РАЗРАБОТКА ВЫСОКОПРОИЗВОДИТЕЛЬНОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ НА БАЗЕ IP-ЯДРА ДЛЯ КОСМИЧЕСКОЙ НАУЧНОЙ АППАРАТУРЫ

Автор: К. И. Сухачёв, К. Е. Воронов, А. С. Дорофеев, Д. А. Шестаков, А. А. Артюшин
Журнал: Научное приборостроение @nauchnoe-priborostroenie
Рубрика: Разработка приборов и систем
Статья в выпуске: 4 т.32, 2022 года.
Бесплатный доступ
В статье представлен результат разработки и реализации универсального синтезируемого процессорного ядра на интегральных микросхемах ПЛИС отечественного и импортного производства. Показана возможность создания высокопроизводительной вычислительной системы на базе ПЛИС. Приведено описание структуры системы, основного процессорного ядра и сопряженных с ним модулей. Приведена система команд процессора. Представлен процесс разработки программы для синтезируемого контроллера и вариант реализации системы управления на базе разработанного контроллера.
ПЛИС, IP-ядро процессора, микроконтроллеры, бортовые системы
Короткий адрес: https://sciup.org/142235508
IDR: 142235508 | УДК: 629.78 | DOI: 10.18358/np-32-4-i88106
DEVELOPMENT OF A HIGH-PERFORMANCE COMPUTING SYSTEM BASED ON AN IP-CORE FOR SPACE SCIENTIFIC EQUIPMENT
The article presents the result of the development and implementation of a universal synthesized processor core based on integrated FPGA circuits of domestic and foreign production. The possibility of creating a highperformance computing system based on a FPGA is shown. The description of the structure of the system, the main processor core and associated modules, is described. The system of processor commands is presented. The process of developing a program for a synthesized controller and a variant of implementing a control system based on the developed controller are presented.
Текст научной статьи РАЗРАБОТКА ВЫСОКОПРОИЗВОДИТЕЛЬНОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ НА БАЗЕ IP-ЯДРА ДЛЯ КОСМИЧЕСКОЙ НАУЧНОЙ АППАРАТУРЫ
При разработке научной аппаратуры (НА) для космических исследований приоритетным является использование высоконадежной элементной базы. Часто дополнительным условием является применение отечественной элементной базы. При наличии импортных аналогов, более выгодным и удобным является проведение макетирования и отладки электронных систем именно на них с дальнейшим переводом разработанных систем на электрорадиоизделия (ЭРИ) отечественного производства. В связи с чем возникает необходимость разработки универсального решения, которое можно было бы применять для систем управления, обработки и сбора информации вне зависимости от применяемой элементной базы [1]. Использование стандартных микроконтроллеров (МК) для данных целей затруднительно, т.к. перенос проекта с одного типа МК на другой часто вызывает необходимость существенной доработки программы. А многие стойкие образцы МК снабжены однократной памятью, что существенно усложняет процесс отладки программы. К тому же использование максимально мощного, стойкого к внешним воздействиям МК с развитой периферией часто бывает не выгодно экономически. Для решения данных проблем известны несколько конструкций синтезированных микропроцессоров, описанных в научных статьях [1–8].
В данной статье приводится пример реализации мощной вычислительной системы на базе интегральных микросхем (ИМС) вида ПЛИС — программируемых логических интегральных схем различных производителей. Предложенное решение является универсальным и подходит для реа- лизации на любых микросхемах FPGA (Field-Programmable Gate Array, программируемая пользователем вентильная матрица, ППВМ) как отечественного, так и импортного производства.
ОПИСАНИЕ ГЛАВНОГО ПРОЦЕССОРНОГО ЯДРА
Вычислительная система построена на базе разработанного процессорного IP-ядра, названного "NMR", являющегося процессором с гарвардской архитектурой, и содержит отдельные шину команд, шину данных и несколько шин периферии. Разрядность адреса памяти программ составляет 32 бита, разрядность шины инструкций 16 бит, однако сами инструкции могут иметь различную длину: 16 бит или 32 бита. Разделение некоторых команд на две части предусмотрено архитектурой ядра и не отражается на программе, т.к. система управления процессора по типу команды автоматически определяет смещение адреса. Структура командного слова представлена на рис. 1.
Система команд и архитектура "NMR" разработана специально для работы с внешней памятью программ, организованной в слова по 16 бит, т.к. данная организация памяти является распространенной как в импортной, так и отечественной номенклатуре ЭРИ, в том числе существуют высоконадежные однократно программируемые ПЗУ, например РР45РТ3У. Данная память имеет повышенную стойкость к внешним факторам и организацию 128 К × 16 [9]. Структура IP-ядра "NMR" представлена на рис. 2.
Предполагается, что память программ будет работать на пониженной относительно ядра процессора частоте. Поэтому в организации системы
Основная часть командного слова
р Расширение
Код команды
Операнд 1
__VАдрес регистра
£7 Адрес младшего сектора ОЗУ
I I VI ГП ГППI I Ы АдРес части периферии
Операнд 2
Операнд 3
„Дополнительный указатель
Дополнительная часть командного слова
1 Информация из памяти программ
| ^ | | | | | 15 71 | | | | | У Полный адрес ОЗУ
Полный адрес периферии
'—Ардеса регистров блока А и блока В
Рис. 1. Структура командного слова
256X16 510byte
RAM L
-^■А-сектор ОЗУ
Q ^ddress | data
65279X16 130kbyte
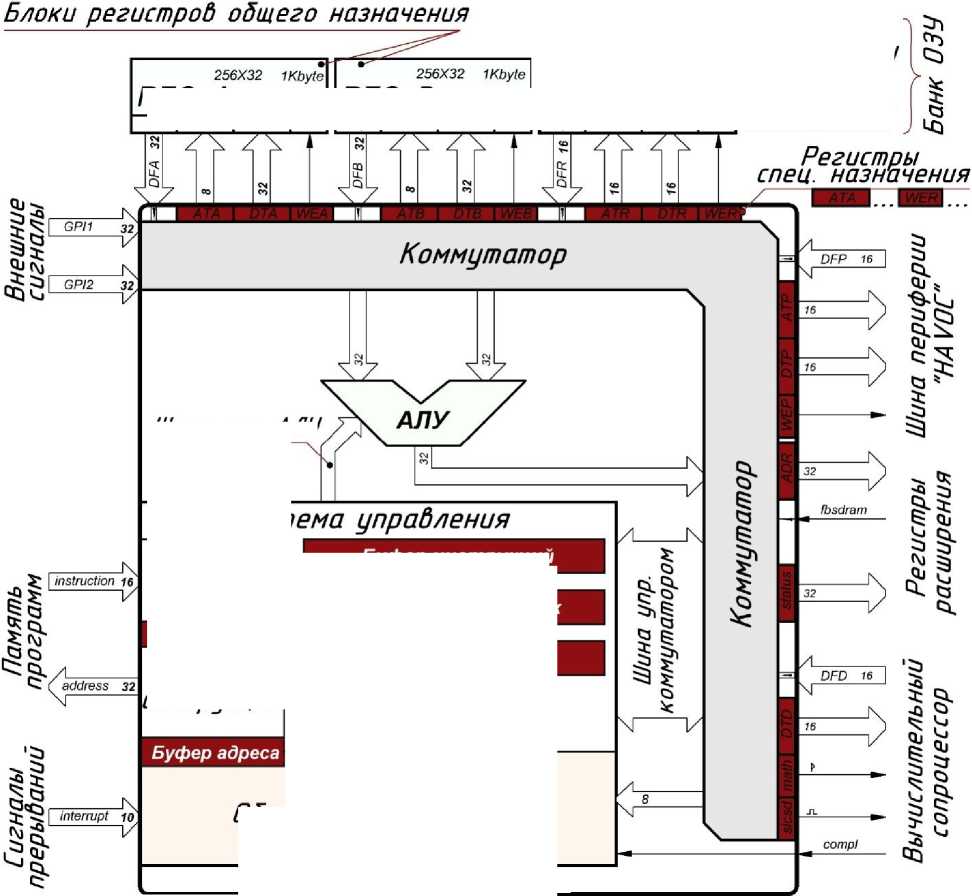
Обработчик прерываний
IP-ядро "NMR"
Буфер инструкции
Системный счетчик
Системный буфер
Рис. 2. Структура IP-ядра процессора "NMR"
RAM
REG_A
Q | address, data | WE
REG_B
Q [address | data | WE
Старший ..сектор ОЗУ Младший
Шина у пр. АЛУ
Декодер и конбейер
Главный КА
Счетчик инструкций
команд процессора и его внутренней архитектуры ние команды еще до ее полного считывания. Инст-реализован подход, позволяющий начать выполне- рукции выполняются на конвейере параллельно
со считыванием частей команд из памяти, что позволяет повысить быстродействие процессора, т.к. память перестает быть узким местом и длительность процессорного такта в среднем соответствует длительности считывания 32-битного командного слова из памяти программ.
В архитектуру "NMR" входит массив регистров общего назначения (РОН), разделенный на два независимых блока REG_A и REG_B. Каждый блок содержит 256 32-битовых регистров. С регистровой памятью возможны все доступные операции, кроме специальных инструкций из системы команд процессора. Система команд "NMR" приведена в Приложении (табл. П1–П5).
Блок работы с оперативной памятью состоит из нескольких частей. Первая часть — для работы с быстрым внутренним банком ОЗУ, который имеет строение, схожее с регистрами общего назначения, и использует внутреннюю ОЗУ ПЛИС, которая имеет разрядность шин данных и адреса по 16 бит, что позволяет адресовать до 131 Кбайт памяти. Первые 256 ячеек ОЗУ (младший сектор) позволяют выполнять большее количество доступных операций, чем с остальным объемом ОЗУ, что позволяет снизить нагрузку на блоки РОН. В "NMR" предусмотрена возможность подключения внешнего ОЗУ через IP-контроллер, для чего предназначены регистры расширения и входные линии внешних сигналов. В зависимости от типа внешнего ОЗУ (SRAM, SDRAM, DDR) IP-контроллер может отличаться.
В системе команд процессора предусмотрены инструкции для работы с динамической памятью, такие как пакетная запись и чтение блоками объемом до 131 Кбайт, остальные функции по взаимодействию непосредственно с ИМС внешнего ОЗУ выполняет IP-контроллер внешнего ОЗУ.
Процессор содержит коммутатор, внешние порты которого буферизированы регистрами специального назначения (РСН). РСН необходимы для работы с блоками регистровой памяти, банком ОЗУ, а также с внешними шинами процессора. В системе команд (Приложение, табл. П1) содержатся инструкции прямого взаимодействия с РСН, что позволяет осуществлять гибкое управление (различные варианты косвенной адресации) и ускорять операции чтения / записи, копирования секторов, потоковое чтение периферии регистровой памяти и ОЗУ. При использовании стандартных операций, связанных с перемещением данных (Приложение, табл. П2), система управления процессором автоматически выполняет все операции с системными регистрами: адресацию, тактирование блоков, выставление и чтение данных с банков памяти. Все периферийные модули подключаются через универсальную адресуемую шину "HAVOC" (Hexadecimal Addressable Vast Outer Connection).
Для чтения данных из шины "HAVOC" используется внешний модуль мультиплексора шины, управляемый адресным пространством данной шины. Ядро "NMR" универсально и было испытано на разных ИМС ПЛИС, полученные характеристики ядра сведены в таблицу и представлены в Приложении (табл. П6).
Система команд "NMR" поддерживает условные и безусловные команды переходов, список которых представлен в Приложении (табл. П3).
В систему команд включены команды mark , позволяющие делать аппаратные отметки по ходу исполнения программы, для данной операции доступны как блоки РОН, так и младший сектор ОЗУ. Условные переходы при выполнении условия позволяют увеличить значения счетчика инструкции от 1 до 255. В пропущенной области может находиться ветвь программы, обрабатываемая при невыполнении условия, либо переход на другой сектор памяти, если данной ветви 255 ячеек памяти недостаточно.
Логические и арифметические операции выполняются на 32-битном АЛУ. Доступные на АЛУ операции представлены в Приложении, табл. П4. Ядро "NMR" разработано как универсальное решение для любых ИМС FPGA, поэтому из команд исключены операции аппаратного деления и умножения, т.к. не во всех ИМС есть соответствующие аппаратные блоки. Для выполнения более сложных математических, вычислительных и специальных операций предусмотрена возможность подключения и взаимодействия с вычислительным сопроцессором, который, если ресурсы ИМС это позволяют, может быть размещен как на той же FPGA, так и в отдельной ИМС [10].
Для взаимодействия с сопроцессором существует выделенная скоростная шина, которая позволяет блоками до 256 байт осуществлять пересылку информации между банком ОЗУ "NMR" и ОЗУ сопроцессора. Сопроцессор имеет выделенную линию прерывания. За работу со специальными средствами процессора отвечает последний блок команд (см. Приложение, табл. П5).
Для удобства работы с системой команд в настоящий момент ведется разработка компилятора, сейчас для отладки используется транслятор команд с функцией определения величины смещения при условном переходе, автоматического назначения РОН и навигации по памяти программ. Пример кода и этапы его преобразования представлены в табл.
Программа состоит из объявления параметров памяти, обнуления необходимых РОН, инициализации блоков периферии, в том числе контроллера прерывания. Далее запускается бесконечный цикл с периодической отправкой на внешний порт инкрементируемой переменной.
Табл. Этапы преобразования программы
|
Исходная программа |
Команды процессора |
Данные в MIF-файле |
|
|
#memory size: 8192 |
A0<=16'd0 |
0 : 1024 |
|
|
#first address: 1024 |
A0>< |
1 : 8000 |
|
|
#interrupt file: C:\NMR\inter1.txt |
A0<=16'd0 |
2 : 8100 |
|
|
// zeroing the register, optional: |
B0<=16'd0 |
3 : 1024 |
|
|
A0<=16'd0 |
B0>< |
||
|
A0>< |
B0<=16'd100 |
1022 |
: 1024 |
|
A0<=16'd0 |
A1<=16'd0 |
1023 |
: 7424 |
|
// zeroing and writing regB0: |
A1>< |
1024 |
: 0 |
|
B0<=16'd0 |
A1<=16'd200 |
1025 |
: 7936 |
|
B0>< |
PRH41<=16'd25 |
1026 |
: 7424 |
|
B0<=16'd100 |
PRH42<=16'd25 |
1027 |
: 0 |
|
// zeroing and writing regA1: |
PRH40<=A0 |
1028 |
: 7680 |
|
A1<=16'd0 |
PRH1<=16'd1 |
1029 |
: 0 |
|
A1>< |
marck RAM1 |
1030 |
: 8192 |
|
A1<=16'd200 |
marck RAM2 |
1031 |
: 7680 |
|
// peripheral module configuration: |
if(A0 |
1032 |
: 100 |
|
PRH41<=16'd25 |
PRH65535<=A0 |
1033 |
: 7425 |
|
PRH42<=16'd25 |
A0++ |
1034 |
: 0 |
|
PRH40<=A0 |
jamp RAM2 |
1035 |
: 7937 |
|
// activation of vector "1" interrupt: |
A0<=16'd0 |
1036 |
: 7425 |
|
PRH1<=16'd1 |
jamp RAM1 |
1037 |
: 200 |
|
// naming, optional: |
address>>8000 |
1038 |
: 7209 |
|
name A0 as counter; |
delayA1 |
1039 |
: 25 |
|
name B0 as limit; |
PRH40<=A0 |
1040 |
: 7210 |
|
let PRH40 as SINT; |
intoff |
1041 |
: 25 |
|
let PRH65535 as outport1; |
1042 |
: 4352 |
|
|
// program: |
1043 |
: 40 |
|
|
pointA: |
1044 |
: 7169 |
|
|
while (counter |
1045 |
: 1 |
|
|
outport1=counter; |
1046 |
: 10753 |
|
|
counter++; |
1047 |
: 10754 |
|
|
} |
1048 |
: 12032 |
|
|
A0<=16'd0 |
1049 |
: 4 |
|
|
goto pointA; |
1050 |
: 4352 |
|
|
// sectop program at 8000: |
1051 |
: 65535 |
|
|
address>>8000 |
1052 |
: 16384 |
|
|
delayA1 |
1053 |
: 11522 |
|
|
SINT=counter; |
1054 |
: 7424 |
|
|
intoff |
1055 1056 1057 8000 8001 8002 8003 |
: 0 : 11521 : 0 : 32001 : 4352 : 40 : 32515 |
|
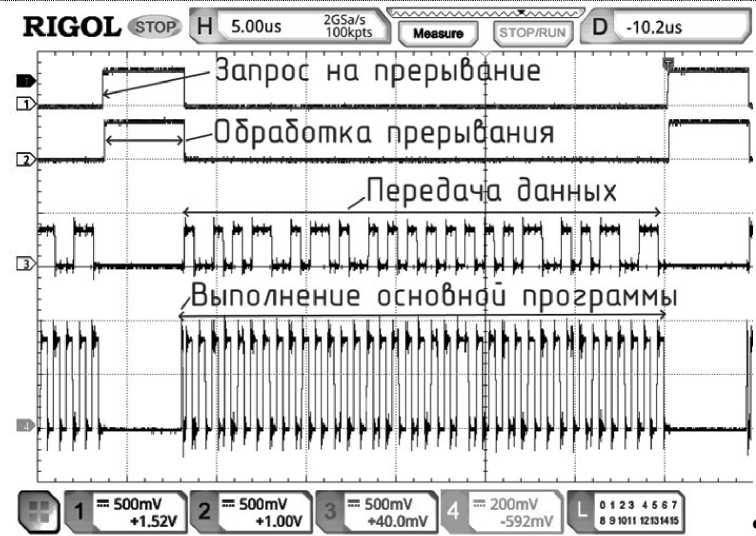
Рис. 3. Осциллограммы исполнения тестовой программы из табл.
Процесс прерывается по сигналу о готовности от модуля передатчика, который захватывает значение переменной и начинает отправку, по завершении которой вызывает прерывание. Программа прерывания описана по адресу начиная с 8000-й ячейки.
На рис. 3 и 4 показаны осциллограммы выполнения программы из табл. на тестовой плате с EP3C25 на частоте ядра и периферии 50 МГц. На рис. 3 представлен полный цикл, в котором выполнение основной программы (инкремент и вывод переменной из РОН в шину периферии (ШП). Сигнал 4 на рис. 3 — младший выводимый разряд переменной counter. Проверка условия и условный переход, инкремент одного из РОН, вывод значения в ШП и прыжок на проверку условия (основная программа) занимают примерно 260 нс. На рис. 4 показана реакция на прерывание и разброс времени реакции.
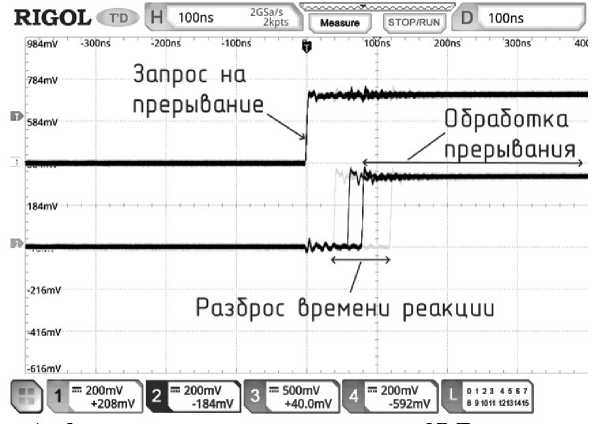
Рис. 4. Отладочные комплекты систем на ядре "NMR" с использованием разных ИМС FPGA
Система управления на базе процессора "NMR"
Для настройки и испытания разработаны две отладочные платы (Приложение, рис. П) на базе ИМС ВЗПП 5578ТС034 и ИМС Intel EP3C25, которая также имеет аналог из каталога ПЛИС ВЗПП 5578ТС094 [9]. Для удобства отладки и испытаний в EP3C25, для хранения небольших программ использовалась ROM-память на базе M9K блоков с загрузкой из конфигурационной flash-памяти EPCS16 в начальный момент. Для исполнения больших программ применялась внешняя ИМС ОЗУ с загрузкой из внешней flash сторонним IP-модулем. Для подачи инструкций ядру внутри 5578ТС034 использовалась плата с EP3C25, подключенная шлейфом — шиной памяти программ.
Результаты, представленные в Приложении, табл. П6, для данных ИМС (рис. 3), изначально получены средствами моделирования в среде Quar-tusII и подтверждены испытаниями. По вре-меннόму анализу QuartusII, разработанное ядро в семействе FPGA Flex может работать на частотах от 23.5 МГц, однако стабильная работа ядра в 5578ТС034 (аналог) была получена на частоте 20 Мгц, что не является критичным, и, скорее всего, данное явление вызвано особенностями печатной платы и применением шлейфового соединения по шине памяти программ. Ядро в ИМС EP3C25 стабильно работало на частоте до 100 МГц (был применен модуль PLL).
По результатам проделанной работы, проведенным виртуальным и реальным испытаниям, а также с учетом ранее разработанных IP-модулей была предложена структурная схема высокопроизводительной системы обработки и управления на отечественной компонентной базе повышенной стойкости. Применялись и компоненты без повышенной стойкости, например накопитель на flash-памяти, было предусмотрено резервирование. Структурная схема разработанной системы представлена на рис. 5.
Накопитель данных
16М (2М х 8)
4 /
-г—► 1636РР4У
2Q,
20,
20,
Интерфейсы и порты ббода-быбойа,
Внешняя ОЗУ
ВыбоЗы программируемые пользователем (ВПП)
4М(512Кх8)
■Х^ 1645РУ5У
4М(512Кх8 )
-X 1645РУ5У
4М(512Кх8) 8
-\ 1645РУ5У
1636РР4У
16М (2М х 8)
1636РР4У
16М (2М х 8)
Flash память
Память программ
2М (128К х 16)
2М(128Кх 16)
1645РТЗУ
2М(128Кх 16)
1645РТЗУ
1645РТЗУ
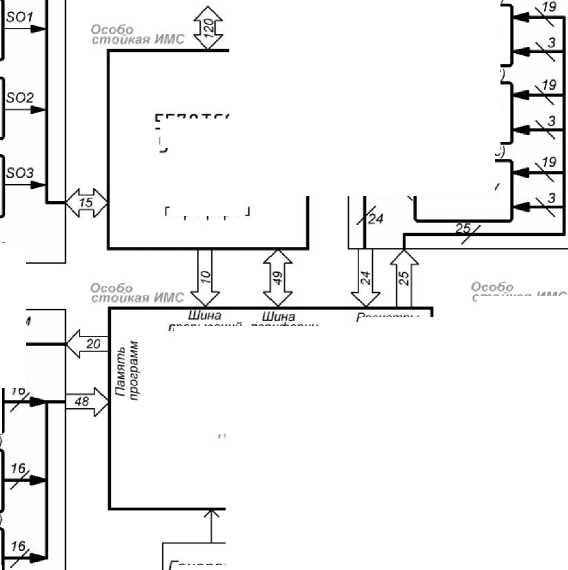
ISE ВПП стойкая ИМС
5578ТС034
СОПРОЦЕССОР
ПРОЦЕССОР "NIGHTMARE"
5578ТЕ034, 5576ХС6Т
Генератор 20МГц
Генератор 20МГц
5578ТЕ034, 5576ХС6Т
Блок периферии
прерывании периферии
Регистры расширения
Стойкая однократная ПЗУ
Рис. 5. Структурная схема системы обработки и управления на базе процессорного IP-ядра "NMR"
ВЫВОДЫ
Показана возможность создания производительный вычислительной системы на базе отечественной стойкой элементной базы, в качестве основного компонента выступает ИМС ПЛИС типа 5578ТС034 или более емкие образцы. Предложен вариант создания системы управления и обработки с использованием разработанного процессорного ядра и периферийных модулей. Проведено
практическое испытание предложенных решений, результаты которых полностью совпали с результатами моделирования. В дальнейших разработках планируется увеличение функциональных возможностей стандартных МК посредством оптимизации IP-модулей и добавления новых, а также создание программной составляющей среды разработки.
ПРИЛОЖЕНИЕ
Табл. П1. Система команд с регистрами специального назначения (РСН)
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
о |
О |
СЯ & В О |
в О |
||
|
ATA<=X |
1 |
X |
– |
Запись числа в системный регистр адреса ATA блока рег. А |
|
|
ATB<=X |
2 |
X |
– |
Запись числа в системный регистр адреса ATA блока рег. В |
|
|
ATR<=X |
3 |
1 |
X |
– |
Запись числа в системный регистр адреса ATR ОЗУ |
|
ATP<=X |
3 |
2 |
X |
Запись числа в системный регистр адреса ATR ШП "HAVOC" |
|
|
ATA<=B# |
8 |
# |
– |
– |
Запись в специальные регистры адресов (ATA, ATB, ATR, ATH) содержимого ячеек с адресом [#] из блоков рег. А или рег. В в зависимости от команды |
|
ATB<=A# |
9 |
# |
– |
– |
|
|
ATR<=A# |
10 |
# |
|||
|
ATP<=A# |
11 |
# |
– |
– |
|
|
A<=RAM |
4 |
1 |
– |
– |
Запись в блок рег. А или рег. В по заранее установленным адресам в регистрах адреса ATA, ATB данных из ОЗУ или ШП "HAVOC" по также заранее установленным адресам в специальных регистрах адреса ATR, ATH соответственно |
|
A<=PRH |
4 |
4 |
|||
|
B<=RAM |
5 |
1 |
– |
– |
|
|
B<=PRH |
5 |
4 |
– |
– |
|
Табл. П1. Продолжение
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
о |
О |
СЯ & В О |
в О |
||
|
A<=RAM+ |
4 |
2 |
– |
– |
Запись в блок рег. А или рег. В по заранее установленным адресам в регистрах адреса ATA, ATB данных из ОЗУ или "HAVOC" по также заранее установленным адресам в специальных регистрах адреса ATR, ATH соответственно, значения в которых после записи инкрементируются |
|
A<=PRH+ |
4 |
5 |
– |
– |
|
|
B<=RAM+ |
5 |
2 |
– |
||
|
B<=PRH+ |
5 |
5 |
– |
– |
|
|
A+<=RAM+ |
4 |
3 |
– |
– |
Запись в блок рег. А или рег. В по заранее установленным адресам в регистрах адреса ATA, ATB данных из ОЗУ или ШП "HAVOC" по также заранее установленным адресам в специальных регистрах адреса ATR, ATH соответственно, значения всех регистров адреса инкрементируются |
|
A+<=PRH+ |
4 |
6 |
– |
– |
|
|
B+<=RAM+ |
5 |
3 |
– |
– |
|
|
B+<=PRH+ |
5 |
6 |
– |
– |
|
|
RAM<=A |
6 |
1 |
– |
– |
Запись в ОЗУ или ШП "HAVOC" по заранее установленным адресам в регистрах ATR и ATH соответственно данных из блоков рег. А или рег. В с также предустановленными адресами в регистрах ATA и ATB |
|
RAM<=B |
6 |
4 |
– |
– |
|
|
PRH<=A |
7 |
1 |
– |
– |
|
|
PRH<=B |
7 |
4 |
– |
– |
|
|
RAM+<=A |
6 |
2 |
– |
– |
Запись в ОЗУ или ШП "HAVOC" по заранее установленным адресам в регистрах ATR и ATH соответственно данных из блоков рег. А или рег. В с также предустановленными адресами в регистрах ATA и ATB. Значения ATR или ATH после операции записи инкрементируются |
|
RAM+<=B |
6 |
5 |
– |
– |
|
|
PRH+<=A |
7 |
2 |
– |
– |
|
|
PRH+<=B |
7 |
5 |
– |
– |
|
Табл. П1. Окончание
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
s |
ci О |
(N ci О |
ci в О |
||
|
RAM+<=A+ |
6 |
3 |
– |
– |
Запись в ОЗУ или ШП "HAVOC" по заранее установленным адресам в регистрах ATR и ATH соответственно данных из блоков рег. А или рег. В с также предустановленными адресами в регистрах ATA и ATB. Значения всех регистров адреса после записи инкрементируются |
|
RAM+<=B+ |
6 |
6 |
– |
– |
|
|
PRH+<=A+ |
7 |
3 |
– |
– |
|
|
PRH+<=B+ |
7 |
6 |
|||
|
RAM<=PRH |
6 |
7 |
– |
– |
Обмен данными между ОЗУ и ШП "HAVOC" с предустановленными адресами в РСН ATR и ATH с инкрементированием адреса в регистрах ATR и ATH или без в зависимости от команды |
|
PRH<=RAM |
7 |
7 |
– |
– |
|
|
RAM+<=PRH |
6 |
8 |
|||
|
PRH+<=RAM |
7 |
8 |
– |
– |
|
|
P=>R(X) |
12 |
– |
– |
– |
Запись из ШП в ОЗУ (код 12) или наоборот (код 13) блока данных объемом X слов, по предустановленным адресам в регистрах ATR, ATH с инкрементом адреса ОЗУ в ATR |
|
R(X)=>P |
13 |
||||
Табл. П2. Система команд перемещения и записи
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
о |
ci в О |
СЯ ci в О |
ci в О |
||
|
RAM•<=A# |
15 |
# |
• |
Запись в ОЗУ или ШП "HAVOC" по адресу [•] содержимого ячейки [#] блоков рег. А или рег. В в зависимости от команды |
|
|
RAM•<=B# |
16 |
# |
• |
– |
|
|
PRH•<=A# |
17 |
# |
• |
||
|
PRH•<=B# |
18 |
# |
• |
– |
|
Табл. П2. Окончание
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
s |
ci О |
(N ci О |
ci в О |
||
|
A#<=RAM• |
19 |
# |
• |
– |
Запись в ячейку [#] блоков рег. А или рег. В из адреса [•] ОЗУ или ШП в зависимости от команды |
|
A#<=PRH• |
20 |
# |
• |
– |
|
|
B#<=RAM• |
21 |
# |
• |
||
|
B#<=PRH• |
22 |
# |
• |
– |
|
|
B#<=A• |
23 |
• |
# |
Запись в ячейку [#] блока рег. В из ячейки [•] блока рег. А |
|
|
A#<=B• |
24 |
• |
# |
– |
Запись в ячейку [#] блока рег. А из ячейки [•] блока рег. В |
|
RAM#<= X |
27 |
# |
X |
– |
Запись ОЗУ, ШП "HAVOC" или блоки рег. А или рег. В с адресом [#] числа ## из памяти программ. Для ОЗУ и ШП доступны только первые 256 адресов. Для 32-битных регистров запись осуществляется в младшие 16 бит |
|
PRH#<= X |
28 |
# |
X |
– |
|
|
A#<= X |
29 |
# |
X |
– |
|
|
B#<= X |
30 |
# |
X |
||
|
А#>< |
31 |
# |
– |
– |
Обмен старших 16 бит на младшие в 32-битной ячейке с адресом [#] блоков рег. А или рег. В |
|
B#>< |
32 |
# |
– |
– |
|
|
A#<=A• |
33 |
• |
# |
– |
Перемещение внутри блока одного блока РОН: запись в ячейку [#] ячейки [•] |
|
B#<=B• |
34 |
• |
# |
– |
|
Табл. П3. Система команд переходов по пространству адреса программ
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
о |
ci в О |
СЯ ci в О |
ci в О |
||
|
mark A# |
40 |
# |
– |
– |
Сохранение в ячейке [#] блока регистров А или В текущего номера инструкции (значение счетчика инструкций) |
|
mark B# |
41 |
# |
– |
– |
|
Табл. П3. Окончание
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
о |
О |
СЯ & В О |
в О |
||
|
mark RAM# |
42 |
# |
– |
– |
Сохранение в ячейке [#] младшего сектора ОЗУ текущего номера инструкции (значение счетчика инструкций) |
|
jamp A# |
43 |
# |
– |
– |
Безусловный переход по адресу из ячейки [#] блоков регистров А или В, а также из ячейки [#] младшего сектора ОЗУ (присвоение счетчику инструкций значения из ячейки [#]) |
|
jamp B# |
44 |
# |
|||
|
jamp RAM# |
45 |
# |
– |
– |
|
|
if(A#>B•)up X |
46 |
# |
• |
X |
Условный переход. Если условие выполняется, происходит прыжок на X значений вперед, иначе выполнение программы идет по порядку. Для проверки условия берутся ячейки [#] и [•] из РАЗНЫХ блоков регистров А и В соответственно |
|
if(A# |
47 |
# |
• |
X |
|
|
if(A#=B•)up X |
48 |
# |
• |
X |
|
|
if(A#!=B•)up X |
49 |
# |
• |
X |
|
Табл. П4. Логические и арифметические команды
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
£ |
в О |
СЯ & В О |
в О |
||
|
A#+X |
60 |
# |
X |
– |
Операция: сложение содержимого ячейки [#] блоков регистров А или В и 16 битного числа X из памяти программ |
|
B#+X |
61 |
# |
– |
– |
|
|
A#-X |
62 |
# |
– |
– |
Операция: вычитание содержимого ячейки [#] блоков регистров А или В и 16 битного числа X из памяти программ |
|
B#-X |
63 |
# |
– |
– |
|
|
A#++ |
64 |
# |
Инкремент ячейки [#] блока регистров A |
||
|
B#++ |
65 |
# |
– |
– |
Инкремент ячейки [#] блока регистров B |
|
A#-- |
66 |
# |
Декремент ячейки [#] блока регистров A |
||
Табл. П4. Продолжение
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
о |
О |
СЯ & В О |
в О |
||
|
B#-- |
67 |
# |
– |
– |
Декремент ячейки [#] блока регистров B |
|
A#<=A•andB◊ |
68 |
# |
• |
◊ |
Логические операции (and; or; xor) между ячейками РАЗНЫХ блоков регистров: ячейка блока регистров А с адресом [•] и ячейка из блока регистров B с адресом [◊]; результат помещается в ячейку [#] блока регистров A, адрес помещения результата может совпадать с адресом [•] операнда блока регистров А, в таком случае исходное значение будет замещено результатом операции |
|
B#<=A•andB◊ |
69 |
# |
• |
◊ |
|
|
A#<=A•orB◊ |
70 |
# |
• |
◊ |
|
|
B#<=A•orB◊ |
71 |
# |
• |
◊ |
|
|
A#<=A•xorB◊ |
72 |
# |
• |
◊ |
|
|
B#<=A•xorB◊ |
73 |
# |
• |
◊ |
|
|
A#<=A•+B◊ |
74 |
# |
• |
◊ |
Математические операции сложения или вычитания между ячейками [◊], [•] РАЗНЫХ блоков рег. А и рег. В; результат операции помещается в ячейку [#] блоков рег. А и рег. В в зависимости от команды |
|
B#<=A•+B◊ |
75 |
# |
• |
◊ |
|
|
A#<=A•-B◊ |
76 |
# |
• |
◊ |
|
|
A#<=B•-A◊ |
77 |
# |
• |
◊ |
|
|
B#<=A•-B◊ |
78 |
# |
• |
◊ |
|
|
B#<=B•-A◊ |
79 |
# |
• |
◊ |
|
|
notA# |
80 |
# |
– |
– |
Логическое побитовое отрицание содержимого ячейки [#] блоков рег. А и рег. В в зависимости от команды |
|
notB# |
81 |
# |
|||
|
mask(X)AL# |
82 |
# |
X |
Побитовая маска младших (код 82) или старших (код 83) 16 бит 32-битной ячейки [#] блока регистров А с числом X |
|
|
mask(X)AH# |
83 |
# |
X |
– |
|
|
mask(X)BL# |
86 |
# |
X |
– |
Побитовая маска младших (код 86) или старших (код 87) 16 бит 32-битной ячейки [#] блока регистров В с числом X |
|
mask(X)BH# |
87 |
# |
X |
– |
|
Табл. П4. Окончание
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
о |
О |
СЯ & В О |
в О |
||
|
rotAL# |
84 |
# |
– |
– |
Операция вращения числа в младшей (код 84) и старшей (код 86) области ячейки [#] блока рег. А или всего 32битового числа ячейки [#] рег. В (код 88) |
|
rotAH# |
85 |
# |
– |
– |
|
|
rotBF# |
88 |
# |
|||
|
A#<< X |
89 |
# |
0 |
X |
Сдвиг вправо или влево содержимого ячейки [#] блока регистров А или В на число X |
|
A#>> X |
89 |
# |
1 |
X |
|
|
B#<< X |
90 |
# |
0 |
X |
|
|
B#>> X |
90 |
# |
1 |
X |
|
|
91 |
# |
Сдвиг вправо или влево содержимого ячейки [#] блока регистров А или В на 1 разряд |
|||
|
>>A# |
92 |
# |
– |
– |
|
Табл. П5. Система дополнительных команд
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
о ^ |
в О |
СЯ & В О |
О |
||
|
R#+X =>DTD |
93 |
# |
X |
– |
Отправка или получение в/от сопроцессора пакета данных из/в ОЗУ объемом до X слов, начиная с адреса [#] ОЗУ |
|
R#+X <=DTD |
94 |
# |
X |
– |
|
|
adr<=A# |
95 |
# |
– |
– |
Запись в специальный регистр ADR ячейки [#] блока рег. А |
|
A#<=adr |
96 |
# |
Запись в ячейку [#] блока рег. А содержимого регистра ADR |
||
|
adr+8'd X |
97 |
X |
– |
– |
Увеличение содержимого специального регистра ADR на X |
|
stat<=A# |
## |
# |
Запись в специальный регистр Status ячейки [#] блока рег. А |
||
Табл. П5. Окончание
|
Команда |
Основ. часть |
Доп. часть |
Описание команды |
||
|
о |
О |
СЯ & В О |
в О |
||
|
A#<=stat |
## |
# |
– |
– |
Запись в ячейку [#] блока рег. А содержимого регистра Status |
|
A#<=GPI1 |
## |
# |
Запись данных со входа GPI1 в ячейку [#] блока рег. А |
||
|
B#<=GPI2 |
## |
# |
– |
– |
Запись данных со входа GPI1 в ячейку [#] блока рег. А |
|
intoff |
## |
– |
– |
– |
Команда выхода из прерывания |
|
sleep |
## |
– |
– |
– |
Остановка процессора, запуск процессора возможен по сигналам прерывания |
|
delayA255 |
## |
# |
– |
– |
Аппаратная задержка на кол-во тактов из ячейки [#] рег. А |
Табл. П6. Характеристики ядра "NMR" в разных ИМС ПЛИС
|
Параметр |
ПЛИС |
|||||
|
5578 ТС034 |
EPF10K100-EBC356-3 |
EP2C8F-256C6 |
EP3C16-U484C6 |
EP3C40-F484С6 |
EP355F-780C8 |
|
|
Занимаемый объем |
4807 (96%) |
4807 (96%) |
3519 (43%) |
3540 (23%) |
3535 (9%) |
3560 (6%) |
|
Занимаемая память [бит] |
32768 (67%) |
32768 (67%) |
147456 (85%) |
81920 (82%) |
147456 (13%) |
278528 (12%) |
|
Кол-во РОН |
512 |
512 |
512 |
512 |
512 |
512 |
|
Объем ОЗУ |
2 КБ |
2 КБ |
16 КБ |
8 КБ |
16 КБ |
32 КБ |
|
Операций в секунду |
6.4 MIPS |
7.5 MIPS |
25.4 MIPS |
47.0 MIPS |
45.3 MIPS |
37.2 MIPS |
|
Макс. частота |
20 МГц |
23.5 МГц |
79 МГц |
149 МГц |
141 МГц |
116 МГц |
|
Система команд |
108 инстр. |
108 инстр. |
полная |
полная |
полная |
полная |
|
Доп. проц. |
внешний |
внешний |
Akeron |
Akeron |
Akeron + Sip CPU |
Akeron + Sip CPU |
|
Время отклика на прерывание, не более |
300 нс |
255 нс |
76 нс |
40 нс |
42 нс |
51 нс |

Рис. П. Отладочные комплекты систем на ядре "NMR" с использованием разных ИМС FPGA
Список литературы РАЗРАБОТКА ВЫСОКОПРОИЗВОДИТЕЛЬНОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ НА БАЗЕ IP-ЯДРА ДЛЯ КОСМИЧЕСКОЙ НАУЧНОЙ АППАРАТУРЫ
- 1. Воронов К.Е., Сухачев К.И., Воробьев Д.С. Разработка бортового модуля управления на базе вычислительного IP-ядра // Ракетно-космическое приборостроение и информационные системы. 2021. Т. 8, № 1. C. 24–38. DOI: 10.30894/issn2409-0239.2021.8.1.24.38
- 2. Haskell R.E., Hanna D.M. A VHDL--Forth Core for FPGAs // Microprocessors and Microsystems. 2004. Vol. 28, is. 3. P. 115–125.
- 3. Ehliar A., Karlstrom P., Liu D. A high performance microprocessor with DSP extensions optimized for the virtex-4 FPGa // 2008 International Conference on Field Programmable Logic and Applications. IEEE. 2008. P. 599–602.
- 4. Tamagnone M., Martina M., Masera G. An application specific instruction set processor based implementation for signal detection in multiple antenna systems // Microprocessors and Microsystems. 2012. Vol. 36, is. 3. P. 245–256.
- 5. Зотов В. PicoBlaze — семейство восьмиразрядных микропроцессорных ядер, реализуемых на основе ПЛИС фирмы Xilinx // Компоненты и технологии. 2003. № 30. С. 194–198.
- 6. Jesman R., Vallina F.M., Saniie J. MicroBlaze tutorial creating a simple embedded system and adding custom peripherals using Xilinx EDK software tools. Embedded Computing and Signal Processing Laboratory, Illinois Institute of Technology, 2006.
- 7. Atehortúa J.C.B. Desarrollo e implementación del procesador soft-core LatticeMico32 en una FPGA. 2016. URL:
- https://1library.co/document/ye9524eq-desarrolloimplementacion-procesador-soft-core-latticemicofpga.html
- 8. Pokale M.S.M., Kulkarni M.K., Rode S.V. NIOS II processor implementation in FPGA: an application of data logging system // Int. J. Sci. Technol. Res. 2012. Vol. 1, is. 11.
- 9. АО "Воронежский завод полупроводниковых приборов" (ВЗПП-С). Каталог изделий 2020 г. URL: http://www.vzpp-s.ru/production/catalog.pdf (дата обращения: 01.07.2022).
- 10. Никитин А.А. Реализация радиационно-стойкого кодирования в рамках межкристальной связи систем, состоящих из нескольких программируемых логических интегральных схем // Космическая техника и технологии. 2018. № 4 (23). C. 100–110.
