Self-configuring genetic programming algorithm for medical diagnostic problems

Author: Popov Evgeny Aleksandrovich, Semenkina Maria Evgenyevna
Journal: Сибирский аэрокосмический журнал @vestnik-sibsau
Section: 2-я международная конференция по математическим моделям и их применению
Article in issue: 4 (50), 2013.
Free access
Genetic programming algorithm for neural network automatic design is suggested. Ensemble member competence estimations based procedure of decision making with intelligent information technologies is proposed. Effectiveness of the approach is proved on the benchmark and real-world medical diagnostic problems.
Intelligent information technologies, genetic programming algorithm, ensemble based decision making
Short address: https://sciup.org/148177128
IDR: 148177128 | UDC: 519.6
Самоконфигурируемыи алгоритм генетического программирования для задач медицинской диагностики
Рассматривается алгоритм генетического программирования для автоматизированного проектирования нейронных сетей. Предлагается алгоритм генетического программирования для автоматического генерирования ансамблей интеллектуальных информационных технологий. Эффективность подхода проверена на тестовых и прикладных задачах медицинской диагностики.
Text of the article Self-configuring genetic programming algorithm for medical diagnostic problems
Recently, the importance of information support of various medical technologies is steadily increasing. The psychological aspect of the information technology application for medical purposes has a great importance in association with the doctor work peculiarities. In this case reasons for the decision are very important, especially if it is offered by computer [1].
Although genetic programming (GP) [2] have been successfully used in solving many real world problems, the performance of this technique essentially depends on the selection of its settings and tuning parameters. The process of settings determination and parameters tuning is known to be a time-consuming and complicated task. That forces the end user to worry about the decisionmaking quality. This research devoted to “self-adapted” GP is based on a range of ideas aimed at reducing the human expert role in algorithm designing. This should increase the validity of the decision-making process.
The rest of the paper is organized in following way. Section 1 describes the proposed method for GP selfconfiguring as well as testing results over the benchmark symbolic regression problems. Neural networks design with GP is described in Section 2, in Section 3 the ensemble design method is described, Section 4 contains the performance comparison of suggested algorithms and alternative approaches on three real world medical diagnostic problem. In Conclusion we discuss obtained results and directions of the future research.
Self-configuring genetic programming algorithm. It is necessary to find solution for the main problem of evolutionary algorithms before suggesting for end users to apply genetic programming algorithm for automated design of tools for solving classification problems. Choosing the right GP setting for each problem is a difficult task even for experts in the field of evolutionary computation, so we need to find a way to avoid it.
In our algorithm [3] operators’ probabilistic rates dynamic adaptation on the level of population with centralized control techniques was applied (see Fig.1). Instead of the real parameters adjusting, setting variants were used, namely types of selection (fitness proportional, rank-based, and tournament-based with three tournament sizes), crossover (one-point, two-point, as well as equiprobable, fitness proportional, rank-based, and tournament-based uniform crossovers [3]), population control and level of mutation (medium, low, high for two mutation types). Each of these has its own initial probability distribution (fig. 2) which are changed as algorithm executes (fig. 3).
The uniform crossover operator in evolutionary algorithms is known as one of the most effective crossover operators. For this reason, uniform crossover operator for GP was modified in [3] with a purpose of improving its performance. Modification gives the possibility to fulfill uniform crossover also in case when nodes have different arity because all functions’ arguments compete with each other. E. g., if one tree is “EXP – X” (exp(x)) and other one is “+ – Y – Z” (y+z) and the off-spring inherits the node “+” then resulting subtree can be one of “y+z”, “x+z” or “y+x”. If the off-spring inherits the node “EXP” then resulting subtrees can be “exp(x)”, “exp(y)”, “exp(z)”. This modification brings more flexibility to the crossover process and adds the potential for a change in the algorithms behavior.
Selective pressure during the recombination process was introduced making the probability of a parental gene being passed to the off-spring depended on parent fitness values. The off-spring can inherit every of its nodes from one of parents not only equiprobably but also with different probabilities determined by parent fitness values in one of the ways like the usual selection operators. Fitness proportional, rank-based and tournament-based uniform crossover operators were added to the conventional operator that can be called now the equiprobable uniform crossover.
As a commonly accepted benchmark for GP algorithms is still an “open issue” [4], the symbolic regression problem with 17 test functions borrowed from [5] were used in [3] for testing the modified genetic programming algorithm with new uniform crossover operators (MGP).
Results of self-configuring GP (SelfCGP) performance evaluation over 17 test problems and the performance comparison with conventional GP are presented in Table 1 below ([3]). Experiments settings are 100 individuals, 300 generations and 100 algorithm runs for each test function. The variance is given over 17 test functions. The reliability is the portion of the runs for a given algorithm that gives satisfactorily precise solution (MSE is less than 0.01). Statistical significance was estimated with ANOVA.
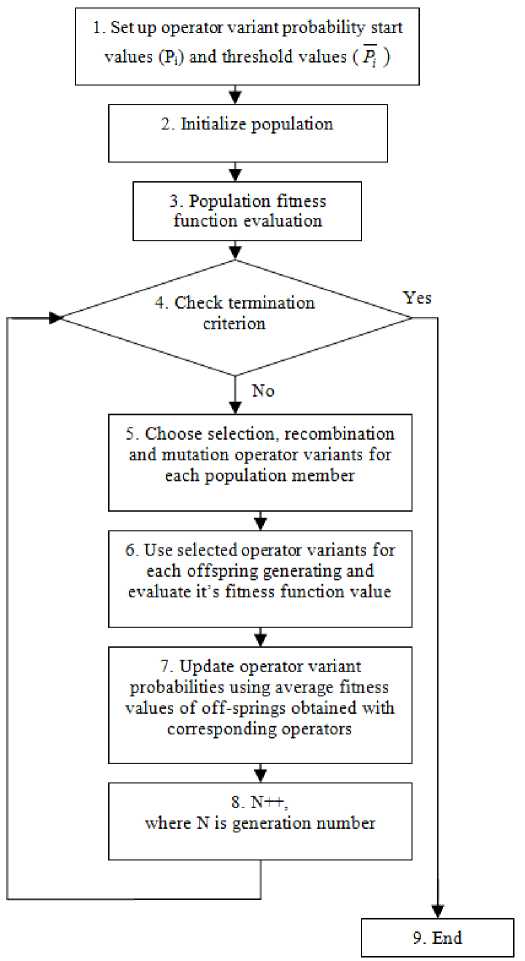
Fig. 1. Main part of SelfCGP block diagram
From table 1 we can see that GP with modified uniform crossover operators (MGP) performs better than conventional GP. This demonstrates that proposed operators may be useful.
SelfCGP reliability averaged over 17 test function is better than averaged best reliability of conventional GP and slightly less than best reliability of modified GP. The worse reliability (for the most hard problem) averaged over 100 runs is equal to 0.42. The best reliability is equal to 1.00. Computational efforts are less than alternative algorithms have. It gives us a possibility to recommend SelfCGP for solving symbolic regression problems as the better alternative to the conventional GP. Main advantage of SelfCGP is no need of algorithmic details adjustment without any losses in the performance that makes this algorithm useful for many applications where end users being no experts in evolutionary modeling nevertheless intend to apply GP for solving these problems.
Solving symbolic regression problems, it is interesting to have not only the precise enough computational procedure but also a symbolically correct answer, i. e. exactly the same analytical expression that was used to generate data base. The last three columns in table 1 contain information on the quality of the obtained approximations. The first column shows the percentage of precise solutions symbolically identical to the test function. The second one shows the percentage of conditionally precise solutions that needed some elementary transformations and numbers rounding to be symbolically identical to the test function. The third column shows the percentage of the obtained solutions which cannot be transformed into a symbolically identical form (but give enough good approximation).
We can add that the self-configuration itself (without new uniform crossover operators use) does not improve this ability of the conventional GP. Such a role of uniform crossover operators in GP can be explained through the observation that these operators prevent GP tree’s blow up which usually complicates the symbolic expression and gives no possibility to find precise solution.
ANN design with GP. We have to describe our way to model and optimize an ANN structure with GP before an employment of our SelfCGP algorithm.
Usually, GP algorithm works with tree representation, defined by functional and terminal sets, and exploits of the specific solution transformation operators (selection, crossover, mutation, etc.) until termination condition will be met [6].
The terminal set of our GP includes input neurons and 15 activation functions such as bipolar sigmoid, unipolar sigmoid, Gaussian, threshold function, linear function, etc. The functional set includes specific operations for neuron placement and connections. The first operation is the plac ing a neuron or a group of neurons in one layer. There will be no additional connections appeared in this case. The second operation is the placing a neuron or a group of neurons in sequential layers in such a way that the neuron (group of neurons) from the left branch of tree preceded by the neuron (group of neurons) from the right branch of tree. In this case, new connections will be added that connect the neurons from the left trees branch with the neurons from the right trees branch. Input neurons cannot receive any signal but have to send a signal to at least one hidden neuron. It might be so that our GP algorithm does not include some input neurons in resulting tree, i. e., high performance ANN structure that uses not all problem inputs can be found. This feature of our approach admits using our GP for the selection of the most informative problem inputs combination. Tree and corresponding neural network example are presented on the figure 4.
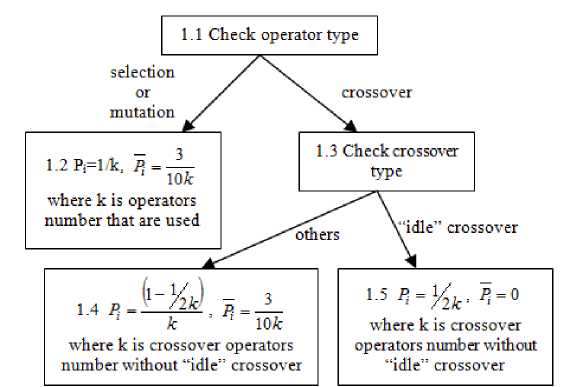
Fig. 2. Flowchart illustrating step 1 in SelfCGP block diagram
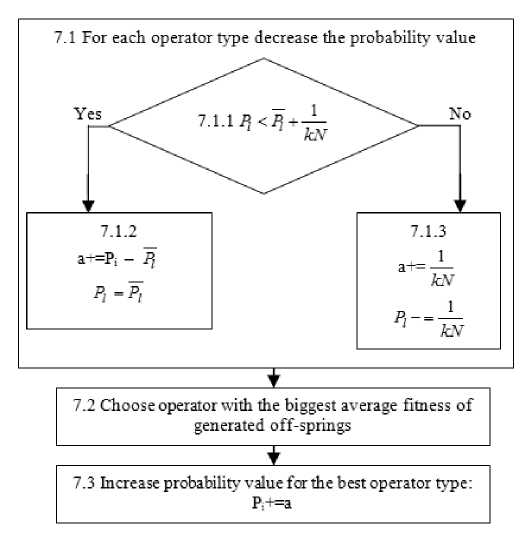
Fig. 3. Flowchart illustrating step 7 in SelfCGP block diagram
Table 1
Self-configuring GP performance over test symbolic regression problems
|
Algorithms |
Reliability |
Average generations variance |
Precise solutions, % |
Cond. precise solutions, % |
Approx. Solutions, % |
||
|
On the most simple task |
On the most difficult task |
In general |
|||||
|
GP |
0,77 [0,41; 0,91] |
0,13 [0; 0,27] |
0,43 [0,00; 0,91] |
[33; 289] |
50 |
16 |
34 |
|
MGP |
0,79 [0,39; 1] |
0,34 [0,15; 0,43] |
0,53 [0,11; 1,00] |
[27; 243] |
58 |
20 |
22 |
|
SelfCGP without MGP |
0,83 |
0,19 |
0,46 [0,19; 0,83] |
[35; 254] |
50 |
17 |
33 |
|
SelfCGP |
1 |
0,48 |
0,69 [0,42; 1,00] |
[49; 201] |
58 |
16 |
26 |
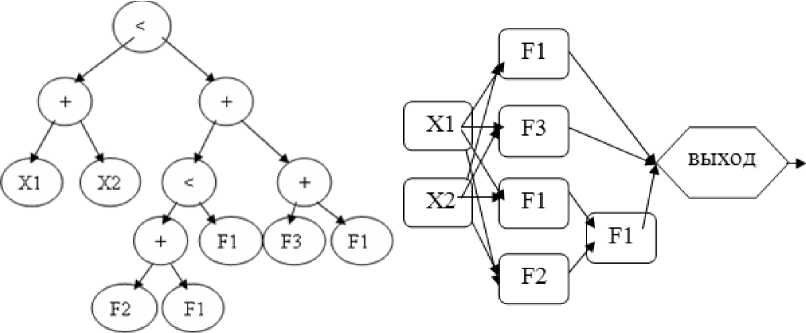
Fig. 4. Tree and corresponding neural network example
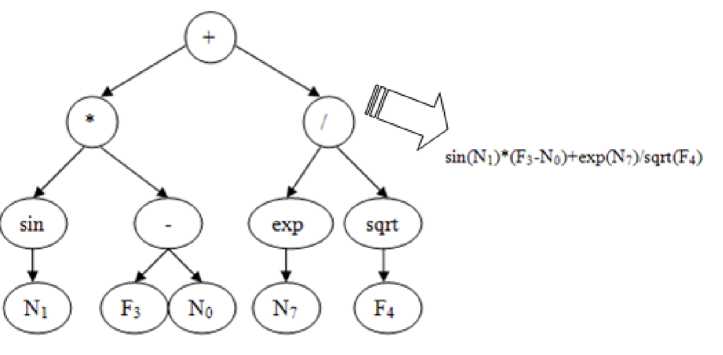
Fig. 5. Tree and corresponding decision making ensemble formula example
The efficiency of the proposed approach was tested on a representative set of test problems (approximation, time series prediction). Averaging of the mean square error was carried out by 20 runs. The test results showed that the neural networks created by genetic programming algorithm have a small number of neurons in comparison with neural networks obtained by means of neurosimulator and are not fully connected (few connections between neurons). These neural networks have enough small mean square error.
Integration of IIT ensembles with self-configuring genetic programming algorithm. Usual practice of data analysis problems solving lies in the fact that the structure choice and parameters setting of a separate intelligent information technology (IIT) are performed and then the best found IIT solves the problem. However, the solutions quality improvement is particularly important for solving problems of medical diagnosis and it is desirable to have a set of IIT and to use all of them at the same time according to the chosen ensemble technology.
In this paper we apply self-configuring genetic programming algorithm to build a common method of decision making by IIT ensemble through the creation of symbolic regression formulas with various IIT as elements of the terminal set.
Having the developed appropriate tool for IIT automated design that does not require the effort for its adjustment, we applied our self-configuring genetic programming technique to construct the formula that shows how to compute an ensemble decision using the component IIT decisions. The algorithm involves different operations and math functions and uses the models of different kinds providing the diversity among the ensemble members. In our numerical experiments, we use symbolic expressions and neural networks, automatically designed with our SelfCGP algorithm, as the ensemble members. The algorithm automatically chooses the component IIT which are important for obtaining an efficient solution and doesn’t use the others. The ensemble component IIT are taken from the preliminary IIT pool that includes 20 ANNs and 20 symbolic regression formulas (SRFs) generated in advance with SelfCGP.
Ensemble decision making method example is presented on the Fig. 5, where N0, N1, N2, …, N10 are ANNs from preliminary pool, F0, F1, F2, …, F10 are symbolic regression formulas from preliminary pool, at the same time better IIT has smaller number, i.e. N 0 is the best ANN in preliminary pool.
The proposed procedure has been implemented as a software system and tested on a test problems representative set.
Approbation on applied problems of medical diagnostics. To test the proposed approach, we used three practical problems of medical diagnosis: breast cancer diagnosis (11 attributes, 2 classes, 458 patients records with benign cancer and 241 records with malignant tumors), diabetes diagnosis (9 inputs, 2 classes, 500 patients with a negative result and 268 patients positive for diabetes) and Heart Disease diagnosis (14 inputs, 2 classes, 303 instances). Input data were taken from [8]. In the problem of cancer diagnostic we need to determine the type of tumor (benign or malignant) throw the existing test result (tumor cell characteristics (shape, thickness, uniformity, etc.). In the diabetes diagnostics problem we need to determine whether a patient is sick with diabetes (all patients are women older than 21 years) according to available data (on age, ancestry, pregnancies number, body mass index, skinfold size, the glucose amount in the plasma, the insulin amount in the blood serum, blood pressure, etc.). For these two problems evaluations were fulfilled in the same manner as in [9], i. e. indicator is equal to weighted sum of mean squared error and quality of classification. Results for comparison for the last problem were taken from [10; 11]. For this problem the indicator is the error of classification.
Table 2
Ensembling methods comparison
|
Classifier |
Cancer |
Diabetes |
Heart |
|
SelfCGP+ANNE |
0 |
17,18 |
0,156 |
|
SelfCGP+ANN+SRF+Ens. |
0,06 |
17,43 |
0,161 |
|
SelfCGP+SRFE |
0,34 |
18,21 |
0,168 |
|
Bagging (SelfCGP+ANN) |
0,67 |
18,22 |
0,171 |
|
Bagging (SelfCGP+SRF) |
0,95 |
19,34 |
0,176 |
|
ANN w. a. |
1,03 |
19,03 |
0,179 |
|
ANN s. a. |
1,09 |
19,75 |
0,183 |
|
SRF w. a. |
1,22 |
19,86 |
0,186 |
|
SRF s. a. |
1,27 |
20,23 |
0,193 |
|
ANN+SRF w. a. |
1,09 |
19,34 |
0,178 |
|
ANN+SRF s. a. |
1,18 |
19,79 |
0,181 |
|
SelfCGP+ANN |
1,05 |
19,69 |
0,185 |
|
SelfCGP+SRF |
1,23 |
20,01 |
0,188 |
|
CROANN |
1,06 |
19,67 |
– |
|
GANet-best |
1,06 |
24,70 |
– |
|
COOP |
1,23 |
19,69 |
– |
|
CNNE |
1,20 |
19,60 |
– |
|
ESANN |
0,95 |
20,93 |
– |
|
GSOANN |
0,65 |
19,79 |
– |
|
NLCS (neural-based learning classifier systems) |
– |
– |
0,16 |
|
Neural Ensemble |
– |
– |
0,181 |
|
NeC4.5 |
– |
– |
0,194 |
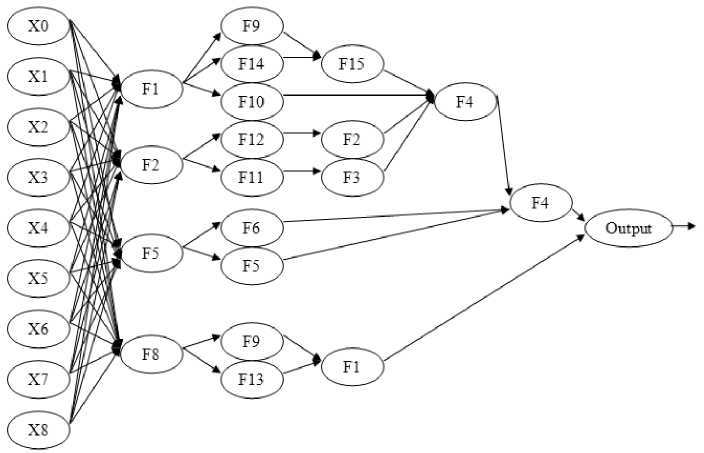
Fig. 6. Example of ANN for Diabetes diagnostic problem
For the designing every IIT, corresponding data set is randomly divided into three parts, i. e., training sample (60 %), validation sample (20 %) and test sample (20 %).
The first three lines contain results of the ensembling method suggested in this paper for three kinds of ensemble members – ANNs (ANNE), symbolic regression formulations (SRFE) and both (ANN+SRF+Ens.). Next eight lines contain results for conventional methods of ensemble form- ing – bagging, simple (s. a.) and weighted averaging (w. a.). Next two lines show results of single best technologies (ANN and SRF) automatically generated with SelfCGP. Results of these thirteen lines are averaged over 20 independent runs. The statistical robustness of the results obtained was confirmed by ANOVA tests which were used for processing received evaluations of our algorithms performance.
Results in table 2 demonstrate that the SelfCGP based ensembling method used the ANNs or ANNs and SRFs integration outperforms conventional ensembling methods, the single best ANN and SRF designed with SelfCGP as well as other given classification methods.
Example of ANN for Diabetes diagnostic problem is presented on the fig. 6. Ensembles obtained by solving the diabetes diagnostic problem have the form
F 2 e F 8 F 7 F 4
2.11
(for symbolic regression formulations)
( Nо + No + No ^
and sinl —2----8----9 I + 0.02 (for ANN).
( 1.998 )
Conclusions. Thus developed software system for intelligent information technology ensembles automated design allows solving complex problems of medical diagnostics. IIT ensemble design increases the efficiency and reliability of IIT application. The efficiency of this approach has been verified not only on the test but also on the real practical problems that allows us to recommend it for end users as a convenient and effective tool for data
The further development of the system is aimed to the expansion of its functionality by including the other types of IITs (fuzzy logic systems, decision trees, neuro-fuzzy systems, other kinds of ANNs, multiobjective selection, etc.).
