Разработка прототипа системы моделирования процессов обработки и хранения визуальной и слуховой информации человеком

Автор: Капитонов Даниил Дмитриевич
Рубрика: Управление сложными системами
Статья в выпуске: 1, 2023 года.
Бесплатный доступ
Работа посвящена созданию программной модели процессов обработки и хранения визуальной и слуховой информации человеком. Проведен анализ имеющихся материалов по работе спинного и головного мозга и механизмов по распределению и приоритизации информации, поступающей из органов зрения и слуха, возможности интеграции этих механизмов в компьютерные системы для приоритизации цифровой информации. В результате исследования определен ряд механизмов, внедрение которых в компьютерные системы снизит объем занимаемой памяти медиафайлами.
Моделирование, информационные процессы мозга, приоритизация информации, эмоциональная оценка информации, алгоритм, визуальная информация, слуховая информация
Короткий адрес: https://sciup.org/148326349
IDR: 148326349 | УДК: 004.04 | DOI: 10.18137/RNU.V9187.23.01.P.29
Development of a prototype of a system for simulation of processing and storage of visual and auditory information by a human
The work is devoted to the development of a software model for the processing and storage of visual and auditory information by a person. In the course of the work, an analysis was made of the available materials on the work of the spinal cord and the brain and the work of mechanisms for the distribution and prioritization of information coming from the organs of vision and hearing. An analysis was also made of the possibility of integrating these mechanisms into computer systems for the prioritization of digital information. As a result of the study, a number of mechanisms were identified, the introduction of which into computer systems can reduce the amount of memory occupied by media files.
Текст научной статьи Разработка прототипа системы моделирования процессов обработки и хранения визуальной и слуховой информации человеком
Проблема хранения цифровой информации с каждым годом становится всё более масштабной в связи с увеличением числа пользователей и количества создаваемой информации. При этом вся информация хранится на разных устройствах, в разных концах планеты и разных сетях.
Кроме того, большое количество информации, сохраненной на устройствах, не является нужной и зачастую вообще не используется в течение всего времени хранения. Усугубляет ситуацию и то, что в процессе хранения одни и те же данные могут быть продублированы тысячи раз и занимать большие объемы памяти [1].
Контролировать весь этот поток данных не представляется возможным ввиду отсутствия свободных вычислительных мощностей для этого процесса [2]. Поэтому необходимо разработать технологию распределения и приоритизации сохранения поступающей информации.
Капитонов Даниил Дмитриевич магистрант кафедры компьютерных систем и сетей, МГТУ имени Н.Э. Баумана (НИУ), Москва. Сфера научных интересов: математическое и программное обеспечение вычислительных систем, комплексов и компьютерных сетей; модели, методы и алгоритмы проектирования, анализа, трансформации, верификации и тестирования программ и программных систем. Автор 10 опубликованных научных работ.
Подобная технология уже несколько тысяч лет существует и активно используется организмом человека. Эта технология была выработана в процессе эволюции и обеспечивает нормальное функционирование человеческой памяти. Наш мозг постоянно получает информацию от органов чувств (зрение, слух, обоняние, вкус и осязание). При нормальной работе мозга запоминается лишь некоторая часть из всей этой информации.
Большинство информационных потоков проходят сначала через спинной мозг, попадая после в головной мозг, остальные попадают напрямую в головной мозг [3]. Несмотря на то, что спинной мозг является лишь концентратором нервных окончаний, он играет важную роль в процессе запоминания информации, которую необходимо проанализировать для получения полной схемы процесса обработки информации.
Окончательно обработкой всей поступающей информации занимается головной мозг. Нервные импульсы, проходя через отделы головного мозга, в итоге сохраняются или отбрасываются. Последовательность активации основных отделов головного мозга во время обработки информации также необходимо проанализировать и выявить основные механизмы определения важности получаемой информации.
Основная информация поступает из зрительных и слуховых рецепторов, следовательно, требуется рассмотреть методы сохранения определенной информации, поступающей из этих источников; иначе говоря, необходимо проанализировать механизм приоритизации поступающей зрительной и слуховой информации, что позволит создать модель системы по приоритизации видео- и аудиоинформации.
Объектом исследования являются механизмы обработки информации спинного и головного мозга для последующего внедрения этих механизмов в системы приоритизации сохраняемой информации [4; 5].
Система, работающая с большим количеством модулей, требует пристального контроля над информацией, которая передается от одного модуля другому [6].
На вход системы должен поступать список входных данных, которые программа должна получать в достаточном объеме, чтобы алгоритм работал корректно. При этом необходимо минимизировать количество обязательно требуемых файлов, чтобы пользователь мог пользоваться программным продуктом, обладая минимумом знаний [7].
Для этого следует сформировать список требуемых обязательных данных: аудио-, фото- или видеофайлы (медиафайлы) и текстовый файл рефлексии.
Под файлом рефлексии в программном продукте понимается текстовый файл, содержащий описание моментов, которые фигурируют в предоставленных медиафайлах в соответствии с установленными правилами:
Разработка прототипа системы моделирования процессов обработки и хранения ...
-
• файл должен иметь формат .txt;
-
• каждое предложение отделено от другого знаком «,»;
-
• каждое предложение состоит из трех фраз, если в какой-то из фраз требуется использовать пробел, он заменяется на символ «_»;
-
• порядок фразы имеет вид «кто кого(чего) что» или «кто из-за_кого (чего) что».
Необязательными данными являются: геолокация, время создания медиафайлов и рефлексии, уникальный идентификатор (далее – UID) обрабатываемого пакета данных. В случае если пользователь не ввел эти параметры, программа автоматически должна присвоить данные всех этих параметров, исходя из текущих метаданных.
После формирования перечня входных данных требуется разработать механизм распределения информации между модулями системы. Было принято решение создать главный логистический модуль, который исходя из команд от других модулей передавал бы им необходимую информацию [8].
Соответственно, необходимо создать системную папку, в которую каждый из модулей будет сохранять текстовые файлы и читать их. Для активации нового модуля требуется создать текстовый файл, содержащий последовательность символов, разделенных пробелом: UID процесса, номер активного процесса, номер модуля, который требуется запустить, и путь к папке с файлами, с которыми запускаемый модуль будет работать.
Во время работы системы могут быть одновременно активны все модули, и каждый из них будет работать в отдельном потоке, если процессор поддерживает мультипоточность, или на отдельном ядре [9]. Но не могут быть активны два одинаковых модуля, чтобы не возникало коллизий, поэтому следует реализовать очередь на активацию: программа будет запускать модули в порядке обращения системы на их запуск, позволяя не нарушать порядок обработки пакета данных.
На выходе пользователь должен получить архив с файлами, содержащий все входные данные, результат поиска эмоционального триггера, результат анализа итоговой эмоции, приоритет пакета данных. Также будут сформированы логфайлы работы запускаемых модулей во время обработки пакета данных.
В результате была спроектирована структурная схема информационной системы, представленная на Рисунке 1.
Разрабатываемая программная система может быть отнесена к разряду сложных; предполагается, что она будет обрабатывать большое количество данных различных типов. Поэтому проектирование системы целесообразно начать с разработки функциональной схемы, которая позволит не только уточнить структуру будущей системы, но и определить, с какими данными эта система будет работать.
Ниже представлен список баз данных, которые потребуются системе для нормальной работы:
-
• база данных (далее – БД) сохраненных пакетов данных – определенное место в директориях системы, куда будут помещаться обработанные пакеты данных; доступ к БД должен быть у пользователя и у системы для сохранения и удаления файлов;
-
• БД объектов, вызывающих первородные эмоции, – текстовые файлы, которые будут содержать в себе слова-триггеры первородных эмоций; доступ к БД должен быть у системы только для чтения и у администраторов системы для возможности корректировки слов-триггеров;
-
• БД объектов, которые стали источниками эмоций, – excel-таблицы, куда по категориям будут записываться объекты, которые стали источниками эмоций; доступ к БД должен быть у пользователя только для чтения и у системы с возможностью редактирования файлов;
-
• БД журналов работы системы – текстовые файлы, содержащие отчет о работе системы в данный момент времени, откуда можно будет прочитать о возникших ошибках при работе системы.
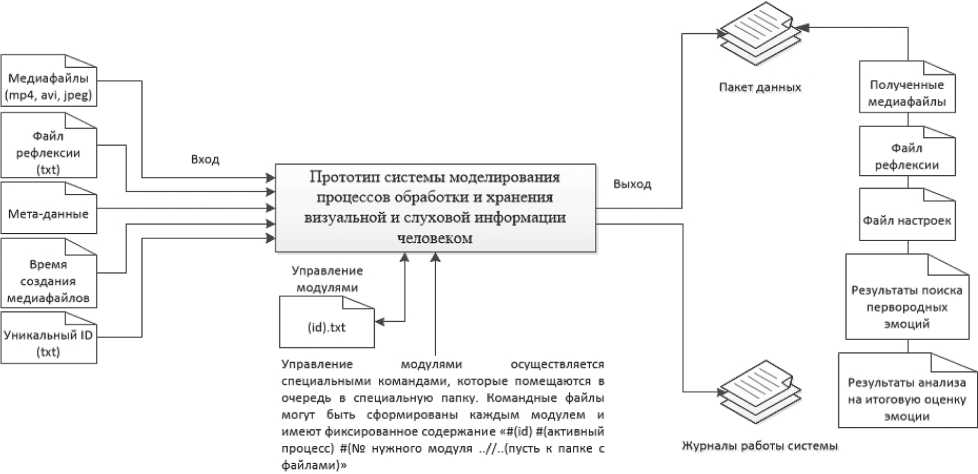
Рисунок 1. Структурная схема информационной системы Источник: составлено автором.
Затем была выполнена декомпозиция программного обеспечения на модули в соответствии с выполняемыми этими модулями операциями:
-
• главный модуль с графическим интерфейсом управления и его подсистемы:
-
– очистка устаревшей информации;
-
– анализ объема информации в системе;
-
– автоматическое определение метаданных;
-
– резервное копирование;
-
– работа с лог-файлами;
-
• модуль формирования пакетов данных;
-
• модуль распределения пакетов данных;
-
• модуль поиска объектов, вызывающих первородные эмоции;
-
• модуль поиска итоговой эмоции и установки приоритета сохранения.
В конце были добавлены модули, на вход которых пользователь будет загружать входные данные (главный модуль) и получать выходные данные (БД сохраненных объектов), куда информация будет помещена модулем поиска итоговой эмоции и установки приоритета сохранения.
Полученная функциональная схема представлена на Рисунке 2.
После проектирования функциональной схемы программного обеспечения стало понятно, что модули системы должны передавать между собой различную информацию, по-
Разработка прототипа системы моделирования процессов обработки и хранения ...
этому для уточнения, какая именно информация передается, была разработана диаграмма потока данных.
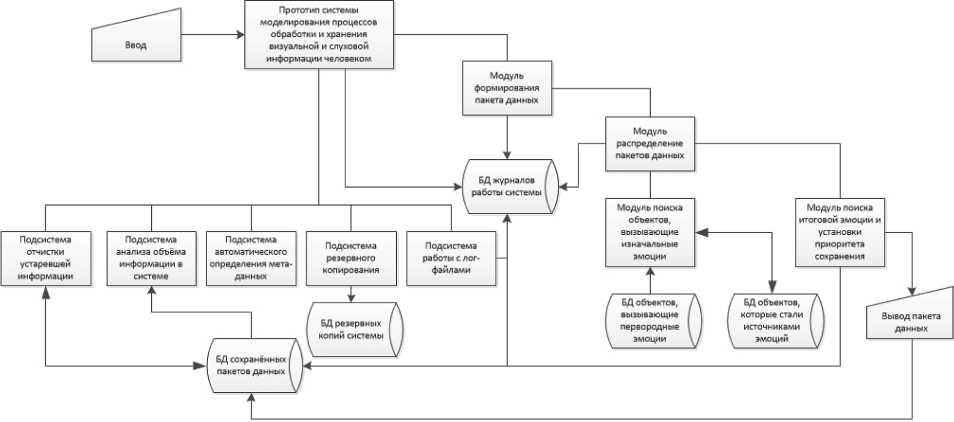
Рисунок 2. Функциональная схема программного обеспечения Источник: составлено автором.
Анализ функциональной схемы показал, что между модулями будет передаваться следующая информация:
-
• медиафайлы;
-
• файл рефлексии;
-
• метаданные;
-
• пакет данных;
-
• уникальный UID;
-
• различная системная информация;
-
• найденные первородные эмоции;
-
• результат обработки пакета данных.
При этом на вход системы от пользователя поступают медиафайлы, файл рефлексии, метаданные. Пользователь, в свою очередь, должен получать от системы обработанный пакет данных, содержащий входные файлы и результаты обработки пакета данных системой, и журналы работы системы во время обработки пакета данных.
Чтобы осуществить указанное преобразование, в системе предусмотрены пять основных модулей. Так, главный модуль, получив на вход необходимую информацию, передает модулю всю информацию, находящуюся в одной папке. Модуль формирования пакета данных формирует пакет данных, присваивает ему UID. Затем пакет данных отправляется модулю по распределению, который согласно меткам, пришедшим вместе с пакетом данных, перенаправляет его в тот или иной модуль. Модуль поиска объектов, вызывающих изначальные эмоции, проводит поиск подобных в файле рефлексии. Результаты поиска вместе с пакетом данных направляются в модуль распределения, а затем в модуль определения итоговой оценки эмоции, где пакету данных присваивается приоритет, и он помещается в хранилище.
Результаты и их обсуждение
В соответствии с разработанной технологией были выполнены испытания программного прототипа посредством тестирования программы на большом объеме поступаю- щих последовательно данных. С помощью программы по генерации случайных файлов рефлексии, содержащих фиксированный набор предметов, людей и действий различных эмоциональных типов, было автоматически сгенерировано 150 текстовых файлов, содержащих по 30 предложений. Каждый из текстовых файлов был автоматически помещен в архив с одним фото- и видеофайлом. Это было сделано для того, чтобы получить более точные сведения по объему загруженных и удаленных данных. Все сгенерированные архивы были помещены в одну папку, их общий объем составил 1603 МБ.
За время проведения предварительных испытаний в программу было в автоматическом режиме загружено 150 пакетов данных. Время, затраченное на их обработку, составило примерно 30 минут. Во время их обработки возникли три критические ошибки, которые не позволили системе корректно обработать три пакета данных. На основе журнала работы модуля был проведен анализ ошибок; выявлено, что эти ошибки вызваны неправильной работой алгоритма по автоматической генерации файлов рефлексии, который впоследствии был исправлен.
Также в результате работы системы были сформированы и другие журналы ее работы, например, журнал логистики пакетов данных, по которому можно отследить, как программа распределяла пакеты данных, в каком порядке каждый из модулей их обрабатывал.
После обработки 150 пакетов данных было выявлено:
-
• 6 новых людей, которые стали источниками эмоций;
-
• 18 новых предметов, которые стали источниками эмоций;
-
• 121 пакет данных не получил определенной оценки эмоции, что соответствует тому, что 80 % информации было отброшено как незначительной;
-
• 1343 мегабайт информации были удалены через сутки после обработки всех пакетов данных.
Заключение
Таким образом, выполнено исследование процессов обработки и запоминания информации человеческим мозгом, построены схемы преобразования информации, на основе которых разработан алгоритм приоритизации информации для ее последующего хранения.
Перспективными задачами дальнейшего исследования являются:
-
• автоматизация преобразования аудиосопровождения из видео- и аудиофайлов в напечатанный текст;
-
• автоматизация преобразования текста из аудио- и видеофайлов в файл рефлексии посредством синтаксического разбора;
-
• разработка способа распараллеливания работы модулей, которые взаимодействуют с excel-файлами;
-
• разработка удобного интерфейса для визуализации пути прохождения пакета данных через модули;
-
• повышение стабильности работы системы.
Список литературы Разработка прототипа системы моделирования процессов обработки и хранения визуальной и слуховой информации человеком
- Евтушенко О.А. Задача распределения информации в потоке сообщений, исходя из требований о ее срочности // Информатизация и связь. 2015. № 1. С. 39-40.
- Цибизова Т.Ю., Слепцова К.А. Автоматизированная система учета данных внутрикорпоративной сети управления информацией // Современные проблемы науки и образования. 2015. № 1-1. URL: https://science-education.ru/ru/article/view?id=19593 (дата обращения: 12.12.2022).
- Голубев В.И. Информация как отображение объектов окружающего мира в коре головного мозга // Информационные технологии. 2016. Т. 22. № 3. С. 233-239.
- Капитонов Д.Д., Ушаков К.Е., Малкина Т.А. Разработка алгоритма приоритизации информации на основе механизмов работы головного и спинного мозга // Будущее машиностроения России: XV Всероссийская конференция молодых ученых и специалистов (с международным участием) (Москва, 21-24 сентября 2022 г.): сборник докладов: в 2 т. М.: Изд-во МГТУ им. Н.Э. Баумана, 2022. Т. 2. С. 380-386.
- Перешеин А.О., Бендерская Е.Н. Нелинейные модели обработки информации, построенные по принципам работы гиппокамп // Наука и инновации в технических университетах: материалы Девятого Всероссийского форума студентов, аспирантов и молодых ученых. Санкт-Петербург, 27-30 октября 2015 года. СПб.: Санкт-Петербургский политехнический университет Петра Великого, 2015. С. 35-37.
- Иванова Г.С., Андреев А.М., Нефедов В.И., Шоуман М. А., Егорова Е.В. Автоматический поиск информации с использованием мультиагентной системы // Электромагнитные волны и электронные системы. 2015. Т. 20. № 2. С. 33-38.
- Капитонов Д.Д., Воскресенская О.Е., Ушаков К.Е. Применение прототипа модели процессов обработки и хранения визуальной и слуховой информации человеком для исследования различных способов установки приоритетов входной информации // XIV Всероссийская конференция молодых ученых и специалистов (с международным участием) "Будущее машиностроения России" (Москва, 21-24 сентября 2021 г.): сб. докладов. М.: Изд-во МГТУ им. Н.Э. Баумана, 2021. С. 94-97.
- Овчинников В.А., Иванова Г.С. Оптимизирующие преобразования алгоритмов, использующие свойства множеств, предикатов и операций над ними // Вестник Московского государственного технического университета имени Н.Э. Баумана. Серия: Приборостроение. 2013. № 4 (93). С. 53-66.
- Ватаманюк И.В., Яковлев Р.Н. Алгоритмическая модель распределенной системы корпоративного информирования в рамках киберфизической системы организации // Моделирование, оптимизация и информационные технологии. 2019. Т. 7, № 4 (27). С. 32-33.
