Software model open computing language

Author: Zharlykasov B.J., Abatov N.T.
Journal: Экономика и социум @ekonomika-socium
Section: Информационные и коммуникативные технологии
Article in issue: 6-3 (25), 2016.
Free access
The article discusses the basic principles of design in accordance with the standard OpenCL 1.1. Without going into too much at this level of presentation details are 4 models on which standard holds: platform model, the execution, the memory model and programming model. The article is not given a single line of code, since the goal - only to introduce the reader into the world of the development on the OpenCL, highlighting various aspects of its design.
Short address: https://sciup.org/140124621
IDR: 140124621
Text of the article Software model open computing language
OpenCL is worth considering after realizing what a hardware and software architecture CUDA, because CUDA - this is a de facto standard, and OpenCL - it is still a new standard that is designed to develop a variety of applications for heterogeneous systems.
In OpenCL programming model based on the concept of core (kernel). Core - a function that will be executed in parallel on the accelerator certain number of threads. Kernel programmer defined as functions on some extension of the C language. Creating core is divided into several stages, each of which corresponds to the appropriate function call OpenCL on the CPU. In the beginning you want to convert the source code of one or more nuclei, given as a string array in OpenCLprogram, then the resulting program should be compiled for your device [1]. After compiling OpenCL - program from it can be obtained kernel functions corresponding to its source code.
To run the kernel on the accelerator you must specify its arguments. Core arguments can be either scalar values and address buffers in memory accelerator. Since, in general, the accelerator has no direct access to the memory of CPU cores are working with addresses in the memory of the accelerator. OpenCL provides a mechanism for allocating memory buffers on the accelerator and the exchange of data between memory and CPU accelerator.
Run the desired engine is carried out by calling the library OpenCL on the CPU. Accelerator, which will run the kernel, is given command queuing, which passed a request to perform kernel.
Platform model gives a high level description of a heterogeneous system.
The central element of this model is the notion of the host - the primary device that controls the OpenCL - performs all calculations and user interaction. Host is always present in a single copy, while OpenCL - devices that run OpenCL -instructions can be presented in the plural. OpenCL - the device can be CPU, GPU,
DSP or any other processor in the system, the system supports the establishment of OpenCL - drivers.
OpenCL - the device is logically divided into a model to compute units [2, 3], which in turn are divided into processing elements. Calculations on OpenCL -devices actually occur in the processing elements. In Figure 1 schematically depicted OpenCL - of the platform 3 devices.
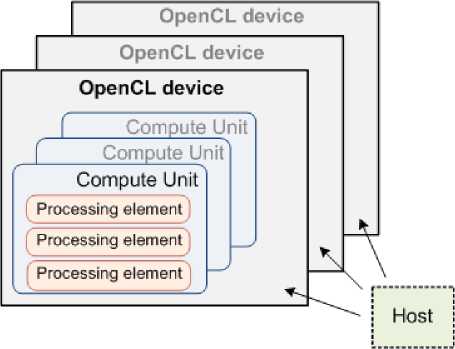
Figure 1. Logical device OpenCL
Execution model describes an abstract representation of how instruction streams are executed in a heterogeneous system.
The kernel is created in the host program and then using a special command is queued for execution in one of the OpenCL devices. During the execution of said instruction OpenCL Runtime System creates integer index space, each element of which is called the global identifier (global ID). Each instance of the kernel is done separately for each value of a global identifier . Engine instance is called work-item. Thus, each work-item is uniquely identified by its global identifier .
A plurality of work-item is divided into groups . Such a group is called a work-group. With each work-group referenced by its unique identifier (work-group ID). All work-item in a work-group uniquely identified within its group number : local ID. Thus, each work-item is defined as by a unique global ID or by a combination of work-group ID and local ID within their group .
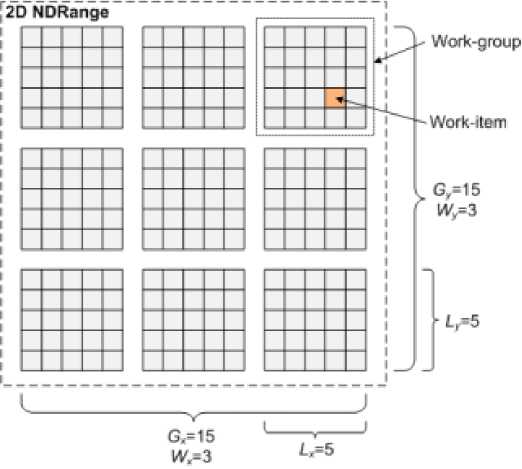
Figure 2. Example two-dimensional NDRange
All work-item within a work-group are executed in parallel processing elements on a single computing unit OpenCL-device. This is guaranteed by the standard, while absolutely no guarantee that a few work-item from different groups are performed in parallel. This important property of parallelism should always remember when developing OpenCL-programs. Space indexes N-dimensionally and commonly called NDRange. In the case of the standard version OpenCL 1.1 dimension N takes the values 1,2 or 3. Thus, the grid coordinates global ID and local ID N-dimension, ie, N coordinates are determined.
An illustrative example of a two-dimensional NDRange, shown in Figure 2, where Gx и Gy - by global identifiers, Wx и Wy - number of groups, а Lx и Ly -number of local identifiers in NDRange. Another important concept model of computation is the context, the definition of which (by calling special functions OpenCL API) is the first task OpenCL-application. Context determines the runtime cores, which includes the following components: the device core, program objects (program objects, source and executable code for future cores), memory objects.
If you draw a line between the CUDA and OpenCL and ask the obvious question that plagues many novice developers. And what actually better CUDA or OpenCL and answers may not be quite so straightforward. For starters, you can conduct a test, based on the simulation will be based on the evolution of the particle system. The result will be displayed as a number of FPS (frames per 1 second), but in this case the display will be turned off and FPS, will mean the number of iterations in one second. Thus the result is obtained as shown in Table 1.
Table 1. Comparative analysis
|
number of particles |
OpenCL FPS |
CUDA FPS |
|
2048 |
2147.2 |
2698.9 |
|
4096 |
883.3 |
1172.33 |
|
8192 |
348.21 |
501.67 |
|
16384 |
117.1 |
183.14 |
Before you jump to conclusions directly test, it should be noted that the test was done using the NVidia GeForce GTX 650Ti with updated drivers (relevance February 2014 - not a beta version), the characteristics of the graphics card have been exposed to a minimum.
Now directly to the results. This test was won by CUDA, which was not surprising, since CUDA is by far the best product in this area, but this does not mean that you should not use OpenCL. Already at this stage it is worth noting that because OpenCL also shows good results, and this can only mean one thing - the leader CUDA present opponent (in fact he is not one), which seeks to become a leader in this sector. And in the future, these aspirations must bring new fruit development as another performance boost.
References Software model open computing language
- Munshi A., Gaster B., Mattson T, Fung J., Ginsburg D., OpenCL Programming Guide, Издательство: Addison-Wesley Professional, 2011 г. -648 с.
- Spinellis D., Code Reading: The Open Source Perspective, Издательство: Вильямс, 2004 г. -528 с.
- Кормен Т. X., Лейзерсон Ч. И., Ривест Р. Л., Штайн К. Алгоритмы: построение и анализ, 2-е издание.-М.: Изд.дом "Вильямс", 2005 г. -736 с.
