Robust Assistive Reading Framework for Visually Challenged

Author: Avinash Verma, Deepak Kumar Singh
Journal: International Journal of Image, Graphics and Signal Processing(IJIGSP) @ijigsp
Article in issue: 10 vol.9, 2017.
Free access
The Main objective of this assistive framework is to communicate the textual Information in the image captured by the Visually Challenged person as Speech, So that the Visually Challenged person can acquire knowledge about the surrounding. This framework can help Visually Challenged person to read books, magazine, warnings, instructions and various displays as well by taking their image along with the surrounding. Then the Optical Character Recognition (OCR) extracts and recognizes the text in the image and generates the text file. This text file is further converted to Speech with the help of Text to Speech (TTS) Synthesis. The inherent problem with the previous approach was if the acquired image is affected with the issues of different lighting conditions, noise and issue of Skew and Blur, as the image is captured by Visually Challenged person. Then the overall accuracy of the system was at stake due to inefficient OCR leads to improper Speech output of TTS Synthesis. In this paper we have introduced two more processes that are deblurring using Blind Deconvolution method and Pre-processing operation to remove the effect of noise and blur. Thus it prepares the image for efficient result of the framework for Visually Challenged. The proposed approach is implemented in Matlab with the image captured manually and taken from the internet and the result along with the OCR text file and corresponding output Speech shows that our framework is better than the previous framework.
Assistive framework, Visually Challenged, Optical Character Recognition, Text to Speech and deblurring
Short address: https://sciup.org/15014235
IDR: 15014235
Text of the scientific article Robust Assistive Reading Framework for Visually Challenged
A lot of text information can be extracted from the images of the Surrounding Environment having text. The Surrounding having text information are name plates having the name and address of the individuals outside their residences, Boards containing the name of street, Area and distance, Various sign board and warning boards and the diversion boards are embedded with text, we also see various displays at airports, railways and shopping malls and most of the text is found in the magazines, newspaper and books. So in our day to day life we are surrounded by text which we see from our eye and then we acquire the knowledge based on this textual information. For instance if we are searching for an address and we find a name plate of the same address outside a residence then we are sure that we have found the correct address. Hence textual information plays a vital role in our life. On the other hand if we think of a person which is Visually Challenged he cannot acquire the knowledge of the surrounding whether it be a warning sign, name of street and various types of displays because he cannot see these things. With the advancement of the Information Technology we have thought of the solution to this problem [1] can be with the help of Image Processing and Signal Processing using Optical Character Recognitions and Text to Speech conversion.
-
A. Input Capturing by Visually Challenged
Image of the text can be taken either with the help of a scanner or with the help of a portable camera or smart phone camera. In today’s era with the advent of technology we have high resolution portable camera with many features such as autofocus, wide angle and high picture clarity it is easy to capture text with clarity. If the text in the captured image is clear then its segmentation and recognition [2] will be efficient and overall accuracy of the system will be high. But for a Visually Challenged person to capture the image with the help of a portable camera and with clarity will be a herculean task. We have assumed that the image captured by the Visually Challenged will be affected with the issues of Blur [2] and skew [3]. Problem associated with the Scanner is that for Visually Challenged person, it is difficult to place a text document in a proper way as the document need to be placed in the scanner in proper orientation, for the scanner to scan efficiently. A lot of research is done on the image acquired by portable camera for efficient optical character recognition [4]. But the image acquired using a portable camera can be affected with problem of
Blur, Skew and variation in the lighting conditions. In this paper we are dealing with the problem of blurred textual image that too affected with a Uniform Motion Blur.
-
B. Image Blurring and Deblurring Model
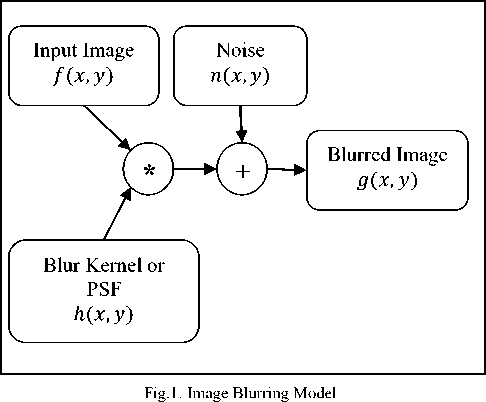
Image Degradation model [5][6] is modeled in which we apply degradation operator on the Input Image along with the additive noise which is random in nature to obtain a Degraded Image. The degraded image is g(x, y) is obtained by applying the degradation operation H over the input image f(x,y) along with the additive noise n(x,y).
g(x,y) = H[f(x,y)A + n(x,y) (1)
Blur in the image is a type of degradation. Blur is the most common degradation which will be associated with our system as the image will be captured while moving. So the Image will be mostly effected with the Uniform motion Blur. Blurred Image is commonly modeled as
Where g(x,y) is Blurred Image and f(x,y) is the actual input or the image without blur n(x, y) is noise h(x,y) is the Blur Kernel also known as point spread function (PSF) [6] and * is the convolution operator.
-
g(x, y) = f ( x, y) * h ( x, y) + n(x, y) (2)
Uniform Motion Blur [21][22] is caused due to the motion of either the object or the capturing device at the time of image capture. The Blur Kernel or the Point spread Function h(x, y) for the motion Blur is based on two parameters that is the Length of motion Blur (L) and the angle of motion Blur (6). When the object with text information is to be captured translates with a relative velocity V in respect to the camera, the blur length L in pixels is L = VTexp where, Texp is the time duration of the exposure. The expression for motion blur is given as,
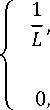
if 0 < |x| < L cos 6 ; y = L sin 6 otherwise
When the angle of blur 6 = 0, it is called horizontal motion blur. Point spread function can be represented in discrete as,
h(m, n, L)
if m = 0, |n| <
(L — 1)
r
L,
-
= • 2Z {(L —1) —2 |L 2-1|j' ifm = 0
Г L — 11
1 ■1
-
V 0, elsewhere
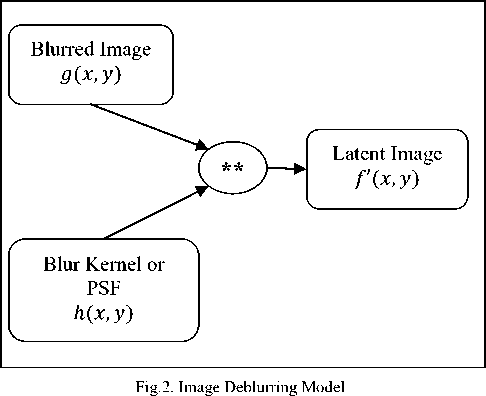
Deblurring [23][24][25] is the inverse operation of Blurring process which comes under Image Restoration [6]. Deblurring model can be given as the Deconvolution operation ** of the degraded image g(x, y) and the estimated Point Spread function or Blur Kernel h(x,y) to obtain the Input image f(x,y) . It is practically impossible to get the exact f(x,y') but we will get some degraded version of input Image f(x,y') due to the random noise present in the image which gets amplified will Deconvolution operation. So we call the obtained f(x,y^ as Latent Image.
f(x,y) = g(x,y) ** h(x,y) (3)
C. Optical Character Recognition (OCR) Algorithms
Most of the Reading framework for Visually Challenged till date have used work used Optical Character Recognition [4] in or the other way. OCR is image processing technology in which we extract the text present in the image and then output it as a Text file. Input to the Optical Character Recognition module is the acquired Image ideally it should be an uncompressed Bitmap Image. With the advent in the technology knower days we can extract the text from even compressed Images. On the input image we have to perform various pre-processing operations such as Binarization, Blur removal, skew correction and noise removal step [2] in order to increase the accuracy of the OCR and to prepare the image for further processing. Then text and non-text segmentation [7][8] is performed to isolate text information from graphics, segmented text is then segmentation into various lines and is known as Line Segmentation. From each line we segment different words and then these words are segmented as individual characters known as Character level Segmentation. Character recognition of the individual character is performed and output will be the Text file containing the recognized text. The main problem associated with OCR Engine is when the input image to the OCR is affected with any kind of Blur. Blur in the image is caused due to the movement of the capturing device or the object to be captured at the time of Image Capture. This problem was not addressed by the previous Reading Framework for Visually challenged persons. We have taken this problem into consideration and have come up with one of the efficient cost effective technique to remove the Blur in the image using Blind Deconvolution Algorithm in our previous paper Text Deblurring Using OCR performance [9]. Thus we remove the Blur present in the image and then it send for Optical Character Recognition. Thus the recognition rate of the text increases and the overall reliability of the System increase drastically.
-
D. Review of Text to Speech Engine
After the Optical character recognitions of the Image we get the text file as output. Now text has to be converted to speech or Braille So that the visually challenged person can understand it. Text to Speech Engine [10][12] converts the text output from OCR engine to its corresponding speech output. Text to speech Engine initially works by performing the preprocessing operation [11] on the Input text file. This is done in order to increase the efficiency of the text to speech generation. After this step speech generation is performed for the preprocessed text. The preprocessing step prepares the input text file for further processing the operations like text analysis, text normalization and then translating into a phonetic or some other linguistic representation are performed. During Preprocessing the spell checking is performed this helps in correcting some misrecognized text during the Optical Character Recognition on the text based on the punctuation marks the formatting of the paragraph is done. The abbreviations and acronyms are handled in the text Normalization [11] which enhances the speech output. This helps in communicating the meaningful speech to the visually challenged person. Morphological operations for the proper pronunciation of the word are performed in the Linguistic analysis followed by syntactic analysis to facilitate in handling ambiguities in the Input text. Now the speech generation process involves various steps such as phonetic analysis that is useful in finding the phone level within the word. Each phone level has the information about the sound tagged with it to be produced. Grapheme to phoneme conversion is the next step based on the dictionary. This is followed by the prosodic analysis which attaches the pitch and the duration information for the speech conversion. Speech synthesis is the last step which involves voice rendering to get the speech from the text to speech Engine.
-
II. Related work
Reading framework for Visually Challenged has been one of the researched topics under the assistive technology for visually challenge [13]. From the early 90’s there have been attempt to create some assistive technology for visually challenged when Xerox launched the device called Reading Edge, which used to scan the printed materials and then it use to read out loud to its users. It also provides is user with the Braille interface so that the blind persons can read out the contents using Braille interface. Reading Edge device has a scanner, speech generation software and a Braille interface equipped with keyboard for editing. Users were also given the facilities of adjusting the reading speed and have the option of choosing among different speaking voices. This was a handy aid for the visually challenged at that time but its usage required significant effort. The reading materials especially the books or the page has to be placed in the proper orientation for it to be scanned. Also the unit consisted of scanner which was large in size and was weighted. So the unit cannot be carried freely. R-Map [14] android application proposed it uses the camera to capture the Image of the Text and then with the help of Optical character Recognition and the text to speech engine it provides the read out loud service. As the mobile phone was used that has lower processing power than a desktop or Notebook. Mobile camera image is affected with various issues such as skew, blur, curved base lines and auto focus mechanism etc. there by making the best possible OCR engine to fail. The most powerful open source Tesseract OCR [20] engine was used for the recognition of the text in the captured image. After that recognized text file is send to Text To Speech (TTS) engine for further text to speech synthesis. With limited mobile screen size it was hard for a visually challenge person to capture the image of the long printed material with accuracy. OCR is developed for scanned documents of high quality to perform text extraction on a low resolution mobile camera captured image it is a challenging job. Whereas the issues of skew blur, different lighting condition and complex background also make the task difficult.
Assistive Reading System for Visually Impaired [15] proposed by Akshay Sharma, Abhishek Srivastava, Adhar Vashishth that uses a Document scanner to scan the image of document text to act as Input to the Optical Character Recognition module, which performs text and Non-text segmentation and recognition of segmented text to generates a text file as output which is converted to its corresponding speech with the help of Text to Speech Module. The difficulty with this proposed system is it also uses a scanner which is not portable and requires accuracy of visually challenged person to put the document into the scanner in proper orientation. Portable Camera-Based Assistive Text and Product Label reading for hand held Objects for Blind persons [16], a framework to help blind person to read the text label and product packaging from hand held object in their day to day life proposed by Chucai Yi, Yingli Tian and Aries Arditi. This system make blind person to feel independent in there day to day life. It isolates the object from its surrounding with the help of motion based Region of Interest (ROI) [2] by asking the user to shake the object. Thus it extracts the moving object from its complex background and then text extraction is performed on the segmented object and this followed by text recognition. The recognized text as speech is communicated to the blind using text to speech mechanism. Hence blind person can get the essence of the object details based on the specification provided on the object as speech. Patrick E.Lanigan, Aaron M. Paulos, Andrew W. Williams, Dan Rossi and Priya Narasimhan proposed Trinetra [17] a cost-effective assistive technology developed for visually challenged person to allow them independent in their life. With the help of this system they can easily do their daily activities. Trinetra system aims at quality improvement of the life of visually challenged by harnessing the collective capability of diverse networked embedded devices to help them to support navigation, shopping, transportation. Trinetra uses a barcode-based solution comprising a combination of off-the-shelf components, such as an Internet and Bluetooth-enabled mobile phone, text-to-speech software and a portable barcode reader. This is a bar code based solution to the problem of visually Challenged person. It have been seen that most of the system proposed were having their own set of merit and demerits. With the advancement in the information technology in recent times and the availability of considerable information processing capability and miniaturized sensors this similar unit can be designed which will have much smaller form factor, for e.g. like a mobile or special goggles. Instead of scanning the printed material it will take a picture and then use it to convert to text and then to speech [18][19].
-
III. Proposed Approach
In the proposed approach input to the system is the image captured by the visually challenged person containing the textual information. Our aim is to communicate the text information in the image to the
Visually Challenged person as Speech, so that he may acquire the knowledge about its surrounding. In order to fulfill our aim we have prepared an overall architecture of robust Reading framework for visually challenged person. In this framework on the input image f(x, y) the deblurring step is performed. This step is responsible for the blur kernel or the point spread function estimation in the image and then performing the Deblurring operation on the input image f(x,y) to get the deblurred Image f'(x,y") . Deblurring is performed using Blind Deconvolution method using OCR performance [9]. After deblurring we get the deblurred image f(x,y) then we perform the preprocessing steps in order to prepare the image f ' (x, y) for better Optical Character Recognition the steps involved are noise removal, thresholding and then Binarization operations to obtain the perfect binary black and white image f '' (x,y) which can be sent to the Optical Character Recognition for the extraction of the text information in the image f '' (x, y) and convert the text information into corresponding Output text file. The last and the important step is conversion of Output text file to speech or voice output with the help of Text to Speech. Hence the output speech will be send to visually challenged person so that he can get the knowledge of the text. This will help him to be more independent and dream of providing some level of Independence can be fulfilled through this framework. The Output Speech is feed to the Visually Challenged person so that he/she could listen whatever text is there in the image.
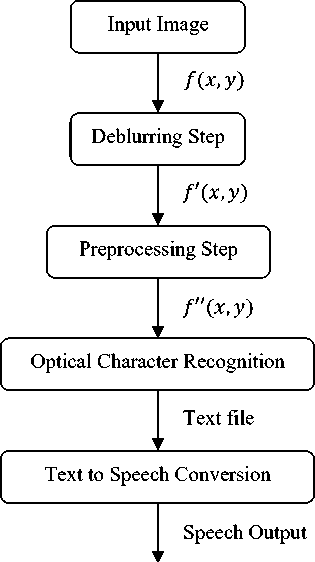
Fig.3. Overall Architecture of Robust Reading Framework for Visually Challenged
Algorithm for the proposed work
-
i. Input to the System is Image Captured by Visually Challenged person f(x, y).
-
ii. Blur Removal is the most important operation in which we first Estimate the Blur Kernel H(x, y).Blur Kernel is estimated with the help of two parameters that are Blur Length L and Blur Angle 6 .
-
iii. We Iteratively Create the Blur Kernel H(x,y) for different values of Blur Length L and Blur Angle 6. Then using Deconvolution operation we extract the Latent Image f' (x,y) for the Input Image f(x, y) and the Current computed Blur Kernel H(x,y).
-
iv. In Order to find the best Blur Kernel H(x,y) which can help in the text information extraction we evaluate each resultant Latent Image f (x, y) by calculating the Average Word Confidence AWC with the help of OCR.
-
v. Highest value of AWCmax indicates that Latent Image f (x,y) is best recognized with the corresponding Blur Kernel H(x,y) with two parameters that are Blur Length Lmax and Blur Angle 6 max .
-
vi. Thus we De-blur using Blind Deconvolution, the Input Image f(x,y) with the Blur Kernel H(x,y) with AWCmax for Blur Length Lmax and Blur Angle 6max to get the Deblurred Image or the Actual Latent Image f'(x,y) that can be used for further processing.
-
vii. The Preprocessing Operations are applied to the Deblurred Image or the Actual Latent Image f'(x,y) to obtain the Image f " (x,y) which is used for further processing. Preprocessing Operations increase the efficiency of the overall system.
viii. The Image f " (x,y) thus obtained is feed to an Optical Character Recognition (OCR) Engine for Text recognition. Output of OCR engine is the text file containing the text in the Image.
-
ix. Text file Output is send to a Text to Speech (TTS) Engine which performs the preprocessing operation the text file and then converts it to the corresponding Speech output.
-
A. Deblurring step on input image
Input image to the system f(x, y) is image captured by the visually challenged person with the motive to acquire the text information present in the image as speech, so that they can act accordingly. As already discussed that the image if affected by motion blur that is caused by the movement of the capturing device or the object at the time of image capture then this system accuracy will be at stake as the OCR is going to fail miserably and the next step that is TTS engine will have nothing as input for speech generation. To overcome this problem Deblurring step is being implemented. Average Word
Confidence AWC metrics [9] is used for the deblurring process. AWC Value lies between 0 and 1 it is calculated as
E Individual Word Confidences Total number of words
In this Deblurring step we iteratively based on two parameters of motion blur that are Blur Length L and Blur Angle 6 we try to estimate the optimal PSF that will give the best recognition rate based on AWC value of the OCR. AWC is the mathematical average of individual word confidences. Word Confidence [9] is the Normalized sum of character level confidence. Character Confidence is the normalized measure of the how effectively the character is recognized. Higher the Character Confidence of recognition Higher is the Word Confidence of Recognition and vice-versa. The Word Confidence is also affected by the dictionary based verification. If a word is found in the dictionary, it increases the Word Confidence value of that word. The longer the word, the higher will be the confidence value if it is found in the dictionary. For example if a long word of around 15 characters is found in dictionary it is pretty sure that the word is correct and will yield a higher word confidence, while on wrongly detected character a match against the dictionary by mistake is unlikely to occur. Short words like 'add' or 'odd' will both be found in dictionary. Therefore for smaller words there is a probability that we can get the dictionary match. Hence to overcome this problem words with 2 or less characters are not checked against the dictionary. The word confidence is normalized to an interval of 0.00 to 1.00 where 1.00 is the best and 0.00 is the worst word confidence.
For different value of Blur Length
L (L1L2L3L4 Ln) and different value of Blur angle 6(6162 63 64......6n) we make the PSF H(x,y) and then for every PSF we perform the deconvolution operation which is inverse operation of the blur to get the latent Image f'(x,y) and the using OCR we calculate the AWC value for the latent Image. The value of Blur length, Blur Angle and AWC are tabulated. The highest value of AWCmax is easily identified from the table and the corresponding values of the Blur length Lmax and Blur Angle 6max are found. These values constitute the best PSF H(x,y) which can deblur the given input Image f(x,y) to get the maximum recognition rate of the text information in the Image. After that we perform the deconvolution operation on the Input Image f(x,y) with the obtained value of Blur kernel or the PSF H(x,y) to obtain the latent Image f'(x,y) which is given as f'(x,y) = f(x,y) ** H(x,y)
Where ** is the deconvolution operation which helps in deblurring and is the inverse of Blurring operation. The resultant Image as known as Latent image f'(x,y) as it will be a distorted version of actual after deblurring step as the noise in the image get amplified during this process. Latent image f'(x, y) will be used for the further processing. Fig 4 shows Input Image f(x,y) to this system is Blurred Image. Now we estimate the PSF for which we will get the recognition of the text. Hence for every estimated PSF we perform the deblurring operation and calculate AWC value for them. The Highest value indicates that the PSF used will give the best recognition result for the Blurred Input Image. Fig 5 shows the Deblurred Image f'(x,y") with PSF created with Blur Length L =15 pixel and Blur Angle 6 =19 degree and the yellow boxes with values in the image indicate the word confidences of the words. They help in the calculation of AWC. Similarly Fig 5 shows the Deblurred Input Image f (x, y) with PSF obtained for Blur Length L =18 pixel, Blur Angle 6 =24 degree AWC = 0.586364 and Fig 6 shows the Deblurred Input Image f (x,y) with PSF obtained for Blur Length L =17 pixel, Blur Angle 6 =19 degree AWC = 0.646726. For different values of Blur Length L and Blur Angle 6 the highest value of AWCmax= 0.646726. Hence the corresponding values of the Blur length Lmax = 17 pixels and Blur Angle 6max = 19 degree are found. The Latent image thus obtained f (x,y) thus obtained in shown in Fig 7 that is used for further processing in next steps.

Fig.4. Blurred Input Image f(x, y)
0.62201

0.68286 0.52776
DUST STORMS
0.68986 0.40933
MAY EXIST
Fig.5. Deblurred Input Image f'(x,y) with PSF obtained for Blur Length L =18 pixel, Blur Angle 6 =24 degree
AWC = 0.5 86364
0.5936
CAUTION
0 69597 0.60407
DUST STORMS
0.6949 0.64509
MAY EXIST
Fig.6. Deblurred Input Image f'(x,y) with PSF obtained for Blur Length L =17 pixel, Blur Angle 6 =19 degree
AWC = 0.646726
САГТЮЯ
DUST STORMS
References Robust Assistive Reading Framework for Visually Challenged
- Marion A.Hersh, Michael A.Johnson “Assistive technology for Visually Impaired and Blind people” Book by Springer ISBN 978-1-84628-866.
- C. Gonzalez Richard E. Woods “Digital Image Processing” Book Third Edition Rafael Interactive Pearson International Edition prepared by Pearson Education PEARSON Prentice Hall.
- Jian Liang, Daniel DeManthon “Geometric rectification of Camera-Captured Document Image” IEEE Transaction on Pattern Analysis and Machine Intelligence Vol 30 No 4 April 2008.
- U. Pal, B.B. Chaudhuri "Indian script character recognition: a survey" Pattern Recognition 37 (2004) 1887 – 1899 published by ELSEVIER
- J.Amudha, N.Pradeepa, R.Sudhakar "A Survey on Digital Image Restoration" ELSEVIER Procedia Engineering, Volume 38, 2012, Pages 2378-2382.
- Ratnakar Dash “Parameter Estimation for Image Restoration” PhD thsis NIT Rourkela, Orrisa,India March 2012.
- Rainer Lienhart, Member, IEEE, and Axel Wernicke "Localizing and Segmenting Text in Images and Videos" IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 12, NO. 4, APRIL 2002.
- Honggang Zhang,KailiZhao,Yi-ZheSong,Jun Guo " A Text extraction from natural scene image:A survey" Neurocomputing 122 (2013) ELSEVIER.
- Avinash Verma, Deepak Kumar Singh “ Text Deblurring Using OCR Word Confidence”, International Journel of Image, Graphics and Signal Processing (IJIGSP), Vol.9, No.1, pp. 33-40, 2017, DOI :10.5815/ijigsp.2017.01.05.
- Kaveri Kamble, Ramesh Kagalkar "A Review: Translation of Text to Speech Conversion for Hindi Language" International Journal of Science and Research (IJSR) Volume 3 Issue 11, November 2014
- Suhas R. Mache,Manasi R. Baheti,C. Namrata Mahender "Review on Text-To-Speech Synthesizer" International Journal of Advanced Research in Computer and Communication Engineering Vol. 4, Issue 8, August 2015.
- Itunuoluwa Isewon,Jelili Oyelade,Olufunke Oladipupo "Design and Implementation of Text To Speech Conversion for Visually Impaired People" International Journal of Applied Information Systems Foundation of Computer Science FCS, New York, USA Volume 7– No. 2, April 2014
- Avinash Verma, Deepak Kumar Singh, Nitesh Kumar Singh “ Review on Assistive Reading framework for Visually Challenged” accepted for publication by International Conference on Computational Intelligence in Data Mining (ICCIDM-2016) in the AISC Series, Springer.
- Akbar S. Shaik, G Hossain “Desgin and Development and performance Evaluation of Reconfigured Mobile Android Phone for People Who are blind or Visually Impaired” In Proceedings of the 28th ACM International Conference on Design of Communication,,New York, NY, USA, 2010. ACM. October 2010.
- Akshay Sharma, Abhishek Srivastava, Adhar Vashishth “ An Assistive Reading System for Visually Impaired using OCR and TTS” International Journal of Computer Applications, Vol 95, No. 2 June 2014.
- Chucai Yi, Yingli Tian and Aries Arditi “Portable Camera-Based Assistive Text and Product Label Reading from Hand Held Objects for Blind Persons” IEEE/ASME Transaction on Mechatronics.
- Patrick E.Lanigan, Aaron M. Paulos, Andrew W. Williams, Dan Rossi and Priya Narasimhan “Trinetra: Assistive Technology for Grocery Shopping for the Blind” Published by Cylab in 2006.
- Bindu Philips and R.D. Sudhaker Samuel “ Human Machine Interface – A smart OCR for the visually challenged”, International Journal of Recent Trends in Engineering, Vol 2, No. 3 November 2009.
- Roberto Netoa, Nuno Fonsecaa "Camera Reading For Blind People" HCIST 2014 International Conference on Health and Social Care Information Systems and Technologies, Procedia Technology 16 ( 2014 ) 1200 – 1209 published by ELSEVIER.
- Ray Smith Google Inc. theraysmith@gmail.com “An Overview of the Tesseract OCR Engine” Google Inc OSCON 2007.
- Shamik Tiwari, V. P. Shukla, and A. K. Singh “Review of Motion Blur Estimation Techniques” Journal of Image and Graphics Vol. 1, No. 4, December 2013.
- Kishore R. Bhagat,Puran Gour "Novel Approach to Estimate Motion Blur Kernel Parameters and Comparative Study of Restoration Techniques"International Journal of Computer Applications (0975 – 8887) Volume 72– No.17, June 2013.
- Lu Fang, Haifeng Liu, Feng Wu, Xiaoyan Sun, Houqiang Li "Separable Kernel for Image Deblurring" 2014 IEEE Conference on Computer Vision and Pattern Recognition Pages: 2885 - 2892, DOI: 10.1109/CVPR.2014.369.
- Jing Wang, Ke Lu, Qian Wang, and Jie Jia "Kernel Optimization for Blind Motion Deblurring with Image Edge Prior" Hindawi Publishing Corporation Mathematical Problems in Engineering Volume 2012, Article ID 639824, 10 pages doi:10.1155/2012/639824.
- Long Mai,Feng Liu "Kernel fusion for better image deblurring" 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Pages: 371 - 380, DOI: 10.1109/CVPR.2015.7298634.
- Taeg Sang Cho,Sylvain Paris,Berthold K. P. Horn,William T. Freeman “Blur Kernel Estimation using the Radon Transform” Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on June 2011.
- Zohair Al-Ameen,Ghazali Bin Sulong,Md. Gapar Md. Johar “Computer Forensics and Image Deblurring: An Inclusive Investigation” IJMECS Vol.5, No. 11, November 2013 PP.42-48, DOI: 10.5815/ijmecs.2013.11.06.
