Система программно-алгоритмической поддержки мультилингвистической адаптивно-обучающей технологии

Автор: Карасева Маргарита Владимировна
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 4 (21), 2008 года.
Бесплатный доступ
Показано, что для разработки системы программно-алгоритмической поддержки многоязычной (мульти-лингвистической) адаптивно-обучающей технологии, кроме проектирования непосредственного программного компонента системы, необходима разработка информационно-терминологического базиса указанной технологии. В области аэрокосмической техники данный базис представляет собой коллекции электронных частотных профессионально-ориентированных многоязычных словарей, подключение которых к обучающей системе обеспечивает достаточный уровень проведения процесса обучения иностранной терминологической лексике. Для персонификации процесса формирования электронных частотных словарей необходим многоуровневый анализ мультилингвистической информации.
Мультилингвистическая адаптивно-обучающая технология, информационный базис, частотный словарь
Короткий адрес: https://sciup.org/148175751
IDR: 148175751
Multilingual algorithmic and software support system for adaptive-training technology
It is shown that for development of multilingual software-algorithmic support system for adaptive-training technologies, except designing the program component of system, is necessary the development of specified technology information-terminological basis. In the domain of aerospace technology the given basis presents the collections of electronic frequency professional-orientated multilingual dictionaries, connection which to training system provides the sufficient level of the foreign terminological lexicon education process. For personification of the electronic frequency dictionaries forming process is necessary deep analysis of multilingual information.
Текст научной статьи Система программно-алгоритмической поддержки мультилингвистической адаптивно-обучающей технологии
нической и производственной деятельности требует решения ряда задач, связанных с совершенствованием интегрированной подготовки элитных специалистов в области высоких технологий и современного менеджмента, а также развития гибкой многоуровневой системы непрерывного образования. Современные задачи персонификации информационного базиса в области аэрокосмической терминологии связаны, во-первых, с расширением профессиональных образовательных программ, учитывающих потребности развития предприятий аэрокосмической отрасли, гражданской авиации и высокотехнологичных производств. Во-вторых, указанные задачи непосредственно связаны со становлением университета в качестве полноправного участника мирового образовательного пространства на основе расширения международной академической мобильности преподавателей и студентов, организации подготовки иностранных студентов по программам высшего и послевузовского профессионального образования и международной аккредитации профессиональных образовательных программ.
В этих условиях профессионально-ориентированной языковой подготовке уделяется все более существенное внимание, а одним из важных ее аспектов становится повышение эффективности изучения многоязычной терминологической лексики в области аэрокосмической техники. На структуру и состав многоязычного информационно-терминологического базиса влияет и то, каким образом в вузе происходит формирование инновационной научно-образовательной системы. Более того, данная система является адаптивной к изменяющимся условиям среды и на основе современных образовательных технологий и структурной интеграции образования, науки и производства обеспечивает генерацию новых знаний и, как следствие, нового терминологического базиса, что важно для воспроизводственного цикла подготовки компетентных специалистов как в аэрокосмической, так и в других высокотехнологичных отраслях.
Ранее в [1] было показано, что проблема разработки системы программно-информационной поддержки многоязычной (мультилингвистической) адаптивно-обучающей технологии, кроме проектирования непосредственного программного компонента системы, включает и разработку информационного базиса указанной технологии. Этот базис представляет собой коллекции электронных частотных профессионально-ориентированных многоязычных словарей, подключение которых к обучающей системе обеспечивает должный уровень проведения процесса обучения иностранной терминологической лексике [1; 2]. При этом ключевыми этапами подготовки обучающей мультилингвистической (МЛ) информации являются, во-первых, анализ и обработка информации, которые приводят к формированию требуемых словарей, а во-вторых, структурирование и персонификация информации, частично осуществляемые непосредственно перед началом и в течение сеанса обучения [2].
Для персонификации процесса формирования электронных частотных словарей необходим многоуровневый анализ мультилингвистической информации [3]. Известно, что каждый языково-статистический анализ начинается с выбора и подготовки соответствующей тек стовой базы. Далее анализ следует осуществлять на уровне терминов.
При работе с лексикой иностранной научно-технической литературы наибольшую трудность для понимания и перевода представляют многокомпонентные термины терминологические словосочетания, созданные лексическим и синтаксическим способом и представляющие собой словосочетания, образованные по определенным моделям. Способ создания терминов в виде цепочки слов все шире входит в практику. Не является исключением и терминология аэрокосмической отрасли. Это происходит по объективным причинам, связанным с тем, что, во-первых, у любого языка существуют ограниченные ресурсы в плане лексических единиц и, во-вторых, результаты научно-технической революции приводят к новым открытиям и явлениям, требующим точных определений и наименований. Замечено, что в эпоху научно-технической революции пополнение лексики языка осуществляется в основном за счет специальной терминологии, которая является наиболее подвижной частью лексикосемантической системы языка; ежегодно такое увеличение составляет около 1 000 новых терминов.
Особую трудность при переводе представляют беспредложные терминологические словосочетания, которые могут нести больший объем информации, Они состоят из цепочки слов, не связанных между собой какими-либо служебными словами. В беспредложном терминологическом словосочетании главным словом является последнее, а все слова, стоящие слева от него, играют второстепенную роль роль определения. Перевод беспредложных терминологических словосочетаний следует начинать с главного слова (рис. 1).
-
1. life test
-
2. radio wave propagation
чего?
" N------------------ V срока службы испытание
Перевод: испытание на срок службы
каких? чего?
I N----------------- ▼ -«----------------- ”
радио волн распространение
Перевод: распространение радиоволн
Рис. 1. Пример перевода беспредложных терминологических словосочетаний
Терминологические словосочетания обычно классифицируются по их лексическому составу. Существуют терминологические словосочетания, состоящие из одних существительных, из прилагательных и существительных, а также из различных комбинаций причастий, существительных, наречий, герундия, инфинитивов и т. д.
Работа с научно-техническими текстами в предметно-ориентированных областях показывает, что наиболее частотными терминологическими словосочетаниями являются те, которые состоят из 2-3 компонентов, что является характерным для любой отраслевой терминологии. На практике встречаются и такие терминологические словосочетания, которые состоят из четырех и большего числа компонентов. Терминологические словосочетания позволяют передавать информацию в более сжатом виде, а тенденция к свертыванию речевого сообщения является характерным признаком стиля научно-технической литературы, в том числе и в аэрокосмической отрасли, поскольку в любом сообщении (высказывании) имеется определенная степень избыточности. Более того, терминологические словосочетания позволяют осуществлять межфразовые связи между предложениями и абзацами.
Анализ терминологических словосочетаний показывает, что их модели определяются числом компонентов, что, в свою очередь, влияет на мотивированность терминологического словосочетания.
Автором предлагается система автоматизированного анализа и обработки информации для формирования мультилингвистического базиса «Build Dictionary» [3]. При формировании словарей, кроме общеизвестных этапов анализа и обработки информации, включающих определение статистических элементов (слова, словосочетания, предложения), планирование контроля (выбор и определение выборочного пробы, установление абсолютной частоты элементов единичной выборочной пробы, расчет относительной частоты), изложение результатов в списках, таблицах или графиках и обобщение результатов, в данной системе реализован этап оптимальной разбивки информационно-терминологического базиса (ИТБ) на равновеликие модули. Модель оптимального разбиения ИТБ построена на основе теории цепей Маркова с использованием критерия минимальной суммарной трудоемкости.
Помимо этого, в рамках определенной предметной области выделены следующие процедуры, поддерживаемые разработанными средствами автоматизации.
-
1. Выбор текста (группы текстов), соответствующего предметной области составляемого частотного словаря, и его (их) частотный анализ. Например, для создания словаря по системотехнике и системному анализу в аэрокосмической отрасли выбираются электронные учебники, статьи, книги большого объема именно по указанной тематике для того, чтобыулучшить достоверность составляемого словаря. Здесь прослеживается закономерность: чем больше объем анализируемого текста, тем точнее получается словарь. Что касается вопроса об оптимальном объеме обрабатываемого текста (группы текстов), то рекомендуется рассматривать тексты объемом не менее 5 000 слов.
-
2. Отсев ненужных слов (это могут быть как предлоги, так и слова, не входящие в предметную область).
-
3. Просмотр оставшихся слов и сопоставление однокоренных, а также приведение всех слов к нужному виду. Например, такие слова как стола (в контексте «нет стола») и столы являются одним и тем же словом стол.
-
4. Сопоставление слов разных языков. Например, рассматривая данные слова, взятые из частотного словаря, одинаковые по значению, но разные по языковой принадлежности (topology - Topologie - топология), можно перевести два из них английский русский, немецкий -русский и потом сопоставить по общим полям или же можно сразу сопоставлять слова из разных языковых множеств. Второй метод наименее трудоемкий.
-
5. Непосредственный перевод несопоставленных слов.
После того как данный этап закончится, получается множество слов, отвечающих заданной предметной области на одном из изучаемых языков. Далее шаги 1-3 выполняются несколько раз (их количество обусловлено требуемой структурой частотного словаря) для других языков.
В связи с тем что разработанная система не привязана к какому-либо конкретному языку (или языкам), в ней не происходит автоматического поиска однокоренных слов.
Для сопровождения разработанной программы, согласно представленной выше структуре, необходим один администратор и один-два специалиста в выбранной предметной области для переводов слов (словоформ). Для работы системы используются ОС Windows 95 и выше, СУБД Microsoft Access 97 и выше, а также DBE Administrator. Кроме того, данная система поддерживает динамическую коррекцию словаря, подключение к сети Интернет и использование любых электронных текстов и стандартных двуязычных словарей.
Практическая реализация результатов работы представлена в сформированном трехъязычном словаре [4]. В результате проведенного статистического исследования и описания текстов по системному анализу в области аэрокосмической техники объемом около 30 000 слов был составлен список из 2 500 слов, адекватность которых была установлена для всех трех языков, а затем около 2 000 слов были включены в частотный словарь, являющийся непосредственным компонентом компьютерной системы, реализующей мультилингвистическую технологию. Так как почти все частотные словари одноязычны, что значительно снижает степень активности слова при его определенном значении в словарном минимуме, то был проведен анализ многоязычных текстов на систематическом уровне. Словарь организован как англо-немецко-русский, однако принцип его построения в виде мультилингвистической базы данных обеспечивает возможность использования его как двуязычного в любом выбранном варианте.
Представленная программа автоматизированного анализа и обработки мультилингвистической информации была принята в опытную эксплуатацию на факультете информатики и систем управления Сибирского государственного аэрокосмического университета имени академика М. Ф. Решетнева, в Сибирском институте бизнеса, управления и психологии и в Красноярском институте социальных наук, где она использовалась для подготовки информационного базиса системы «Virtual Teacher 1.0» для обучения терминологической лексике студентов ряда специальностей.
Очевидно, что правильность составления словарей, т. е. выбор терминов, и определение их частотных характеристик существенно влияет на эффективность работы алгоритма обучения [2]. Как уже было сказано выше, особенностью информационной базиса предложенной технологии прежде всего является многоязычность (муль- тилингвистичность) терминологических понятий [5]. Это приводит к тому, что базисный информационный компонент мультилингвистической технологии, являясь основой информационной модели данных, представляет собой совокупность многоязычных элементов обучающей информации и их частотных свойств.
Современные программно-алгоритмические средства разработки компьютерных обучающих систем требуют применения оригинальных методик при формировании информационной модели данных, используемых при обучении. В основном это методики, которые базируются на основных идеях структурного системного анализа и на структурных методологиях, относящихся к классу методологий, ориентированных на данные [1; 3]. Примером этого подхода является DSSD-методология (Data-Structured Systems Development), предложенная Варнье-Орром и ориентированная на разработку систем со структурными данными [5].
Так. терминологическое множество, соответствующее базисному информационному компоненту мультилингвистической обучающей технологии, может быть описано следующим образом:
МЛ-компонент = {терминяз_1. термин яз_2. термин яз_К частота яз_ 1, частота яз_2, ,,, частота яз_П}.
Структурная методология DSSD использует аналогичную нотацию - множественную скобку (рис. 2).
МЛкомпонен!
термин яз_1
термин яз_2
термин яз_П частота яз_1 частота яз 2
частота яз N
Рис. 2. Применение нотации DSSD к мультилингвистической технологии
При построении модели в DSSD используются диаграммы сущностей (DFD) для определения системного контекста и диаграммы Варнье-Орра (assembly-line diagrams) в качестве основного средства моделирования. Базовым элементом диаграммы Варнье-Орра является множественная скобка. Детализация элементов данных производится слева направо, а предполагаемая последовательность действий осуществляется слева направо и сверху вниз. Такая нотация удобна для представления композиции структур, определения структур данных, спецификации форматов файлов и может быть использована для иллюстрирования структуры программы и иерархии модулей (структур данных на модули или файлы, а на нижних уровнях - на подпрограммы. DO-циклы, условные и другие операторы), являясь в этом случае неким аналогом визуального языка проектирования типа FLOW-форм [4].
Таким образом, основные этапы методологии DSSD с помощью диаграмм Варнье-Орра позволяют определить логику обработки данных, продуцируя структуру программ обработки с целью реализации обучающих алгоритмов МЛ-технологни (рис. 3).
На этой диаграмме применены две базовые конструкции диаграмм Варнье-Орра: иерархия и последовательность. Они могут интерпретироваться следующим образом: МЛ-технология в качестве первого этапа содержит выбор сеансного состава МЛ-компонентов, в качестве второго этапа - определение характеристик и требований. в качестве третьего этапа обучение. Предлагаемая информационно-логическая организация МЛ-технологии фактически содержит этапы обработки информации.
выбор сеансного состава
МЛ-компонентов
альтернативное формирование БД; ранжирование БД; выбор БД;
характеристики и требования
обучение
на логическом уровне
на физическом уровне формирование _ альтернативного терминологического ряда адаптация параметров модели
частота; обученность;
скорость забывания;
модель обучаемого; достигаемая обученность;
термин яз 1;
термин яз N:
алгоритм; процедура; результат приложения;
Рис. 3. Диаграмма Варнье-Орра
На первом этапе при выборе сеансного состава МЛ-компонентов ставится задача непосредственной реализации словаря в виде мультилингвистической базы данных, включающей: альтернативное формирование базы данных (БД) с учетом соотношений терминов и их частот; ранжирование БД. т. е. отбор наиболее употребительных терминов; выбор сформированной БД для сеанса обучения.
На логическом уровне второго этапа определяются требования к частоте и обученности и характеристики, включающие начальные значения скорости забывания терминов. На физическом уровне второго этапа строится модель обучаемого и задается уровень достигаемой (в реальной обстановке) обученности.
На третьем этапе - этапе обучения формируется альтернативный набор терминов, образующий порцию обучающей информации. Формирование альтернативного терминологического ряда также находится на логическом уровне обработки информации. На физическом уровне этапа обучения происходит адаптация параметров модели обучаемого согласно алгоритму обучения, пошаговой процедуре и в итоге - в зависимости от результата обучения (значения критерия обучения).
Указанные выше этапы обработки обучающей информации и непосредственно адаптивный алгоритм обучения реализованы в системе «Virtual Teacher 1.0» [4]. к которой подключаются ранее сформированные мультилин-гвистические частотные словари. Данная система также успешно применена на практике как в Сибирском госу- дарственном аэрокосмическом университете имени академика М. Ф. Решетнева, так и ряде других вузов Красноярска.
Очевидно, что персонификация процесса адаптивного обучения, т. е. индивидуальная подготовка мультилин-гвистического словаря по определенной предметной области для конкретного пользователя, может быть осуществлена только при интеграции указанных систем, так как необходимое согласование информационной и функциональной моделей обучающей технологии достигает в этом случае высшего уровня. Система «Build Dictionary» [1]. направленная на формирование информационно-терминологического базиса в заданной пользователем предметной области и оптимальное разбиение базиса на блоки, интегрируется с обучающей системой «Virtual Teacher 1.0», в которой реализован алгоритм обучения, осуществляющий адаптацию параметров модели обучаемого с учетом индивидуальных свойств его памяти (рис. 4).
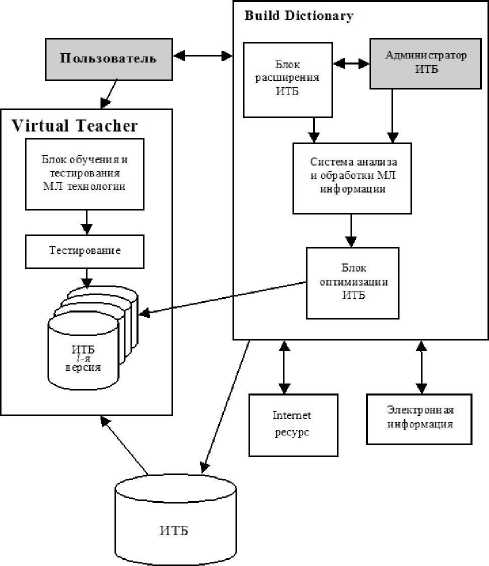
Рис. 4. Интеграция систем в мультилингвистической адаптивно-обучающей технологии
Таким образом, при тщательном подборе комплекса программ, а именно: программ обучения другим языковым навыкам, редактора текста со встроенной программой проверки орфографии, браузера Интернета, обычных электронных словарей и энциклопедий (особенно с интерфейсом на изучаемом языке, что обеспечивает более интенсивное погружение в иноязычную среду) - существует возможность создания компьютерной обучающей среды как интегрированного средства изучения иностранного языка на базе описанной выше системы.
Для разработанной компьютерной системы необходим один администратор и. как правило, два-три специалиста в выбранной предметной области для перевода слов и словоформ.
