Реализация базы правил системы нечеткой логики самоконфигурируемым генетическим программированием при решении задачи классификации

Автор: Кошин М.А., Семенкин Е.С.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 1 т.27, 2026 года.
Бесплатный доступ
Системы нечеткой логики широко используются в задачах классификации благодаря их способности работать с неопределенностью, неточностью и субъективностью в данных. В отличие от традиционных «четких» методов, нечеткая логика позволяет описывать входные характеристики и выходные классы с помощью лингвистических переменных, таких как «высокий», «средний» и «низкий», что делает модели более интерпретируемыми и согласованными с человеческой логикой. Ключевым ограничением данного подхода является необходимость построения базы правил с привлечением экспертных знаний, а также неоднозначность в выборе подходящих форм функций принадлежности. Для решения этих проблем используются различные алгоритмы оптимизации. Один из таких алгоритмов – генетическое программирование, целью которого является эволюция базы правил, способной точно улавливать лежащие в основе закономерности для правильной классификации, сохраняя при этом интерпретируемость за счет структурной адаптации. В данной статье рассматривается подход применения самонастраивающегося генетического программирования в сочетании с дифференциальной эволюцией для построения баз правил нечеткой логики. Также представлены их практическая реализация и применение к задачам классификации.
Эволюционные алгоритмы, системы нечеткой логики, генетическое программирование, задача классификации, дифференциальная эволюция, генетический алгоритм, самоконфигурация
Короткий адрес: https://sciup.org/148333106
IDR: 148333106 | УДК: 519.6 | DOI: 10.31772/2712-8970-2026-27-1-33-46
Implementation of the fuzzy logic system rule base by self-configuring genetic programming in solving the classification problem
Fuzzy logic systems are widely used in classification problems due to their ability to handle uncertainty, imprecision, and subjectivity in data. Unlike traditional “crisp” methods, fuzzy logic allows input features and output classes to be described in terms of linguistic variables – such as “high”, “medium”, and “low” – making models more interpretable and aligned with human reasoning. A key limitation of this approach is the need to construct a rule base using expert knowledge, as well as the ambiguity in selecting appropriate membership function shapes. To address these challenges, various optimization algorithms have been developed. One such method is genetic programming, which purpose is to evolve a rule base capable of accurately capturing underlying patterns for correct classification while preserving interpretability through structural adaptation. This article explores the theoretical framework of self-configuring genetic programming combined with differential evolution for constructing fuzzy logic rule bases. It also presents their practical implementation and application to classification tasks.
Текст научной статьи Реализация базы правил системы нечеткой логики самоконфигурируемым генетическим программированием при решении задачи классификации
Большинство традиционных алгоритмов классификации демонстрируют хорошую производительность, но страдают от низкой интерпретируемости. Для решения этой проблемы были разработаны системы нечеткой логики, которые обеспечивают высокую интерпретируемость благодаря понятным для неэкспертов лингвистически интерпретируемым правилам, функциям принадлежности, которые сопоставляют входные данные с нечеткими термами, возможности включения экспертных знаний на всех этапах процесса проектирования.
Существенным недостатком нечетких систем является необходимость определения базы правил на этапе проектирования. Это представляет проблему, так как получение необходимых знаний от экспертов может быть невыполнимой задачей. Экспертные знания часто субъективны, что может искажать лежащие в основе классификации закономерности. Более того, может не существовать достаточного количества квалифицированных экспертов или они могут отсутствовать вовсе.
Для решения этой проблемы можно интегрировать компонент нечеткой логики, который автоматически генерирует базу правил, точно отражающую закономерности, необходимые для правильной классификации, и устраняет обязательную зависимость от экспертов. Этот подход сохраняет преимущества систем нечеткой логики, включая высокую производительность, даже при отсутствии экспертов в предметной области, а также сокращает время проектирования.
Один из перспективных методов для реализации этого подхода – использование эволюционных алгоритмов. Такие алгоритмы, как генетические алгоритмы, дифференциальная эволюция (с точки зрения численной адаптации) и генетическое программирование, могут быть использованы для взращивания базы правил. Эти алгоритмы обеспечивают как численную адаптацию – например, оптимизацию параметров функций принадлежности, так и структурную адаптацию – оптимизацию количества и состава правил.
Прежде чем детально рассмотреть использование эволюционных алгоритмов для генерации базы нечетких правил, необходимо ознакомиться с теоретическими основами систем нечеткой логики.
Системы на нечеткой логике
Нечеткая логика – математический подход для работы с неточными или неопределенными данными. В отличие от классической булевой логики, которая оперирует бинарными значениями (0 и 1), нечеткая логика оперирует степенями истинности (в диапазоне от 0 до 1) [1].
Каждый элементы, рассматриваемый в нечеткой логике, принадлежит определенному множеству с некоторой степенью принадлежности:
А = {( x, И A (x ))| x e X }• (1)
Функция принадлежности определяет, насколько рассматриваемый элемент соответствует нечеткому множеству. В рамках статьи рассматривается Гауссова функция принадлежности:
Ц a ( x ) = exp
(
-
\
I
Использование Гауссовой функции принадлежности в рамках данной статьи основано на двух следующих соображениях: она имеет всего два оптимизируемых параметра и, при условии, что рассматриваемые термы всегда соответствуют реальным атрибутам сущностей, наилучшим образом подходит для их описания в силу того, что многие процессы подчиняются нормальному распределению.
В рамках теории нечетких множеств также рассматривается понятие лингвистической переменной – переменной, значения которой выражаются словами или фразами естественного языка. Лингвистические переменные используются для описания качественных характеристик в системах, где можно применить точные количественные оценки. Возможные значения лингвистической переменной называются термами; для каждого терма определяется некоторое значения функции принадлежности. Примером лингвистической переменной может служить температура, для которой могут быть определены такие термы, как «низкая», «ниже нормы», «нормальная», «выше норма», «высокая». Для такой лингвистической переменной, если рассматривать ее в контексте температуры человека, температура 35,7 °C будет близка по степени истинности к терму «ниже нормы» при условии, что параметры (2) заданы для этого терма правильно. Функция принадлежности фигурирует на этапе фаззификации, которая представляет собой преобразование числовых данных в степени принадлежности к термам.
Поведение системы нечеткой логики определяется базой правил, которая содержит набор логических условий вида «если …, то …»; такие условия связывают входные лингвистические переменные с целевой. База данных является основным компонентом важного этапа работы системы нечеткой логики – применения нечетких правил для решения задачи. Пример базы правил систем нечеткой логики представлен на рис. 1.
Testing Accuracy: 95.6522%
If Bill Depth is Medium And Flipper Length is Large And Body Mass is Very Light Then Species is Adelie
If Bill Depth is Medium And Flipper Length is Large And Body Mass is Light Then Species is Adelie
If Bill Length is Very Large And Flipper Length is Large And Body Mass is Very Light Then Species is Adelie
If Bill Length is Large And Bill Depth is Medium And Flipper Length is Large Then Species is Chinstrap
If Bill Length is Large And Bill Depth is Medium And Flipper Length is Medium Then Species is Chinstrap
If Bill Length is Large And Flipper Length is Large Then Species is Gentoo
If Bill Length is Very Large And Bill Depth is Medium And Flipper Length is Large And Body Mass is Very Heavy
Then Species is Gentoo
If Bill Length is Medium And Bill Depth is Medium And Flipper Length is Large And Body Mass is Vert' Heavy
Then Species is Adelie
If Bill Length is Small And Bill Depth is Medium And Flipper Length is Large And Body Mass is Light Then Species is Adelie
If Bill Length is Small And Bill Depth is Medium And Flipper L ength is Large And Body Mass is Light Then Species is Adelie
If Bill Length is Small And Bill Depth is Medium And Flipper L ength is Large And Body Mass is Very Heavy Then
Species is Gentoo
If Bill Length is Very Large And Flipper Length is Large And Body Mass is Very' Heavy Then Species is Gentoo
If Flipper Length is Large And Body Mass is Very Light Then Species is Chinstrap
Рис. 1. База правил классификации пингвинов. Данный пример демонстрирует, что построенная база правил для классификации пингвинов четко определяет принципы реализации процесса классификации
Fig. 1. The rule base of the Palmer penguin classification system. This example demonstrates that the rule base constructed for penguin classification clearly outlines the principles for implementing the classification process
База правил формируется на основе знаний экспертов, участвующих в проектировании системы. Однако эксперты доступны не всегда в силу ряда факторов, включая нехватку квалифицированных специалистов, присущую им суждениям субъективность и вытекающую из этого противоречивость их знаний.
Каждому терму лингвистической переменной выставляется функция принадлежности с определенной формой и параметрами. Для корректной работы системы нечеткой логики ее база правил должна быть надлежащим образом разработана, сохраняя структуру, которая является одновременно понятной и интерпретируемой.
После того как закономерность выявлена, происходит заключительный этапе процесса реализации системы на нечеткой логике – дефаззификация. Этот процесс преобразует нечеткий вывод в точное четкое численное значение.
Таким образом, для реализации системы нечеткой логики необходимы решения двух ключевых задач: во-первых, разработка базы правил, точно описывающей желаемую закономерность, и, во-вторых, подбор функций принадлежности для каждого терма, обеспечивающих высокую точность модели. Для решения этих задач могут применяться самоконфигурируемые эволюционные алгоритмы [2]. Их использование предоставляет возможность одновременно оптимизировать как функции принадлежности каждого терма, так и структуру базы правил.
Самоконфигурируемые эволюционные алгоритмы
Эволюционные алгоритмы (ЭА) – класс алгоритмов оптимизации, основанных на принципах естественного отбора [3]. Алгоритм начинается с инициализации набора кандидатов-решений, называемых особями (индивидами). Эти особи кодируются таким образом, чтобы над ними могли проводиться различные операторы изменения их структуры – мутация и скрещивание. Скрещивание не является случайным процессом – оно направляется операторами селекции, предназначенными для выбора наиболее приспособленных родителей. Это гарантирует, что особи в последующих поколениях могут наследовать полезные черты от своих предшественников.
Конкретные реализации операторов селекции, скрещивания и мутации определяют различные типы эволюционных алгоритмов, включая генетические алгоритмы [4], генетическое программирование [5] и дифференциальную эволюцию [6]. Основные различия между этими алгоритмами заключаются в способе представления структуры особи и, как следствие, реализации операторов, которые её изменяют.
Генетический алгоритм
Генетический алгоритм (ГА) – стохастический процесс, имитирующий естественную эволюцию. Ключевой характеристикой канонического генетического алгоритма является представление генотипа особи в виде бинарной строки. Соответственно, операции скрещивания и мутации предполагают манипуляции с этой бинарной строкой. При декодировании в десятичную форму взращенное бинарное число дает параметры новых решений-кандидатов, которые, в идеале, сочетают в себе лучшие черты предыдущей популяции или вносят новые вариации.
Универсальность генетических алгоритмов позволяет применять их к широкому спектру задач, формулируемых как задачи оптимизации, где каждое решение-кандидат может быть оценено с помощью функции пригодности.
В контексте систем нечеткой логики ГА часто используется для проектирования базы правил. Двумя основными методиками для этого являются Питтсбургский и Мичиганский подходы. В данной статье рассматривается гибридный метод, сочетающий оба подхода [7]. Базовый алгоритм следует первому подходу, где каждая особь представляет собой полный набор правил, в то время как второй подход представлен в виде специфичного оператора мутации. Кроме того, в эту версию включена самоконфигурация, которая адаптирует вероятности выбора различных операторов, меняющих структуру индивида, на основе их эффективности.
Данная версия ГА предлагает несколько преимуществ, включая интерпретируемость, автоматическую настройку параметров и некоторого рода гибкость, т. е. способность адаптироваться к различным типам задач. Пример представления особи в этой версии ГА изображен на рис. 2.
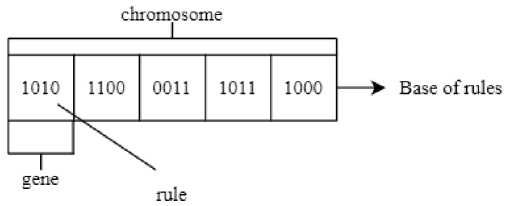
Рис. 2. Пример представления особи в генетическом алгоритме
Fig. 2. Individual example in the GA implementing the rule base
Существенным недостатком данного подхода является «жесткая» схема кодирования, проистекающая из фиксированной структуры правил и хромосомы фиксированной длины. Для преодоления этого ограничения может быть использовано генетическое программирование, поскольку его представление позволяет эволюционировать к более компактной и упрощенной базе правил.
Генетическое программирование
Генетическое программирование – метод из класса эволюционных алгоритмов, который характеризуется использованием древовидной структуры для представления особи (хотя в настоящее время только древовидной структурой алгоритм не ограничивается). Данное представление предполагает определение функционального и терминального множеств. Терминальное множество включает переменные и константы, в то время как функциональное множество – операции, выполняемые над элементами терминального множества. Как следствие, древовидная структура особи требует специальных реализаций для генетических операторов, которые меняют структуру индивида.
При применении такого метода для работы с системами на нечеткой логике, терминальное множество может быть определено как множество термов целевой лингвистической переменной:
T = { u 1 , u 1 , ... u n } . (3)
Функциональное множество может быть определено как множество операций, отделяющих термы из различных лингвистических переменных, тем самым присваивая им в соответствие какой-то терм целевой лингвистической переменной. Пример представления особи для базы правил, реализованной с помощью генетического программирования (рассматривается случай с двумя лингвистическими переменными и одной целевой переменной), показан на рис. 3.
Таким образом, каждая особь в популяции представляет собой полную базу правил для использования в системе нечеткой логики. В течение какого-то количества поколений происходит эволюция и отбор наиболее подходящих баз правил, в конечном счете, лучшая из отобранных становится конечным решением.
Данный подход способствует созданию структурно разнообразной базы правил, всесторонне охватывающей закономерности, необходимые для корректной работы системы. Однако, поскольку ручная настройка такого алгоритма может быть трудоемкой, в рамках статьи используется метод самоадаптации для автоматизации этого процесса. Когда доступны несколько вариантов операторов для изменения структуры индивида, может применяться самоконфигура-ция на уровне операторов для определения наиболее эффективного набора операторов для конкретной задачи. Изначально рассматриваемым типам операторов скрещивания, мутации и селекции присваиваются равные вероятности применения к популяции ГП. Этот процесс представлен на рис. 4.
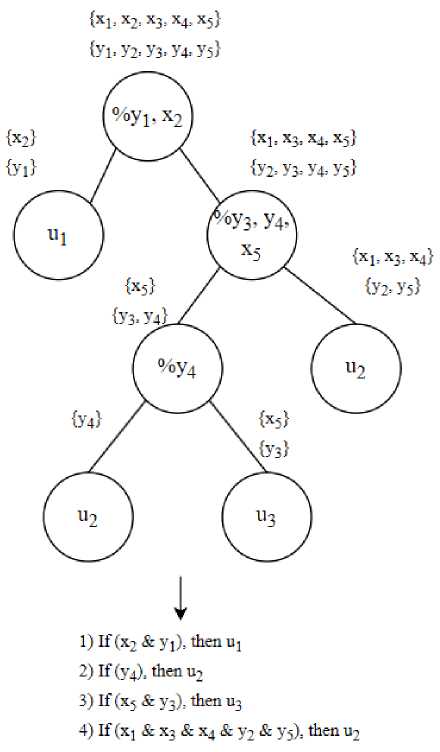
Рис. 3. Пример представления особи в генетическом программировании
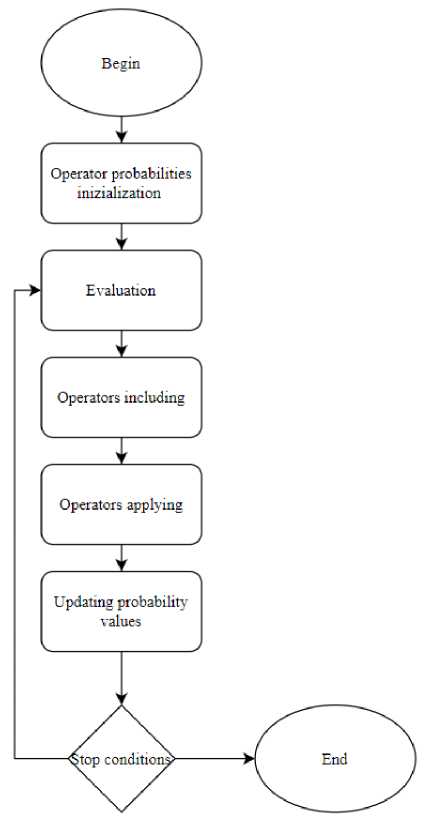
Рис. 4. Блок-схема самоконфигурации
Fig. 4. Self-configuration flowchart
Fig. 3. Individual example in the GP implementing the rule base
По мере выполнения алгоритма вероятность выбора эффективного оператора увеличивается, в то время как вероятности выбора других уменьшаются. Снижающиеся вероятности ограничиваются заданным нижним пределом, что гарантирует продолжение использования всех операторов в той или иной степени.
Данный подход позволяет алгоритму отдавать предпочтение более эффективным комбинациям операторов, сохраняя при этом их разнообразие за счет нижнего порога вероятности. После формирования базы правил для каждого терма в рамках правил определяется функция принадлежности. Следовательно, общее количество оптимизируемых параметров пропорционально общему количеству термов. Для оптимизации параметров этих функций принадлежности, представленной в виде задачи многомерного поиска, требуются методы, известные своей эффективностью для работы в многомерных пространствах, один из таких методов – дифференциальная эволюция.
Дифференциальная эволюция
Дифференциальная эволюция – третий эволюционный алгоритм, рассматриваемый в рамках статьи. Его главным отличием от выше рассмотренных эволюционных алгоритмов заключается в реализации операторов скрещивания и мутации, соответствующих векторному представлению особи, пример которого представлен на рис. 5.
|
10.1 |
29 |
31.5 |
42.21 |
43.21 |
44.142 |
51.1 |
52 |
Рис. 5. Пример индивида в дифференциальной эволюции
Fig. 5. Example of differential evolution individual
Учитывая возможность варьирования параметров ( с , σ) в функции принадлежности для каждого терма, имеющего вид (2), целесообразно использовать комбинацию дифференциальной эволюции и генетического программирования для корректировки этих параметров в соответствие с тем же критерием, который используется для оценки качества классификации.
Описание подхода
В статье рассматривается подход, использующий самоконфигурируемое генетическое программирование для эволюции базы нечетких правил в сочетании с алгоритмом дифференциальной эволюции, в частности L-SRTDE [8], для оптимизации параметров функций принадлежности. Реализация данной системы требует выполнения следующих шагов:
-
– выявить лингвистические переменные, необходимые для представления числовых переменных, относящихся к задаче, и определить их соответствующие термы;
-
– реализовать самоконфигурируемое ГП и адаптировать ДЭ для оптимизации параметров предопределенных функций принадлежности;
-
– в рамках работы генетического программирования определить целевые лингвистические переменные как терминальное множество. Функциональное множество должно включать операторы для построения правил путем комбинирования термов. Параметры функций принадлежности для каждого терма подлежат оптимизации алгоритмов дифференциальной эволюции;
-
– задать функцию пригодности как для ГП, так и для ДЭ на основе критерия, отражающего качество решения. Учитывая контекст классификации, в качестве основного критерия рассматривается точность классификации;
-
– установить начальные параметры для ГП и ДЭ. Для генетического программирования выбор конкретных операторов селекции, скрещивания и мутации автоматизируется за счет само-конфигурации, что устраняет необходимость ручного выбора операторов;
-
– провести валидацию алгоритма на эталонных задачах классификации. После успешной валидации системы может быть развернута для решения целевых задач классификации;
-
– пригодность особи в ГП оценивается после оптимизации параметров функций принадлежности. Значение пригодности в ГП устанавливается равным значению функции пригодности в ДЭ, которое, в свою очередь, вычисляется в рамках процедуры оценки функции пригодности ГП.
Концептуальное представление такой системы представлено на рис. 6.
Конечная система объединяет алгоритмы для автоматического создания и оптимизации базы правил, а также для применения этой базы правил в системе нечеткой логики для решения задач классификации. Хотя в данном случае используется точность классификации, функцию пригодности можно заменить другими метриками качества, если они будут сочтены более подходящими для конкретной задачи, без критических изменений в структуре подхода. Описанные терминальное и функциональное множества обеспечивают достаточную основу для построения базы правил для широкого круга задач.
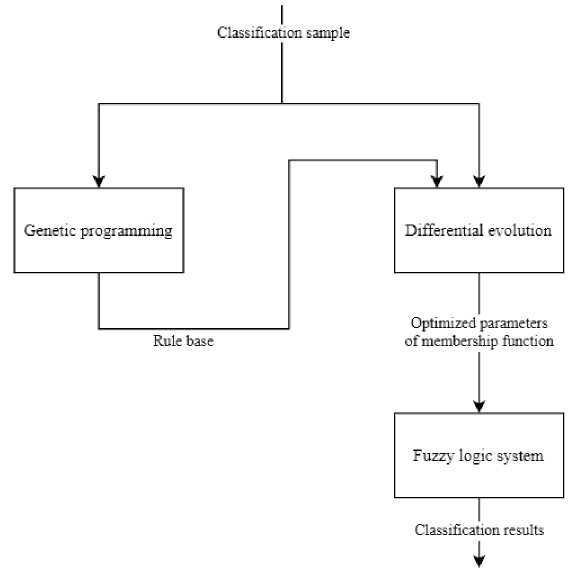
Рис. 6. Концепция комбинирования ГП и ДЭ
Fig. 6. Combining GP and DE concept
Тестирование
В качестве тестовых задач были выбраны две задачи: задача классификации ирисов Фишера [9] и задача классификации видов пингвинов Палмера [10].
В первом случае в качестве лингвистических переменных представлены четыре параметра: длина и ширина наружной доли околоцветника, а также длина и ширина внутренней доли околоцветника. Для каждой лингвистической переменной определено пять термов, характеризующих значения лингвистических переменных в словесном диапазоне: очень маленький, маленький, средний, большой, очень большой. Целевой лингвистической переменной является класс, характеризующийся тремя термами.
Во втором случае в качестве лингвистических переменных также представлены четыре признака. Целевой лингвистической переменной является вид пингвина: Adelie, Gentoo, Chinstrap. Начальные параметры самоконфигурируемого генетического программирования показаны в табл. 1.
Таблица 1
Начальные параметры самоконфигурируемого ГП
|
Параметр |
Значение |
|
Количество поколений |
40 |
|
Размер популяции |
35 |
|
Нижний предел значения вероятностей |
0,1 |
|
Глубина дерева |
5 |
|
Количество запусков |
30 |
Таким образом, поскольку метод ГП является стохастическим, результаты усредняются на основе 30 запусков алгоритма. Начальные параметры подбираются эмпирически, значение глубины задается произвольно.
Начальные параметры дифференциальной эволюции для оптимизации параметров функций принадлежности представлены в табл. 2.
Таблица 2
Начальные параметры дифференциальной эволюции при тестировании
|
Параметр |
Значение |
|
Количество поколений |
60 |
|
Размер популяции |
30 |
Начальные параметры генетического алгоритма представлены в табл. 3.
Таблица 3
Начальные параметры генетического алгоритма при тестировании
|
Параметр |
Значение |
|
Количество поколений |
60 |
|
Размер популяции |
30 |
|
Тип селекции |
Турнирная |
|
Точность |
0,0001 |
Поскольку в качестве используемого ДЭ рассматривается модификация L-SRTDE, коэффициент скрещивания и коэффициент мутации адаптивно выбираются в зависимости от показателя успешности. Результаты тестирования комбинации дифференциальной эволюции и генетического программирования представлены в табл. 4.
Таблица 4 Результаты тестирования комбинации ДЭ и ГП
|
Выборка |
Критерий |
Среднее |
Разброс |
|
Ирисы Фишера |
Точность (обучающая) |
0,9823 |
0,00006 |
|
Точность (тестовая) |
0,9311 |
0,0013 |
|
|
Пингвины |
Точность (обучающая) |
0,963467 |
0,000172 |
|
Точность (тестовая) |
0,931733 |
0,000602 |
Результаты тестирования комбинации генетического алгоритма и генетического программирования представлены в табл. 5.
Таблица 5
Результаты тестирования комбинации ГА и ГП
|
Выборка |
Критерий |
Среднее |
Разброс |
|
Ирисы Фишера |
Точность (обучающая) |
0,962 |
0,00022 |
|
Точность (тестовая) |
0,912 |
0,0152 |
|
|
Пингвины |
Точность (обучающая) |
0,94252 |
0,00081 |
|
Точность (тестовая) |
0,931733 |
0,00162 |
На основании полученных результатов можно сделать вывод, что для тестовых задач комбинация генетического программирования и дифференциальной эволюции демонстрирует превосходящую производительность. Кроме того, следует отметить, что вторая комбинация (ГП+ГА) потребовала для решения задачи больших вычислительных ресурсов.
Первая комбинация алгоритмов (ГП+ДЭ) показывает устойчивую и эффективную работу для задач классификации в рамках системы нечёткой логики. Несмотря на это, подход может быть дополнительно улучшен путём оптимизации параметров функций принадлежности после формирования каждой особи в ГП, тем самым стимулируя конкуренцию среди наиболее подходящих кандидатов.
Следует отметить, что предложенный подход требует значительных вычислительных затрат с точки зрения оперативной памяти и времени обработки. Однако для задач, в которых требуется высокая интерпретируемость, а экспертных знаний для формирования базы правил недостаточно, данный подход представляет собой хорошо обоснованное решение.
Апробация
Для апробации алгоритмов были выбраны следующие выборки для классификации: данные о кредитоспособности в Германии [11], данные об австралийских кредитных заявках [12] и данные о сердечных заболеваниях [13].
Первый набор данных содержит информацию о кредитной истории клиентов немецких банков и включает 1000 наблюдений и 20 переменных (9 категориальных и 7 числовых, а также идентификатор и целевая переменная). Целевая переменная является бинарной: «хороший» (1) или «плохой» (2) кредитный риск, где «хороший» означает, что клиент своевременно погашает кредит, а «плохой» – что существует высокий риск дефолта. Признаки включают информацию о возрасте, поле, семейном положении, занятости, сумме кредита, сроке кредита, наличии поручителей и кредитной истории. Особенностью данных является сильный дисбаланс классов (около 70 % «хороших» заемщиков и 30 % «плохих»), что усложняет задачу классификации. В связи с этим под точностью для данной выборки подразумевается взвешенная точность.
Второй набор данных является анонимизированным (названия признаков заменены сокращениями) и содержит 690 наблюдений и 15 переменных (6 числовых, 8 категориальных и целевая переменная). Целевая переменная – бинарная: 0 (отказ в кредите) или 1 (одобрение кредита). Признаки включают информацию о доходах, возрасте, кредитной истории, собственности, семейном положении. Особенностью данных является отсутствие пропусков и тщательная предобработка (все строковые значения заменены числовыми кодами), что делает их удобными для проверки алгоритмов.
Третий набор данных содержит медицинские записи пациентов и включает 303 наблюдения (после удаления пропусков – 297) и 14 переменных. Целевая переменная – наличие сердечного заболевания (0 – здоров, 1 – болен). Признаки включают возраст, пол, тип боли в груди, артериальное давление, уровень холестерина, результаты ЭКГ, пульс. Особенностью данных является их небольшой размер и наличие пропусков, что требует предварительной обработки.
Поскольку рассматриваемые задачи имеют большую размерность по сравнению с тестовыми выборками, для работы с ними было выделено больше ресурсов.
В табл. 6–8 представлены начальные параметры генетического программирования, дифференциальной эволюции и генетического алгоритма при апробации соответственно.
Таблица 6
Начальные параметры самоконфигурируемого ГП при апробации
|
Параметр |
Значение |
|
Количество поколений |
40 |
|
Размер популяции |
60 |
|
Нижний предел значения вероятностей |
0,1 |
|
Глубина дерева |
8 |
|
Количество запусков |
30 |
Таблица 7
|
Параметр |
Значение |
|
Количество поколений |
75 |
|
Размер популяции |
45 |
Таблица 8
|
Параметр |
Значение |
|
Количество поколений |
75 |
|
Размер популяции |
45 |
|
Тип селекции |
Турнирная |
|
Тип скрещивания |
Одноточечное |
|
Точность |
0,0001 |
Начальные параметры дифференциальной эволюции при апробации
Начальные параметры генетического алгоритма при апробации
Результаты апробации комбинации ДЭ и ГП представлены в табл. 9.
Результаты апробации комбинации ДЭ и ГП
Таблица 9
|
Выборка |
Среднее |
Разброс |
Max |
Min |
|
|
Немецкие кредиты |
Обучающая |
0,6725 |
0,009528 |
0,69 |
0,65 |
|
Тестовая |
0,63075 |
0,023912 |
0,675 |
0,59 |
|
|
Австралийские кредиты |
Обучающая |
0,6515 |
0,009366 |
0,671506 |
0,629764 |
|
Тестовая |
0,63285 |
0,036069 |
0,71223 |
0,561151 |
|
|
Заболевания сердца |
Обучающая |
0,7914 |
0,0074 |
0,81 |
0,7625 |
|
Тестовая |
0,771 |
0,0216 |
0,815 |
0,74 |
|
Результаты апробации комбинации ГА и ГП представлены в табл. 10.
Результаты апробации комбинации ГА и ГП
Таблица 10
|
Выборка |
Среднее |
Разброс |
Max |
Min |
|
|
Немецкие кредиты |
Обучающая |
0,6525 |
0,00821 |
0,6625 |
0,6425 |
|
Тестовая |
0,6125 |
0,0419 |
0,635 |
0,5825 |
|
|
Австралийские кредиты |
Обучающая |
0,6425 |
0,00881 |
0,65 |
0,635 |
|
Тестовая |
0,62 |
0,0528 |
0,61 |
0,59 |
|
|
Заболевания сердца |
Обучающая |
0,7615 |
0,0084 |
0,7725 |
0,75 |
|
Тестовая |
0,7412 |
0,0452 |
0,76 |
0,735 |
|
Исходя из результатов, можно сделать вывод о том, что как в процессе апробации, так и в ходе тестирования комбинация генетического программирования и дифференциальной эволюции стабильно демонстрирует более высокие результаты. Статистическая значимость была оценена с помощью критерия Уилкоксона, примененного к исходным результатам тридцати независимых запусков, который выявил значительную разницу (α = 0,05).
Заключение
В рамках данной статьи рассмотрено применение гибридного подхода к автоматизированному проектированию систем нечеткой логики для решения задач классификации. Предложенный подход сочетает самоконфигурируемое генетическое программирование для структурной эволюции базы правил и дифференциальную эволюцию для параметрической оптимизации функций принадлежности. Основной целью было устранение известного узкого места проекти- рования систем нечеткой логики – зависимости от субъективных и часто недоступных экспертных знаний для построения базы правил – при сохранении интерпретируемости модели.
Экспериментальные результаты, проверенные на эталонных и реальных наборах данных, позволяют сделать несколько ключевых выводов. Во-первых, эволюционные алгоритмы успешно генерируют базы правил, адекватно отражающие лежащие в основе закономерности, необходимые для корректной классификации. Комбинация ГП и ДЭ стабильно превосходила гибрид ГП и стандартного ГА по точности классификации во всех тестовых выборках. Меньшие вычислительные затраты ДЭ при оптимизации большого количества параметров выставляет комбинацию ГП и ДЭ как более эффективный и результативный вариант предложенного подхода.
Однако в рамках данной статьи заметен фундаментальный компромисс, присущий данному методу. Основное преимущество таких систем нечеткой логики – их высокая интерпретируемость, обеспечивающая прозрачный, понятный для человека набор лингвистических правил. Это достигается ценой некоторого снижения средней точности по сравнению с традиционными «черными ящиками».
Выявлено несколько ограничений и направлений для улучшения:
-
1. Вычислительная сложность: вложенный процесс оптимизации, при котором ДЭ точно настраивает функции принадлежности для каждого кандидата в базы правил в популяции ГП, является вычислительно затратным. Это ограничивает применимость подхода для очень больших наборов данных или систем реального времени. Будущие исследования могут быть направлены на использование суррогатных моделей или более эффективных стратегий оптимизации для снижения этих затрат.
-
2. Предобработка данных и размерность: производительность системы, вероятно, чувствительна к качеству предобработки данных и первоначальному определению лингвистических переменных. Производительность метода на сложных, многомерных наборах данных может быть ограничена взрывным ростом пространства поиска. Для повышения масштабируемости могут быть интегрированы методы автоматического отбора признаков или снижения размерности до начала эволюционного процесса.
-
3. Потенциал деанонимизации: важным, хотя и вторичным, выводом является то, что интерпретируемая природа рассмотренных баз правил потенциально может облегчить деанонимизацию конфиденциальных наборов данных. Это поднимает важные вопросы для применения подобных методов в чувствительных к конфиденциальности областях, таких как финансы и здравоохранение, и требует дальнейшего изучения методов эволюционной оптимизации с сохранением конфиденциальности.
-
4. Выбор функции пригодности: хотя в качестве критерия приспособленности использовалась точность классификации, интерпретируемость полученных баз правил не была явно количественно оценена или оптимизирована. Будущие варианты подхода могли бы включить многокритериальную оптимизацию для явного балансирования между точностью и метриками интерпретируемости, такими как простота или понятность правил, что потенциально может привести к созданию более компактных и интуитивно понятных моделей.
В заключение, комбинация самоконфигурируемого ГП и ДЭ представляет собой устойчивый и обоснованный подход для построения систем нечеткой логики в сценариях, где экспертные знания ограничены, а интерпретируемость модели является критически важным требованием. Несмотря на свои вычислительные затраты и присущий компромисс между точностью и интерпретируемостью, он предлагает хороший вариант автоматизации эффективных с точки зрения интерпретируемости классификаторов, способствуя достижению целей объяснимого искусственного интеллекта.
Acknowledgment. This research was supported by the Russian Science Foundation (project № 2519-20154, , and the Krasnoyarsk Regional Science Foundation.
