Семантический подход к визуализации научных документов с использованием веб-графики 3D

Автор: Золотарев Олег Васильевич, Шарнин Михаил Михайлович, Мацкевич Андрей Георгиевич, Клименко Станислав Владимирович
Рубрика: Управление сложными системами
Статья в выпуске: 2, 2018 года.
Бесплатный доступ
В статье описывается семантический подход к визуализации 3D-киберпространства научных работ и их исследований с использованием веб-3D-графики. Наиболее цитируемые и значимые документы в этом киберпространстве отображаются сферами большого размера, а расстояние между документами - пропорционально их смысловому сходству. Предложена новая мера семантического подобия документов, которая определяется максимальной корреляцией между явной и неявной связностью документов. Предложен и внедрен новый индекс контекстного цитирования документов (SCCI), который определяется по максимуму корреляции с индексом научного цитирования (SCI). SCCI может более точно измерять научную значимость документов, находить важные документы и оценивать новые статьи с нулевым SCI. Значимые научные статьи подтверждают друг друга и образуют кластеры в киберпространстве. В результате исследования формируется набор таких кластеров. Предлагаемое киберпространство, реализованное в WebVR и с помощью интерактивной 3D-графики, можно рассматривать как динамичную среду обучения, которая удобна для обнаружения новых значимых статей, идей и тенденций.
Киберпространство, веб-3d-графика, научные статьи, семантическое сходство, индекс контекстного научного цитирования, неявные ссылки, интеграция информации, визуализация
Короткий адрес: https://sciup.org/148309493
IDR: 148309493 | УДК: 681.3.07 | DOI: 10.25586/RNU.V9187.18.06.P.46
Semantic approach to visualization of scientific documents using 3D web graphics
Keywords: cyberspace, WebVR, scientific papers, semantic similarity, science contextual citation index, implicit links, information integration, visualization, web-based 3D graphic
Текст научной статьи Семантический подход к визуализации научных документов с использованием веб-графики 3D
Кибернетические миры и виртуальная реальность (ВР) часто используются в образовательных и исследовательских целях. VR – это, по сути, компьютерная реальность, также называемая киберпространством, виртуальной средой, симуляциями и искусственными мирами [1].
В этой статье мы описываем семантический подход к визуализации 3D-киберпространства научных работ и их исследований с использованием веб-3D-графики. Наиболее цитируемые и значимые документы в этом киберпространстве представлены сферами большого размера, а расстояние между документами – пропорционально их смысловому сходству. В этом киберпространстве фронт исследований может существовать как набор кластеров значимых документов.
Концепция исследовательского фронта была первоначально введена Прайсом [15] как совокупность статей, которые активно цитируют ученые. Для ученых и аналитиков необходимо понимание динамики исследовательского фронта, чтобы они могли идентифицировать новые тенденции и внезапные изменения в теле научных знаний. В этой статье мы разрабатываем концепцию исследования, предлагая учитывать как явные, так и неявные связи между документами. Более подробно наша концепция исследования фронтов описана в разделе 2.
В этой статье мы предлагаем трехмерное пространство научных работ, аналогичное созвездию Chaomei Chen [2; 3; 4], но имеющее улучшенные функции визуализации и смысловую точность. В последние годы был достигнут значительный прогресс как в разработке новых инструментов визуализации, таких, как WebVR [8], так и в анализе семантического подобия. Интерес к смысловому текстовому сходству постоянно растет. Например, Международный семинар по семантической оценке 2016 года увеличил число команд на 45% по сравнению с 2015 годом. На этой конференции методы Word2Vec [9; 11] и WMD [12] часто использовались для оценки семантического подобия текстов [22–24]. Метод Word2Vec оценивает семантическое сходство разных слов, в то время как метод WMD способен оценивать семантическое сходство разных фраз без общих слов. Метод Doc2Vec [10] позволяет встраивать слова и документы в общее семантическое векторное пространство.
Чтобы найти наиболее важные научные статьи, широко используется индекс научного цитирования (SCI). У SCI много недостатков, и он не подходит для изучения новых статей, которые представляют наибольший интерес для ученых. Чтобы преодолеть эту проблему, мы предлагаем новую меру, называемую индексом контекстного научного цитирования (SCCI), описанного в разделе 6. Также в этом документе предлагается новый подход для измерения семантического подобия документов, описанный в разделе 5.
Предлагаемое семантическое киберпространство научных работ, реализованное в WebVR и посредством интерактивной 3D-графики, можно рассматривать как динамичную среду обучения, которая удобна для обнаружения новых значимых статей, идей и тенденций.
Кроме того, следует отметить, что предлагаемое киберпространство может быть мощным инструментом интеграции информации, поскольку позволяет визуализировать документы разных языков в одном пространстве, если мера семантического сходства достаточно развита и поддерживает многоязычие.
II. Визуализация исследовательских направлений
Концепция исследовательского фронта была первоначально введена Прайсом [15] как совокупность статей, которые активно цитируют ученые.
Если мы определяем исследовательский фронт как текущее состояние специальности (т.е. линию исследований), то исследовательский фронт формирует его интеллектуальную базу. Специальность может быть концептуализирована как временное отображение Ф( t ) исследуемого фронта Ψ( t ) в интеллектуальную базу Ω( t ) [14].
В нашем подходе мы далее разрабатываем концепцию исследовательского фронта и предлагаем учитывать как неявные, так и формальные ссылки между статьями. Неявные ссылки вычисляются на основе меры семантического сходства, описанной в разделах 5 и 6. Неявная ссылка – это ссылка на автора или его идеи в тексте. Идея представляется как набор фраз с аналогичным значением. Фразы, представляющие идеи в текстах статей, образуют вместе систему неявных ссылок. Использование неявных ссылок вместе с формальными ссылками делает алгоритм более чувствительным и позволяет более детально исследовать фронт исследования.
-
III. Визуализация многомерных данных
В этой статье мы предлагаем трехмерное семантическое киберпространство научных работ, в котором документы представлены сферами, а расстояние между документами – пропорционально их смысловому сходству. Мы также предлагаем новую меру семантического сходства документов. Если мы вычислим семантическое сходство между всеми документами ( N ) в корпусе, то получим матрицу N × N взаимных расстояний. Для визуализации документов в трехмерном пространстве нам нужно преобразовать эту матрицу в размер N × 3 и создать трехмерную визуальную карту. Это отображение матрицы взаимных расстояний в 3D неизбежно приводит к искажениям (неточностям) для размеров матриц более 4 × 4. Эта проблема правильной визуализации семантического подобия из-за большой размерности семантического векторного пространства может быть частично решена специальными методами уменьшения размерности и метода t -SNE.
В течение последних нескольких десятилетий было предложено множество методов визуализации многомерных данных. T-SNE – один из самых популярных алгоритмов сокращения размерности сегодня. Существует много модификаций, описанных в Интернете. T-SNE сохраняет большую часть локальной структуры многомерных данных, а также раскрывает глобальную структуру. Этот метод широко используется, поскольку после моделирования похожие объекты располагаются близко друг к другу, в то время как менее похожие – далеко друг от друга.
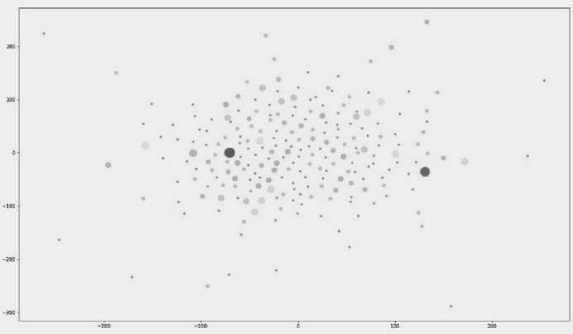
Рис. 1. 2D-карта визуализации корпуса текстов
В зависимости от размера визуализации (2D, 3D) используются разные методы. Если визуальная карта плоская, достаточно использовать стандартные инструменты визуализации Python, например библиотеку matplotlib.
В этой статье рассматривается корпус документов по компьютерной графике с заранее рассчитанной оценкой и мерой сходства. Корпус состоит из 230 статей. Каждая статья представлена в виде вектора смысловых мер сходства с другими статьями. Рейтинг каждой статьи равен числу цитат из других статей. Чем больше рейтинг (количество цитат) статьи, тем больше размер точки. Полученная двумерная визуальная карта статей представлена на рис. 1.
-
IV. WebVR визуализация 3D-карты
Мы используем технологию WebVR для создания трехмерной визуальной карты корпуса компьютерной графики на основе результатов алгоритма t -SNE. Технология WebVR позволяет поворачивать 3D-модель, просматривать ее под разными углами и тем самым создавать более полную картину структуры текстового корпуса.
Команда Mozilla VR разработала A-Frame в середине 2015 года. A-Frame – это структура WebVR, которая упрощает и ускоряет реализацию виртуальной реальности, позволяя вам кодировать HTML без необходимости знать мощный, но сложный WebGL [21]. A-Frame является открытым исходным кодом и в основном поддерживается Mozilla и сообществом WebVR. Это система компонентов компонента для Three.js, где разработчики могут создавать сцены 3D и WebVR с использованием HTML.
На рис. 2 представлена трехмерная визуальная карта корпуса из 230 российских документов по компьютерной графике. Эта карта является одной из фотографий сцены виртуальной реальности, которая была построена с использованием технологий WebVR и A-Frame.

Рис. 2. 3D-визуальная карта корпуса из 230 российских документов по компьютерной графике
V. Новая мера семантического сходства
В этой статье мы предлагаем новую меру семантического сходства, основанную на соотношении явных и неявных связей. Эта корреляция была впервые обсуждена в работе «Об основных типах связи между текстовыми документами» [6], где рассматривается вопрос о связности двух текстов естественного языка на основе их текстовых признаков (фрагментов). Выявлены два типа связности: явная (формальная) связь, когда тексты связаны библиографическими ссылками, и неявная связь, когда тексты связаны через общие текстовые фрагменты. Эксперимент проводился с использованием корпуса компьютерной графики из 120 связанных статей; каждая из них цитируется или имеет библиографическую ссылку на другую статью в этом корпусе. На основе эксперимента показано, что оба типа связности коррелированы. Оптимальные параметры обработки текста обнаруживаются, когда корреляция максимальна и достигает около 55%. Результаты эксперимента показаны на рис. 3, где вертикальная ось представляет собой корреляцию, тогда как горизонтальная ось представляет количество букв в пороге длины текстового фрагмента. Из рисунка видно, что корреляция достигает максимума на пороге 7.
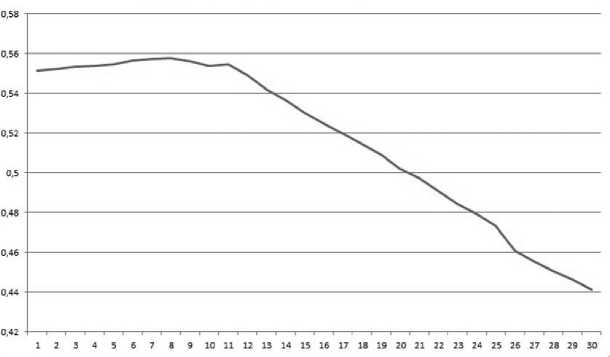
Рис. 3. Корреляция между явной и неявной связностью в зависимости от порога длины текстового фрагмента
Преимущество такого подхода заключается в том, что он не требует ручной работы экспертов для оценки связности и сходства текстов. Вместо этого этот подход основан на более авторитетном мнении ученых, которое выражается в библиографических ссылках и в значении индекса научного цитирования.
-
VI. Индекс контекстного научного цитирования (SCCI)
В этой статье мы предлагаем Индекс контекстного научного цитирования (SCCI), который определяется количеством и качеством неявных ссылок на статью. Параметры алгоритма обнаружения неявных ссылок определяются максимальной корреляцией между явными и неявными ссылками. SCCI полезен для визуализации новых документов, так что более значимые и влиятельные документы могут быть представлены большими размерами. Обычно индекс научного цитирования (SCI) используется для обнаружения значимых научных документов, но SCI не может анализировать новые документы с нулевым SCI. Поэтому необходимость совершенствования SCI для наших целей самоочевидна. SCCI способен анализировать новые документы, потому что он более чувствителен, чем SCI. SCCI рассчитывается путем анализа текста статьи и сравнения его с текстами других статей с использованием меры семантического сходства. Алгоритм вычисления SCCI строится путем выбора оптимальных параметров обработки текста, которые обеспечивают максимальную корреляцию между SCCI и SCI. Таким образом, можно сказать, что SCCI является дальнейшим развитием SCI. Первая реализация SCCI уже выполнена и проверена с использованием корпуса компьютерной графики.
Таким образом, использование SCCI помогает нам решить задачу построения более реалистичных кибермиров, найти более важные статьи и более точно отразить семантическое сходство между ними.
VII. Выводы
В статье описывается семантический подход к визуализации 3D-киберпространст-ва научных работ и их исследовательского фронта с использованием веб-3D-графики. Предложена модель киберпространства, в которой научные статьи представлены сферами разных размеров в соответствии с их значением и влиянием. Эта модель позволяет построить более реалистичное киберпространство научных работ для улучшения и облегчения научных исследований и разработки новых возможностей в динамичной учебной среде.
Мы благодарны Российскому фонду фундаментальных исследований за финансовую поддержку наших проектов.
Список литературы Семантический подход к визуализации научных документов с использованием веб-графики 3D
- Patel, H., Cardinali, R. Virtual Reality Technology in Business // Management Decisio. - 1994. - Vol. 32. - Issue: 7. - Pp. 5-12.
- Chen, C. Structuring and visualizing the WWW with Generalized Similarity Analysis // Proceedings of the Eighth ACM Conference on Hypertext (Hypertext'97). - Southampton. - 1997. - June. - UK. - Pp. 177-186.
- Chen, C. Visualization of knowledge structures. Handbook of Software Engineering and Knowledge Engineering, 2002.
- Dodge, M., Kitchin, R. Mapping Cyberspace. - Routledge, London, 2000.
- Grobelnik, M., Mladenić, D. Visualization of news articles // Informatica Journal. - 2004. - Vol. 28. - No. 4. - Pp. 375-380.
