Разработка модели машинного обучения для прогнозирования признаков одаренности у перспективных абитуриентов по их подпискам на сообщества в социальной сети

Автор: Маганков Кирилл Сергеевич, Рябцев Николай Павлович, Юркова Ольга Николаевна
Статья в выпуске: 1 (21), 2023 года.
Бесплатный доступ
В данной статье особое внимание уделяется разработке модели машинного обучения для классификации одарённых старшеклассников, осуществляемых на основе анализа сообществ «ВКонтакте». Описывается процесс разработки, обуславливается значимость направления исследования и эффективность выбранного метода.
Машинное обучение, классификация, одарённые старшеклассники, образование
Короткий адрес: https://sciup.org/140303591
IDR: 140303591 | УДК: 338.1
Текст научной статьи Разработка модели машинного обучения для прогнозирования признаков одаренности у перспективных абитуриентов по их подпискам на сообщества в социальной сети
Данное научное исследование посвящено изучению феномена одаренности у старшеклассников. Для достижения этой цели был проведен анализ данных, полученных из социальной сети «ВКонтакте», с целью прогнозирования признаков одаренности.
Актуальность данной темы обусловлена тем, что одаренные ученики обладают значительным потенциалом для достижения успеха в учебе и в жизни в целом. Однако, этот потенциал не всегда проявляется явно и может остаться незамеченным педагогами и родителями.
Прогнозирование одаренности старшеклассников может помочь определить их потенциал и выявить области, в которых они могут достичь наибольших успехов. Это позволит педагогам и родителям разрабатывать индивидуальные учебные планы и программы, а также предоставлять дополнительную поддержку и стимул для развития талан- тов учеников. Кроме того, прогнозирование одаренности может помочь самим ученикам более осознанно планировать свое будущее и выбирать карьерные пути, соответствующие их способностям и интересам [1,2].
С помощью современных технологий анализа больших данных можно получить информацию из социальных сетей, которая может помочь улучшить качество высшего образования и расширить рынок образовательных услуг в регионах. Для этого необходимо обнаруживать закономерности в данных, которые позволят выявить интересы и профессиональные увлечения будущих студентов, а также определить особенности формирования их про-филя[3].
Согласно современной научной концепции, под одаренностью понимается комплексное взаимодействие различных качеств личности, таких как:

-
1. Интеллект - способность быстро усваивать новую информацию, анализировать ее и использовать для решения сложных задач.
-
2. Креативность — это способность к креативному мышлению.
-
3. Мотивация - одаренные люди обладают внутренней мотивацией, стремлением к достижению высоких результатов в том, что они делают, и к поиску новых вызовов и возможностей.
-
4. Личностные особенности - одаренность может также проявляться в ряде личностных особенностей, таких как высокая самооценка, уверенность в себе, умение работать в команде и стрессоустойчивость.
Одаренные люди могут придумывать новые и нестандартные решения задач, видеть скрытые связи между вещами и создавать что-то новое и оригинальное.
Все данные качества в совокупности обеспечивают высокий уровень достижений в различных сферах деятельности. Одаренными считаются люди, обладающие высоким уровнем развития указанных качеств или способные их развить и эффективно использовать в любой потенциально ценной деятельности. В современной психологии одаренность рассматривается как многомерный и изменчивый феномен, зависящий от многих факторов, таких как генетические, социокультурные и образовательные [3,4].
Таким образом следует, что для проведения данного анализа были использованы методы машинного обучения.
Рисунок 1. Фрагмент исходных данных по сообществам с ключевыми словами «Образование», «Ученики», «Школьники»
Это объясняется тем, что данные, с которыми работали исследователи, содержали большое количество признаков и были сложны для анализа вручную. Вместо того чтобы пытаться разобраться в этих данных вручную, авторами статьи было принято решение применить методы машинного обучения для автоматического извлечения закономерностей и обнаружения скрытых паттернов в данных. В результате этого были получены более точные прогнозы и улучшены результаты работы.
Машинное обучение — это процесс, в котором компьютерные системы могут обучаться на основе предыду-
Рисунок 2. Фрагмент исходных данных по подписчикам сообществ, найденных по запросу
|
User ID |
Аналоги |
Числовы e ряды |
Беглость |
Образная адаптивная гибкость |
Семантическая спонтанная гибкость |
Оригина льность |
Неза виси мость |
Креативное поведение |
Лознават ельный мотив |
Мотив само реал и вации |
Инициат ивность |
Настойчи вость |
Проф. Компетент ность |
Автономия |
|
244114303 |
2 |
5 |
10 |
5 |
7 |
6 |
5 |
3 |
1 |
1 |
3 |
22 |
9 |
11 |
|
532104981 |
8 |
1 |
7 |
6 |
6 |
5 |
7 |
1 |
2 |
2 |
1 |
21 |
10 |
13 |
|
500655531 |
19 |
2 |
5 |
4 |
4 |
6 |
10 |
3 |
2 |
2 |
3 |
23 |
15 |
11 |
|
73665061 |
8 |
2 |
8 |
6 |
5 |
8 |
8 |
1 |
2 |
2 |
2 |
20 |
6 |
19 |
|
499813555 |
9 |
3 |
9 |
7 |
9 |
9 |
3 |
3 |
2 |
2 |
1 |
14 |
18 |
18 |
|
613215301 |
20 |
3 |
5 |
7 |
4 |
7 |
7 |
2 |
2 |
1 |
2 |
23 |
17 |
13 |
|
80667768 |
17 |
1 |
8 |
6 |
5 |
10 |
7 |
3 |
2 |
2 |
3 |
23 |
20 |
И |
|
592109834 |
18 |
4 |
6 |
4 |
8 |
7 |
6 |
1 |
2 |
3 |
2 |
13 |
13 |
14 |
|
448296152 |
20 |
1 |
6 |
4 |
8 |
9 |
3 |
2 |
1 |
2 |
3 |
26 |
13 |
10 |
|
155132771 |
9 |
1 |
7 |
5 |
7 |
8 |
10 |
3 |
1 |
1 |
2 |
13 |
13 |
15 |
|
514544228 |
2 |
3 |
5 |
4 |
9 |
10 |
5 |
1 |
2 |
3 |
3 |
30 |
19 |
18 |
|
593716628 |
20 |
1 |
6 |
5 |
8 |
5 |
3 |
2 |
1 |
1 |
2 |
15 |
18 |
14 |
|
479232927 |
9 |
1 |
8 |
6 |
9 |
9 |
7 |
2 |
2 |
1 |
2 |
25 |
20 |
17 |
|
269441065 |
16 |
2 |
8 |
8 |
4 |
9 |
2 |
1 |
2 |
1 |
1 |
16 |
14 |
13 |
|
29352300 |
10 |
1 |
5 |
7 |
4 |
9 |
9 |
3 |
1 |
3 |
2 |
12 |
12 |
18 |
|
23560774 |
18 |
3 |
6 |
5 |
9 |
8 |
1 |
2 |
1 |
1 |
3 |
12 |
16 |
10 |
|
4409676 |
2 |
3 |
6 |
7 |
9 |
8 |
3 |
2 |
2 |
3 |
3 |
17 |
6 |
20 |
|
697005110 |
11 |
4 |
5 |
8 |
4 |
8 |
10 |
3 |
1 |
1 |
3 |
22 |
15 |
19 |
|
730739682 |
13 |
2 |
9 |
5 |
9 |
10 |
9 |
1 |
2 |
2 |
1 |
27 |
6 |
17 |
Рисунок 3. Фрагмент исходных данных по многопрофильному тестированию
щего опыта. Одной из наиболее распространенных задач машинного обучения является классификация объектов на основе определенных признаков. Эта задача решается на основе модели, которая обучается на предварительно подготовленном наборе данных - дата сете [5].
Для создания модели машинного обучения необходимо иметь достаточное количество данных, чтобы модель могла выявлять закономерности и обучаться. Кроме того, выбор и подготовка данных являются критически важными этапами в процессе разработки модели. Набор данных должен быть репрезентативным и покрывать все возможные варианты объектов, которые будут классифицироваться в рамках задачи.
Результаты классификации машинного обучения могут быть более точными, чем результаты, получаемые при классификации вручную. Машинное обучение также может быть использовано для анализа большого количества данных и автоматизации процессов принятия решений. Однако, важно помнить, что выбор модели и качество данных, на которых она обучается, могут значительно повлиять на результаты классификации.
|
User ID |
IM |
CM |
MM |
PM |
|
244114303 |
7 |
36 |
2 |
45 |
|
532104981 |
9 |
32 |
4 |
45 |
|
500655531 |
21 |
32 |
4 |
52 |
|
73665061 |
10 |
36 |
4 |
47 |
|
499813555 |
12 |
40 |
4 |
51 |
|
613215301 |
23 |
32 |
3 |
55 |
|
80667768 |
18 |
39 |
4 |
57 |
|
592109834 |
22 |
32 |
5 |
42 |
|
448296152 |
21 |
32 |
3 |
52 |
|
155132771 |
10 |
40 |
2 |
43 |
|
514544228 |
S |
34 |
5 |
70 |
|
593716628 |
21 |
29 |
2 |
49 |
|
479232927 |
10 |
41 |
3 |
64 |
Рисунок 4. Классификация результатов тестирования
VK API - мощный инструмент для получения данных из социальной сети ВКонтакте. С помощью VK API можно получить доступ к различным типам данных, таким как информация о пользователях, сообществах, постах, комментариях и многое другое.
Этот инструмент может быть использован для сбора данных для создания дата сета для модели машинного обучения. Например, можно использовать VK API для получения комментариев на определенную тему или для сбора постов из группы с определенным количеством лайков или комментариев.
С помощью VK API можно получить большое количество данных, которые могут быть использованы для обучения модели машинного обучения, что позволит сделать более точные прогнозы и классификации. Однако, при использовании VK API необходимо учитывать требования пользовательского соглашения и ограничения на количество запросов к API в сутки.
После того, как основные исходные данные были получены, имелась необходимость в их обработке и классификации.
Для классификации полученных данных по школьникам потребовалось рассчитать вес по 4-ём основным признакам: IM – интеллект, CM – креативность, MM – мотивация, PM – личность для каждого подписчика сообщества.
Расчёт производился по формуле:
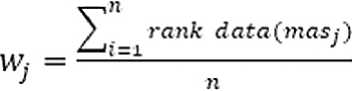
где Wj – коэффициент, характеризующий вес j-го ученика по i-му признаку;
masi – результаты по тестированию i-го ученика;
rankdata – функция вычисления рангового индекса списка;
n – количество абитуриентов.

|
User ID |
IM |
CM MM |
PM |
Интеллект |
Креативность |
Мотивация |
Личность |
|
|
244114303 |
0,15 |
0,49 |
0,07 |
0,27 |
3 |
2 |
3 |
2 |
|
532104981 |
0,23 |
0,24 |
0,54 |
0,27 |
2 |
2 |
1 |
2 |
|
500655531 |
0,73 |
0,24 0,54 |
0,5 |
1 |
2 |
1 |
2 |
|
|
73665061 |
0,27 |
0,49 |
0,54 |
0,34 |
2 |
2 |
1 |
2 |
|
499813555 |
0,36 |
0,7 |
0,54 |
0,46 |
2 |
1 |
1 |
2 |
|
613215301 |
0,78 |
0,24 |
0,27 |
0,59 |
1 |
2 |
3 |
1 |
|
80667768 |
0,6 |
0,66 |
0,54 |
0,65 |
1 |
1 |
1 |
1 |
|
592109834 |
0,76 |
0,24 |
0,74 |
0,17 |
1 |
2 |
1 |
3 |
|
448296152 |
0,73 |
0,24 |
0,27 |
0,5 |
1 |
2 |
3 |
2 |
|
155132771 |
0,27 |
0,7 |
0,07 |
0,2 |
2 |
1 |
3 |
3 |
|
514544228 |
0,07 |
0,37 |
0,74 |
0,8 |
3 |
2 |
1 |
1 |
|
593716628 |
0,73 |
0,09 |
0,07 |
0,41 |
1 |
3 |
3 |
2 |
|
479232927 |
0,27 |
0,73 |
0,27 |
0,77 |
2 |
1 |
3 |
1 |
|
269441065 |
0,6 |
0,24 |
0,27 |
0,24 |
1 |
2 |
3 |
2 |
Рисунок 5. Фрагмент полученных результирующих, классифицированных данных о студентах с перцентилями по ключевым признакам
Полученные результаты были распределены на классы от 1 до 3 по каждому признаку (1 класс – высокий уровень: 75 перцентиль и выше, 2 – средний: от 26 до 74 перцентиля, 3 – низкий: 25 перцентиль и ниже) в зависимости от полученных баллов по многопрофильному тестированию.
Что касается информации по сообществам, то рассчитанные классы (рисунок 5) были использованы для построения матрицы, где в строке указывается id сообщества, а в столбцах, на пересечении, количество учащихся, подписавшихся на это сообщество и про ранжированных по результатам тестирования (рисунки 3, 4).
После чего для каждого класса, в зависимости от признака, была найдена его доля:
classy
Ei=iclassii
где pij – доля учеников в i-ом признаке j-го уровня, n=3.
Далее был рассчитан условный коэффициент, показывающий преобладание в сообществе одаренных учеников: отрицательное значение – в сообществе преобладают уча- щиеся с низким результатом тестирования, положительное значение – в сообществе преобладают учащиеся с высоким результатом тестирования:
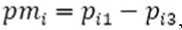
где pmi – разность между высоким и низким классом i-го признака
|
Group ID |
IM |
CM |
MM |
PM |
|
184025088 |
-1 |
-1 |
-1 |
0 |
|
1 |
1 |
1 |
1 |
0 |
|
12 |
0 |
-1 |
-1 |
1 |
|
23592973 |
-0,57 |
0 |
1 |
-0,33 |
|
14 |
-1 |
0 |
-1 |
0 |
|
31457299 |
1 |
-1 |
1 |
-1 |
|
109314072 |
-1 |
-1 |
1 |
0 |
|
191365145 |
o |
0 |
-1 |
-1 |
Рисунок 7. Фрагмент исходных данных по классификации сообществ
|
UserID |
IM |
Классифи кафя |
Кол-во маркерных сообществ |
Общее кол-во сообществ |
|
244114303 |
-14,5680 |
3 |
5 |
108 |
|
532104981 |
0,1850 |
2 |
2 |
11 |
|
500655531 |
0,9636 |
1 |
216 |
221 |
|
73665061 |
-0,2367 |
2 |
6 |
56 |
|
499813555 |
0,1031 |
2 |
13 |
145 |
|
613215301 |
1,0000 |
1 |
2 |
2 |
|
80667768 |
0,6744 |
1 |
77 |
119 |
|
592109834 |
1,0000 |
1 |
8 |
9 |
|
448296152 |
0,8220 |
1 |
56 |
66 |
|
155132771 |
0,0000 |
2 |
0 |
1 |
|
514544228 |
-22,7033 |
3 |
3 |
87 |
|
593716628 |
0,8325 |
1 |
4 |
4 |
Рисунок 8. Фрагмент результирующих классифицированных данных по анализу

На основании этих результатов можно определить преобладание у ученика одного из четырех признаков (интеллект, креативность, мотивация, личность) и дающий вес каждому сообществу:
SM. = ^^ , J n где SMj – коэффициент, характеризующий j-го ученика, подписанного на i-ые сообщества;
n – количество маркерных подписок у абитуриента;
Таким образом, была построена модель, с помощью которой удалось определить одарённых старшеклассников на основе их подписок на сообщества в социальной сети «ВКонтакте».
Результат работы модели на рис. 9.
Режим доступа к модели и исходные данные:
Начало обработки : 2022-06-10 14:08:09.104878
Обработка пользователей Время открытия файла : 0.3 сек. Student loading... 1513 of 1513 Calculate values 1513 of 1513 Обработано записей : 1513 Время обработки : 3.39 сек.
Обработка подписок
Время открытия файла : 9.5 сек.
Community loading... 100439 of 100439 Community processing... 100439 Of 100439 Community saving...
Обработано записей : 100439 Время обработки : 344.79 сек.
Конец обработки : 2022-06-10 14:24:33.964201
Общее время обработки : 984.86 сек.
Рисунок 9. Результат выполнения скрипта
Список литературы Разработка модели машинного обучения для прогнозирования признаков одаренности у перспективных абитуриентов по их подпискам на сообщества в социальной сети
- Коршунов А. и др. Анализ социальных сетей: методы и приложения //Труды Института системного программирования РАН. – 2014. – Т. 26. – №. 1
- Коршунов А. и др. Определение демографических атрибутовпользователей микроблогов //Труды Института системного программированияРАН. – 2013. – Т. 25, стр. 179-194. DOI: 10.15514/ISPRAS-2013-25-10
- Рензулли Дж. Модель обогащающего школьного обучения / Дж. Рензулли, С. М. Рис // Основные современные концепции творчества и одаренности. – М., 1997. – С. 214-242.
- Щебланова Е. И. Одаренность как психологическая система: структура и динамика в школьном возрасте: дис. д-ра психол. наук / Е. И. Щебланова. – М.,2006. – 311 с.
- Введение в машинное обучение [Электронный ресурс] // URL: https://www.intuit.ru/studies/courses/10621/1105/lecture/17981 (дата обращения:13.05.2023)
