Resource Allocation Policies for Fault Detection and Removal Process

Author: Md. Nasar, Prashant Johri, Udayan Chanda
Journal: International Journal of Modern Education and Computer Science (IJMECS) @ijmecs
Article in issue: 11 vol.6, 2014.
Free access
In software testing, fault detection and removal process is one of the key elements for quality assurance of the software. In the last three decades, several software reliability growth models were developed for detection and correction of faults. These models were developed under strictly static assumptions. The main goal of this article is to investigate an optimal resource allocation plan for fault detection and removal process of software to minimize cost during testing and operational phase under dynamic condition. For this we develop a mathematical model for fault detection and removal process and Pontryagain's Maximum principle is applied for solving the model. Genetic algorithm is used to find the optimal allocation of fault detection and removal process. Numerical example is also solved for resource allocation for fault detection and remoal process.
SRGM, Testing Effort Allocation, Correction-Removal Process, Optimal Control Theory, Genetic Algorithm
Short address: https://sciup.org/15014706
IDR: 15014706
Text of the scientific article Resource Allocation Policies for Fault Detection and Removal Process
Published Online November 2014 in MECS DOI: 10.5815/ijmecs.2014.11.07
For the last few decades, it has been observed that computer systems have been widely used for problem solving, and there has been phenomenal increase in complexity of a system. A fault in the software system may produce huge loss in terms of money as well as time. There are numerous examples of failure of computer control system resulting in huge financial and other losses. Hence, it is necessary for an organization to invest resources in developing a software product that should be error free, reliable and also suitable for market conditions.
As industries are depending more and more on computer systems for day to day business, a reliable software system is needed by businesses to be efficient. Software testing comes under the software development life-cycle, and both are multistage processes, where each stage possesses a pre-specified activity or goal to deliver high quality products to a client. Software testing plays a very important role in software quality. Software testing interacts with every phase of software development life cycle, and the software reliability valuation is an important component to predict and evaluate the reliability of a software system. The model applicable to calculate the software reliability is called software reliability growth model (SRGM). The main goal of SRGM is to establish the relationship between fault observation and fault removal, and to calculate the reliability of the software. These reliability models have also been used for resource allocations.
Resources, such as manpower, CPU time and some hardware, are generally used during software testing process. Fault detection and correction process completely depends upon the nature of fault and volume of resources consumed for correction. Numerous SRGMs have been proposed to minimize the amount of testing effort consumed during testing but mostly under static condition. [1] first considered a simple software reliability model depending on the testing effort and formulated a testing resource allocation problem. [2] - [6] discussed the time-dependent behavior of testing efforts in their work. Generally, exponential curve is used to describe the performance of testing resources whenever spent equally; otherwise, Rayleigh curve is used. Weibull and Logistic type functions have also been used to describe testing efforts. [7] discussed optimization problem for testing resource allocations and for the software systems having modular structure and assumed that testing effort allocation depends upon the size and severity of the fault. Numerous SRGMs have been proposed in the last four decades in that mostly fault detection models were based on the assumption that detection and correction of faults is done concurrently. But, in reality there is always a time gap [8] - [12].
Generally, when a fault is detected, testing team reports it for correction, and then the development team rectifies the faults. Hence, evidently, there must be a time lag between fault detection and correction processes. [13] Determined the resource allocation problem by minimizing the mean number of remaining faults in the software modules with a budget constraint and a reliability aspiration. [14] Studied the optimal amount of resources desired for software module testing using the hyper-geometric software reliability growth model. [15]
Discussed the effort allocation in dynamic environment. The author used differential evolution for dynamic allocation of testing resources. Differential evolution is an improved version of genetic algorithm for faster optimization. The author also discussed a numerical example for allocating the testing resources.
-
[16] Discussed an optimal resource allocation problem for modular software systems throughout the testing phase. The main aim was to minimize the software development cost when the number of remaining faults is to be minimized, and a desired reliability objective is given. The authors analyzed the sensitivity of parameters of proposed software reliability growth models. In addition, the authors also present the impact on the resource allocation problem if some parameters are either overestimated or underestimated. The authors have evaluated the optimal resource allocation problems for various conditions by examining the behavior of the parameters with the most significant influence. For this purpose, a numerical example is also solved.
-
[17] Investigated dynamic programming approach for testing resource allocation problem when the software is developed in modules. For this, two optimization models are proposed for optimal allocation of testing resources among the modules of software. In the first model, authors maximize the total fault removal, subject to cost constraint. In the other model, other constraints representing aspiration levels for fault removals for each module of the software are added. The authors solved these models using dynamic programming technique. A dynamic programming approach for finding the optimal solution has also been proposed. The methods have been illustrated through numerical examples.
-
[18] Studied the association between the number of faults deleted with respect to testing effort and/or time. The authors assumed that throughout the testing stage of a software development life cycle (SDLC), faults are removed in two stages: first a failure occurs and then the fault causing that failure is corrected; hence the testing effort will be spent on two distinct processes; failure detection and failure alteration. In their paper, the authors developed a software reliability growth model incorporating time delay not only between the two phases but also through the segregation of resources between them and proposed two alternate methods for controlling the testing effort for achieving the pre-specified reliability level or error detection level.
-
[19] Discussed a cost model for software, that is used to formulate whole software project cost and discussed the optimal release policy based on cost and reliability criteria.
-
[20] considered the cost factor in testing-resource allocation problems, but they only put the cost factor into the constraints, which means it is feasible if the total cost is less than budget. In fact, it is a profit for a company if the cost can be less than the budget provided that the customers’ requirements are still satisfied. Thus he involved cost factor in the objective function together with reliability, which means that he is having multiple
objectives in term of both maximizing system reliability and minimizing testing cost.
-
[21] investigated an optimal resource allocation plan to minimize the cost of software during the testing and operational phase under dynamic condition. An elaborate optimization policy based on the optimal control theory is used. The authors used learning curve phenomenon under dynamic environment for optimal allocation of testing resources. During the analysis, Author observed that due to the experience curve phenomenon, the effort required to fix an error keeps on decreasing with time. At the same time, testing effort keeps on increasing as in the later stages of a planning period it becomes hard to detect faults. For this purpose one numerical example is also illustrated. The model is based on the assumption that at any point of time the total resources allocated for debugging and testing is fixed.
The above literature review shows that most of the well-known SRGMs are built on static conditions but in real time, it is not true. In this paper, we have proposed mathematical optimization model that helps to assign allocation of resources for fault detection and fault correction under dynamic environment.
The paper is subdivided into the following sections. Section two and three describe the model for fault detection and correction processes, and the cost optimization modeling. In section four, we discuss the solution approach. Section five discusses the basic parameter for genetic algorithm. A numerical problem for fault detection and correction process Vs time using genetic algorithm is given in section six. Finally, in section seven, we conclude our paper with a discussion on results and findings.
Notations Used
c 3
Cost per unit at time ‘ t ’ for cumulative fault corrected is f r ( t ) debugging efforts w 2( t )
Cost of testing per unit effort at time ‘t’.
-
II. Model Development
Modeling Fault Detection and Correction Processes:
For perfect removal of faults, the predictable number of fault corrected is the same as predictable number of faults identified. However, in reality if a fault is identified, it is not necessary to correct the fault instantly. Hence, after identifying the fault, the debugging personnel ask the programmer to correct the fault. Thus, there must be a time gap between identification and removal processes. In general, the expected number of faults detected at time T is more than faults corrected at time T. Hence, the fault detection and removal processes are done in two stages. To begin with, let’s assume ‘a’ is the total fault content in the software. Therefore, it is necessary to assume the following equation of fault identification and removal process;
x ( t ) = df d h”) = b w 1 ( t )( a - fd ( t ))
and
У ( t ) = dfrdt^ = b2 w2 (t)(fd (t) - fr (t)) where fd (0) = 0, fr (0) = 0
-
III. Cost Optimization Modelling
Now assume the software firm wants to minimize the total expenditure over the finite planning horizon. Therefore, mathematically the model can be given as;
-
IV. Solution Procedure
To solve the problem for equation (2), Pontryagain’s Maximum principle is applied. The Hamiltonian function is as follows [22]:
H (f d ( t ),f r ( t ), Z ( t ), w 1 ( t ), w 2 ( t ), w 3 ( t ), t ) =
-[ C i ( t ) x ( t ) + C 2 ( t ) y ( t ) + C 3 w i ( t ) ]
+ 2 ( t ) x ( t ) + ^ ( t ) y ( t ) (3)
2 ( t ) and ^ ( t ) are the adjoint variables (shadow cost of and respectively), which satisfies the following differential equation.
d 2 ( t ) = *X = dt
d H d f fd
And;
d d H
— ^ ( t ) =-- dt d f r
Terminal condition for the differential equation (4) and (5) are given by ^( T ) = 0 and ^.T ) = 0 respectively.
The adjoining variable ^ ( t ) represents per unit change in the objective function for a small change in f ( t ) i.e. ^ ( t ) can be interpreted as marginal value of faults detected at time ‘ t ’. Similarly, ^ ( t ) can be interpreted as marginal value of fault removed at time ‘t’. Thus, the Hamiltonian is the sum of current cost ( C ^ + C2y ) and the future cost ( Z x + Д У ) . In short, H represents the instantaneous total cost of the firm at time’ t ’ .
The following are the necessary conditions hold for an optimal solution:
T min J[ c1 ( t ) x ( t ) + c 2( t ) У ( t ) + c3 w1( t )]dt 0
subject to x (t) = ddy) = bl W1( t)(a - fd(t))
dt
У (t ) = ^Д = b2 w2(t)(fd (t) - fr (t)) dt where fd (0)=0 ,fr (0 ) = 0, c1(t) = cl (fd (t ), w3 (t )) ,c2(t)
= c2 (fr (t), w2 (t )) and w1 (t) + w2 (t) + w3 (t) = w
( w i ( t ) ; w 2 ( t ) ; w ( t ) ) ^ 0
Where;
H w = 0 ^- C 1 M ( t ) x ( t ) - ( C 1 ( t )
- Z ( t )) x M( t ) - c з = 0 (6)
H w 2 = 0 ^
- C 1 w 2 ( t ) x ( t ) - c 2 w 2 ( t ) У ( t ) - ( c 2 ( t ) (7)
-M ( t )) y w 2 ( t ) = 0
C 1 w ! ( t ) =
C 1 w 2 ( t ) =
a c 1( t ) 5 w 1( t )
d c 1 ( t ) 5 w 2 ( t )
c 2 w 2 ( t ) =
5 c 2 ( t ) 5 w 2( t )
x „ 1 ( t ) =
d x ( t ) d „ 1 ( t )
y „ 2 ( t ) =
d y ( t ) a „ 2 ( t )
• •
„ 1 H „ 2 „ + „ 2 H „ 2 „ 2 + x ( t ) H „ 2 fd + У ( t ) H „ 2 fr
•
= — М У „ 2
Where;
The other optimality maximization are;
conditions for Hamiltonian
H„„ < 0
and Hw w Hw w
—
H„„ 2 > 0
On solving equations (6) and (7), we get;
w= ( c l ( t ) — ж ( t )) b l ( a — f d ( t )) + c 3
1 c l 4( t ) b i( a — fd ( t )
And;
H = d2 H ( t )
„„ d 2 „ 1( t )
d2 H (t)
„ „ 2 d „ 1 ( t ) d „ 2 ( t )
a2 h (t)
„ 2 „ 2 d 2 „ 2 ( t )
H = d2 H ( t )
„ifr dWi( t )dfr (t)
h„. = _!LJHt)_, for i =1,2
i/d a„i(t)afd(t)
„ 2 ( t ) = —
( c 2 ( t) — At )) b 2 (f d ( t) — fr ( t )) + c l „ 2 ( t)x ( t)
C 2 „ 2 ( t ) b 2 (f d ( t ) — f r ( t ))
Using the assumption that the total resource is fixed i.e; „ 1 ( t ) + „ 2 ( t ) + „ 3 ( t ) = „ . Thus,
To solve the above optimization problem, we used Genetic Algorithm (GA). Genetic Algorithm is a computerized search and heuristic optimization method for solving difficult type of problem which cannot be solved easily by general methods [23], [24] and [25].
* **
„3 = „ + „1 + „2
Now, upon integrating equation (4) with the transversality condition, we have the future cost of detecting one more fault from the software;
T
^ ( t ) = — j t
^ ^ ^ ( t ) x ( t ) + ( C 1 ( t ) — ж t ) ) l x.
4 f d 1 d
+ ( c 2 ( t ) — ^ ( t ) ) |^ l d
Similarly, integrating equation (5) with the transversality condition, we have the future cost of removing one more fault from the software;
T
^ t 1 =- 1
5c^
- y- У ( t ) + 8 fr
' c 2( ' ) ) lL I — » ( t ) ) l fr
dt
Now taking time derivative of equation (6), we have;
„ 1 H „ 1 „ 1 + „ 2 H „ 1 „ 2 + x ( t ) H „ 1 fd
•
+ y ( t ) H „ 1 fr =— Ж х „1
Time derivative of equation (7) implies;
V. Genetic Algorithm
Genetic algorithm is an optimization technique that mimics the process of natural selection. This heuristic approach is regularly used to generate solutions for optimization problems. Genetic algorithm belongs to evolutionary class of algorithm which is inspired by natural evolution, such as selection, crossover, mutation, and inheritance. Genetic algorithm is successfully applied in many fields such as bioinformatics, economics, physics, chemistry, computer science, mathematics and many others.
To solve the above problem using genetic algorithm, following steps will follow.
Chromosome Representation: Genetic algorithm starts with some initial population represented as chromosome. A chromosome consists of genes and each gene represents a specific solution for the problem.
Initial population: We will generate an initial population for total number of faults ‘a’ content in the software. It will take minimum and maximum values and it will generate initial population form this limit.
Fitness of a chromosome: Fitness of a chromosome quantifies the optimality of a solution (chromosome) so that particular solution may be ranked against all the other solutions.
Selection: Selection is the process of choosing two chromosomes from the whole population of the chromosomes. The chromosome with highest fitness value has high probability of selection. There are many methods to choose the best chromosome like tournament
selection, rank selection, roulette wheel selection, Boltzman selection, steady state selection and some others.
Crossover: It is the process in which two chromosomes (strings) combine their genetic material (bits) to produce a new offspring which possesses both their characteristics. Two strings are randomly picked from the mating pool to cross over.
Mutation: By mutation individuals are randomly altered. These variations (mutation steps) are commonly very small. They will be applied to the variables of the individuals with a low probability (mutation rate or mutation probability). Normally, offspring will be mutated after being created by recombination.
The steps, selection, crossover and mutation, are then repeated till the stopping criteria are reached.
-
VI. Numerical Solution
Using GA approach, in this section, we discuss the numerical solution of the problem as discussed in section 3 in order to count the number of errors detected and corrected at time ‘t’. To solve this problem, we have used genetic algorithm and implemented through MATLAB 7.4.0 and C++. The parameters used to solve this problem are:
Total number of population Size: 200
Total number of generation: 100
Method of selection: Tournament selection
Rate of crossover: 0.8
Rate of mutation: 0.1
And the base values are as follows:
a = 100
W = 0.40 д ( 0 ) = 100 c 0 = 1000
b 1 = 0.3 w2 = 0.42 f d, ( 0 ) = 0 b 0 = 1000
b 2 = 0.3
w = 1 2 ( 0 ) = 100
fr ( 0 ) = 0 c 3 = 500
The expected number of fault detected and corrected is as follows:
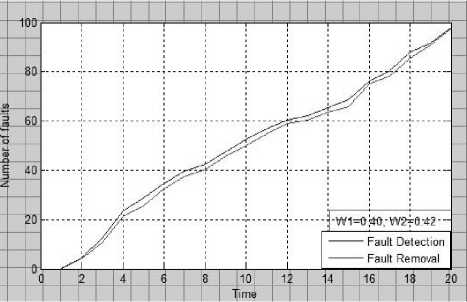
Fig: 1a. Number of fault Vs time.
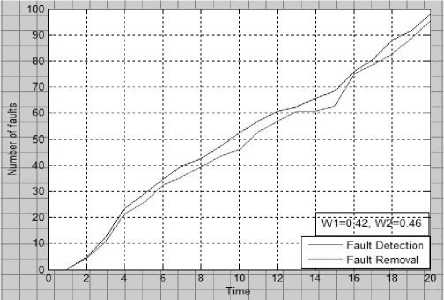
Fig: 1b. Number of fault Vs time.
Above fig. shows the fault detection and correction process Vs time. In first figure we use W1= 0.40 and W2=0.42, in second figure we use W1=0.42 and W2=0.46.
-
VII. Conclusions
In this paper, we propose an alternative foundation for optimal time allocation of fault detection and removal processes using genetic algorithm. We have considered fault detection and removal processes in two stages. During this study we have allocated fault detection and removal processes in dynamic environment. We describe a method to allocate time based on number of faults detected and corrected. This means that the tester and developer can dedicate their time and resources to finish off their testing and debugging tasks for well controlled expenditure. Simulation is done using genetic algorithm, MATLAB and C++ for the same.
References Resource Allocation Policies for Fault Detection and Removal Process
- Ohtera, H. and Yamada, S.: Optimal allocation and control problems for software testing-resources. IEEE Transactions on Reliability, R-39 (2), 171-176 (1990).
- Putnam, L (1978), 'A general empirical solution to the macro software sizing and estimating problem', IEEE Transactions on Software Engineering, SE-4, 345-361.
- Yamada, S., J. Hishitani and S. Osaki (1993), 'Software Reliability Growth Model with Weibull testing effort: A model and application', IEEE Trans. On Reliability, R-42, 100-105.
- Basili, V.R. and M.V. Zelkowitz (1979), 'Analyzing medium scale software development', Proceedings of the 3rd International Conference on Software Engineering, 116-123.
- Kapur, P.K. and Garg, R.B. (1990), 'Cost Reliability optimum release policy for a software system with testing effort', OPSEARCH, 27, 109-116.
- Huang, C-Y, S-Y. Kuo and J.Y. Chen (1997), 'Analysis of a software reliability growth model with logistic testing effort function', Proceeding of 8th International Symposium on software reliability engineering, 378- 388.
- Kapur, P.K., Bardhan A.K.and Yadavalli V.S.S. (2007), 'On allocation of resources during testing phase of a modular software', International Journal of Systems Science, 38 (6), 493 - 499.
- Ohba, M. (1984),'Software reliability analysis models', IBM Journal of research and Development 28, 428-443.
- Schneidewind, N.F. (1975), 'Analysis of error processes in computer software', Sigplan Notices 10, 337-346.
- Xie, M. and Zhao, M. (1992), ' The Schneidewind software reliability model revisited.' Proceedings of the 3rd International Symposium on Software Reliability Engineering, 5, 184-192.
- Schneidewind, N.F. (1975), 'Analysis of error processes in computer software', Sigplan Notices 10, 337-346.
- Gokhale, S.S., Wong, W.E., Trivedi, K.S. and Horgan, J.R.,(1998), 'An analytic approach to architecture-based software reliability prediction' in Proceedings of the International Symposium on Performance and Dependability, September, pp. 13-22.
- Yamada S. Ichitmori T. Nishiwaki M., "Optimal allocation policies for testing-resource based on a software reliability growth model", Mathematical and Computer Modelling, 1995, 22(10-12), 295-301.
- Huo R.H., Kuo S.K., Chang Y.P., "Needed resources for software module test, using the hyper-geometric software reliability growth model", IEEE Trans. on Reliability, 1996, 45(4), 541-549.
- Md. Nasar, Prashant Johri and Udayan Chanda, "A Differential Evolution Approach for Software Testing Effort Allocation," Journal of Industrial and Intelligent Information, Vol. 1, No. 2, pp. 111-115, June 2013.
- C. Y. Huang, J. H. Lo, S. Y. Kuo and M. R, "Optimal Allocation of Testing-Resource Considering Cost, Reliability, and Testing-Effort," Dependable Computing, 2004. Proceedings. 10th IEEE Paci?c Rim International Symposium on 3-5 March 2004, pp. 103-112.
- Dohi, T., Nishio, Y., and Osaki, S. (1999), 'Optimal Software Release Scheduling Based on Artificial Neural Networks', Annals of Software Engineering, 8, 167-185.
- P. K. Kapur and A. K. Bardhan, "Testing effort control through software reliability growth modelling", International Journal of Modelling and Simulation, vol. 22, pp. 90–96.2002.
- C.-Y. Huang, (2005), "Cost-reliability-optimal release policy for software reliability models incorporating improvements in testing efficiency," Journal of Systems and Software, vol. 77, pp. 139–155.
- Coit, D.W., Smith, A.E., 1996. Reliability optimization of series–parallel systems using a genetic algorithm. IEEE Trans. Reliab. 45 (2), 254–266.
- P.K. Kapur, Hoang Pham, Udayan Chanda & Vijay Kumar (2012): Optimal allocation of testing effort during testing and debugging phases: a control theoretic approach, International Journal of Systems Science, 2012, 1–12, iFirst, Taylor & Francis Publication.
- Sethi, S.P., and Thompson, G.L. (2005), Optimal Control Theory - Applications to Management Science and Economics (2nd ed.), New York: Springer.
- Goldberg, D. E., (1989), Genetic Algorithms: in Search Optimization and Machines Learning (New York: Addison-Wesley).
- David, L. Handbook of Genetic Algorithms. New York : Van Nostrand Reinhold. (1991).
- Deb K.(1995)Optimization for Engineering Design-Algorithms and Examples. Prentice Hall of India, New Delhi.
