Разработка методов формирования цвето-текстурных признаков для анализа биомедицинских изображений

Автор: Пластинин А.И., Куприянов А.В., Ильясова Н.Ю.
Журнал: Компьютерная оптика @computer-optics
Рубрика: Цифровая обработка сигналов
Статья в выпуске: 2 т.31, 2007 года.
Бесплатный доступ
В статье рассматривается метод формирования цвето-текстурных признаков. Метод основан на вычислении характеристик многомерного распределения вероятности интенсивностей цветовых компонент. Представлены экспериментальные исследования метода на натурных изображениях. Приводится сравнение разработанного метода с уже существующими.
Короткий адрес: https://sciup.org/14058749
IDR: 14058749
Текст научной статьи Разработка методов формирования цвето-текстурных признаков для анализа биомедицинских изображений
Одним из важнейших диагностических методов, который до сих пор выполняется вручную лаборантами, остается общеклиническое исследование крови. Именно данный анализ крови тонко отражает реакцию кроветворных органов на воздействие на организм различных физиологических и патологических факторов [1]. Важным диагностическим показателем является количество и процентное соотношение каждого из типов лейкоцитов (лейкоцитарная формула). Лейкоциты различны по внешнему виду и функциям. Различают следующие виды лейкоцитов: нейтрофилы (палочко-ядерные, сегментноядерные), эозинофилы, базофилы, моноциты, лимфоциты [2].
Широкое распространение, трудоемкость выполнения и низкое качество результатов при ручном анализе делает автоматизацию общеклинического анализа крови необходимой и актуальной задачей. Рассмотрим принцип работы системы автоматической диагностики. Изображение препарата крови формируется подключенной к окуляру микроскопа фотокамерой. Оно представляет собой фон, с относительно постоянной яркостью, на котором присутствуют различные форменные элементы (клетки крови). Затем на изображении выделяются лейкоциты, которые представляют собой связные области. Для каждого лейкоцита определяется его тип. И подсчитывается общее количество клеток каждого типа.
Целью работы является разработка признаков для классификации изображений лейкоцитов. Рассматриваются классы: эозинофилы, базофилы, моноциты, лимфоциты.
лейкоцитов. Подход, основанный на матрицах вероятностного распределения (МВР) яркости, уже не раз очень успешно использовался для выделения аналогичной информации [4, 5, 6].
К недостаткам методов МВР можно отнести: работу с полутоновыми изображениями; использование целочисленного формата данных; высокую вычислительную сложность, заключающейся в необходимости работы с трёхмерными матрицами распределения вероятности. В данной работе рассматривается модификация существующих методов для устранения указанных недостатков.
1. Метод цвето-текстурного анализа
Текстурные признаки – это статистические характеристики многомерного вероятностного распределения интенсивности отсчетов цветовых компонент.
Будем рассмотривать цветное изображение в формате RGB, которое представляется отсчетами функции интенсивности цветовых компонент f ( m, n ) = ( fR ( m , n ) f c ( m , n ) fB ( m , n ) ) T , где m, n e Z . Как известно в пространстве RGB присутствует кросс-канальная корреляция, что приводит к статистической зависимости признаков, вычисленных по разным цветовым каналам. Поэтому необходимо использовать декоррелированное цветовое пространство. Таким является цветовое пространство Ruderman l a в [7], которое получено на основе анализа главных компонент в пространстве LMS [7].
Переход в цветовое пространство l a в из RGB осуществляется в два этапа.
1) Переход из RGB в LMS [7]:
Рис. 1. Изображения лейкоцитов
В качестве основы для исследований был выбран метод, предложенный Хараликом в [3], называемый в дальнейшем статистическим текстурным анализом. Задачей является выделение признаков, связанных с локальными текстурными особенностями
' L '
M
I ^ )
' 0,3811
0,1967
( 0,0241
0,5783
0,7244
0,1288
0,0402Y R )
0,0782 G
0,8444 J^ B J
2) Переход из LMS в l ap [7]:
< l )
a
IpJ
" 0,5774 0,4082 ( 0,7071
0,5774
0,4082
- 0,7071
0,5774 )
- 0,8164
0 )
' lg LM' lg M I lg S )
Здесь цветовые компоненты RGB нормированы так, чтобы принимать значения в диапазоне [ 0;1 ] .
Для того, чтобы достичь инвариантность к цвету, необходимо привести статистические характеристики каждой компоненты к заранее определенным величинам, например, m = 0; о = 1. Это можно сделать, выполнив для каждого канала поэлементную обработку следующего вида:
Пусть каждому из случаев соответствуют функции распределения f 12 ( x , y , z ) , F 2 2 ( x , y , z ) , F 2 3 ( x , y , z ) , F 2 4 ( x , y , z ) .
В результате усреднения получим функцию распределения:
‘ _ l - ml
1 о ;
'
a
a-ma o. _ p-me Z« ; e = , о о
где m - математическое ожидание, о - дисперсия.
В данной работе рассматриваются статистические методы формирования признаков, основанные на 3-х мерной функции распределения вероятности яркости в 3-х соседних точках.
Рассмотрим интенсивности заданного цветового канала С (одного из l ap ) в трех точках, находящихся на заданном расстоянии друг от друга:
M 0 = fc ( m , n ) , M 1 = f ( m + A mpn + A nx),
M 2 = f c ( m + A m 2, n + A n 2).
Обозначим p ( m 0 = x , m 1 = y , m 2 = z ) - вероятность появления точек с яркостями x , y , z . Тогда
F ( x , y , z ) = 4 ( f2 ( x , y , z ) + F 2 ( x, y , z ) +
+ F 3 2 ( x, y , z ) + F 2 ( x , y , z ) ) .
Введем следующие числовые характеристики: Корреляция:
R = J xyzdF ( x , y , z ) .
R 3
Затенение:
S = J ( x + y + z ) dF ( x , y , z ) .
R 3
Контраст:
x - z | + | y - z I) dF ( x , y , z ) ,

Рис. 2. Примеры взаимного расположения точек
Так как нет необходимости учитывать порядок расположения соседних отсчетов, перейдем к следующей функции распределения, усреднением по следующей схеме:
3 R3
K 2 = J| ( x - y )( x - z )( y - z )| dF ( x y , z ) .
R 3
Инерция:
I 1 = 1 J ( ( x - y ) 2 +( x
3 R 3
^^^^^в
z ) 2 + ( y - z ) 2 ) dF ( x , y , z ) ,
I 2 = J ( x - y ) 2 ( x - z ) 2 ( y - z ) 2 dF ( x , y , z ), R3
Признаки записаны для нулевого математиче-го ожидания. Общий вид признака, можно пред
Fг ( x , y , z ) = 6 ( F 1 ( x , y , z ) + F 1 ( x , z , y ) +
+ F 1 ( y , x , z ) + F 1 ( y , z , x ) +
ставить как:
C = J g ( x, y , z ) dF ( x, y , z ) .
R 3
В случае, если исходная функция распределения не известна, можно использовать эмпирическую функцию распределения вероятности [8]: F ( x . y . z ) = Ng. где k - количество элементов выборки, попадающих в область x < x , y ' < y ,
+ F 1 ( z , x , y ) + F 1 ( z , y , x ) ) .
Для обеспечения инвариантности, относительно поворота на угол кратный 45 ° . Будем рассматривать следующие расположения точек:
-
1. A m ; = A k 1 ; A n ; = A 1 1 ; A m 2 = A k 2; A n 2 = A 1 2,
-
2. A m ; = A 1 1 ; A n ; = A k 1 ; A m 2 = A 1 2; A n 2 = A k 2,
-
3. A m ; = A 1 1 ; A n ; = A k 1 ; A m 2 = -A 1 2; A n 2 = A k 2,
-
4. A m ; = -A k 1 ; A n ; = A 1 1 ; A m 2 = -A k 2; A n 2 = A 1 2.
z < z . Тогда получим следующую выборочную оценку:
1 N - 1
N i = 0
Значение признаков вычисляется для каждой цветовой компоненты, поэтому далее будем использовать обозначения, включающие название цветового канала и признака, например: l Shading ( lS ) – затенение, рассчитанное по компоненте l .
Таким образом, процедура вычисления признаков заключается в одном проходе по изображению заданными шаблонами взаимного расположения то-
чек. Экспериментальные исследования на натурных изображениях показали, что предложенный метод вычисления признаков является более быстрым и требует меньше памяти по сравнению с методом, основанным на вычислении 3-х мерной матрицы вероятностного распределения (гистограммы).
2. Дискриминантный анализ признаков
Для определения степени эффективности признаков при классификации используются элементы дискриминантного анализа [9, 10]. Цель выбора признаков состоит в выделении признаков, которые являются наиболее эффективными с точки зрения разделимости классов. Разделимость классов зависит только от распределения объектов в классах, а также от используемого классификатора.
В дискриминантном анализе критерий разделимости записывают с использованием матриц рассеяния внутри классов и матриц рассеяния между классами. Пусть Sw , – матрица рассеяния внутри классов, Sb – матрица рассеяния между классами, Sm – матрица рассеяния смеси. Для выбора признаков рассматривались три критерия:
-
J 1 =tr Sm /tr Sw ,
-
J 2 =| S m |/| S w |,
-
J 3 = tr( S w - 1 S b ) .
Наилучшие признаки те, для которых критерий разделимости максимален [9, 10]. В данной работе рассматривалась задача выбора трёх признаков. Из всего множества векторов признаков, построенных по обучающей выборке, вычислялись критерии разделимости по всем тройкам, количество которых равно C 1 3 8 = 816 . В таблицах 1-3 показаны результаты вычисления критериев разделимости.
Из таблиц видно, что критерии J 1 и J 3 дали одинаковые результаты, при этом наилучшими оказались признаки: l Shading ( lS ), a Contrast2 (α K 2 ), b Shading ( β S ) – 1-ый набор. А по критерию J 2 лучшими признаками являются: l Shading ( lS ), a Contrast2 ( α K 2 ), b Correlation ( β R ) – 2-ой набор. Расположения объектов в пространстве признаков данных наборов показано на рисунках 2, 3, из которых видно, что обрабатываемые четыре класса лейкоцитов линейно разделимы.
Можно заметить, что полученные наборы признаков отличаются одним признаком (признак β S и β R ). Вследствие этого, в дальнейшем для построения классификатора планируется использовать четыре признака, максимизирующие выбранные критерии разделимости классов.
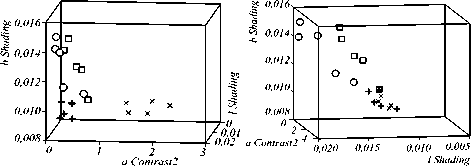
Рис. 3. Расположение объектов в пространстве 1
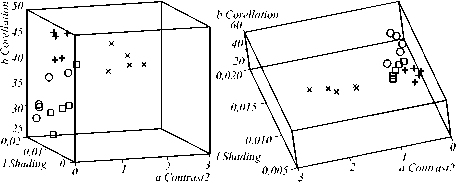
Рис. 4. Расположение объектов в пространстве 2
Таблица 1. Значения критерия 1
|
lS |
α K 2 |
β S |
10,66213 |
|
α S |
α K 2 |
β S |
10,66211 |
|
α R |
α S |
β S |
2,08106 |
Таблица 2. Значения критерия 2
|
lS |
α K 2 |
β R |
163,95 |
|
lS |
α K 2 |
β S |
159,86 |
|
lK 2 |
lI 2 |
α R |
3,38 |
Таблица 3. Значения критерия 3
|
lS |
α K 2 |
β S |
17,09 |
|
lI 1 |
α S |
α K 2 |
17,01 |
|
lK 2 |
lI 2 |
α R |
1,80 |
Заключение
В работе предложен метод вычисления цветотекстурных признаков, основанный на вычислении статистических характеристик двумерных случайных полей. Экспериментальные исследования проводились на натурных изображениях клеток крови. Работа алгоритма сравнивалась с уже реализованными алгоритмами на основе МВР. В результате сделаны следующие выводы:
-
1. Полученные признаки позволяют проводить автоматическую классификацию клеток крови.
-
2. Алгоритм обладает высокой скоростью, в сравнении с методами, основанными на анализе матрицы вероятности [5, 6].
Анализ проведенных экспериментальных исследований свидетельствует о том, что разработанные алгоритмы могут применяться для системы диагностики заболеваний крови. Одним из достоинств работы можно назвать сокращение затрат времени на обработку изображения.
Работа выполнена при поддержке российско-американской программы «Фундаментальные исследования и высшее образование» (BRHE) и программы Президиума РАН «Фундаментальные науки – медицине», гранта РФФИ № 06-07-08006-офи, гранта РФФИ № 07-08-96611.
