Реализация эвфемистического потенциала лексической единицы в рамках реляционной модели

Автор: Логвина Светлана Андреевна
Журнал: Вестник Тверского государственного университета. Серия: Филология @philology-tversu
Рубрика: Исследования по теории и истории языка
Статья в выпуске: 4, 2020 года.
Бесплатный доступ
В данной статье автором предпринята попытка метрического описания функции эвфемистического потенциала с последующим анализом изменений значения лингвистической переменной в зависимости от степени отклонения от «эталона». Результаты вычислительных операций легли в основу классификации интеллектуальных объектов с разными уровнями качества эвфемистического потенциала: эвфемизмы-автоматизмы, собственно эвфемизмы и эвфемистические симулякры.
Эвфемистический потенциал, эвфемистическая номинация, лингвистическая переменная, нечеткое множество, среднеквадратическое отклонение
Короткий адрес: https://sciup.org/146281752
IDR: 146281752 | УДК: 81`32 | DOI: 10.26456/vtfilol/2020.4.031
Manifestation of the euphemistic potential of a lexic unit in the framework of a relational model
In this article, the author attempts to describe the function of the euphemistic potential metric, followed by an analysis of the changes in the meaning of the linguistic variable depending on the degree of deviation from the «standard». The results of computation formed the basis for the classification of intelligent objects with different levels of quality of euphemistic potential: euphemisms-automatisms, euphemisms proper, and euphemistic simulacra.
Текст научной статьи Реализация эвфемистического потенциала лексической единицы в рамках реляционной модели
Изучение особенностей эвфемии, выявление ее основополагающих признаков имеет длительную историю. Наиболее продуктивный период исследования этого феномена пришелся на ХХ столетие, когда наряду с этнографами проблемой типологизации эвфемизмов стали заниматься лингвисты и лексикографы. Именно в этот период учеными было предложено значительное количество классификаций эвфемизмов, проанализированы способы образования и пополнения эвфемистической номинации, а также создан ряд словарей эвфемизмов. Несмотря на значительные достижения в исследовании этого феномена, множественные попытки комплексной параметризации не привели к созданию универсального алгоритма в рамках «диалектики равных прав» автора, читателя (реципиента) и текста (дискурса) [7]. Основную сложность представляет собой именно многообразие способов авторской семантизации эвфемизма как совокупность техник, раскрывающих его содержание, что ограничивает возможность алгоритмического подхода к описанию языка. По мнению Крюковой Н.Ф., именно герменевтика проявляет больший интерес к авторской семантике. Она исследует закономерности функционально обусловленного выбора стиля и экспрессивных ресурсов языка, ищет алгоритмы интерпретации семантики текста [7: 106].
Однако, с точки зрения алгоритмизации языка, несмотря на активную критику, именно генеративистика в XX в. добилась значимых результатов, демонстрируя воплощение прочного союза логики с математическим аппаратом при создании классификации формальных языков и формальных грамматик. В рамках универсальной грамматики Н. Хомского [12] бесконечное и хаотичное разнообразие языковых процессов было систематизировано с помощью рекурсии - простейшей логической операции, при которой одна единица высказывания вкладывается в другую, и логической операции соединения. Трансформационный анализ Н. Хомского базируется на строгих логических операциях, направленных на выработку соответствующих алгоритмов, необходимых для выполнения преобразований [3].
А.А. Залевская [4: 16] убеждена, что идентификация слова как такового и/или лингвистической единицы (в нашем случае, эвфемизма) представляет собой сложный процесс, а также составляет обязательный этап во многих ситуациях жизнедеятельности человека. Именно поэтому, как нам представляется, исследователи нередко обращаются к построению гипотез, моделированию постулируемых процессов на основании признаков того, что удаётся обнаружить в результате наблюдений и экспериментов, с целью выявления стратегий и опор, используемых носителями языка и культуры. Результатом (продуктом) постулируемого сложного процесса идентификации является переживание слова или фигуры речи как понятного, что подразумевает наличие готовности при необходимости ответить (в том числе – самому себе) на множество вопросов (типа: кто? / что? / где? / когда? / как? / зачем? / почему? и т.д.). Анализ статистики закономерных показателей, основывающихся на ответах на выше представленные вопросы, в рамках математической логики, составляет метрическое описание, лежащее в основе классификации и категоризации исследуемых явлений.
Для определения реляционных данных ученые неоднократно прибегали к выявлению устойчивых, существенных причинно-следственных, повторяющихся взаимосвязей между процессами и лингвистическими явлениями как частями системы. Так, при создании словаря эвфемизмов Хью Роусон опирался на два закона, которым, по его мнению, подчиняются эвфемизмы [14: 6].
Первый, закон Грешама (Gresham’s Law), восходит к экономической теории, которая утверждает: «плохие деньги имеют тенденцию изымать из обращения хорошие деньги». Аналогичные процессы происходят и в языке, когда «плохие» значения или ассоциации, вызываемые теми или иными словами, могут вытеснить из употребления те значения или ассоциации, что некогда были безобидными [13]. Закон Грешама приводит в действие закон последовательности (the Law of Succession). Так как «значение слова “загрязняется”, само слово становится табу для носителей языка и требует создания нового эвфемизма. То же самое происходит и со вторым и третьим словом. Примером такой эвфемистической цепочки служит слово mad (‘безумный’), которое последовательно эвфемизировалось в crazy > lunatic > mentally deranged > mental » (цит. по [9: 61]). Несмотря на системную логику, лежащую в основе этих законов, принципы классификации и верификации эвфемизмов, на которые опирается ученый при составлении словарей, демонстрируют весьма субъективный характер.
В своих исследованиях Г.Г. Кужим [8] попыталась охарактеризовать традиционное понятие эвфемии в свете закона триады как одного из объективно универсальных лингвистических явлений на основе принципа стилистических оппозиций. Данный закон, по мнению автора, позволяет отправителю языковой информацию передавать информацию: а) стилистически нейтрально; б) способом мелиорации; в) способом детериорации. Все три компонента закона триады отражают качественное преобразование базового денотативного значения, в то время как функция «вуалятивности», притенения значения не может быть рассмотрена в рамках заявленного лингвистического закона триады, что ограничивает спектр анализа эвфемистического субстрата.
Обобщая опыт предыдущих исследований в области стандартизации эвфемизмов (А.М. Кацев, Н.М. Бердова, А.М. Никитина, Н.М. Потапова, Н.В. Прядильщиков, Е.П. Сеничкина, Е.Н. Торопцева и т.д.), в которых исследуется явление эвфемии и сами эвфемизмы, а также выделяется ряд особенностей и существенных признаков, позволяющих отграничивать эвфемизмы от схожих явлений - мелиоративов и криптолалий (тайноречия), манипуляции, дезинформации, политических и коммерческих уловок и т.д., -мы попытаемся произвести метрическое описание функции потенциала эвфемистической единицы. Проанализировав научные подходы к вопросу классификации эвфемизмов, мы выделили три основных условия, одновременная реализация которых может считаться минимально достаточной (закон достаточного основания) [1] для разграничения эвфемизмов и смежных явлений. В нашем исследовании рассматриваются три базовых условия образования эвфемизма: субъективное «улучшение» денотата (посредством экстраполяции переживаний широкого спектра); сохранение истинности и информативности исходного высказывания; и вуалятивность, притенение значения; однако, при необходимости, их количество может быть увеличено. Реализация этих условий в разных констелляциях позволяет строить предположения о перспективе (потенциале) лингвистической единицы стать эвфемизмом и на основании этого выделять группы с типовыми параметрами.
Продолжая логику суждения Е.А. Уваровой [11: 453] о том, что эвфемистический потенциал «зависит от расположения отрицательного компонента в архисеме, гипосеме, либо на периферии значения», можем предположить, что также он зависит и от степени реализации базовых модусов эвфемизма: формального улучшения денотата, сохранения истинности и информативности исходного высказывания и маскировки при реконструкции интеллектуального объекта. В каждом из заявленных модусов именно срединные показатели являются «идеальным условием» для формирования и реализации эвфемизма, тем самым определяя его потенциал.
Научное употребление термина «потенциал» своими корнями уходит в философию Аристотеля, который рассматривал акт (актуальное) и потенцию (потенциальное) как основу онтологического развития. При этом потенциал рассматривался Аристотелем как способность чего-то быть не тем, что оно есть в категории субстанции качества, количества и места, что позволяло представить развитие как переход от первого ко второму [10: 14]. В ракурсе лингвистической парадигмы речь идет о переходе (преобразовании) от отрицательной, по тем или иным причинам, денотативной основы концепта к удовлетворительной, «в определенных коммуникативных условиях, форме овнешнения метафорической (в нашем случае - эвфемистической) интенции автора, посредством перцептивно-образной фиксации ассоциативного и метафорического фона (который включает, как общие значения, так и уникальные)» [6: 25–26], реализуемом с помощью мощного коннотативного ресурса. Эвфемизм обеспечивает восприятие определенного объекта действительности и представляет собой структурированный концептуальный феномен, в котором сигнификат соответствует комплексу признаков, характеризующих то, каким объект или ситуация отражаются в сознании говорящего (что подчеркивает субъективный характер эвфемистической номинации как особого типа семантического варьирования), а денотат соответствует объему понятия, которое может быть в дальнейшем субъективно «развернуто» за счет укрупнения единиц индивидуального знания, как путем компрессии смысла, так и путем обратного процесса - детализации смысла с концентрацией внимания на различных аспектах этого целого с общей тенденцией «улучшения» исходной информации. Субъективность эквивалентности эвфемизма, как эвфемистического переосмысления, высвечивает те или иные характеристики объектов действительности, моделирует их, прогнозирует их развитие и направляет деятельность говорящего, связанную с «уравновешиванием» коммуникации при постоянном «контроле» правильности восприятия денотата. В свою очередь, события, реалии, которые отождествляются с изменением личностного смысла и/или эмоционального фона индивида, определяя разнообразие коннотативных аспектов эвфемизма. Потенциал коннотативного значения эвфемизма, по нашему мнению, отображает переход от первичного, заданного значения к новому преобразованному значению ad hoc, где оптимально (категориально корректно) реализованная совокупность признаков (модусов) определяет вероятность лингвистической комбинации быть воспринятой как эвфемизм. Уровни реализации эвфемистического потенциала (высокий, средний и низкий) пропорционально зависят от объема реализованных условий.
Для воссоздания эвфемизма или имитации элемента эвфемистической номинации в коммуникативных стратегиях как естественной, так и «электронной» коммуникации необходима реализация определенных «технических» параметров – лингвистических, графических, фонетических и т.д. как соответствий внешним требованиям, предъявляемым к эвфемизму при восприятии.
Аргументируя высказанную позицию, предпримем попытку схематично представить расчет лингвистического коэффициента потенциала эвфемистической единицы как совокупность результатов, рассчитанных математическим путем.
Конкретизируя реляционную модель эвфемистической единицы, определим лингвистические переменные и нечеткие подмножества, необходимые для проведения оценки эвфемистического потенциала. Так как оценка интегрального показателя производится по ряду элементарных показателей, то сначала с помощью теории нечетких множеств будет оценен каждый элементарный показатель, иначе, модус, где модус амелиорации (Ма) соответствует базовому признаку эвфемизма – субъективное «улучшение» денотата; лингвистическое множество модуса искренности (Мs) соответствует такому базовому признаку эвфемизма, как сохранение истинности и информативности исходного высказывания; а также лингвистическое множество контенсивного (стратегия морфосинтаксического кодирования с базовым переходом от значения к форме) модуса (Mk), который соответствует базовому признаку вуалятивности. После определения элементарных показателей (Ма, Мs, Mk) производится их свертка в интегральный показатель ЕP (эвфемистический потенциал). Поскольку в каждом заявленном модусе именно «срединные» показатели демонстрируют «идеальные условия» для создания эвфемизма, то эвфемистический потенциал будет рассчитан путем вычисления среднеквадратического отклонения как наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания. Подобный подход позволит избежать большого разброса в числовых значениях всех элементарных показателей и ликвидировать различия их измерителей, приводя каждый из показателей к универсальному виду лингвистического описания (табл. 1).
Таблица 1. Терм-множества значений лингвистических переменных
|
Лингвистическая переменная ЕP-уровень эвфемистического потенциала |
Терм-множество |
|
ЕP-Н1 |
Нечеткое подмножество «незначительный уровень или полное отсутствие эвфемистического потенциала» |
|
ЕP-Ср1 |
Нечеткое подмножество «средний (недостаточный) уровень эвфемистического потенциала» |
|
ЕP-В |
Нечеткое подмножество «высокий уровень эвфемистического потенциала» |
|
ЕP-Ср2 |
Нечеткое подмножество «средний (избыточный) уровень эвфемистического потенциала» |
|
ЕP-Н2 |
Нечеткое подмножество «низкий (избыточный) уровень эвфемистического потенциала» |
|
L1 |
Лингвистическая переменная модуса амеллиорации |
|
L2 |
Лингвистическая переменная модуса истинности |
|
L3 |
Лингвистическая переменная модуса контенсивности |
Приведенная в данной таблице лингвистическая переменная представляет собой переменную (понятие), значениями которой являются символы нечетких множеств, соответствующих различным уровням эвфемистического потенциала (ЕP-Н1, ЕP-Ср1, ЕP-В, ЕP-Ср2, ЕP-Н2).
Важно уточнить, что исчерпывающего описания понятия не существует. Поскольку слова в коммуникации сигнализируют актуальные признаки понятий, то ни одно слово, использованное в коммуникативном акте, не может выразить все содержание понятия. Масштаб эвфемистической экстралингвистической среды напрямую связан со значимостью этого понятия для лингвокультурного сообщества, а также с аксиологической или теоретической ценностью того внеязыкового явления, которое воплощено во всем его когнитивно-семантическом объеме. «При этом осуществляется идентифицирующая референция индивидом самого себя относительно конкретной профессиональной группы и конкретной личности, а также формируется аттитюдно-релевантная информация об ингерентных коннотациях в спектре полиморфности общения» [5: 32]. Например, понятие «смерть» будет иметь больше лингвистических форм, чем понятие «опыты над животными». Соответственно, сложно представить конкретный математический результат лингвистического множества каждого из этих понятий, но очевидно, что лингвистическое множество понятия смерть больше, чем лингвистическое множество понятия опыты над животными. Учитывая тот факт, что эвфемистические производные не имеют конечного числа, а тематические концепты имеют разную по объему лингвистическую глубину (количество лексических единиц-вербализаторов), считаем рациональным обозначение показателей от 0 до 1, включая десятичные значения. Соответственно, распределение от 0 до 1, независимо от количества эвфемистических производных, считается условным. В качестве примера можно рассмотреть условный классификатор текущих значений ресурсной составляющей эвфемистического потенциала вуалятивного модуса (Мк) понятия бродяга как критерий разбиения данного подмножества (рис. 1).
T ramp
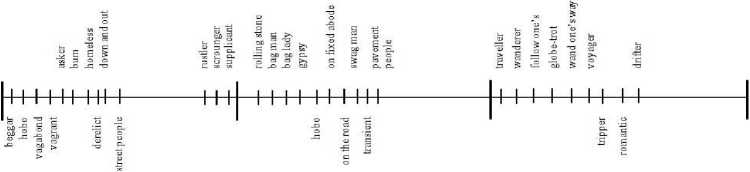
Рис. 1
На данной гистограмме представлен далеко не полный спектр коннотативных значений, которые могут иметь разноуровневый эвфемистический потенциал, поскольку лингвистический эвфемистический субстрат понятия бродяга (переменная) может апеллировать к целому ряду синонимов, лексико-семантических полей, метафорических образов, чье количество не имеет исчерпывающего числа. Коннотативные значения (значения переменной) среднего блока демонстрируют достаточный уровень «притенения» денотативного значения, чтоб эти лексические единицы могли быть реализованы как эвфемизмы (терм-множество).
Для сегментации нормализованного изображения заданного модуса (Мs), будем использовать составной пятиуровневый 01-классификатор. Пусть имеется унимодальная гистограмма фактора с «подозрением» на то, что за этой гистограммой стоит нормальное распределение. Тогда, по общим правилам статистики, определим среднее значение x гистограммы и среднеквадратическое отклонение от среднего (СКО) σ . Построим набор из пяти узловых точек пятиуровневого классификатора по правилу:
-
х 1 = x – t 1 σ ,
-
х 2 = x – t 2 σ ,
-
х 3 = x,
-
х 4 = x + t 2 σ ,
-
х 5 = x + t 2 σ ,
где ti — коэффициенты, в классической статистике являющиеся коэффициентами Стьюдента, которые широко применимы в практике проверки статистических гипотез о равенстве средних значений (в нашей теории это «достаточный» показатель) в том числе и в гуманитарных науках. Для каждой узловой точки классификатора справедливо, что в ней уровень фактора распознается однозначно, со стопроцентной уверенностью. Например, точка х1 отвечает очень низкому уровню фактора (ОН), х2 – низкому уровню фактора (Н) и т. д. Поскольку при кодировании эвфемизма необходимо учитывать большое количество переменных (например, опыт индивида или эмоциональное состояние, фонетическое предъявление), влияющих как на его кодирование, так и на декодирование, далее поделим каждый отрезок [µi, µi + 1] на три зоны: зону абсолютной уверенности, зону пониженной уверенности и зону абсолютной неуверенности. Длины этих трех зон составляют пропорцию 1 : u : 1, где параметр u выражает глубину неуверенности. Нанесем дополнительные точки (границы зон уверенности-неуверенности) на ось носителя фактора. Тогда можно в зоне уверенности принять соответствующую функцию принадлежности за 1, в зоне абсолютной неуверенности – за 0, а зону неуверенности описать наклонным ребром соответствующего трапециевидного нечеткого числа (рис. 2).
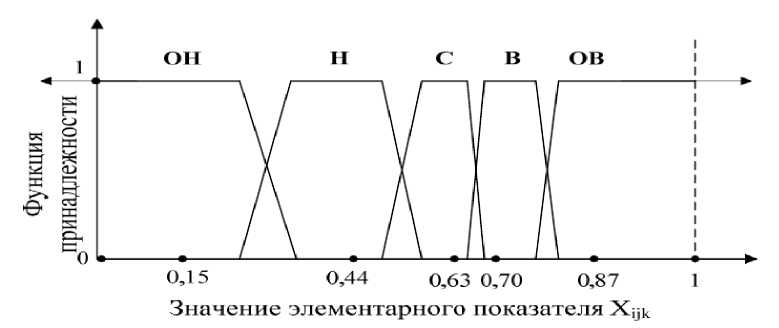
Рис. 2
В качестве примера можем представить стандартный пятиуровневый классификатор коэффициента вуалятивности (Мк) эвфемистического значения понятия «бродяга». Боковые грани трапеций отражают колебание уверенности-неуверенности в принадлежности конкретного отрезка на 01-носителе к тому или иному терм-множеству. Например, существует высокая вероятность того, что такие выражения, как vagrant, vagabond, derelict, down-and-out будут реализованы как эвфемизмы по отношению к понятию tramp (бродяга), в то время как выражения beggar и homeless person будут иметь низкую вероятность реализации в качестве эвфемизма к понятию tramp . Источником примеров лексическо-семантического объема к понятию tramp является тезаурус как корпус, полномерно указывающий семантические отношения (синонимы, антонимы, паронимы, гипонимы, гиперонимы и т. п.) между лексическими единицами. [15].
При построении классификатора необходимо ассоциировать узловые точки пенташкалы с гистограммой. Узловыми точками низкого (Н) значения показателя можно считать значение 0,15 и 0,87, высокого (В) — значение 0,63.
Для данного классификатора узловые точки Н и В определены с помощью таблицы коэффициентов Стьюдента [2], с учетом частоты попадания значений показателя в интервал. Исходя из расчетов, узловая точка подмножества Н равна 0,44 и 0,70. Исходя из значений узловых точек и параметра u, построим интервалы зон абсолютной уверенности в интерпретации:
ЕР-Н1: [0,07; 0,25];
ЕР-Ср1: [0,34; 0,50];
ЕР-В: [0,57; 0,65];
ЕР-Ср2: [0,68; 0,76];
ЕР-Н2: [0,81; 0,92].
Классификация промежутков качества лингвистической переменной вуалятивности (Мк) понятия «бродяга» представлена в табл. 2. Такие же промежутки качества будут справедливыми и для модуса истинности, и для модуса амелиорации.
Таблица 2
|
Промежутки качества лингвистической переменной L1 |
||||
|
«низкий недо» |
«средний недо» |
«высокий» |
«средний пере» |
«низкий пере» |
|
(0; 0,07; 0,25; 0,34) |
(0,25; 0,34; 0,5; 0,57) |
(0,5; 0,57; 0,65; 0,68) |
(0,65; 0,68; 0,76; 0,81) |
(0,76; 0,81; 0,92; 1) |
Под качеством лингвистической переменной понимаем объем и количество преобразований, достаточных для того, чтобы «притенить» стигму, но не исказить ее. Например, промежуток качества «низкий недо» свидетельствует о незначительном недостаточном «притенении», в то время как «низкий пере» отражает чрезмерное «притенение» отрицательного компонента значения. Однако и в том, и в другом случае это не приведет к реализации коннотативного значения с таким качеством как признака эвфемизма. И лишь «достаточное притенение» будет иметь высокое качество коннотативного значения, чтобы послужить формированию эвфемизма. В буквенном выражении это может быть представлено следующим образом:
ЕР-Н1: [Н,Н,С; С,Н,С; С,Н,Н]
ЕР-Ср1: [Н,С,С; С,Н,С; С,С,Н] ____________________ ЕР-В: [С,С,С] _____________________________________ ЕР-Ср2: [В,С,С; С,В,С; С,С,В] _____________________ ЕР-Н2: [В, В,С; С,В,В; В,С,В]
Таким образом, подготовительный этап состоит из четырех шагов: определение показателей модели, присвоение им значимости, определение лингвистических переменных, построение классификаторов для универсальных показателей по трем базовым модусам.
После распознавания значений элементарных показателей для конкретного понятия следует непосредственно этап оценки уровня эвфемистического потенциала, который производится на основе расчета параметров лингвистического коэффициента эвфемистического потенциала в - 38 - условиях неопределенности (уверенность/неуверенность) по формуле среднеквадратического отклонения.
Результирующий показатель эвфемистического потенциала (ЕР) определим как простую среднюю от его ресурсных составляющих с помощью формулы среднеквадратичного отклонения
/to=J5^5^^, (1)
где f(x) – потенциал эвфемизма,
Xi – значение лингвистической переменной данного эвфемизма, в данном случае рассматривается формулы, со значением n=3, где n принимает значения i, j, k (см. табл. 3).
Таблица 3
|
X i |
Лингвистическая переменная модуса амелиорации |
|
X j |
Лингвистическая переменная модуса истинности |
|
X k |
Лингвистическая переменная модуса контенсивности |
X – среднеарифметическое значение лингвистической переменной рассматриваемого эвфемизма.
Областью определения функции f(x) является промежуток [0; 1], содержащий все рациональные числа, так называемый интервал оценки качества эвфемистического потенциала. Объявляем числовое значение середины отрезка 0,5 эталонным, то есть значение f(x)=0,5 – это «идеальный» эвфемизм по всем параметрам. Значения, приближенные к эталонному, назовем контрольным интервалом.
Для оценки значений X_ijk также берем интервал [0; 1], эталонным значением объявляем значение 0,5, но сам интервал разбиваем условно на 5 частей. Устанавливаем соответствие между произведенной оценкой для значений X_ijk и промежутками качества лингвистической переменной (см. табл. 4).
Таблица 4
|
Промежутки качества лингвистической переменной A jk | |
||||
|
«низкий недо» |
«средний недо» |
«высокий» |
«средний пере» |
«низкий пере» |
|
(0; 0,2] |
(0,2; 0,4) |
[0,4; 0,6] |
(0,6; 0,8) |
(0,8; 1) |
В табл. 4 показаны изменения лингвистической переменной в зависимости от степени отклонения значения от эталонного 0,5. Эталонным значением выступает то, которое во всех трех модусах будет демонстрировать изменения, достаточные (т.е. средние показатели) для коммуникативного комфорта. Например, срединный показатель модуса формального улучшения денотата отображает улучшения в альтернативном именовании денотата, происходящие за счет положительных ассоциаций и отсутствия негативной семы путем смещения акцента на положительные признаки объекта. Срединный показатель модуса истинности включает коннотации, которые демонстрируют незначительное усечение и достаточную достоверность информации, т.е. меняя форму преподнесения, они не меняют референт. И срединный показатель модуса вуалятивности индексирует качественные изменения, связанные с образным представлением действительности в ходе реноминации первичного знака, ассоциативные шаги которых насчитывают не менее 4 и не более 7 преобразовательных компонентов. К таким эталонным эвфемистическим значениям понятия tramp можно отнести конотации pavement people и wanderer.
Все 3 переменные из таблицы 3 рассматриваются по данной схеме, однако если X_ijk попадает в промежутки 1 или 5, то необходимо ввести понятие коэффициента усиления значения лингвистической переменной k. Если значение лингвистической переменной попадает в промежутки 1 или 5 в соответствии с таблицей 2, то значение X_ijk в формуле (1) домножается на коэффициент k = n/N, который показывает отношение высоты уровня значения лингвистической переменной (n) к количеству градаций промежутка оценивания (N).
Например, если выражение бездомный оценено как xi = 0,7
xj = 0,3
xk = 0,2 по отношению к понятию бродяга , значит, xi попадает в промежуток 4, xj – в промежуток 2, xk – в 1. Рассчитаем эвфемистический потенциал данного высказывания:
_ 0,7+0,3+0,2 ,
X =-------= 0,4 - среднеарифметическое значение лингвистических переменных;
=
7(0,7 - 0,4)2 + (0,3 - 0,4)2 + (0,1 * 0,2 - 0,4)2 = 0,09+0,01+0,02=0,12
Получили показатель 0,12, который попадает в промежуток 1, значит, эвфемистический потенциал выражения бездомный для понятия бродяга является низким.
Резюмируя результаты вычислительной стороны нашего исследования, изложим ниже объяснительную базу нашей классификации. Рассмотренный выше эмпирический материал позволяет нам установить корреляцию с показателями, распределяемыми нами по трем группам. На основе численного значения интегрального показателя произведем его лингвистическую интерпретацию с определением уровня принадлежности значения показателя к конкретной группе.
В нашей теории знаки, которые попали в диапазон значений (0,25; 0,34; 0,5; 0,57) по всем трем модусам (коэффициентам) или в буквенном показателе хотя бы один показатель Н [например, Н,С,С; С,С,Н, С,Н,Н и т.д.], будут иметь низкий, недостающий эвфемистический потенциал. Согласно развиваемой нами теоретической концепции, единицы с такими показателями являются эвфемизмами-автоматизмами – интеллектуальными объектами минимальной сложности. Реализовывая в коммуникации эвфемистические выражения, находящиеся «на поверхности», индивид затрачивает минимум интеллектуальных усилий, что тождественно отражается на количестве и качестве когнитивных процессов, а также может иметь как фоническую, так и хронометрическую спецификацию.
Знаки, попавшие в диапазон значений с [С,В,С], [В,С,С] и т.д. с показателем «В» в одном из модулей (0,65; 0,68; 0,76; 0,81) будут иметь также средний или низкий, по причине избыточности, «пере» эвфемистический потенциал. В нашем исследовании такие знаки именуются псевдоэвфемизмами, или эвфемистическими симулякрами, поскольку их прагматические функции носят симулятивный характер, используют иллокутивный потенциал эвфемии в «меркантильных» целях, тем самым дискредитируя явление эвфемии. К таким симулякрам могут относиться социально-политические манипулятивные обороты. Нарушая сущностный философский базис эвфемизма, а именно «забота о…», симулякры не могут быть отнесены к категории эвфемизмов. Несмотря на то, что эвфемистический симулякр будет представлять собой сверхсложный интеллектуальный объект, поскольку, наряду с эвфемистической реноминацией исходного денотата (когнитивные механизмы особой направленности), говорящим предпринимаются стратегии сложной (многоходовой) манипуляции, прочтение которой адресантом может привести и зачастую приводит к негативному результату коммуникации, в то время как эвфемизм изначально запрограммирован на создание бесконфликтного коммуникативного взаимодействия.
Символизация и конструирование знака собственно эвфемизма осуществляется с учетом всех трех признаков, обеспечивающих корректную кодировку знака-эвфемизма. Все знаки, которые попадают в диапазон [С,С,С] или (0,5; 0,57; 0,65; 0,68) во всех трех плоскостях, будут обозначены как лексические единицы с высоким эвфемистическим потенциалом с точки зрения соответствия прагматическим нормам в рамках реализации основных принципов эвфемии. Это лингвистическое образование, продукт, заданный показателями трех равнозначных ортогональных векторов (модусов), актуализация средних величин которых приводит к материализации лингвистических знаков с высоким эвфемистическим потенциалом. Такой знак-эвфемизм будет представлять собой сложный интеллектуальный объект, при кодировании которого индивид всегда идет на преодоление автоматизма в выборе средств из числа уже готовых, опираясь на принцип гуманности.
В нашем исследовании рассматриваются три базовых условия образования эвфемизма, однако, при необходимости и достаточной обоснованности, их количество может быть увеличено. Реализация этих условий позволяет строить предположения о перспективе (потенциале) лингвистической единицы стать эвфемизмом с позиции реализации реляционной модели.
Список литературы Реализация эвфемистического потенциала лексической единицы в рамках реляционной модели
- Бирюков Б.В., Ивин А.А. Закон достаточного основания. URL: https://gtmarket.ru/concepts/6975 (дата обращения: 20.07.2020).
- Выборки и доверительные интервалы. URL: https://www.mathelp.spb.ru/book2/tv12.htm (дата обращения: 20.07.2020).
- Григорьева Н.В. Аспекты теории глубинных структур в работах Н. Хомского // Вестник Воронежского государственного университета. Серия: "Лингвистика и межкультурная коммуникация". 2018. № 4. С. 9-14.
- Залевская А.А. О междисциплинарном потенциале научного термина // Вопросы психолингвистики. 2019. № 3 (41). С. 14-23.
- Зубкова О.С. Неоднородность каламбура как лингвосемиотического феномена и проблема понятийной редукции // Теория языка и межкультурная коммуникация. 2014. №1 (15). С. 32-37.
- Зубкова О.С. Функциональная релевантность контекстуальной, социальной, институциональной и идеологической означивающих практик (попытка расширения понятийного аппарата) // Теория языка и межкультурная коммуникация. 2013. № 2 (14). С. 23-33.
- Крюкова Н.Ф. Дискурсивно-стилистический потенциал метафоризации // Теория и практика лингвистического описания разговорной речи. 2016. № 30. С. 105-108.
- Кужим Г.Г. Универсальный лингвистический закон триады, мелиорация и детериорация в современном английском и русском языках, явление эвфемии в свете закона триады: дис. … канд. филол. наук: 10.02.19: Армавир, 2003. 188 c.
- Никитина И.Н. Эвфемия в зарубежной и отечественной лингвистике: история вопроса и перспектива исследования // Вестник ВУиТ. 2009. №1. C. 49-64.
- Реанович Е.А. Смысловые значение понятия "Потенциал" // МНИЖ. 2012. №7-2 (7). С. 14-15.
- Уварова Е.А. Семантический механизм эвфемизации // Известия ТулГУ. Гуманитарные науки. 2010. № 2. С. 452-460.
- Chomsky N. Aspects of the Theory of Syntax. Cambridge, Massachusetts: MIT Press, 1965. 251 p.
- Postoutenko K. Gresham's Law, Conceptual Semantics, and Semiotics of Authoritarianism: Do "Bad" Concepts Drive Out "Good" Ones? // Contributions to the History of Concepts. 2014. Vol. 9. № 1. Pp. 1-23.
- Rowson H.A. Dictionary of Euphemisms and Other Doubletalk. New York: Crown Publishers, Inc., 2002. 463 p.
- Synonyms and Antonyms of Words // URL: https://www.thesaurus.com/ (accessed at 08.07.2020).
