборки – обучающую и тестовую, соответственно составляющие 80 % и 20 % от общего объема данных. Кроме того, было произведено создание дополнительных 30 правил на основе всего набора данных с целью расширения обучающего контекста для повышения точности алгоритма предсказания. Эксперименты проводились на ЭВМ с видеокартой NVIDIA А5000 и центральным процессором 12th Gen Intel(R) Core(TM) i3-12100, c размером батча обучения 32. В качестве признаков были выбраны атрибуты, выделенные жёлтым цветом (табл. 3), а в качестве предиктора выбрано поле модель. В процессе обучения алгоритма KNN удалось достичь высокого значения точности в размере 89 % на тестовой выборке для рекомендательного алгоритма. Этот результат свидетельствует о хорошей способности алгоритма предоставлять рекомендации, точно соответствующие предпочтениям пользователей или другим критериям, используемым в процессе обучения.
-
3.3. Оценка работы метода выбора моделей машинного обучения (шаг 2)
Чтобы оценить качество сформированных правил, был выбран набор условий, каждый из которых содержал изображения и аннотации из заданного НД и список соответствующих параметров требований к искомой модели. В данной серии нет условий, которые участвовали в формировании продукционных правил. Для каждого условия с помощью предложенного алгоритма были получены рекомендации в виде списка наиболее подходящих моделей. Модели из списка рекомендаций сравнивались со всеми моделями из базы знаний для оценки эффективности рекомендаций. Эксперименты проводились на расширенном наборе данных WaRP, содержащем 25000 размеченных изображений для 27 классов объектов твердых коммунальных отходов (далее – ТКО) и собранном совместными усилиями компаниями Insystem и AIRI, а также Университетом ИТМО [16 – 18]. Набор данных представлен изображениями отсортированного мусора с различных сортировочных заводов из Ленинградской и Московской областей, а также из Ставропольского края.
Целью эксперимента было получить рекомендации при помощи предложенной в статье методики, после чего сравнить их с обученными на расширенном наборе данных WaRP моделями, использованными при формировании продукционных правил, для оценки эффективности методики в решении реальной задачи. Первый эксперимент заключался в поиске наиболее точной модели распознавания (по метрике mAP50), а второй – в поиске компромиссной максимально быстрой модели на GPU (по метрике FPS_GPU), имеющей высокую точность (по метрике mAP50).
Эксперимент 1: на вход системе был предоставлен расширенный набор данных WaRP и конфигурационный файл с требованиями максимальной точности. Основной целью эксперимента было получение наиболее точной модели. В результате работы рекомендательной системы были получены следующие модели: YOLOv5-x, YOLOv8-x, YOLOv5-m.
Эксперимент 2: мы предоставили системе конфигурационный файл, в котором были установлены требования к максимальной скорости и высокой точности. Целью данных экспериментов было определение наилучшей компромиссной модели, которая сочетает в себе высокую скорость работы. В результате работы рекомендательной системы были получены следующие модели: YOLOv7-tiny, YOLOv8-n, YOLOv5-s.
Далее были проведены подсчеты точности и скорости для всех моделей.
Результаты экспериментов показаны на графике (рис. 3). Синим цветом выделены наиболее точные модели, а зеленым – наиболее быстрые.
По результатам проведенных экспериментов наиболее эффективной моделью является YOLO v5-x – по полученным значениям метрик она продемонстрировала высокую скорость и точность распознавания объектов. На втором месте по эффективности оказалась модель YOLO v5-m, на третьем месте – YOLO v8-x. Из предсказаний системы и проведенных экспериментов следует, что система действительно выдает обоснованные начальные приближения в выборе МО для обнаружения объектов. Полученные данные были использованы для пополнения базы знаний рекомендательной системы. Из сравнительного графика (рис. 4) вытекают следующие выводы. При выборе наиболее быстрой модели рекомендательная система показала высокие результаты. Действительно, были выбраны наиболее оптимизированные модели с учетом скорости работы. Однако при рассмотрении баланса между скоростью и точностью результаты экспериментов показали, что модель Yolov8s является наиболее подходящей для обеспечения высокой точности предсказаний.
-
3.4. Дискуссия
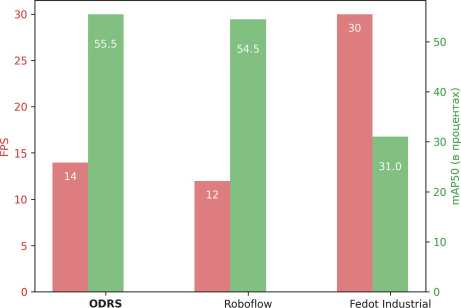
Для оценки эффективности разработанного метода были проведены эксперименты на различных открытых и полуоткрытых платформах, предоставляющих возможность создания моделей для обнаружения объектов. В качестве платформ для исследования были выбраны Roboflow, на которой зарегистрировано более 250 тысяч пользователей, и Fedot Industrial, насчитывающая свыше 1000 пользователей. Дополнительно эксперименты проводились с использованием набора данных WaRP. На графике (рис. 4) представлены результаты, демонстрирующие точность и скорость моделей, предложенных этими фреймворками.
Сравнение моделей по тАР_50, тАР_95 и FPS_GPU (вертикальная диаграмма)
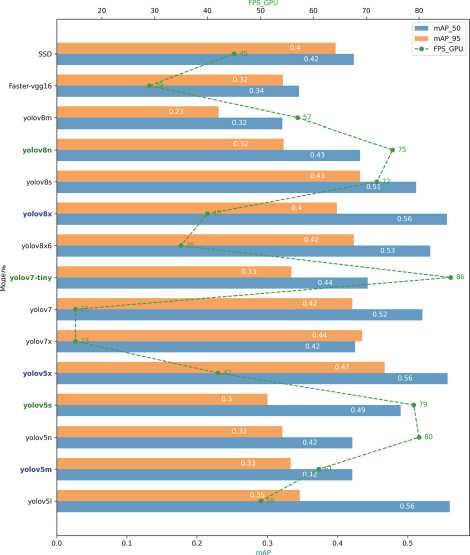
Рис. 3. Сравнительный график моделей глубокого обучения по скорости и точности
Сравнение FPS, тАР50 и времени поиска модели
Платформа
Рис. 4. Сравнительный график AutoML фреймворков по скорости, точности и времени поиска
Фреймворки ODRS и Roboflow продемонстрировали схожие результаты как по скорости, так и по точности модели. В свою очередь, фреймворк Fedot Industrial позволил найти модель с высокой скоростью, но существенно уступающую по точности. На основе проведённых экспериментов платформа ODRS показала конкурентоспособные результаты среди современных открытых платформ.
Заключение
В рамках данной работы предложен новый метод автоматизированного выбора моделей машинного обучения для детектирования объектов на изображениях, основанный на механизме продукционных правил. Основное преимущество предложенного подхода заключается в его способности интегрировать накопленные знания о существующих архитектурах нейросетей и их производительности на различных наборах данных. Это позволяет значительно сократить время на подбор оптимальных моделей и повысить точность решений, что особенно актуально для задач реального времени.
Ценность данной работы заключается в разработке системы рекомендаций, использующей продукционные правила, которая адаптируется под конкретные требования пользователя и набор данных. В отличие от существующих решений, данная система не только предоставляет рекомендации по выбору моделей, но и предлагает конвейеры для автоматизации их обучения и использования, что делает ее уникальной в контексте применения в компьютерном зрении.
Практическая значимость результатов проявляется в возможности применения предложенной системы в различных областях, таких как промышленная автоматизация, медицинская диагностика, системы безопасности и интеллектуальные транспортные системы. Благодаря возможности гибкой настройки и работы в офлайн-режиме, система может быть внедрена в условиях ограниченных ресурсов, что повышает ее ценность для широкого круга пользователей. Планы на будущее включают расширение базы данных продукционных правил за счет добавления новых наборов данных, таких как медицинские изображения и изображения дронов для мониторинга окружающей среды. Кроме того, планируется расширить набор параметров для формирования рекомендаций с использованием больших языковых моделей, которые помогут извлекать текстовые описания изображений и расширять пространство анализируемых признаков.
Данная работа была поддержана Министерством образования и науки, договор FSER-2024-0004.
