Semantic Question Generation Using Artificial Immunity

Author: Ibrahim E. Fattoh, Amal E. Aboutabl, Mohamed H. Haggag
Journal: International Journal of Modern Education and Computer Science (IJMECS) @ijmecs
Article in issue: 1 vol.7, 2015.
Free access
This research proposes an automatic question generation model for evaluating the understanding of semantic attributes in a sentence. The Semantic Role Labeling and Named Entity Recognition are used as a preprocessing step to convert the input sentence into a semantic pattern. The Artificial Immune System is used to build a classifier that will be able to classify the patterns according to the question type in the training phase. The question types considered here are the set of WH-questions like who, when, where, why, and how. A pattern matching phase is applied for selecting the best matching question pattern for the test sentence. The proposed model is tested against a set of sentences obtained from many sources such as the TREC 2007 dataset for question answering, Wikipedia articles, and English book of grade II preparatory. The experimental results of the proposed model are promising in determining the question type with classification accuracy reaching 95%, and 87% in generating the new question patterns.
Natural Language Processing, Automatic Question Generation, Semantic Role Labeling, Named Entity Recognition, Artificial Immune System
Short address: https://sciup.org/15014717
IDR: 15014717
Text of the scientific article Semantic Question Generation Using Artificial Immunity
Published Online January 2015 in MECS DOI: 10.5815/ijmecs.2015.01.01
Natural language processing is one of the most popular areas of artificial intelligence and has numerous applications such as text summarization, machine translation, question answering, question generation, etc. [1]. Question generation is an important component in advanced learning technologies such as intelligent tutoring systems. A wide transformation has been made last years in the field of Natural Language Processing (NLP) in studying the questions as a part of the task of question answering to the task of the Automatic Question Generation (AQG). Developing AQG systems has been one of the important research issues because it requires insights from a variety of disciplines, including, Artificial Intelligence, Natural Language Understanding (NLU), and Natural Language Generation (NLG). One of the definitions of Question Generation is that it is the process of automatically generating questions from various inputs like raw text, database, or semantic representation [2].
The process of AQG is divided into a set of subtasks which are content selection, question type identification, and question construction. Previous trials on question generation have focused on two types of question formats; multiple choice questions and entity questions systems. Multiple choice questions ask about a word in a given sentence where the word may be an adjective, adverb, vocabulary, etc. Entity questions systems or Text to Text QG (such as factual questions) ask about a word or phrase corresponding to a particular entity in a given sentence where the question types are what, who, why etc. This research introduces a learning model using the Artificial Immune System (AIS) for the second type of question formats. The proposed learning model depends on the labeling roles extracted from SRL (Semantic Role Labeling) and named entities extracted from NER (Named Entity Recognition). An artificial immune system approach in supervised learning problems is adopted to build a classifier generator model for classifying question types and then generating the best matching question (s) for a given sentence. The rest of the paper is organized as follows: section 2 discusses the related work for AQG, section 3 introduces AIS, section 4 introduces both SRL and NER, section 5 presents the proposed model AIQGS (Artificial Immune Automatic Question Generation System) and section 6 shows the experimental results and evaluation. Finally, section 7 introduces a conclusion and future work with some remarks.
-
II. Related Work
A review of the previous AQG systems that generate questions from a sentence for the second question type mentioned in section 1 is introduced in this section. Previous efforts in QG from text can be broadly divided into three categories: syntax based, semantics based, and template based methods. The three categories are not entirely disjoint. Syntax based methods follow a common technique: parse the sentence to determine syntactic structure, simplify the sentence if possible, identify key phrases and apply syntactic transformation rules and question word replacement. There are many systems in the literature for the syntax based methods. Kalady et al.[3], Varga and Ha [4], Wolfe [5], and Ali et al.[6] introduce a sample of these methods. Semantic based methods also rely on transformations to generate questions from declarative sentences. They depend on semantic rather than the syntactic analysis. Mannem et al. [7] proposed a system that combines SRL with syntactic transformations to generate questions. Yao and Zhang [8] demonstrate a QG approach based on minimal recursion semantics (MRS). A framework for shallow semantic analysis was developed by Copestake et al.[9] which uses an eight-stage pipeline to convert input text to a set of questions. The third category, template based methods, offer the ability to ask questions that are not as tightly coupled to the exact wording of the source text as syntax and semantics based methods. Cai et al. [10] presented NLGML (Natural Language Generation Markup Language), a language that can be used to generate questions of any desired type. Wang et al. [11] introduced a system to generate questions automatically based on question templates which are created by training the system on many medical articles. The model used in this research belongs to semantic based methods with a learning phase that introduces a classifier to decide the question type and a recognizer for question pattern that specifies the generated question.
-
III. Artificial Immune System
An Artificial Immune System is a computational model based upon metaphors of the natural immune system [12]. From the information-processing perspective, an immune system is a parallel and distributed adaptive system with a partial decentralized control mechanism. An immune system utilizes feature extraction, learning, storage memory and associative retrieval in order to solve recognition and classification tasks. In particular, it learns to recognize relevant patterns, remember patterns that have been seen previously and has the ability to efficiently construct pattern detectors. The overall behavior is an emergent property of many local interactions. Such information-processing capabilities of the immune system provide many useful aspects in the field of computation [13]. AIS emerged as a new branch in Computational Intelligence (CI) in the 1990s. A number of AIS models exist and are used in pattern recognition, fault detection, computer security, data analysis, scheduling, machine learning, search optimization methods and a variety of other applications researchers are exploring in the field of science and engineering [12][14]. There are four basic algorithms in AIS; network model, positive selection, negative selection, and clonal selection [12]. The main features of the clonal selection theory [15] are proliferation and differentiation on stimulation of cells with antigens, generation of new random genetic changes expressed subsequently as a diverse antibody pattern and estimation
of newly differentiated lymphocytes carrying low affinity antigenic receptor. The clonal selection algorithm is the one used in the learning phase of the proposed model as will be shown in section 5.
-
IV. Semantic Role Labeling and Named Entity Recognition
The natural language processing community has recently experienced a growth of interest in semantic roles since they describe WHO did WHAT to WHOM, WHEN, WHERE, WHY, HOW etc. for a given situation, and contribute to the construction of meaning [16]. SRL has been used in many different applications such as automatic multiple choice question generation [16] and automatic question answering [17]. Given a sentence, a semantic role labeler attempts to identify the predicates (relations and actions) and the semantic entities associated with each of those predicates. The set of semantic roles used in PropBank [18] includes both predicate-specific roles whose precise meaning are determined by their predicate and general-purpose adjunct-like modifier roles whose meaning is consistent across all predicates. The predicate specific roles are Arg0, Arg1, ..., Arg5 and ArgA. Table1 shows a complete list of the modifier roles. Considering a sentence such as: Columbus discovered America in 1492. The SRL parse will be as in (1).
[ Columbus /Arg0] [ discovered /v:Discover] [America /Arg1] [in 1492/ ArgM-Tmp]. (1)
Moreover, recognition of named entities (e.g. people, organizations, location, etc.) is an essential task in many natural language processing applications nowadays. Named entity recognition (NER) is given much attention in the research community and considerable progress has been achieved in many domains [19].Considering the same sentence as in the previous example , the output of NER will be as in (2).
[Person Columbus] discovered [GPE America] in [date1492]. (2)
The attributes extracted from both NER and SRL act as the target words which are searched for in the sentence whose question type is being identified. Table 2 shows the extracted attributes; their source and their associated question type and which are used in this research. The next section shows how SRL and NER are used in the content selection phase in the proposed model for AQG.
-
V. Proposed Model
To generate a question, named entity recognition and semantic role labeling are first performed. Then, sentence and question patterns are generated for sentences used in
Table 1. ProbBank Arguments Roles
The algorithm ALG_DATA_PREPARATION is used to prepare the training data set after which the training patterns are passed to the learning phase. An AIS classifier generator, named ALG_TRAIN, is proposed for the training phase based on the clonal selection mechanism.
The training phase starts by choosing random patterns from the training patterns to act as memory cells (MCs).
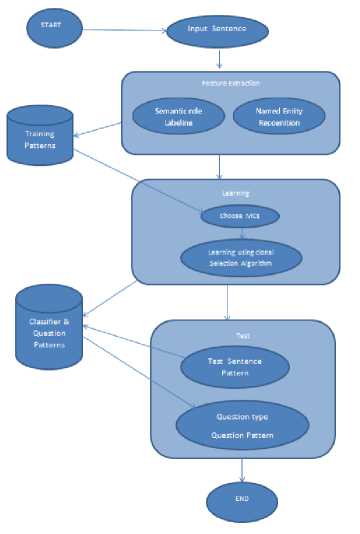
Fig.1. Flow diagram of the AIQGS
Table 2. Attributes used from SRL and NER and their question types
|
Target |
Source |
Question Type |
|
|
SRL |
How |
|
|
SRL |
Why |
|
|
SRL |
Why |
|
|
SRL |
Why |
|
|
NER |
Who |
|
|
SRL |
Where |
|
|
NER |
Where |
|
|
SRL |
When |
|
|
NER |
When |
|
|
NER |
When |
ALG_DATA_PREPARATION (Sentence)
For each sentence S in the training set
SentPat ^ Get the sentence pattern using NER, and SRL
Set the question(s) Type(s) for the SentPat
Quest_Pat ^ Build the question(s) pattern(s) for the SentPat
End for
Return the Sent_Pat and Ques_Pat.
For each antigen (AG) in the training data, the affinity between the antigen and every memory cell is measured using the Euclidean distance. Then, a stimulation value is calculated for each memory cell. The memory cell which has the highest stimulation value is chosen to be cloned using ALG_CLONAL _SELECTION. The stimulation value for the mutated clones is also calculated and the one with the highest stimulation value is chosen to be a memory cell candidate. If the mutated clone stimulation value is greater than the memory cell stimulation value, the memory cell is removed from the MCs pool.
ALG_TRAIN (Sent_Pat, Quest_Pat)
MCPool ^ get random sentence and question patterns from
Sent_Pat and Quest_Pat for each class.
For each Antigen (AG) in the training patterns
McAff ^ Get the affinity (AG, classMCs)
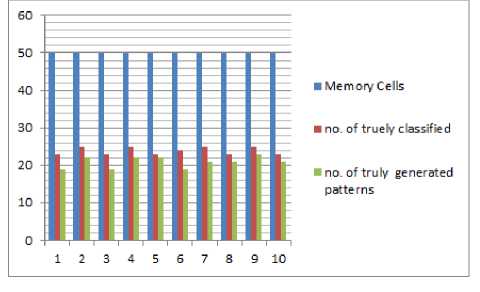
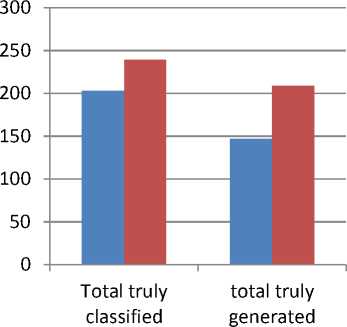
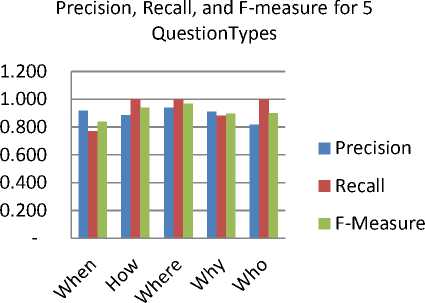
Mc_Stim_Val MC_Aff) McHigh ^ Get the MC with the highest stimulation value and its question pattern McClones ^CLONAL_SELECnON (Mc_High,AG,Mc_Stim_Val) End for ALG_CLONAL _SELECTION (MC, AG, Stim_Val) Number_ of_Clones=Stim_Val * Clonal_Rate For each new clone CloneAff ^ Get the Affinity (clone. AG) MutatedClone ^ Mutate the clone Mutated Clone Stim Val ^ Calculate the mutated clone stimulation value with the AG. Select the mutated clone with the highest stimulation value and put it in the MCs pool If the Mutated_Clone_Stim_Val >Stim_Val Remove the MC from MCs pool End for After finishing the training phase, the classifier is considered to be the memory cells existing in the memory cell pool. Question patterns are associated with these memory cells and every mutated clone added to the memory cell pool. The testing phase starts with preparing the new sentence as a pattern, then calculating the stimulation value for each memory cell existing in the classifier with the sentence’s pattern. The stimulation value for each class is then calculated by adding all the stimulation values of each memory cell belonging to the class. The class which has the highest average stimulation value is chosen to be the question type for the sentence. The memory cell(s) that has a stimulation value greater than a given threshold value in that class is chosen. The question pattern of the chosen class is retrieved and is considered as the question generated for the input sentence. The threshold value used here is 0.5. It is chosen after trying many threshold values, and got the best results. The generated pattern is then mapped into a sentence to form the real question of the sentence. ALG_TEST (Test_Sentence) AG ^DATA_PREPERATION (Test_Sentence) Foreach MC in MCsPool Calculate the stimulation value(MC, AG) End for For each class Calculate the average stimulation value of the class for that AG End for Return the class with the highest average stimulation value as the question type Get the question pattern from the MCs Pool that belongs the MC that has stimulation value >0.5 A. Walk Through Example For Data Preparation In this section, we apply the data preparation phase on the example shown in section 2. The output of both (1) and (2) are merged yielding a pattern as in (3) {Arg0} The output of the SRL is between { }, and the output of the NER is between < >. According to table 2, the question type is chosen according to the target extracted from NER and SRL. Searching the pattern (3), the targets Person, AM-TMP, and Date are found so two question patterns are generated for the sentence; a pattern is for WHO question and the other is for WHEN question. The two patterns are Who + {VBD} + {Arg1} When + did + {Arg0} The verb {V} is obtained from the output of SRL labeling. The sentence pattern (3) and its question patterns (4) and (5) are interpreted as a two feature vectors in the training set, one vector for each question type. The representation of the feature vector is numeric data; 1, 0, and 5. One means that the attribute exists in the sentence, zero means that the attribute doesn’t exist in the sentence, five is for the attribute(s) that determines the question type. VI. Experimental Results The proposed system is applied to a set of sentences extracted from different sources including Wikipedia articles, TREC 2007 dataset for question answering and English book of grade II prep. 170 sentences are extracted and mapped into 250 patterns using SRL and NER as explained previously. The number of patterns is greater than the number of sentences because some sentences are mapped into more than one pattern. This occurs in cases where a sentence has more than one label of either SRL or NER labels. The 250 patterns are used in training and testing. The system is tested using a crossvalidation test with number of folds=10, each fold having 25 patterns chosen for testing. Two trials are applied to the system. In the first trial 25 patterns are randomly chosen to be memory cells in each fold. In the second trial, 50 patterns are chosen as memory cells in each fold. Each time after extracting the memory cells and the test patterns, the training phase is applied to the memory cells and the remaining patterns in the training set to generate the classifier. Then, testing is applied to the 25 chosen patterns. Table 3 shows the results obtained from the two trials in each fold, the number of memory cells, the number of truly classified patterns, the number of falsely classified patterns, the number of truly generated patterns for the truly classified sentences. Fig.2 (A). The 10 folds for trial 1 Fig.2 (B). The 10 folds of trial 2 Table 3. Results of classification and question patterns generated using 25 and 50 M-cells in each test fold EXP# No.of M-Cells No. of truly classified No.of false classified No. of truly generated patterns Percent of true classification Percent of true generated patterns 1 25 20 5 16 80.00% 80.00% 50 23 2 19 92.00% 82.61% 2 25 19 6 12 76.00% 63.16% 50 25 0 22 100.00% 88.00% 3 25 20 5 14 80.00% 70.00% 50 23 2 19 92.00% 82.61% 4 25 22 3 15 88.00% 68.18% 50 25 0 22 100.00% 88.00% 5 25 22 3 17 88.00% 77.27% 50 23 2 22 92.00% 95.65% 6 25 21 4 15 84.00% 71.43% 50 24 1 19 96.00% 79.17% 7 25 22 3 16 88.00% 72.73% 50 25 0 21 100.00% 84.00% 8 25 20 5 15 80.00% 75.00% 50 23 2 21 92.00% 91.30% 9 25 19 6 13 76.00% 68.42% 50 25 0 23 100.00% 92.00% 10 25 18 7 14 72.00% 77.78% 50 23 2 21 92.00% 91.30% The total and average of the overall test results for the 10 folds of the two trials are shown in tables 3, 4, and figures 2A and 2B. From tables 3 and 4, it is obvious that increasing the number of memory cells at the beginning of the training phase leads to an increase in the number of patterns in the classifier. The increase in the number of patterns gives the system the ability to classify more accurately and to increase the number of question patterns that are generated or recognized truly. It is shown that out of the 10 trials, classification accuracy reaches 100% four times when increasing the memory cells to 50 at the beginning of the training phase. Also the percentage of the truly generated patterns has been improved in all trials as shown in last column in table3. the overall classification accuracy is increased by increasing the number of memory cells in the second trial from 81% to more than 95% as shown in table 4 and figure 3. The increase in the classification accuracy leads to the increase in the total truly generated patterns, as seen it jumps to 209 truly generated patterns out of 239 truly classified patterns. The increase of both total truly classified and total truly generated patterns reflects the effect of increasing the memory cells in the training process in order to generate a good classifier able to produce an accurate classification ratio. The overall classification accuracy is increased by increasing the number of memory cells in the second trial from 81% to more than 95% as shown in table 4 and figure 3. The increase in the classification accuracy leads to the increase in the total truly generated patterns, as seen it jumps to 209 truly generated patterns out of 239 truly classified patterns. The increase of both total truly classified and total truly generated patterns reflects the effect of increasing the memory cells in the training process in order to generate a good classifier able to produce an accurate classification ratio. The most important measures for classification problems are the precision, recall, and f-measure for each class. Precision _ True Positive True Positive+False Positive = _______True Positive_______ True Positive+False Negative Table 4. The total of both truly classified and generated patterns for the two trials Trial No. No. of M-Cells Total true classified Total true generated Percentage of true classified Percentage of true generated 1 25 203 147 81.20% 72.41% 2 50 239 209 95.60% 87.45% Table 5. Precision, recall, and F-measure for classification of question types Question Type Precision Recall F-measure Who 0.898 1 0.946 How 0.973 1 0.986 Why 1 0.971 0.985 When 1 0.828 0.906 Where 1 1 1 ■ trial 1 ■ trial 2 Fig.3. Total truly classified and total truly generated patterns for the two trials F- = 2∗ Precision∗Recall Precision+Recall The precision measures the probability that the retrieved class is relevant; the recall measures the probability that a relevant class is retrieved, and the F-measure is the harmonic mean of precision and recall. These measures are shown in table 5 for each question type in this problem. The number of truly generated patterns for each question type used in this research differs and the reason for this is the difference in the number of patterns that exist in the training set for each question type. Also, in each fold the memory cells are chosen randomly, so sometimes the patterns that are chosen for a type may increase or decrease the other types. There are no common measurement units for the automatic question generation problem. Most systems use manual evaluation of experts and some other use the measures of precision, recall, and f-measure to measure the acceptability of the system concerning the generated questions. In this research, since the question patterns of the test sentences are prepared, so we can use the precision, recall, and f-measure. Table 6 and figure 4 illustrate the precision, recall, and f-measure for each generated question type used in this research. The precision of the generated questions for when, Where, and Why increases to 90% of their tested patterns while results for How and Who are below this percentage. Increasing the patterns for the latter two types may increase the percentage of generated questions for those types. Table 6. Precision, recall, and F-measure for each generated question type. Question Type Precision Recall F-Measure Who 0.818 0.9 0.857 How 0.886 1 0.939 Why 0.909 0.882 0.896 When 0.917 0.772 0.838 Where 0.941 1 0.970 From table 6, it is shown that Where, When, and Why have the highest precision values and have the highest percentage of the truly generated questions. Therefore, as the precision value increases for the question type, the percentage of the truly generated questions increases. VII. Conclusion And Future Work This research introduces a novel Automatic question Generation model based on a learning model that is based on the meta-dynamics of the Artificial Immune System. The learning model depends on mapping the input sentence into a pattern, the attributes of the pattern depends on the output of two important natural language processing models; the SRL and NER are the two NLP models which build the pattern of the sentence. The training phase generates the classifier based on the clonal selection algorithm inherited form natural immunology. The meta-dynamics of the clonal selection which apply cloning and mutation for the highly stimulated patterns leads to building a strong classifier which is able to classify new patterns with accuracy greater than 95%. The classification ratio obtained proves the power of artificial immune system in multi-classes classification problem. Hence, the first contribution of this research is building a learning model for identifying the question type. Our second contribution is proposing a new methodology for generating the question. Preserving the question patterns during the training with the memory cells which constitute the classifier is the idea used to generate a question pattern for the new test pattern. The percentage of true generated patterns increases to 87% which appears to be promising when compared to other techniques used in generating questions automatically. Most related systems use a set of predefined rules that makes syntactic transformation form sentence to a question as in [6] and [7]. The percentage of the true generated questions reflects the power of both SRL and Fig.4. Precision, Recall. And F-measure for all question types NER in recognizing the semantic attributes of a sentence to be used in the AQG problem. In the future, we plan to introduce a set of enhancements by taking into account the syntax information of the sentence besides the semantic information used. It is planned to increase the training sentences and question types used such as What, Which, How many and How long questions. We will also attempt to enhance the classification accuracy by hybridizing the clonal selection with genetic algorithm. Increasing the classification accuracy may lead to increasing the truly generated patterns.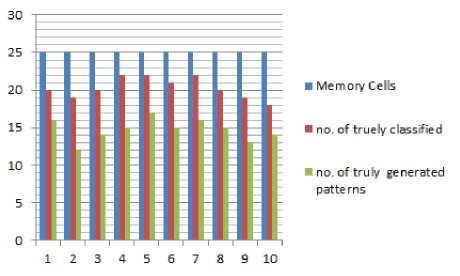
References Semantic Question Generation Using Artificial Immunity
- L.Bednarik and L.Kovacs, “Implementation and Assessment of the Automatic Question Generation Module,” CogInfoCom 2012. 3rd IEEE International Conference on Cognitive info communications. December 2-5, 2012. Kosice, Solvakia, “DOI:10.1109/CogInfoCom.2012.6421938”.
- V. Rus, Z. Cai, and A. Graesser, “Question Generation: Example of A Multi-year Evaluation Campaign,” In Proceedings of 1st Question Generation Workshop, September 25-26, 2008, NSF, Arlington, VA.
- S. Kalady, A. Elikkottil, and R. Das, ”Natural Language Question Generation using Syntax and Keywords,” In Proceedings of QG2010: The Third Workshop on Question Generation, pages 1–10, 2010.
- A. Varga, and L.Ha, “Wlv: A Question Generation System for the Qgstec 2010 Task B,” In Proceedings of QG2010: The Third Workshop on Question Generation, pages 80–83, 2010.
- J. Wolfe, “Automatic question generation from text-an aid to independent study,” In ACM SIGCUE Outlook, volume 10, pages 104–112. ACM, 1976.
- H. Ali, Y. Chali, and S. Hasan, “Automation of question generation from Sentences,” In Proceedings of QG2010: The Third Workshop on Question Generation, pages 58–67, 2010.
- P. Mannem, R. Prasad, and A. Joshi, “Question generation from paragraphs at upenn: Qgstec system description,” In Proceedings of QG2010: The Third Workshop on Question Generation, pages 84–91, 2010.
- X. Yao, and Y. Zhang, “Question generation with minimal recursion semantics,” In Proceedings of QG2010: The Third Workshop on Question Generation, pages 68–75. Citeseer, 2010.
- A. Copestake, D. Flickinger, D. Pollard, and I. Sag,” Minimal recursion semantics: An introduction,” Research on Language and Computation, 3(2-3):281–332, 2005.
- Z. Cai, V. Rus, H. Kim, S. C. Susarla, P. Karnam, and C. A. Graesser, “Nlgml: A markup language for question generation,” In Thomas Reeves and Shirley Yamashita, editors, Proceedings of World Conference on E-Learningin Corporate, Government, Healthcare, and Higher Education 2006, pages 2747–2752,Honolulu, Hawaii, USA, October 2006. AACE.
- W. Wang, T. Hao, and W. Liu, “Automatic Question Generation for Learning Evaluation in Medicine,“ Advances in Web Based Learning- ICWL 2007(2008), 242-251.
- N. L. Decastro, "Immune Cognition, Micro-evolution, and a Personal Account on Immune Engineering," S.E.E.D. Journal (Semiotics, Evolution, Energy, and Development). Universidad de Toronto, 3(3). 2003.
- D. Dasgupta, "Advances in Artificial Immune Systems," IEEE Computational intelligence magazine, November 2006.
- F. S. Mohsen, and A. S. Mohammad, “AISQA: An Artificial Immune Question Answering System,” I.J.Modern Education and Computer Science, 2012, 3, 28-34, “DOI: 10.5815/ijmecs.2012.03.04”.
- N. L. Decastro, and J. F. Von Zuben “Learninig and Optimization Using Clonal Selection Principle,” IEEE Transactions on Evolutionary Computation, Vol. 6, No. 3, June 2002.
- I.Fattoh, A. Aboutable, and M.Haggag, “Sematic Attributes Model for Automatic Generation of Multiple Choice Questions,” International Journal of Compute Applications, Vol 103(1). 18-24, October 2014, “DOI: 10.5120/18038-8544”.
- L. Pizzato, and D. Molla,”Indexing on Semantic Roles for Question Answering,” Coling 2008: Proceedings of the 2nd workshop on Information Retrieval for Question Answering (IR4QA). pages 74–81. Manchester, UK. August 2008.
- M. Palmer, D. Gildea, and P. Kingsbury, “The proposition bank: An annotated corpus of semantic roles,” Computational Linguistics, 31(1):71–106, 2005.
- M. Tkachenko, and A. Simanovisky, “Named Entity Recognition: Exploring Features,” Proceedings of KONVENS 2012 (Main track: oral presentations), Vienna, September 20, 2012
- L. Ratinov, and D. Roth, “Design Challenges and Misconceptions in Named Entity Recognition,” CoNLL (2009)
- V. Punyakanok, D. Roth, and W. Yih, “The Importance of Syntactic Parsing and Inference in Semantic Role Labeling,” Computational Linguistics (2008).
