Разработка парсера расписания железнодорожных поездов

Автор: Кожуханцева Ирина Валентиновна, Стучилин Владимир Валерьевич
Журнал: Горные науки и технологии @gornye-nauki-tekhnologii
Статья в выпуске: 7, 2011 года.
Бесплатный доступ
В данной статье содержится материал по созданию парсера пригород- ных поездов посредством языка PHP, Web-сервера Apache и СУБД MySQL. Данный парсер является частью информационной системы для информационных киосков, призванных сделать поиск расписания электри- чек более быстрым и удобным для пассажиров. В статье рассматривается 42 структура информационной системы, аргументирование выбора ресурса актуального расписания, выбор технологии парсинга, структура про- граммного обеспечения сервера, структура базы данных, в которую полу- ченная информация заносится и затем передается на терминал конечному пользователю.
Парсер, парсинг, расписание, расписание железнодорожных поездов, информационный терминал, регулярные выражения, база данных
Короткий адрес: https://sciup.org/140215358
IDR: 140215358 | УДК: 004.414.28
Текст научной статьи Разработка парсера расписания железнодорожных поездов
Информационный терминал, или информационный киоск, стал необходимым атрибутом современного бизнеса. Он представляет собой устройство, оснащенное дисплеем с сенсорным экраном и специализированным компьютером. Такой киоск дает возможность потенциальному клиенту ознакомиться с продукцией или услугами компании, найти ответы на интересующие вопросы. Информация, предоставляемая информационным терминалом, является достоверной и актуальной. Простая, разумно организованная база данных, настроенная под специфику учреждения, облегчает работу пользователя и делает ее удобной.
Устанавливаются терминалы там, где посетитель может быстро и удобным для него способом получить необходимую информацию. Станции пригородных поездов – это место с большим потоком пассажиров, нуждающихся в своевременном осведомлении о расписании. На данный момент централизованный источник данных, предоставляющий такую информацию быстро и удобным для пассажиров способом, отсутствует. Информационные киоски могут стать решением данной проблемы и оперативно снабжать посетителей станций пригородного сообщения требуемой информацией.
Целью данной работы является автоматизированное получение актуального расписания железнодорожных поездов для использования в информационных киосках.
В задачи проекта входят:
-
1. Выбор технологии получения актуальной информации.
-
2. Разработка алгоритмов для получения информации.
-
3. Разработка структуры базы данных.
-
4. Создание и апробация программного обеспечения.
Структура информационной системы
В структуре информационной системы, представленной на рис. 1, отправной точкой является источник информации, необходимый для напол- нения содержания системы. Здесь он представлен Интернет-ресурсом «Яндекс. Расписания».
Такой выбор обусловлен тем, что данный ресурс отвечает всем заданным критериям, а именно:
-
• информативности;
-
• актуальности;
-
• возможности и простоты работы с кодом страницы.
Информационные терминалы
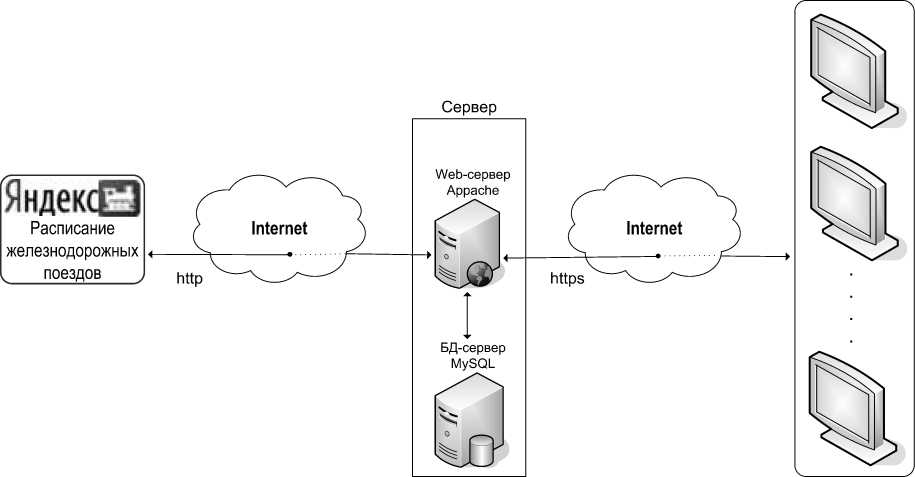
Рис. 1. Структура информационной системы.
«Яндекс. Расписания» являются лидером в рейтинге служб по предоставлению информации такого рода, потому что обладают доступным и удобным интерфейсом и ссылаются на официальные источники, в числе которых ОАО «Центральная пригородная пассажирская компания» [6]. В силу последнего факта этот ресурс обновляется минимум раз в день, в нем всегда учтены все последние изменения в расписании пригородных поездов.
С точки зрения программирования «Яндекс. Расписания» также подходят для данного программного обеспечения, так как код страниц сайта хорошо структурирован, что облегчает задачу извлечения из них нужной информации.
Для универсализации проекта планируется прибегнуть к услугам альтернативного источника данных, который будет подстраховывать информационную систему в случае сбоев работы основного ресурса.
Следующим звеном, на котором и будет работать парсер расписания, является выделенный сервер установленный в дата-центре провайдера (collocation).
Collocation – это физический хостинг, предполагающий установку сервера на техническом узле интернет-провайдера. Под хостингом подразумевается обособленное технически оборудованное помещение с гарантированными условиями хранения данных (бесперебойное электропитание, температурный режим, охрана, системы пожарной безопасности и так далее) [4]. Его преимущества:
-
• предоставляется полная свобода выбора программного и аппаратного обеспечения;
-
• объем свободного пространства ограничивается только техническими характеристиками сервера.
Такой вид хостинга очень удобен для ресурсов с большим трафиком, так как скорость обмена данных при установке сервера на техническом узле ощутимо увеличивается [5]. Альтернативой выделенному серверу является виртуальный хостинг, подразумевающий размещение виртуального Web-сервера на территории интернет-провайдера, чьи ресурсы разделяются им с другими виртуальными серверами. Но такое разделение неизбежно ведет к снижению скорости работы системы, установленной на виртуальном сервере, и при этом его владелец ограничен программными ресурсами, предоставляемыми провайдером.
На физическом сервере будут установлены два программных: Web-сервер и БД-сервер.
Парсер расписания будет функционировать на Web-сервере Apache. Apache HTTP-сервер (от англ. a patchy server) – свободный Web-сервер. Apache является кроссплатформенным программным обеспечением, т.е. поддерживает множество операционных систем: Linux, BSD, Mac OS, Microsoft Windows, Novell NetWare, BeOS.
Основными достоинствами Apache считаются надёжность и гибкость конфигурации. Он позволяет подключать внешние модули для предоставления данных, использовать СУБД для аутентификации пользователей, модифицировать сообщения об ошибках и т. д. Ядро Apache включает в себя основные функциональные возможности, такие как обработка конфигурационных файлов, протокол HTTP и система загрузки модулей [10].
После получения данных будет осуществляться связь с сервером баз данных MySQL для занесения в него полученной информации.
MySQL – это свободная система управления базами данных (СУБД). Гибкость СУБД MySQL обеспечивается поддержкой большого количества типов таблиц: пользователи могут выбрать как таблицы типа MyISAM, поддерживающие полнотекстовый поиск, так и таблицы InnoDB, поддерживающие транзакции на уровне отдельных записей. Более того, СУБД
MySQL поставляется со специальным типом таблиц EXAMPLE, демонстрирующим принципы создания новых типов таблиц.
Главное достоинство MySQL состоит в том, что она распространяется бесплатно [1].
Последней частью информационной системы, с которой непосредственно взаимодействуют пользователи, являются информационные терминалы (информационные киоски). Сформированная парсером информация из базы данных передается на них при помощи специального программного обеспечения (в данной статье не рассматривается).
Выбор технологии парсера
В качестве инструмента программирования парсера выступает скриптовый язык PHP. PHP (англ. Hypertext Preprocessor – препроцессор гипертекста) – это широко используемый язык сценариев общего назначения с открытым исходным кодом. Этот язык был специально разработан для написания web-приложений (сценариев), исполняющихся на Web-сервере [3].
Использование языка программирования РНР обусловлен следующими характеристиками:
-
• простотой;
-
• эффективностью;
-
• безопасностью;
-
• гибкостью.
Также PHP обладает довольно широким набором методов парсинга.
Парсинг (англ. parsing) – это автоматизированный сбор всего содержимого или конкретных данных с какого-либо сайта или сервиса. Скрипт или программа, занимающаяся, непосредственно, сбором, анализом и преобразованием требуемой информации называется парсером [8].
Любой парсер состоит из трех частей, которые отвечают за три отдельных процесса:
-
1. Получение информации в исходном виде;
-
2. Извлечение и преобразование данных;
-
3. Генерация результата.
Основными инструментами парсинга, которые предлагает PHP являются:
-
• объектная модель Документа (DOM);
-
• интерфейс Simple API for XML (SAX);
-
• парсер SimpleXML;
-
• парсер XPath;
-
• регулярные выражения (regular expressions).
Базовыми понятиями при работе с текстом источника обрабатываемой информации являются XML и HTML.
HTML (англ. Hypertext Markup Language – язык разметки гипертекста) – это стандартный язык разметки документов во Всемирной паутине.
XML (англ. eXtensible Markup Language – расширяемый язык разметки) – рекомендованный Консорциумом Всемирной паутины язык разметки, фактически представляющий собой свод общих синтаксических правил. XML – текстовый формат, предназначенный для хранения структурированных данных, для обмена информацией между программами, а также для создания на его основе более специализированных языков разметки (например, XHTML) [2].
Наиболее общей задачей обработки XML является именно разбор XML-документа, т.е. парсинг. Он включает в себя чтение XML-документа для определения его структуры и содержимого [9].
При разработке программы Парсера расписания была выбрана ориентация на один формат HTML по следующим причинам:
-
• текст в формате HTML, в отличие от XML, может содержать незакрытые теги, как, например, широко используемый тег переноса строки
в HTML; -
• в XML значения атрибутов обязательно должны быть заключены в кавычки, а HTML допускает возможность использования атрибутов без кавычек;
-
• помимо этого, HTML является старейшим форматом текста в web-пространстве и также поддерживается абсолютно всеми браузерами.
Вывод: данный формат является более универсальным и независимым форматом текстовых данных, к тому же текст любого другого формата легко преобразовать в формат HTML.
Большинство из выше указанных парсеров предназначены для работы именно с XML. Среди их прочих неудобств для данного программного обеспечения можно отметить следующие:
-
• DOM строит в памяти дерево XML-документа, следовательно, если документ действительно большой, дерево DOM может требовать большого объема памяти;
-
• дерево DOM содержит множество объектов, представляющих содержимое исходного XML-документа, следовательно, если требуется лишь часть документа, создание этих объектов вызывает необоснованное усложнение кода;
-
• парсер DOM должен построить полное дерево DOM прежде, чем код сможет работать с ним, следовательно, при разборе большого XML-документа, можно получить значительную задержку, ожидая, пока парсер закончит работу;
-
• парсер SAX разработан с меньшими требованиями к объему памяти, но он перекладывает больше работы на программиста;
-
• события SAX не сохраняют состояние, т.е. нельзя посмотреть на отдельное событие SAX и вычислить его содержимое;
-
• парсеры SimpleXML и XPath значительно облегчает работу с XML-файлами по сравнению с DOM и SAX, но в нашем случае они не подходит, так как требуют наличия определенных тегов в структуре текста.
Регулярные выражения – это специальный язык для работы с текстом. Причём подчас одна строчка с их использованием может заменить несколько страниц обычного кода. С помощью регулярных выражений можно эффективно искать фрагменты текста любой сложности, заменять одни вхождения на другие.
Основа регулярного выражения – шаблон. С его помощью мы описываем формат нужного нам фрагмента текста, а затем либо проверяем, подходит ли текст под шаблон, либо вырезаем одно или несколько вхождений шаблона, либо заменяем на какой-либо текст [7].
Регулярные выражения являются более простым методом, предлагаемым языком PHP, для достижения поставленных нами целей по сравнению с XML-парсерами. Регулярные выражения характеризуются отсутствием необходимости использования усложненных инструментов, занимающихся разборкой структуры текста или основанных на большом количестве внутренних методов, и большей эффективностью, чем поэтапный разбор и выборка текстовых фрагментов посредством других функций работы с символами.
Структура программного обеспечения сервера
Программное обеспечение сервера состоит из следующих модулей:
-
1. Модуль работы с базой данных;
-
2. Модуль работы с удаленным сервером;
-
3. Модуль администрирования парсера (служит для редактирования полученной информации, задания графика ее обновления и т.д.);
-
4. Модуль работы с информационным киоском.
Модуль работы с базой данной предназначен для установления соединения с БД-сервером, аутентификации пользователя и перехода на нужную кодировку. Его алгоритм представлен на рис. 2.
Модуль работы с удаленным сервером является ключевой частью парсера расписания и предназначен для соединения с источником информации, извлечения данных оттуда, преобразования данных в требуемую форму и последующее занесение этих данных в базу. Также эта подпрограмма дает возможность отследить время выполнения скрипта. Алгоритм этого модуля представлен на рис. 3.
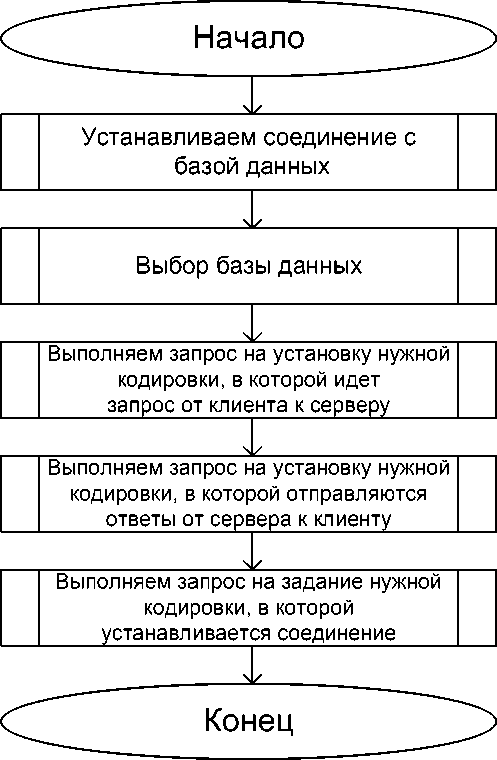
Рис. 2. Алгоритм модуля работы с базой данных.
Модуль администрирования парсера служит для редактирования базы данных.
Модуль работы с информационным киоском предназначен для передачи данных из базы на терминал в удобном для конечного пользователя виде и не является частью данного проекта.
Структура базы данных
При работе парсера расписания происходит частое обращения к базе данных как для добавления туда информации, так и для извлечения. При таком режиме работы лучше всего подходит тип таблиц MyISAM СУБД MySQL (без поддержки транзакций).
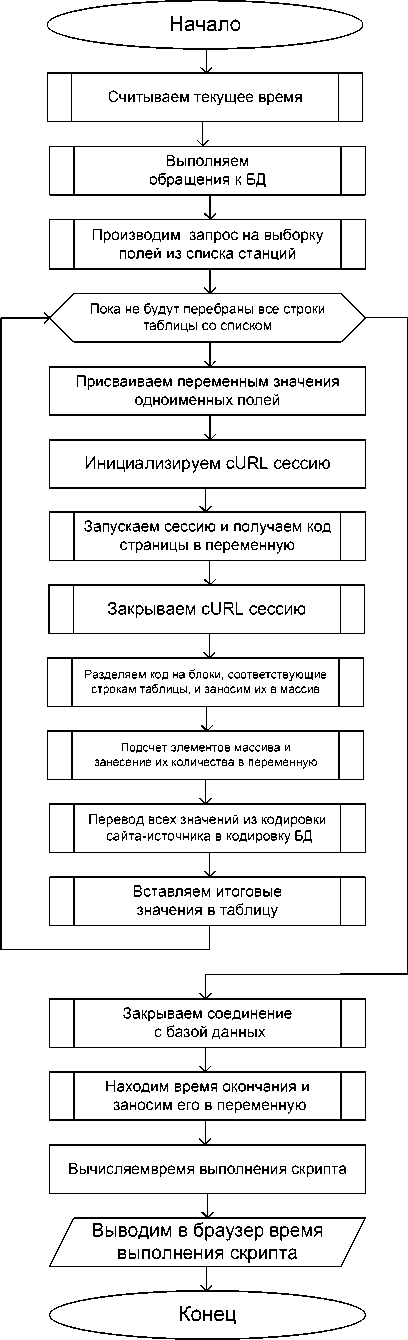
Рис.3. Алгоритм модуля работы с удаленным сервером.
В связи с тем, что вся информация, содержащаяся в базе данных, будет на русском языке, а кодировка источника информации, utf-8, не всегда воспринимается операционной системой Windows корректно, в качестве кодировки таблиц выбрана cp1251_general_ci.
База данных состоит из двух таблиц:
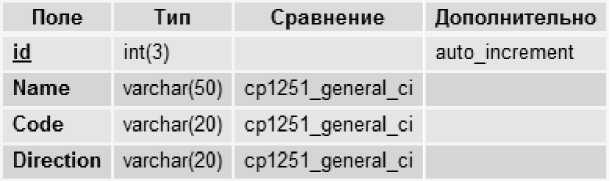
Рис. 4. Структура таблицы Stations.
Все поля представлены типом varchar с обозначением длины, так как хранят в себе текстовую информацию разного объема.
Таблица «Schedule» cодержит полученные данные в требуемой форме и имеет структуру, показанную на рис. 5.
|
Попе |
Тип |
Сравнение |
Допопнитепьно |
|
id |
int(5) |
autojncrement |
|
|
Direction |
varchar(50) |
cp1251_general_ci |
|
|
Station |
varchar(50) |
cp1251_general_ci |
|
|
Train |
varchar(200) |
cp1251_general_ci |
|
|
Arrival time |
varchar(15) |
cp1251_general_ci |
|
|
Stops |
varchar(500) |
cp1251_general_ci |
|
|
Days |
varchar(300) |
cp1251_general_ci |
Рис. 5. Структура таблицы Schedule.
Пример выполнения программы
После генерации скрипта модуля работы с удаленным сервером, в который включен программно модуль работы с базой данных, получаем заполненные таблицы, представленные на рис. 6, 7.
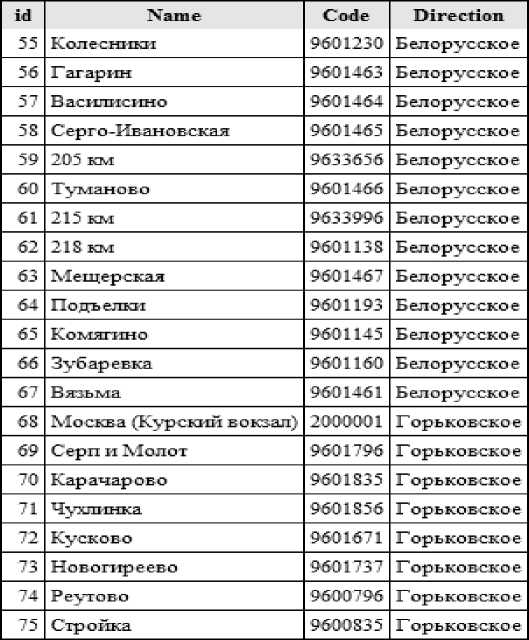
Рис. 6. Итоговый вид таблицы Stations.
|
id |
Direction |
Station |
Train |
Arrival time |
Stops |
Dii-s |
|
11561 |
Горьковское |
Бдаднха«р |
Н-Нэвгсрод-хкЕ- - Владимир |
19:42 экспресс |
ПО Е1С.Э1НЫМ |
|
|
11562 |
Горексвское |
Вдаднхзф |
Владимир - Легуизн |
20-25 |
кроме Красная Osota |
ежедневно |
|
1156Э |
Гор*кс®скс4 |
Бдадпмгр |
М-Курская - Влазыир |
20:41 экспресс |
ежедневно |
|
|
11561 |
Горккоеское |
Бладихзгр |
Влажмнр - Тумскан |
20:50 |
везде |
ежедневно |
|
11565 |
Горьковское |
Власи с ст |
Владимир- Ковров-1 |
2125 |
кроме Актог^ивбор |
ежедневно |
|
11566 |
Горексеское |
Влалс лгр |
Вязники- Влад|г-!яр |
21:45 |
ежедневно |
|
|
11567 |
Горекоеско* |
Влалмгр |
M-Курская- ВладЕмгр |
2351 экл^хесс |
ежедневно |
|
|
11568 |
Казанское |
Моема (Казанский вокзал) |
М-Казанская- Шэтхра |
04:10 |
кроме Фрезер. Плюпуевс- Зеслниюк Косино |
ежедневно 4>оме 6, '. $, 9,10.13.14,15.16,1_ |
|
11566 |
Казанское |
Моема (Казанский вокзал) |
М-Казанская- А1ск«®о |
04:10 |
кроме Фрезер. Глпокэево Зегпнэтэк Косино |
таеко 6,7, L 9,10,13,14,15,16,17,20, 21_ |
|
11570 |
Казанское |
^ locaa (Казанский вокзал) |
М-Казавоал- Голхтем! |
05:14 |
везде |
ежедневно |
|
1154 |
Каинское |
Москва (Казанский вокзал |
М-Казанская- 4 ш |
0530 |
ве:зе |
ежедневно |
|
11572 |
Казанское |
Моема (Казанский вокзал) |
47 км- М-Казаяскал |
0535 |
ежедневно |
|
|
11573 |
Казанское |
Москва Казанский вокзал) |
М-Каллнскал - ЬКроьзкая |
05:44 |
кроме Фрезер. Пдющево Весшлкн. Косино |
ежедневно |
|
11574 |
Казанское |
Моава 7^азаиазд1 вокзал) |
М-52азаваая - Быксео |
05:50 |
везде |
ежедневно |
Рис. 7. Итоговый вид таблицы Schedule.
Заключение
В результате проделанной работы были решены следующие задачи:
-
1. Выбрана технология парсера;
-
2. Разработаны алгоритмы программы;
-
3. Разработана структура базы данных;
-
4. Написан программный код;
-
5. Проведена апробация программы.
Результаты работы будут использованы для разработки методов, библиотек и функций универсального парсера.
Список литературы Разработка парсера расписания железнодорожных поездов
- Лозовюк А. Утилиты администраторы сервера MySQL. -[Электронный источник] -режим доступа: http://hostinfo.ru/articles/361/
- Сергеев А.П. HTML и XML. Профессиональная работа. -М.: Диалектика, 2004. -880 с. -ISBN 5-8459-0676-8
- Транский А. Основы PHP. -[Электронный источник] -режим доступа: http://www.php.su/php/
- Независимая глава «Классификация и выбор хостинга» (из некоммерческого учебника по CMS/CMF Drupal). -проект drupal.bz, 2008. -С. 96.
- Отличия Colocation от других видов хостинга. -[Электронный источник] -режим доступа: http://colocat.ru/texts/colocation.html
- Партнеры сервиса «Яндекс.Расписания». -[Электронный источник] -режим доступа: http://rasp.yandex.ru/info/partners
- Регулярные выражения. -[Электронный источник] -режим доступа: ttp://www.phpfaq.ru/regexp
- Что такое «Парсинг(Parsing)»? -[Электронный источник] -режим доступа: http://westseo.ru/article/parsing/
- Тидвел Д. XML-программирование в технологии Java. -[Электронный источник] -режим доступа: http://www.ibm.com/developerworks/xml/tutorials/xmljava/
- Хокинс С. Администрирование веб-сервера Apache и руководство по электронной коммерции. -М.: Вильямс, 2001. -336 с. -ISBN 0-13-089873-2.
