Sintaksička analiza kao centralna faza u radu kompilatora

Free access
Kompilator se projektuje kao modularan i dobro strukturiran programski sistem. Proces kompilacije, u logičkom pogledu, podeljen je na etape, a svaka etapa na faze. U fizičkom pogledu, proces kompilacije se deli na prolaze. Dve glavne etape procesa kompilacije su analiza i sinteza, one čine samo jezgro procesa kompilacije. U ovom radu obrađena je faza analize – sintaksička analiza.
Short address: https://sciup.org/170204295
IDR: 170204295 | UDC: 004.4'422
Text of the scientific article Sintaksička analiza kao centralna faza u radu kompilatora
Vesna Simovic, dipl. matematicar
Visoka ekonomska skola strukovnih studija Pec u Leposavicu
Rezime: Kompilator se projektuje kao modularan i dobro strukturiran programski sistem. Proces kompilacije, u logickom pogledu, podeljen je na etape, a svaka etapa na faze. U fizickom pogledu, proces kompilacije se deli na prolaze. Dve glavne etape procesa kompilacije su analiza i sinteza, one cine samo jezgro procesa kompilacije. U ovom radu obradena je faza analize - sintaksicka analiza.
UVOD
Jedan program moze biti zapisan u razlicitim notacijama, u razlicitim programskim jezicima. Uloga kompilatora je da transformiše tekst programa iz reprezentacije na visokom programskom jeziku, koja je citljiva coveku, u ’’citljivu” za racunar, sto omogucava eventualno izvrsavanje programa.
U osnovi, kompilacija je jedna vrsta prevodenja: na osnovu teksta koji je napisan u višem programskom jeziku i koji opisuje neki algoritam, treba sastaviti novi tekst, koji opisuje isti algoritam, ali na mašinskom jeziku mašine za koju se programiralo. U ovom smislu, kompilacija se sastoji u citanju niske karaktera koja je sastavljena u skladu sa izvesnim sintaksickim pravilima, sa ciljem da se konstruise jedna drugacija reprezentacija informacije koju ti karakteri izrazavaju.
Sintaksicka analiza je faza rada kompilatora, koja pripada etapi analize izvornog koda. Tokom analize se izvorni program prevodi u podesnu posrednu reprezentaciju, koja prikazuje strukturu izvodnog programa. U sintaksickoj analizi se ispituje i rekonstruiše struktura programa kao celine na osnovu niza tokena koje prosleduje leksicki analizator.
1. Sintaksicki analizator
Faza sintaksicke analize, koju obavlja sintaksicki analizator, je kljucni deo u radu prednjeg procesora, a i kompilatora u celini. 1 Sintaksicki analizator na ulazu prima tokene koje mu upucuje leksicki analizator i proverava njihovu saglasnost sa sintaksickim pravilima analiziranog jezika. Pravila gramatike su zadata nekom kontekstno slobodnom gramatikom. Na osnovu ovoga, sintaksicka analiza je proces utvrdivanja da li se zadata rec jezika moze generisati gramatikom ili ne. Tokom provere saglasnosti sa sintaksickim pravilima, sintaksicki analizator gradi drvo sintaksicke analize i priprema fazu prevodenja polaznog jezika na medujezik. Pored ovih osnovnih funkcija, sintaksicki analizator obraduje i eventualne sintaksicke greske koje su se pojavile na ulazu.
Gramatike su osnovni alati u specifikaciji jezika, one imaju nekoliko važnih aspekata. Prvo, gramatika služi da postavi strukturu u linearan niz tokena koji su u programu. Drugo, koristeci tehike iz polja formalnih jezika, gramatika moze biti zaduzena da konstruse sintaksicki analizator automatski. Ovo je velika pomoc u konstrukciji kompajlera. Trece, gramatike pomazu programerima da pisu sintaksicki ispravne programe i
Sintaksicka analiza kao centralna faza u radu kompilatora obezbede odgovore na detaljna pitanja o sintaksi. Tu istu pomoc pružaju i u konstrukciji kompajlera. 2
Postoje tri opsta tipa sintaksickog analizatora za gramatike. 3 Univerzalna metoda sintaksicke analize kakva je Cocke-Younger-Kasami algoritam i Earley-ev algoritam koji mogu da analiziraju bilo koju kontekstno slobodnu gramatiku. Ove metode su suviše neefikasne da bi se koristile u produkciji kompilatora. Metode koje se obicno koriste u konstrukciji kompilatora se klasifikuju kao metoda naniže (top-down) i metoda naviše (bottom-up). Kao što i sama njihova imena kažu, cvorovi drveta u ovim analizama se generisu nanize (od korena ka listovima) i navise (od listova ka korenu). U oba slucaja, ulaz u sintaksickom analizatoru se skanira s leva nadesno sa po jednim simbolom u jedinici vremena.
Obe metode i nanize i navise su deterministicke metode. Intuitivno govoreci, deterministicki znaci da ne angazujemo pretrazivanje, vec svaki token dovodi sintaksicki analizator jedan korak blize ciljnoj konstrukciji sintaksickog drveta. U teoriji formalnih jezika ova definicija je mnogo rigoroznija.
Deterministicke metode sintaksicke analize imaju vreme izvrsenja linearno zavisno od duzine unosa, tj. reda O ( n ) gde je n dužina ulaza. Nažalost, one ne rešavaju sve probleme linearnog analizatora jer rade samo za ogranicenu klasu gramatike. Gramatike ulaznih jezika imaju veoma male šanse da upravljaju deterministickom metodom, sem naravno ako konstruktor jezika napravio gramatiku koja odgovara ovom metodu.
lako je brzina sintaksickog analizatora od velikog znacaja, to nije jedini razlog što se insistira na determinizmu. Gramatika za svaki deterministicki sintaksicki analizator sigurno je odredena kao nedvosmislena, što je veoma važna osobina za gramatiku programskog jezika. Posto se proizvoljna gramatika cesto ne slaže sa gramatikom standardnih metoda sintakse, važno je imati tehnike za transformaciju gramatike kako bi bile odgovarajuce.
2. Principi metode naniže
Analiza nanize pocinje od pocetnog simbola gramatike, a tokom analize se postupno generise izvodenje nalevo niske koja se poredi sleva nadesno sa ulaznim nizom tokena. Poželjno je da ovo izvodenje bude takvo da je u svakom koraku moguce odrediti koje ce sledece pravilo biti primenjeno u izvodenju nalevo na osnovu tekuceg preduvidnog simbola. Pozeljno svojstvo gramatike je da se odluka o sledecem pravilu moze doneti na osnovu tacno jednog preduvidnog simbola, kako se nebi vracali unazad.
Gramatike bez vracanja unazad kod kojih je jedan preduvidni simbol dovoljan za odluku o sledecem pravilu u izvodenju ulevo su LL ( 1 ) -gramatike. Da li je neka gramatika LL ( 1 ) ne odreduje se neposredno, vec postoji algoritam kojim se to utvrduje. Ali ne postoji algoritam kojim bi se za proizvoljan jezik utvrdilo da li je LL ( 1 ) ili ne, tj. da li za njega postoji LL ( 1 ) gramatika. Ovo znaci da za proizvoljnu gramatiku nije moguce utvrditi da li je jezik koji se njome generise LL ( 1 ) . 4
Metod nanize pocinje konstrukcijom korena drveta koji je ujedno i pocetni simbol gramatike. Zatim se konstruise vrh poddrveta pre bilo kog njegovog nizeg cvora.
Kada analizator naniže konstruiše koren, obeležje korena, koje je ujedno i startni simbol gramatike, je vec poznato npr. N, ovo je tacno za koren i tokom analize trebamo utvrditi da li je tacno i za ostale cvorove. Koristeci informacije sa ulaza, sintaksicki analizator odreduje ispravnu alternativu za N, tako sto ima uvid u sledeci karakter — preduvidni simbol. Znajuci koja se alternativa primenjuje, znamo obelezja svih cvorova dece korena, cije je obelezje N. Analizator zatim konstruise prvi cvor dete za N, s tim sto vec zna njegovo obelezje. Proces odredivanja ispravne alternative za najlevlje dete se ponavlja na sledecim nivoima, dok najlevlje dete nije konstruisano kao završni simbol. Zavrsni cvor se tada ’’spaja’’ sa prvim tokenom t u programu. Ovo se ne desava slucajno: analiza nanize bira alternative za najlevlji cvor precizno.
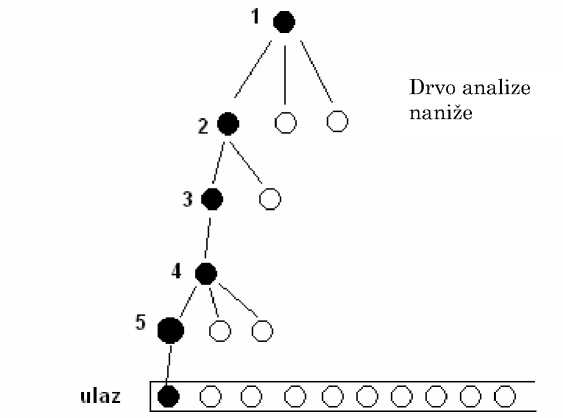
t 1 t 2 t 3 t 4 t 5 t 6 t 7 t 8 t 9 t 10
Slika 1 : Prepoznavanje prvog tokena sa ulaza od strane analizatora naniže
Analizator onda napusta zavrsni cvor i nastavlja sa konstrukcijom sledeceg cvora, ovo na primer moze biti drugo dete roditelja prvog tokena. Na slici je sa vecim punim krugom prikazan cvor koji je konstruisan kao zavrsni, manji puni krugovi predstavljaju cvorove koji su konstruisani na putu do zavrsnog simbola, a prazni krugovi predstavljaju cvorove cija su obeležja poznata ali koja još nisu konstruisana. O ostatku drveta analize ništa se više nezna, pa taj deo nije ni prikazan. Dakle, glavna uloga analizatora naniže je da izabere ispravne alternative za cvorove koji nisu zavrsni, kako bi se dobio tacan završni simbol.
3. Principi metode naviše
Analiza naviše predstavlja pokušaj da se za ulaznu nisku tokena konstruise drvo sintaksicke analize polazeci od njegovih listova, postupnim svodenjem ka korenu. Postupak svodenja se sastoji u tome da se u pojedinim koracima analize, desna strana nekog pravila gramatike zameni njegovom levom stranom.
Metoda analize navise konstruise cvorove u drvetu sintakse tako što se vrh poddrveta konstruiše posle konstruisanja svih nižih cvorova. Kada se u analizi navise konstruise cvor, sva deca cvorovi su vec konstruisani, i prisutni su kao poznati, a i obelezje cvora je takode poznato. Analizator zatim kreira cvor, obelezje za njega i spaja ga sa decom.
Analiza navise uvek konstruise cvor koji je na vrhu prvog kompletnog poddrveta na koje se nailazi kada se vrši unos sleva nadesno. Kompletno poddrvo je drvo kod koga su sva deca vec konstruisana. Tokeni su razmatrani kao podrveta visine 1 i konsruisani su kako se sa njima sretalo. Novo poddrvo mora takode biti izabrano od nas kao poddrvo od drveta analize, ali
Sintaksicka analiza kao centralna faza u radu kompilatora ocigledan problem je sto jos uvek neznamo celo drvo analize, nego se ono tek konstruiše.
Deca prvog poddrveta se konstruišu samo kao listovi drveta, obeleženi kao završni, a ispravna alternativa je izabrana tako da se poklapa sa njima. Sledecem, drugom poddrvu u ulazu, osnovu predstavljaju sva deca cvorovi koji su vec konstruisani. Deca od ovih cvorova mogu da obuhvate i cvorove koji nisu listovi, a koji su kreirani ranijom konstrukcijom cvorova. Takav cvor ima odgovarajuce obelezje koje odgovara ispravnoj alternativi. Ovaj proces se ponavlja dok se sva deca najviseg cvora ne konstruisu, zatim se konstruise najvisi cvor i analiza je kompletna.
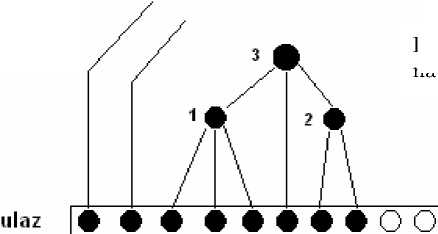
t 1 t 2 t 3 t 4 t 5 t 6 t 7 t 8 t 9 t 10
Drvo analize naviše
Slika 2 : Konstruisanje prvog, drugog i treceg cvora
Slika 2 prikazuje analizator posle njegovog konstruisanog (prepoznatog) prvog, drugog i treceg cvora. Veci puni krug prikazuje cvor koji se zadnji konstruisan, a manji puni krugovi cvorove koji su ranije konstruisani. Prvi cvor spaja tokene ta, t4 i ts, drugi spaja t? i ts, a treci spaja prvi cvor, token te i drugi cvor. O postojanju drugih cvorova jos se nista nezna, ali su grane za tokene t1 i t2 nacrtane naviše, jer znamo da one ne mogu biti deo manjeg poddtveta od ovog koje spaja tokene od t3 do t8. U suprotnom bi to poddrvo bilo prvo koje je konstruisano. Glavni zadatak analizatora navise je da ponovo pronade koren za poddrvo cija su deca vec konsruisana, i na kraju nade koren celog drveta analize.
Gramatike koje imaju svojstvo da se konflikti u analizi naviše mogu razrešiti na osnovu informacija o dotadašnjem toku analize i uvidom u odredeni broj preduvidnih simbola, cine klasu LR ( k ) -gramatika, gde k predstavlja broj preduvidnih simbola neophodnih za analizu. Znacajne crte LR ( k ) -gramatika na teorijskom planu su:
-
- postoji algoritam koji odlucuje da li je za dato k data kontekstno slobodna gramatika LR ( k ) ;
-
- bilo koji jezik koji je LR ( k ) , za zadato k , je i LR ( 1 ) .
Prednosti LR -gramatika se ogledaju i u sledecim crtama: 5
-
- za najveci deo konstrukata u programskim jezicima koji se mogu opisati nekom kontekstno slobodnom gramatikom, može se konstruisati i LR - analizator;
-
- klasa gramatika koje se mogu analizirati metodama LR analize, je pravi nadskup klase gramatika koje se mogu analizirati metodama analize naniže; i
-
- LR -analizatori otkrivaju sintaksicku gresku najranije moguce tokom skaniranj ulaza sleva nadesno.
Nedostatak metode LR -analize je što je potrebna prekomerna kolicina manuelnog rada za konstrukciju LR -analizatora realnog programskog jezika. Ovaj nedostatak se prevazilazi tako što postoje programski alati koji omogucavaju generisanje LR -analizatora.
-
5 Duško M. Vitas, Prevodioci i interpretatori (Uvod u teoriju i metode kompilacije programskih jezika), Matematicki fakultet, Beograd 2006, str. 195
ZAKLJUCAK
Sintaksicka analiza je faza u kojoj se ispituje i rekonstruise struktura programa kao celine na osnovu niza tokena koje prosleduje lesicki analizator. Sintaksicka analiza je centralna faza u radu kompilatora: ona upravlja radom leksicke analize i, pri tome, gradi strukturu na osnovu koje ce biti moguca semanticka analiza programa.
Ulaz za sintaksicku analizu predstavljaju tokeni, koje isporucuje leksicki analizator. Ova analiza podrazumeva analizu konteksta u kome se token pojavio. Na izlazu iz ove faze dobija se drvolika struktura kojom je predstavljena struktura programa.
Sintaksicki analizator mora biti u stanju da utvrdi na osnovu procitanih tokena sa ulaza da li oni predstavljaju deo jezika na kome je napisan program koji se kompilira ili ne. Ukoliko token, koji se upravo pojavio na ulazu, nije u skladu sa pravilima jezika, sintaksicki analizator ce pozvati podsistem za rad sa greškama.
References Sintaksička analiza kao centralna faza u radu kompilatora
- Duško M. Vitas, Prevodioci i interpretatori (Uvod u teoriju i metode kompilacije programskih jezika), Matematički fakultet, Beograd 2006.
- D. Grune, H. Bal, C. Jacobs and K. Langendoen, Modern compiler design, John Wiley & Sons, LTD.
- Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman, Compilers, Principles, Tehniques and Tools, Addison-Wesley publishing company,1986.
- Allen I. Holub,Compiler design in C, Prentice Hall software series, 1990.
- Andrew W. Appel, Modern compiler implementation in C, Cambridge University press, 1998.
- Alfred V. Aho, Jeffrey D. Ullman, The theorz of parsing, translation, and compiling, Volume I: Parsing, PrenticeHall, INC, 1973.
- Alfred V. Aho, Jeffrey D. Ullman, The theory of parsing, translation, and compiling, Volume II: Compiling, Prentice-Hall, INC, 1973.
