Синтаксический анализатор HTML в браузерах

Бесплатный доступ
В данной статье рассмотрен основной этап синтаксического анализа html-документов в браузерах - построение DOM-дерева.
Синтаксический анализ, синтаксический анализатор, браузер, dom-дерево
Короткий адрес: https://sciup.org/140286905
IDR: 140286905 | УДК: 004.622
HTML parser in browsers
This article is devoted to main step of html parsing in browsers that is DOM-tree creating.
Текст научной статьи Синтаксический анализатор HTML в браузерах
Задача синтаксического анализатора HTML – разобрать исходный текст HTML файла и на его основе построить синтаксическое дерево. К сожалению, ни один из стандартных анализаторов не подходит для языка HTML. HTML невозможно определить с помощью контекстно-свободной (бесконтекстной) грамматики, с которой работают автоматические синтаксические анализаторы. Существует формальный стандарт определения HTML – формат DTD (Document Type Definition), однако его грамматика не является бесконтекстной.
На первый взгляд это может показаться странным, так как язык HTML во многом схож с XML; кроме того, оба этих языка произошли от стандартного обобщенного языка разметки SGML. В ходе развития технологий разработки web-документов язык HTML совершенствовался и, начиная с версии HTML4, перестал полностью соответствовать структуре языка SGML. Кроме того, синтаксис языка перестал быть строгим: вместе с развитием Интернета браузеры научились исправлять за разработчиками разного рода ошибки, например, потерянные теги (открывающие или закрывающие). Все эти нововведения привели к тому, что для современного HTML становится очень сложно формально определить грамматику. Таким образом, грамматика HTML не является контекстносвободной, поэтому его анализ нельзя выполнить ни с помощью стандартно сгенерированных анализаторов, ни с помощью анализаторов для языка XML.
Полученное синтаксическое дерево называют DOM-деревом. DOM – объектная модель документа (Document Object Model) – служит для описания структуры и представления HTML-документа. Кроме того, DOM-дерево является главным интерфейсом взаимодействия для внешних объектов, таких как Javascript код.
Модель DOM практически идентична разметке. Рассмотрим небольшой пример разметки (рис. 1):
Hello World
Vp>
Рисунок 1 - HTML-код
На рисунке 2 представлено DOM-дерево для данной разметки.
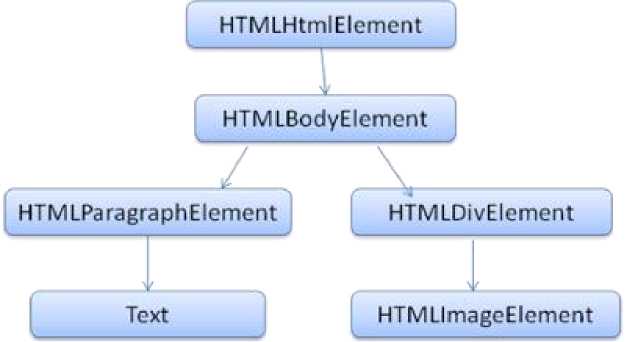
Рисунок 2 - DOM-дерево
Спецификации DOM, как и сам язык HTML, разрабатывает World Wide Web Consortium (W3C). Это универсальная спецификация для работы с документами. В специальном модуле описаны элементы, характерные для HTML. Под словами "дерево содержит узлы DOM" подразумевается, что дерево состоит из элементов, которые реализуют один из интерфейсов DOM. В браузерах применяются специфические реализации, обладающие дополнительными атрибутами для внутреннего использования.
Рассмотрим этапы создания дерева для следующего примера (рис. 3):
Пустой документ
Рисунок 3 - Пример HTML-кода
-
1. Начальное состояние анализатора – исходное состояние: последовательность токенов, полученная в результате лексического анализа;
-
2. Анализатор получает токен "html". Состояние меняется на "до html", после чего токен обрабатывается еще раз, но уже в новом состоянии;
-
3. Анализатор создает элемент HTMLHtmlElement и добавляет его к корневому объекту Document. Состояние меняется на " до head";
-
4. Анализатор получает токен "body". Несмотря на то, что в коде нет тега "head", элемент HTMLHeadElement будет автоматически создан и добавлен в дерево, так как элемент "head" является обязательным. Состояние меняется на "внутри head" и сразу же на "после head". После повторной обработки токена "body" элемент HTMLBodyElement создается и добавляется в дерево. Состояние меняется на "внутри body";
-
5. Анализатор получает первый токен строки "Пустой документ", что ведет к созданию узла Text и добавление его к объекту HTMLBodyElement. Далее к созданному узлу добавляются остальные символы;
-
6. Анализатор получает закрывающий токен "body". Состояние
-
7. Анализатор получает закрывающий токен "html". Состояние
-
8. Как только будет получен токен конца файла (EOF), анализ завершается.
меняется на "после body";
меняется на "после после body";
Список литературы Синтаксический анализатор HTML в браузерах
- Garsiel, T. How Browsers Work: Behind the scenes of modern web browsers / T. Garsiel, P. Irish. - Режим доступа: https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/ (Дата обращения: 31.05.2019)
