Сопоставление библиотек для создания моделей машинного обучения на основе методов градиентного бустинга

Автор: Д. С. Пономарев
Журнал: Современные инновации, системы и технологии.
Рубрика: Управление, вычислительная техника и информатика
Статья в выпуске: 5 (2), 2025 года.
Бесплатный доступ
В статье проводится сравнительный анализ современных библиотек для построения моделей машинного обучения на основе методов градиентного бустинга: CatBoost, XGBoost и LightGBM. Рассмотрены их ключевые особенности, преимущества и недостатки, включая обработку категориальных признаков, скорость обучения, потребление памяти, устойчивость к переобучению и требования к настройке гиперпараметров. Особое внимание уделено алгоритмам, лежащим в основе каждой библиотеки, а также их математическому аппарату, включая функции потерь и методы регуляризации. На основе проведенного анализа сделаны выводы о целесообразности выбора той или иной библиотеки в зависимости от специфики задачи, структуры данных и требований к производительности. В качестве рекомендуемого инструмента выделен CatBoost благодаря его эффективной работе с категориальными признаками, автоматизации предобработки данных, устойчивости к переобучению и упрощенной настройке гиперпараметров. Статья предназначена для исследователей и практиков в области машинного обучения, а также специалистов, занимающихся разработкой и оптимизацией прогнозных моделей.
Машинное обучение, CatBoost, XGBoost, LightGBM, градиентный бустинг
Короткий адрес: https://sciup.org/14133022
IDR: 14133022 | УДК: 004.85:004.896:004.4'2 | DOI: 10.47813/2782-2818-2025-5-2-3001-3006
Текст статьи Сопоставление библиотек для создания моделей машинного обучения на основе методов градиентного бустинга
DOI:
В последние десятилетия машинное обучение стало неотъемлемой частью решения сложных задач в различных областях, таких как финансы, медицина, биоинформатика и компьютерное зрение. Среди множества алгоритмов особое место занимают ансамблевые методы, которые комбинируют несколько базовых моделей для повышения точности и устойчивости предсказаний. Одним из наиболее эффективных и широко применяемых ансамблевых подходов является градиентный бустинг [1, 2] (в зарубежных публикациях используется термин – Gradient Boosting Machine, GBM [3-5]).
Методы градиентного бустинга основаны на идее последовательного построения ансамбля слабых предсказателей (обычно деревьев решений), каждый из которых компенсирует ошибки предыдущих, минимизируя заданную функцию потерь с помощью градиентного спуска. Этот подход, предложенный Джеромом Фридманом в конце 1990-х годов, продемонстрировал высокую эффективность в задачах регрессии и классификации, часто превосходя по точности другие методы, включая случайные леса и нейронные сети, особенно на структурированных данных.
Можно выделить три наиболее популярные библиотеки [6], которые активно используются исследователями на сегодняшний день для создания моделей на основе градиентного бустинга: CatBoost [7], XGBoost [8] и LightGBM [9].
Хотя все три библиотеки имеют похожую задачу — улучшение производительности моделей машинного обучения, они имеют свои особенности, преимущества и недостатки.
Рассмотрим более подробно различия данных библиотек и алгоритмов, которые они реализуют.
АНАЛИЗ БИБЛИОТЕКИ CATBOOST
Для данной библиотеки характерен ряд особенностей, выгодно отличающих её от XGBoost и LightGBM . Прежде всего, стоит отметить расширенные возможности работы с категориальными признаками: они обрабатываются автоматически, что позволяет отказаться от предварительного кодирования и подготовки данных — это одно из ключевых преимуществ библиотеки. Кроме того, используется метод « Ordered Boosting » с применением L2 -регуляризации, что способствует снижению риска переобучения и делает модель более надёжной. Также стоит подчеркнуть, что подбор гиперпараметров здесь максимально упрощён: для получения приемлемых результатов требуется меньше усилий, чем при работе с вышеуказанными библиотеками.
Таким образом, к сильным сторонам библиотеки можно отнести: эффективную работу с категориальными переменными без необходимости ручной предобработки; устойчивость модели и пониженную склонность к переобучению; возможность добиться хороших результатов без сложной настройки гиперпараметров. К числу недостатков можно отнести: повышенное потребление оперативной памяти по сравнению с XGBoost и LightGBM , а также менее высокую скорость обучения и предсказаний (особенно по сравнению с LightGBM ).
На рисунке 1 далее представлен алгоритм, реализующий основные принципы библиотеки Catboost .
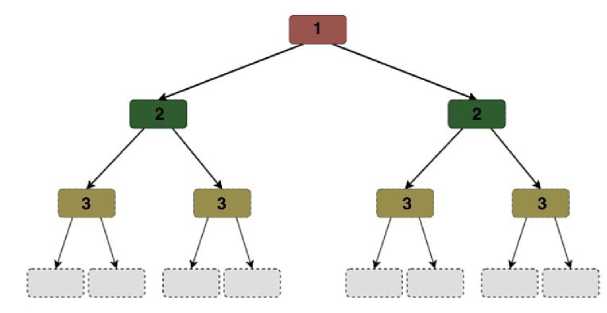
Рисунок 1. Алгоритм обучения, реализованных в библиотеке C ATBOOST .
Figure 1. The training algorithm implemented in the Catboost library.
Как можно увидеть из алгоритма, изображённого на рисунке 1, его ключевая идея заключается в том, что все узлы на одном уровне выполняют одинаковую функцию. Это позволяет избежать излишнего разветвления и одновременно вводит ограничения на структуру дерева. Подобный подход даёт несколько преимуществ: он обеспечивает высокую эффективность выполнения кода и снижает вероятность переобучения модели. При этом обучение прекращается, как только достигается заданная глубина дерева, что служит основным критерием остановки.
ОСОБЕННОСТИ ПРИМЕНЕНИЯ XGBOOST
Для данной библиотеки присущи следующие особенности: поддержка параллельного выполнения, что может в некоторых случаях ускорить обучение моделей; автоматизированная обработка пропущенных данных; использование как L1 так и L2 регуляризации.
Из преимуществ можно выделить: высокую точность; хорошую поддержку регуляризации; эффективную параллелизацию, что ускоряет обучение.
Из недостатков можно выделить: отсутствие (по сравнению с Catboost ) оптимизации гиперпараметров т.е. здесь требуется более тщательная настройка гиперпараметров; также, алгоритмы XGBoost на больших наборах данных более медленные чем алгоритмы, заложенные в основу LightGBM .
На рисунке 2 далее представлен алгоритм, который лежит в основе обучения для XGBoost .
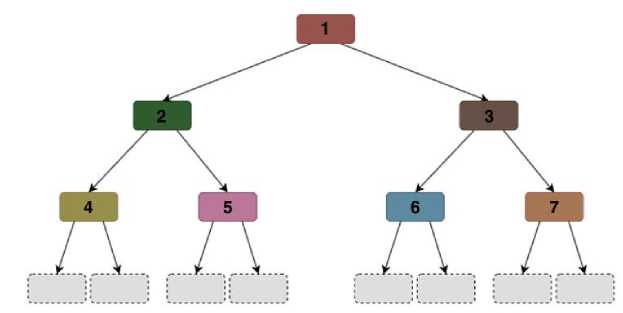
Рисунок 2. Алгоритм обучения, реализованных в библиотеке XGB OOST .
Figure 2. The training algorithm implemented in the XGBoost library.
В основе алгоритма XGBoost лежит принцип последовательного построения дерева по уровням, с любым количеством вершин, ограничивающим условием здесь является максимальная глубина дерева. Для алгоритмов XGBoost характерна симметричность дерева «по глубине», что в идеальных условиях должно привести к бинарному дереву, если это не противоречит остальным условиям. Преимуществом данного подхода, как и в предыдущем случае, является устойчивость к переобучению.
ОСОБЕННОСТИ ПРИМЕНЕНИЯLIGHTGBM
Для библиотеки LightGBM можно выделить следующие особенности: использование технологии Leaf-wise growth (развитие по листьям) т.е. алгоритм LightGBM направлен на развитие деревьев, выбирая самые глубокие листья для роста, это позволяет быстрее достигать высокой точности, особенно на больших наборах данных. Ветвление дерева при этом может быть разным и иметь разную глубину (т.е. симметричность отсутствует (рисунок 3)).
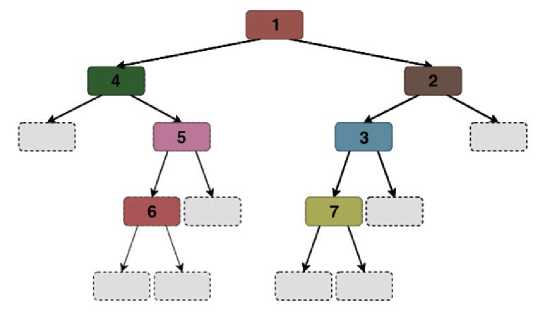
Рисунок 3. Алгоритм обучения, реализованных в библиотеке L IGHT GBM.
Figure 3. The training algorithm implemented in the LightGBM library.
Из преимуществ можно выделить: большую по сравнению с Catboost и XGBoost скорость обучения, особенно на больших наборах данных; низкое потребление памяти.
Из недостатков, по сравнению с рассмотренными ранее библиотеками можно выделить: меньшую устойчивость к переобучению по сравнению с CatBoost ; более тщательную настройку (по сравнению с Catboost и XGBoost ) гиперпараметров; меньшую ориентированность на категориальные данные по сравнению с CatBoost.
СРАВНЕНИЕ ПОДХОДОВ ПО ИСПОЛЬЗОВАНИЮ
РАССМАТРИВАЕМЫХ БИБЛИОТЕК
Рассмотрим выбор библиотеки в зависимости от поставленной задачи. Если в данных присутствует обработка категориальных признаков, то выбор может остановиться на CatBoost , для XGBoost и LightGBM требуется предварительное кодирование и предобработка категориальных признаков. Если в приоритете лежит скорость обучения, то выбор можно остановить на LightGBM – т.к. для него присуще самое быстрое обучение за счет технологии leaf wise growth ; XGBoost быстрее CatBoost , но медленнее LightGBM . Если в приоритете стоит потребление памяти, то ситуация следующая: LightGBM – низкое потребление памяти; XGBoost – среднее потребление памяти; CatBoost – высокое потребление памяти.
Следует также рассмотреть и устойчивость к переобучению. Для библиотеки CatBoost (по сравнению с остальными) можно выделить наилучшую устойчивость благодаря технологии Ordered Boosting; далее, на второе место, можно поставить XGBoost и далее LightGBM (за счет несимметричного алгоритма ветвления при обучении).
Сравнение функций потерь. Функция потерь с регуляризацией для XGBoost (1):
L(0) = x r=i i(yi,yi) + XL i ^(fk), (1)
где Q(fk) = yT + | Л £ j=1 w; 2 , у и Л - параметры регуляризации, T – количество узлов в дереве, w j – вес в узле j.
Функция потерь с регуляризацией для CatBoost (2):
L(0) = X ?=i l(yi,yi) + AX ^=i WJ2 , (2)
где J – количество признаков, w j – вес признака j .
Таким образом, можно сделать следующие выводы. CatBoost отлично подходит для данных с большим количеством категориальных признаков и обеспечивает высокую стабильность; XGBoost является мощным инструментом с хорошей поддержкой регуляризации и параллелизации; LightGBM превосходит по скорости и потреблению памяти, особенно на больших наборах данных, но требует тщательной настройки гиперпараметров для предотвращения переобучения. Выбор между этими библиотеками зависит от специфики задачи, структуры данных и требований к скорости и памяти.
ЗАКЛЮЧЕНИЕ
Для проведения дальнейших разработок следует обратить особое внимание на применение библиотеки Catboost по ряду причин: из-за имеющихся категориальных данных, работа с которыми имеет значение в расчетах; низкие риски переобучения моделей; использование в алгоритмах обучения более строгой L2-регуляризации; автоматизация обработки пропущенных данных; более упрощенная настройка гиперпараметров (что может быть актуальным, если в обучении моделей будут заинтересованы пользователи, которые не являются специалистами по МО).
Дополнительными преимуществами, которые могут повлиять на выбор данной библиотеки: Catboost является отечественной разработкой; имеется возможность ее полной интеграции с другими известными библиотеками (например, такими как SciKit-Learn, Pandas и др.); кроме того, данная библиотека появилась среди открытого ПО сравнительно недавно, что повышает интерес к ее использованию.
