Реализация оценки эффективности адаптивной программно-аппаратной системы распознавания, перевода и озвучивания речи для операторов технологических процессов

Автор: Золкин Александр Леонидович, Клюканов Алексей Васильевич
Рубрика: Информатика и вычислительная техника
Статья в выпуске: 4, 2023 года.
Бесплатный доступ
Целью данного исследования являются разработка и реализация адаптивной программноаппаратной системы распознавания, перевода и озвучивания речи, предназначенной для операторов технологических процессов. Система разрабатывается с целью улучшения эффективности и удобства работы операторов. Основной функциональностью системы является автоматическое распознавание речи операторов на различных языках с последующим переводом на выбранный язык и озвучиванием текстовых ответов. Это облегчит и ускорит коммуникацию операторов с системой, а также улучшит понимание информации. Рассмотрен процесс разработки методов обработки звука и анализа речи для точного распознавания и интерпретации вводимой операторами информации. Для этого применяются передовые алгоритмы машинного обучения, что делает систему более адаптивной и улучшает качество распознавания с течением времени. Важным аспектом исследования является внедрение предиктивной аналитики на основе тембральных признаков голоса. Это позволяет улучшить качество голосовой связи, а также осуществить контроль качества на линии связи для определения возможных помех и проблем. Для повышения безопасности системы и защиты от несанкционированного доступа представлено подробное использование хэш-стойкого алгоритма верификации пользователей на основе тембральных признаков голоса, что обеспечивает надежную идентификацию пользователей и защиту от подделки голоса. В ходе исследования проведены эксперименты и тестирование различных аспектов системы, что позволило оценить ее эффективность и точность. Результаты исследования подтверждают значительное улучшение взаимодействия операторов с системой, повышение качества распознавания и снижение ошибок в процессе перевода и озвучивания. Представленное исследование является значимым шагом в области разработки адаптивных систем распознавания и верификации голоса, демонстрирует потенциал таких систем для повышения производительности операторов технологических процессов и создания удобной и эффективной среды для их работы.
Адаптивная система, распознавание речи, перевод речи, озвучивание речи, операторы технологических процессов, предиктивная аналитика, обработка звука, машинное обучение, хэш-стойкий алгоритм, тембральные признаки голоса
Короткий адрес: https://sciup.org/148327419
IDR: 148327419 | УДК: 004.056 | DOI: 10.18137/RNU.V9187.23.04.P.96
Assessment of the effectiveness of an adaptive software- hardware system for speech recognition, translation and speech synthesis for operators of technological processes
The aim of the study is to develop and implement an adaptive software-hardware system for speech recognition, translation, and speech synthesis designed for operators of technological processes. The system is designed to improve the efficiency and convenience of operators’ work by enabling them to interact with the system using voice commands. The main functionality of the system is automatic speech recognition of operators in various languages, followed by translation into the selected language and voice synthesis of textual responses. This will facilitate and accelerate the communication between operators and the system, enhancing the overall understanding of information. The article includes a description of the process of developing methods for sound processing and speech analysis to ensure accurate recognition and interpretation of the input information from the operators. Advanced machine learning algorithms are applied to make the system more adaptive and continuously improve the recognition quality over time. A crucial aspect of this research is the integration of predictive analytics based on vocal timbre features. This enhances the quality of voice communication and enables quality control on the communication line to identify possible disturbances and problems. To enhance system security and protect against unauthorized access, the authors propose a detailed use of a hash-resistant algorithm for user verification based on vocal timbre features, which ensures reliable user identification and protects against voice impersonation. Throughout the research, experiments and testing on various aspects of the system have been conducted to evaluate its effectiveness and accuracy. The results confirm significant improvements in operator-system interaction, enhancement of recognition quality, and reduction in errors during translation and voice synthesis. In conclusion, this research is a significant advancement in the field of developing adaptive speech recognition and verification systems. It demonstrates the potential of such systems to enhance the productivity of operators in technological processes and create a convenient and efficient environment for their work.
Текст научной статьи Реализация оценки эффективности адаптивной программно-аппаратной системы распознавания, перевода и озвучивания речи для операторов технологических процессов
Современные технологические процессы становятся все более сложными и автоматизированными, что требует от операторов быть внимательными, профессиональными и быстрыми в принятии решений. Важной частью работы операторов является обработка речевой информации, включая команды, сообщения и инструкции. Однако перед ними стоит ряд проблем, связанных с пониманием и обработкой большого объема речевой информации, особенно в случаях, когда процессы происходят на разных языках и требуют верификации по голосовому признаку [1; 2].
В процессе работы операторы технологических процессов весьма часто сталкиваются с рядом сложных задач, основанных на языковых барьерах.
Первая проблема заключается в распознавании речи, особенно при использовании специфических терминов и в шумных условиях окружающей среды [3–5].
Вторая проблема возникает в случае, когда оператору необходимо работать с информацией на разных языках, и перевод требует значительных усилий и времени.
Третья проблема связана с озвучиванием информации для оператора, чтобы обеспечить ему удобство и сконцентрированность на основных задачах.
Целью данного исследования является разработка системы оценки эффективности адаптивной программно-аппаратной системы, которая предоставляет решение указанных проблем. Система должна быть способна распознавать речь операторов с высокой точностью, обеспечивать быстрый и точный перевод информации на различные языки и озвучивать результаты перевода с естественностью и понятностью [6].
Методы исследования
Предметом исследования является комплексная эффективность адаптивной программно-аппаратной системы распознавания, перевода и озвучивания речи для операторов технологических процессов, объектом исследования – модель адаптивной программно-аппаратной системы распознавания, перевода и озвучивания речи для операторов технологических процессов.
Субъектами исследования являются научные работники или специалисты, которые реализуют исследование, а также операторы технологических процессов, которые будут использовать систему и принимать участие в оценке ее эффективности.
Для создания математической модели определения степени эффективности адаптивной программно-аппаратной системы распознавания, перевода и озвучивания речи необходимо определить набор параметров, которые будут характеризовать эту эффективность. Затем требуется использовать эти параметры для разработки математических формул или алгоритмов, которые будут оценивать их влияние на общую эффективность системы.
Результаты
Приведем основные параметры, которые необходимо учесть при создании математической модели определения вероятности правильного распознавания вводимой речи оператора. Можно использовать стандартные метрики, такие как точность (accuracy) или процент ошибок (error rate).
Скорость распознавания позволяет измерить время, требуемое для распознавания речи. Быстрые ответы системы повышают эффективность взаимодействия с оператором.
Так как система будет поддерживает многие языки, то нужно определить качество перевода с одного языка на другой. Будем использовать метрики BLEU для оценки качества перевода.
Необходимо также оценить качество голосовой озвучки текста, чтобы операторы могли легко понимать получаемую информацию.
Следовательно, необходимо разработать параметры, которые оценивают способность системы адаптироваться к различным операторам и условиям работы.
Производительность системы позволяет оценить загрузку системы и ее производительность при работе с несколькими операторами одновременно.
Реализация оценки эффективности адаптивной программно-аппаратной системы ...
После определения параметров необходимо разработать математические уравнения, функции или алгоритмы, которые объединят эти параметры для определения общей степени эффективности системы. Таким образом, получим количественную оценку работы системы и возможность сравнивать ее производительность при различных условиях и настройках. Однако для построения конкретной математической модели необходимо провести более глубокий анализ требований и характеристик самой системы. Следует отметить, что определение математических уравнений для каждого из этих пунктов зависит от специфики самой системы, используемых данных и методов оценки. В реальных исследованиях необходимо проводить более подробный анализ и выбирать подходящие математические модели в зависимости от контекста задачи и доступных данных.
Для создания единой конструкции, которая объединяет все параметрические уравнения, представим эффективность системы (Efficiency) как комплексную функцию от всех параметров:
Efficiency = f(A, Speed, BLEU(L1, L2), Q, C, P). (1)
Здесь A представляет вероятность правильного распознавания речи, выраженную в долях (от 0 до 1); Speed – скорость распознавания, обратное значение времени; BLEU(L1, L2) характеризуют оценку качества перевода между языками L1 и L2; Q представляет качество озвучивания текста, выраженное в долях (от 0 до 1); C – параметр, определяющий степень адаптивности системы; P – признак, характеризующий производительность системы при работе с несколькими операторами одновременно.
Это комплексное уравнение описывает, как каждый из параметров влияет на общую эффективность адаптивной программно-аппаратной системы распознавания, перевода и озвучивания речи для операторов технологических процессов.
Для создания адаптивной системы распознавания, перевода и озвучивания речи на Python обычно используются библиотеки для обработки речи, машинного обучения и взаимодействия с голосовыми интерфейсами, что подразумевает использование оценки, обозначенной на Рисунке 1.
[Начхало]
|Ввод параметров]
А =
0.85
Speec
= 0.5
[ Вычисление весов ы х коэффициентов ]
BLEU(L1, .2) = 0.78
[Преобразова ние значений]
Q =
С =
0.92
0.6
[Вычисление эффективности]
Efficient/ = 1,61
[Вывод результатов]
[Конец,]
Рисунок 1. Граф-схема оценки эффективности адаптивной программно-аппаратной системы распознавания, перевода и озвучивания речи Источник: схема составлена авторами.
В частности, один из подходов к реализации может включать использование библиотеки Speech Recognition для распознавания речи, Google Cloud Translation API – для перевода, gTTS – для озвучивания текста.
Для внедрения модели обучения в адаптивную систему распознавания, перевода и озвучивания речи можно использовать предобученную модель для распознавания речи и модель машинного перевода.
Для простоты воспользуемся библиотеками speech_recognition и googletrans для распознавания речи и перевода соответственно. Необходимо обратить внимание на то, что эти модели могут иметь ограничения, и для более точных и профессиональных результатов можно использовать другие библиотеки и API, такие как Speech-to-Text.
import speech_recognition as sr from googletrans import Translator from gtts import gTTS import os
-
# Функция для распознавания речи с использованием модели Speech Recognition
def recognize_speech():
recognizer = sr.Recognizer()
with sr.Microphone() as source:
print(«Говорите...»)
try:
text = recognizer.recognize_google(audio, language=’ru-RU’)
return text except sr.UnknownValueError:
print(“Извините, не удалось распознать речь.”)
return None
-
# Функция для перевода текста с использованием модели Googletrans
def translate_text(text, target_language):
translator = Translator()
translation = translator.translate(text, dest=target_language)
-
# Функция для озвучивания текста на английском языке
def text_to_speech(text, language):
tts = gTTS(text=text, lang=language)
Реализация оценки эффективности адаптивной программно-аппаратной системы ...
-
# Основной код
if __name__ == «__main__»:
-
# Распознавание речи на русском языке
recognized_text = recognize_speech()
if recognized_text:
print(«Распознано: «, recognized_text)
-
# Перевод на английский
target_language = ‘en’ translated_text = translate_text(recognized_text, target_language)
print(“Перевод: “, translated_text)
-
# Озвучивание текста на английском text_to_speech(translated_text, target_language)
Для эффективного взаимодействия и обмена данными между компонентами адаптивной системы, включая распознавание речи, перевод и озвучивание, используются CAN-подключения (Controller Area Network). CAN-подключения обеспечивают надежную передачу данных в реальном времени и широко применяются в автомобильной промышленности, где требуется высокая производительность и надежность.
Добавим в разрабатываемую систему такое подключение для передачи данных между компонентами:
python
Copy code import speech_recognition as sr from googletrans import Translator from gtts import gTTS import os
-
# Функция для распознавания речи с использованием CAN-подключения
def recognize_speech():
-
# Ваш код для получения данных с использованием CAN-подключения
-
# recognized_text = can_receive_data()
recognized_text = “Привет, как дела?”
return recognized_text
-
# Функция для перевода текста с использованием модели Googletrans
def translate_text(text, target_language):
translator = Translator()
translation = translator.translate(text, dest=target_language)
-
# Функция для озвучивания текста на английском языке с использованием CAN-подключения
def text_to_speech(text, language):
-
# Ваш код для отправки данных с использованием CAN-подключения
-
# can_send_data(text)
tts = gTTS(text=text, lang=language)
-
# Основной код
if __name__ == «__main__»:
-
# Распознавание речи с использованием CAN-подключения
recognized_text = recognize_speech()
if recognized_text:
print(“Распознано: “, recognized_text)
-
# Перевод на английский
target_language = ‘en’ translated_text = translate_text(recognized_text, target_language)
print(“Перевод: “, translated_text)
-
# Озвучивание текста на английском с использованием CAN-подключения text_to_speech(translated_text, target_language)
В примере выше мы использовали мок-функции can_receive_data() и can_send_data() для получения распознанного текста через CAN-подключение и отправки озвученного текста на английском языке с использованием CAN-подключения соответственно.
Также разработаем простой метод предиктивной аналитики для повышения качества голосовой связи. Для этого можно использовать простую линейную регрессию для предсказания уровня качества связи на основе собранных данных. Наш скрипт будет предсказывать уровень качества связи на основе задержки и уровня шума.
-
# Собранные данные (задержка и уровень шума)
delay = [20, 30, 40, 50, 60] # Задержка в миллисекундах noise_level = [0.5, 0.8, 1.2, 1.5, 1.9] # Уровень шума в децибелах
-
# Уровень качества связи (фактические данные, которые нужно предсказать)
call_quality = [4.5, 4.2, 3.9, 3.7, 3.4]
Реализация оценки эффективности адаптивной программно-аппаратной системы ...
-
# Преобразование данных в массивы numpy и изменение их формы
-
# Создание модели линейной регрессии
model = LinearRegression()
-
# Предсказание уровня шума для новых значений задержки new_delay = [25, 35, 45, 55, 65]
-
# Вывод предсказанных значений уровня шума print(“Предсказанный уровень шума:”, predicted_noise)
-
# Визуализация результатов
plt.scatter(delay, noise_level, label=”Фактический уровень шума”)
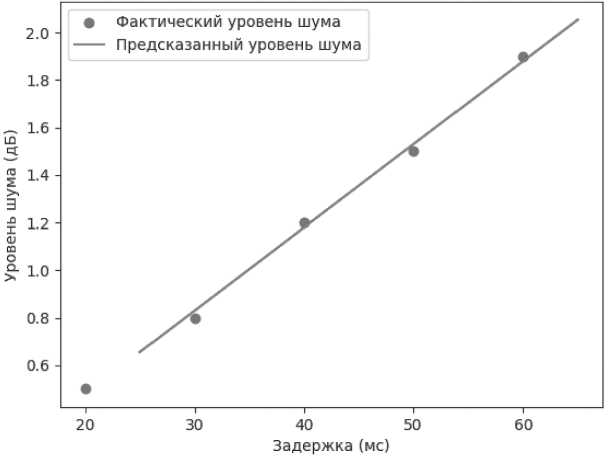
Рисунок 2. Контроль уровня шума при распознавании речи (контроля качества соединения) Источник: составлено авторами.
Для повышения оценки эффективности и безопасности в голосовой системе можно внедрить хэш-стойкий алгоритм для верификации пользователя на основе тембральных признаков его голоса. В данном случае будем использовать хэш-функцию SHA-256 для создания хэша на основе тембральных признаков. Необходимо собрать и представить тембральные признаки голоса для каждого пользователя в системе. Эти признаки могут включать такие характеристики, как частоты формант, скорость речи, громкость и другие акустические параметры. На основе собранных признаков для каждого пользователя можно использовать хэш-функцию SHA-256 для создания уникального хэша для каждого пользователя. Этот хэш будет представлять уникальный идентификатор голоса пользователя. При регистрации новых пользователей в системе их тембральные признаки будут собраны, и для каждого пользователя будет создан уникальный хэш на основе этих признаков. Этот хэш будет связан с учетной записью пользователя в системе.
При прохождении верификации система снова соберет тембральные признаки голоса пользователя. Затем на основе этих признаков система создаст новый хэш и сравнит его с заранее сохраненным хэшем в учетной записи пользователя. Если хэши совпадают, то пользователь будет верифицирован и получит доступ к системе.
Очень важно обеспечить безопасное хранение хэшей тембральных признаков пользователей. Хэши следует хранить в зашифрованном виде в безопасной базе данных или файле, чтобы предотвратить несанкционированный доступ к ним.
Для создания модели сбора тембральных признаков голоса, а также процедуры регистрации и верификации пользователя разработан скрипт на языке Python. Будем использовать библиотеку hashlib для создания хэшей.
import hashlib class VoiceAuthenticationSystem:
def __init__(self):
-
# Словарь для хранения хэшей пользователей self.user_hashes = {}
def collect_voice_features(self):
-
# Здесь можно реализовать сбор тембральных признаков голоса
-
# Пример сгенерированных признаков:
voice_features = [120, 2.5, 0.8, 3000]
return voice_features def create_voice_hash(self, voice_features):
-
# Преобразуем тембральные признаки в строку features_str = ‘ ‘.join(str(f) for f in voice_features)
-
# Создаем хэш с помощью SHA-256
voice_hash = hash_object.hexdigest()
return voice_hash
Реализация оценки эффективности адаптивной программно-аппаратной системы ...
def register_user(self, username):
-
# Сбор тембральных признаков голоса voice_features = self.collect_voice_features()
-
# Создание хэша на основе тембральных признаков voice_hash = self.create_voice_hash(voice_features)
-
# Сохранение хэша в словаре пользователей
self.user_hashes[username] = voice_hash print(f”Пользователь ‘{username}’ успешно зарегистрирован.”)
def verify_user(self, username):
-
# Сбор тембральных признаков голоса voice_features = self.collect_voice_features()
-
# Создание хэша на основе тембральных признаков voice_hash = self.create_voice_hash(voice_features)
-
# Проверка соответствия хэша зарегистрированному пользователю
if username in self.user_hashes and voice_hash == self.user_hashes[username]: print(f”Пользователь ‘{username}’ верифицирован.”)
else:
print(“Верификация не пройдена. Пользователь не найден или голос не совпадает.”)
-
# Пример использования
if __name__ == “__main__”:
voice_auth_system = VoiceAuthenticationSystem()
voice_auth_system.register_user(«alice»)
voice_auth_system.verify_user(«alice»)
Таким образом, реализована модель для сбора тембральных признаков голоса, создания хэша на их основе и процедуры регистрации и верификации пользователей (Рисунок 3).
Ниже представлена таблица с объектами, субъектами и признаками всей системы распознавания и верификации голоса.
Таблица
Схема объектов, субъектов и признаков в системе распознавания и верификации голоса
|
Объекты |
Субъекты |
Признаки |
|
Голосовые данные |
Пользователи системы |
Частоты форматов |
|
Задержка в голосе |
Операторы |
Скорость речи |
|
Уровень шума |
Система распознавания |
Громкость |
|
Идентификаторы пользователей |
Длительность речи |
|
|
Энергия звука |
||
|
Амплитуда голоса |
Рисунок 3. Граф-схема аутентификации голоса с использованием хэш-стойкого алгоритма Источник: составлен авторами.
Заключение и выводы
Таким образом, адаптивная программно-аппаратная система для распознавания, перевода и озвучивания речи является критически важным инструментом для повышения эффективности и производительности операторов технологических процессов. Такая система позволит значительно улучшить коммуникацию и взаимодействие операторов с автоматизированными системами, сократить время на обработку информации принятие решений, а также избежать возможных ошибок и недопониманий [7].
Благодаря этой системе операторы смогут более эффективно управлять сложными технологическими процессами, что, в свою очередь, приведет к повышению качества производства и снижению вероятности возникновения аварийных ситуаций.
Этот проект является только примером комплексной системы; реальная реализация может варьироваться в зависимости от требований и целей конкретной системы распознавания и верификации голоса для операторов технологических процессов. Обеспечение безопасности, точности и эффективности является критически важным аспектом при разработке и реализации подобных систем.
Реализация адаптивной программно-аппаратной системы для распознавания, перевода и озвучивания речи является актуальной и важной задачей, которая значительно улучшит условия работы операторов технологических процессов и повысит общую эффективность предприятия [8].
Список литературы Реализация оценки эффективности адаптивной программно-аппаратной системы распознавания, перевода и озвучивания речи для операторов технологических процессов
- Dong Yu, Lee Deng. Automatic speech recognition. A Deep Learning Approach. London: Springer, 2015. 321 p. DOI: 10.1007/978-1-4471-5779-3
- Ryzhova K., Yumashev A.V., Klimova M., Osin R., Gracheva E., Dymchishina A. Artificial intelligence in the diagnosis of diseases of various origins // Journal of Complementary Medicine Research. 2023. Vol. 14. No. 2. Pp. 199-202. DOI: 10.5455/jcmr.2023.14.02.31
- Benzeghiba M., Mori R., Deroo O. et al. Automatic speech recognition and speech variability: A review // Speech communication. 2007. Vol. 49. No. 10-11. Pp. 763-786. Реализация оценки эффективности адаптивной программно-аппаратной системы.. DOI: 10.1016/j.specom.2007.02.006
- Чирков М.С., Лачинина Т.А., Чистяков М.С. Знания и информация как синергия платформенного подхода цифровизации глобального развития // Свободная мысль. 2020. № 5 (1683). С. 37-44. DOI: 10.24411/0869-4435-2020-00003
- Zolkin A.L., Aygumov T.G., Losev A.N., Alexandrova E.V. Development of a fuzzy authentication system for the automated line devices of a distributed internet of things using a hash-resistant algorithm // AIP Conference Proceedings. Proceedings of the IV International Scientific Conference on Advanced Technologies in Aerospace, Mechanical and Automation Engineering: (MIST: Aerospace-IV 2021). Krasnoyarsk, December 10-11, 2021. Vol. 2700. Krasnoyarsk: American Institute of Physics Inc., 2023. P. 040006. DOI: 10.1063/5.0124871 EDN: PPFYBU
- Zue V.W. The use of speech knowledge in automatic speech recognition // Proceedings of the IEEE. 1985. Vol. 73. No. 11. P. 1602-1615. DOI: 10.1109/PROC.1985.13342
- Bhardwaj V., Othman M., Kukreja V. et al. Automatic speech recognition (ASR) systems for children: A systematic literature review // Applied Sciences. 2022. Vol. 12. No. 9. P. 4419. DOI: 10.3390/app12094419
- Reitmaier T., Wallington E., Raju D. et al. Opportunities and challenges of automatic speech recognition systems for low-resource language speakers // Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. CHI '22, April 29-May 5, 2022, New Orleans, LA, USA P. 1-17. DOI: 10.1145/3491102.3517639
