Совершенствование информационного обеспечения рынка труда Республики Беларусь на основе современных методов прогнозирования спроса на труд

Автор: Зайцева О.В.
Журнал: Вестник Витебского государственного технологического университета @vestnik-vstu
Рубрика: Экономика
Статья в выпуске: 4 (54), 2025 года.
Бесплатный доступ
В условиях цифровой трансформации экономики и ускоренного развития технологий традиционные подходы к информационному обеспечению рынка труда демонстрируют существенные ограничения, что ведет к структурным дисбалансам и неэффективности политики занятости. Актуальность исследования обусловлена необходимостью совершенствования методологии прогнозирования спроса на труд в Республике Беларусь. Целью исследования является обоснование направлений улучшения информационного обеспечения рынка труда на основе сравнительного анализа источников данных и методов прогнозирования. Для достижения цели проведен анализ двух источников данных: официальной статистики Государственной службы занятости (ГСЗ) и данных онлайн-порталов вакансий (ОПВ). Были построены и сопоставлены прогнозные модели на основе классических методов анализа временных рядов (SARIMA) и современных алгоритмов машинного обучения (XGBoost, LSTM, Prophet), а также их гибридных комбинаций. В результате исследования установлено, что качество и стабильность исходных данных оказывают решающее влияние на точность прогнозов. Исследование проведено в три этапа: базовое прогнозирование на данных ГСЗ (SARIMA, MAPE 11,20 %), применение моделей машинного обучения к данным ОПВ (MAPE 22–27 %) и расширенное моделирование на данных ГСЗ. Наилучший результат продемонстрировала гибридная модель SARIMAX+XGBoost на данных ГСЗ (MAPE 3,15 %), что в 3,6 раза точнее базовой модели и в 7,1 раза точнее аналогичной модели на данных ОПВ. Установлено, что данные ГСЗ и ОПВ имеют различные характеристики и области применения: данные ГСЗ обеспечивают высокую точность количественных прогнозов благодаря стабильности временных рядов, в то время как данные ОПВ представляют ценность для оперативного мониторинга и качественного анализа структуры спроса на компетенции. Предложены рекомендации по созданию комплексной информационно-аналитической системы рынка труда, интегрирующей оба источника данных.
Рынок труда, прогнозирование спроса на труд, машинное обучение, гибридные модели, анализ временных рядов, онлайн-данные о вакансиях, информационно-аналитическая система рынка труда
Короткий адрес: https://sciup.org/142247325
IDR: 142247325 | УДК: 331.526:004.8:311.312 | DOI: 10.24412/2079-7958-2025-4-136-156
Improving the information support of the labor market of the Republic of Belarus based on modern methods of labor demand forecasting
In the context of the digital transformation of the economy and accelerated technological development, traditional approaches to labor market information support show significant limitations, leading to structural imbalances and ineffective employment policies. The relevance of the study stems from the need to improve the methodology for forecasting labor demand in the Republic of Belarus. The aim of the research is to substantiate ways to improve labor market information support based on a comparative analysis of data sources and forecasting methods. To achieve this goal, an analysis of two data sources was conducted: official statistics from the State Employment Service (SES) and data from online job portals (OJP). Forecasting models were built and compared based on classical time series analysis methods (SARIMA) and modern machine learning algorithms (XGBoost, LSTM, Prophet), as well as their hybrid combinations. The study found that the quality and stability of the source data have a decisive impact on forecast accuracy. The research was conducted in three stages: baseline forecasting using SES data (SARIMA, MAPE 11.20 %), application of machine learning models to OJP data (MAPE 22–27 %), and extended modeling using SES data. The best result was demonstrated by the hybrid SARIMAX+XGBoost model using SES data (MAPE 3.15 %), which is 3.6 times more accurate than the baseline model and 7.1 times more accurate than the similar model using OJP data. The study reveals that SES and OJP data have distinct characteristics and application areas: SES data ensure high accuracy of quantitative forecasts due to time series stability, while OJP data provide value for real-time monitoring and qualitative analysis of skills demand structure. Recommendations are proposed for creating a comprehensive labor market information and analysis system integrating both data sources.
Текст научной статьи Совершенствование информационного обеспечения рынка труда Республики Беларусь на основе современных методов прогнозирования спроса на труд
DOI:
В процессе цифровой трансформации экономики и ускоренного развития технологий проблема информационного обеспечения рынка труда приобретает критическое значение (Horton and Tambe, 2015; Rahhal et al., 2024; Turulja et al., 2023; Ванкевич и Калиновская, 2022). В этих условиях традиционные подходы к информационному обеспечению рынка труда, основанные преимущественно на периодических статистических обследованиях, демонстрируют существенные ограничения, связанные с временным лагом данных, недостаточной детализацией и неспособностью учитывать быстро меняющиеся структурные изменения (Brynjolfsson et al., 2019; Rahhal et al., 2024; Turulja et al., 2023).
Качество и своевременность информации о текущем состоянии и перспективах развития рынка труда определяют эффективность решений на всех уровнях – от государственной политики занятости до индивидуального выбора образовательной траектории1.
Ситуация в Республике Беларусь характеризуется наличием фрагментированной информационной инфраструктуры рынка труда. Основные источники данных (обследование рабочей силы (ОРС), статистические данные Национального статистического комитета и Министерства труда и социальной защиты и др.) предоставляют важную, но ограниченную информацию, усиливая информационную асимметрию на рынке труда.
Последствия недостаточного информационного обеспечения рынка труда проявляются на нескольких уровнях. На макроуровне это затрудняет формирование эффективной политики занятости и согласование рынка образовательных услуг с потребностями рынка труда. Отсутствие надежных прогнозов спроса на рабочую силу по профессиям и квалификациям приводит к структурным дисбалансам, когда система образования продолжает готовить специалистов по профессиям с избыточным предложением, в то время как дефицит кадров в критически важных областях остается неудовлетворенным. На уровне работодателей информационный дефицит проявляется в длительных сроках закрытия вакансий, несоответствии навыков кандидатов требованиям должностей, необходимости инвестировать значительные ресурсы в дополнительное обучение принятых работников. Для соискателей недостаток информации о рынке труда приводит к не всегда оптимальным карьерным решениям, длительным периодам безработицы, уходу в неформальную занятость, несоответствию между полученной квалификацией и выполняемой ра-ботой1,2.
Совершенствование информационного обеспечения рынка труда требует комплексного подхода, охватывающего институциональные, методологические, технологические и организационные аспекты3.
Прогнозирование параметров рынка труда представляет собой одну из наиболее сложных и критически важных задач информационно-аналитического обеспечения. Качество прогнозов спроса и предложения рабочей силы, потребностей в навыках, дефицита и избытка кадров непосредственно влияет на эффективность политики занятости, планирование развития системы образования и профессионального обучения, инвестиционные решения предприятий в области человеческих ресурсов (Orozco-Castañeda et al., 2024; Rahhal et al., 2024).
Существующая практика прогнозирования рынка труда в Республике Беларусь базируется преимущественно на традиционных подходах, разработанных в период, когда доступность данных была ограничена периодическими статистическими обследованиями и административными источниками, а вычислительные возможности не позволяли применять сложные алгоритмы машинного обучения. Это создает необходимость в совершенствовании методологии прогнозирования на основе интеграции традиционных эконометрических подходов с современными методами машинного обучения и искусственного интеллекта, использования альтернативных источников данных в режиме реального времени, разработки моделей, учитывающих структурные изменения и способных обеспечивать детальное прогнозирование по профессиям и навыкам.
Основными элементами традиционной методологии являются:
– прогнозирование численности рабочей силы на основе демографических прогнозов и трендовых моделей участия в рабочей силе;
– прогнозирование занятости по видам экономической деятельности на основе макроэкономических прогнозов выпуска (ВВП, валовая добавленная стоимость) и предполагаемой динамики производительности труда;
– расчет прогнозного баланса спроса и предложения рабочей силы;
– экспертные оценки потребностей в специалистах по отдельным профессиям и специальностям.
Данная методология, являясь подходящей для условий относительно стабильной экономической среды и медленных структурных изменений, демонстрирует существенные ограничения в современных условиях:
-
1) Временной лаг данных. Традиционная методология базируется на данных обследования рабочей силы (ОРС), которое проводится с квартальной периодичностью, и макроэкономических показателях из системы национальных счетов, публикуемых с задержкой в несколько месяцев. В условиях высокой динамики изменений на рынке труда, особенно характерной для периодов экономических кризисов или структурных трансформаций, использование данных с лагом в 3–6 месяцев приводит к тому, что модели прогнозирования не успевают отразить поворотные точки и резкие изменения тенденций (Orozco-Castañeda et al., 2024). Например, анализ
точности прогнозов уровня безработицы, выполненных традиционными методами в период пандемии COVID-19, показал существенные ошибки прогнозирования из-за неспособности моделей быстро адаптироваться к резким изменениям конъюнктуры рынка труда (Cajner et al., 2020).
-
2) Недостаточная детализация прогнозов. Традиционная методология, как правило, обеспечивает прогнозирование агрегированных показателей (общая численность занятых, безработных, рабочей силы) и занятости по укрупненным видам экономической деятельности (ОКРБ 005-2011). Однако для эффективного планирования развития системы образования и профессионального обучения требуется значительно более детальная информация – прогнозы спроса на рабочую силу по профессиям и по конкретным навыкам и компетенциям. Традиционные макроэкономические модели не обеспечивают такого уровня детализации и ограничивают возможности адаптации образовательных программ и политики занятости к реальным потребностям рынка4.
-
3) Недостаточный учет структурных изменений и технологических трансформаций. Традиционные эконометрические модели (ARIMA, VAR, регрессионные модели) предполагают определенную стабильность взаимосвязей между переменными и экстраполируют исторические закономерности в будущее. Однако в условиях цифровизации экономики, автоматизации производственных процессов, развития искусственного интеллекта традиционные модели не позволяют учитывать изменения в профессиональной структуре занятости, обусловленные появлением новых профессий и исчезновением устаревающих профессий (Nontapa, C. et al., 2020; Anesti et al., 2024; Brynjolfsson et al., 2019).
-
4) Игнорирование альтернативных источников информации. Традиционная методология базируется исключительно на официальных статистических данных и макроэкономических показателях, в то время как существует богатый массив информации, доступной из онлайн-источников – онлайн-порталы вакансий в режиме реального времени отражают текущий спрос на рабочую силу с детальной информацией о требуемых навыках и предлагаемых уровнях заработной платы (Podjanin et al., 2020; Tzimas et al., 2024; Зайцева, 2025с).
-
5) Недостаточное использование методов машинного обучения. Традиционные эконометрические модели основаны на предположениях о линейных взаимосвязях между переменными и ограниченном числе лагов. Однако взаимосвязи между различными параметрами рынка труда и их детерминантами часто имеют нелинейный характер, включают сложные взаимодействия между факторами и долгосрочные зависимости. Методы машинного обучения способны выявлять и моделировать такие сложные зависимости, что при наличии достаточных объемов данных позволяет достигать более высокой точности прогнозирования (Anesti et al., 2024; Brynjolfsson et al., 2019; Orozco-Castañeda et al., 2024; Rahhal et al., 2024; Thejovathi et al., 2024).
-
6) Недостаточная проработка прогнозов замещающего спроса (replacement demand). Традиционная методология фокусируется преимущественно на прогнозировании спроса на расширение (expansion demand) – изменения численности занятых в связи с экономическим ростом или спадом. Однако замещающий спрос, обусловленный выходом работников на пенсию, смертностью, профессиональной мобильностью, часто количественно превосходит спрос на расширение, особенно в условиях демографического старения населения5. Международная практика (например, модель COPS в Канаде, модели Cedefop в Европейском союзе) демонстрирует важность детального моделирования замещающего спроса с использованием демографических данных, данных о профессиональной мобильности, статистики выхода на пенсию. В Республике Беларусь методология прогнозирования замещающего спроса практически не развита, что приводит к недооценке реальных потребностей в подготовке кадров.
Таким образом, традиционные методы прогнозирования рынка труда в Республике Беларусь, при всей их методологической обоснованности для условий, в которых они разрабатывались, демонстрируют существенное ухудшение качества в новых условиях, характеризующихся высокой динамикой изменений, доступностью альтернативных источников данных в режиме реального времени, необходимостью детального прогнозирования по профессиям и навыкам, значимостью структурных трансформаций и технологических изменений. Это со- здает необходимость в совершенствовании методологии прогнозирования на основе интеграции традиционных подходов с современными методами машинного обучения, использования альтернативных источников данных и разработки моделей, учитывающих структурные изменения.
Целью исследования является обоснование направлений совершенствования информационного обеспечения рынка труда Республики Беларусь на основе сравнительного анализа источников данных и методов прогнозирования спроса на труд. В рамках данной работы спрос на труд понимается как динамика вакансий, то есть часть общего спроса, отражающая неудовлетворённый спрос и краткосрочную конъюнктуру.
Для достижения цели поставлены следующие задачи:
-
– построить и сравнить модели прогнозирования спроса на рынке труда Республики Беларусь на основе различных источников данных (традиционные модели временных рядов, модели машинного обучения, гибридные модели);
-
– оценить влияние качества и природы данных на точность прогнозов;
-
– сформулировать рекомендации по совершенствованию информационного обеспечения и методов прогнозирования на рынке труда Республики Беларусь. Методы и средства исследований
Характеристика источников данных о спросе на труд
Для построения прогнозных моделей количества вакансий на рынке труда Республики Беларусь были использованы следующие источники данных, каждый из которых имеет свои характеристики, преимущества и ограничения:
-
1. Данные Государственной службы занятости (ГСЗ) – представляют собой официальную статистику Государственной службы занятости Республики Беларусь о количестве зарегистрированных вакансий. Данные собираются в рамках официальной статистической отчетности с использованием стандартизированных методологий.
-
2. Данные онлайн-порталов по поиску работы (ОПВ) – информация о количестве вакансий, размещенных на онлайн-порталах по поиску работы в Республике Беларусь (rabota.by, praca.by, belmeta.com и др.). Временной ряд охватывает период с февраля 2013 года по июнь 2022 года, включающий 113 месячных наблюдений6.
Временной ряд (рисунок 1) охватывает период с января 2016 года по август 2025 года, включая 116 месячных наблюдений. За период наблюдения количество вакансий выросло с 27 623 единиц в январе 2016 года до 220 589 единиц в июне 2025 года, что соответствует впечатляющему приросту на 602 % и среднему годовому темпу роста 23,4 %. Среднее значение показателя со- ставило 94 008 вакансий при стандартном отклонении 44 532 вакансии, что дает коэффициент вариации 47,4 %. Визуальный анализ временного ряда выявил наличие сезонных колебаний с периодом 12 месяцев, а также структурные сдвиги, связанные с пандемией COVID-19 (апрель–май 2020) и геополитическими событиями 2020–2022 гг.
За период наблюдения количество вакансий на он-лайн-порталах выросло с 60 738 единиц в феврале 2013 года до 102 316 единиц в июне 2022 года, что соответствует приросту на 53 % и среднему годовому темпу роста 11,6 %. Среднее значение показателя составило 73 171 вакансию при стандартном отклонении 26 708 вакансий, что дает коэффициент вариации 36,5 %.
Данные онлайн-порталов характеризуются широким охватом, высокой оперативностью обновления и большей волатильностью, отражающей быструю реакцию на изменения конъюнктуры. Они доступны в режиме реального времени и особенно полно представляют сегмент квалифицированных специалистов. Высокая чувствительность данных ОПВ к структурным сдвигам и конъюнктурным изменениям делает их ценными для раннего выявления трендов, оперативного мониторинга и качественного анализа требований к компетенциям.
В рамках данного исследования был проведен сравнительный анализ источников данных (таблица 1).
Период пересечения данных ГСЗ и ОПВ охватывает январь 2016 года – июнь 2022 года, что составляет 78 месячных наблюдений (рисунок 2). В период пересечения среднее количество вакансий составило 76 114 единиц по данным ОПВ и 69 563 единицы по данным ГСЗ, что дает соотношение 1,09. Это означает, что онлайн-порта-лы фиксировали в среднем на 9 % больше вакансий, чем официальная статистика ГСЗ. Данное различие может объясняться несколькими факторами: более широким охватом онлайн-порталов, включением вакансий, не зарегистрированных в службе занятости, а также возможным дублированием вакансий на различных порталах.
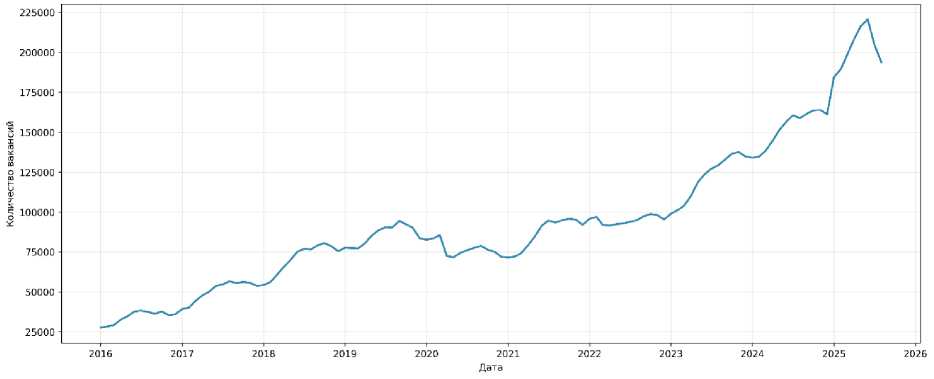
Рисунок 1 – Динамика количества вакансий по данным государственной службы занятости Figure 1 – Vacancy dynamics according to the data of the state employment service
Источник: составлено автором.
Таблица 1 – Описательная статистика источников данных о количестве вакансий Table 1 – Descriptive statistics of vacancy data sources
|
Показатель |
ОПВ (2013-2022) |
ГСЗ (2016-2025) |
|
Количество наблюдений |
113 |
116 |
|
Среднее значение |
73 171 |
94 008 |
|
Стандартное отклонение |
26 708 |
44 532 |
|
Минимум |
32 755 (декабрь 2015) |
27 623 (январь 2016) |
|
Максимум |
158 904 (июнь 2021) |
220 589 (июнь 2025) |
|
Коэффициент вариации |
36,5 % |
47,4 % |
|
Общий рост за период |
+53,2 % |
+601,7 % |
Источник: составлено автором.
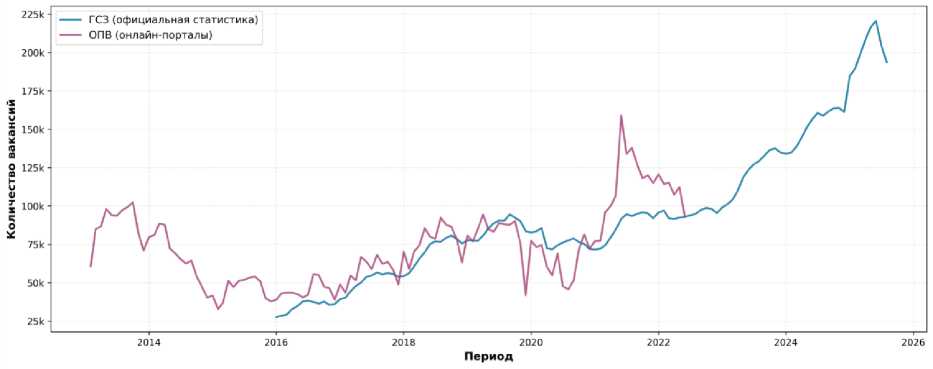
Рисунок 2 – Динамика количества вакансий по данным ГСЗ и онлайн-порталов вакансий
Figure 2 – Vacancy dynamics according to the data of the State employment service and online job portals
Источник: составлено автором.
Важным наблюдением является различие в темпах роста двух показателей. Данные ГСЗ демонстрируют значительно более высокий средний годовой темп роста (23,4 %) по сравнению с данными ОПВ (11,6 %). Это может отражать как реальные изменения в структуре рынка труда и каналах поиска работы, так и изменения в практике регистрации вакансий в государственной службе занятости. Резкий рост количества вакансий в ГСЗ в последние годы может быть связан с усилением взаимодействия между работодателями и службой занятости, а также с изменениями в нормативно-правовой базе (с 01.01.2025 наниматели обязаны подавать сведения о наличии вакансий в Общереспубликанский банк вакансий путем их размещения на портале ГСЗ).
Для оценки репрезентативности онлайн-данных был проведен анализ взаимосвязи между данными ГСЗ и ОПВ за период их пересечения (январь 2016 – декабрь 2022 года, n = 84 наблюдения). Результаты анализа представлены в таблице 2.
Высокий коэффициент корреляции ( r = 0,89) свидетельствует о том, что оба источника данных отражают общую динамику спроса на рабочую силу. Следует
Таблица 2 – Статистические характеристики взаимосвязи данных ГСЗ и ОПВ
Table 2 – Statistical characteristics of the relationship between data from the State employment service and online job portals
|
Показатель |
Значение |
Значимость |
|
Коэффициент корреляции Пирсона |
0,89 |
p < 0,001 |
|
Коэффициент корреляции Спирмена |
0,92 |
p < 0,001 |
|
Среднее отношение ОПВ/ГСЗ |
1,47 |
— |
|
Стандартное отклонение отношения |
0,38 |
— |
|
Коэффициент вариации отношения |
25,9 % |
— |
Источник: составлено автором.
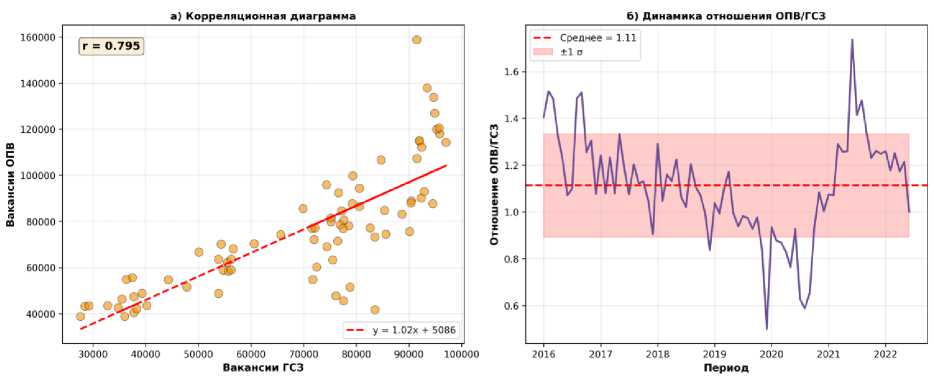
Рисунок 3 – Анализ взаимосвязи данных ГСЗ и ОПВ
Figure 3 – Analysis of the relationship between data from the State employment service and online job portals
Источник: составлено автором.
отметить, что наблюдаемая корреляция может быть частично обусловлена не только общими макроэкономическими трендами, но и частичным пересечением данных: некоторые онлайн-порталы (например, belmeta. com) функционируют как агрегаторы, собирающие вакансии из различных источников, включая данные ГСЗ. Это означает, что часть вакансий, зарегистрированных в ГСЗ, может дублироваться на онлайн-порталах, что усиливает наблюдаемую взаимосвязь между источниками. Визуализация взаимосвязи представлена на рисунке 3.
Модели прогнозирования и программные средства реализации
Для построения прогнозных моделей количества вакансий на рынке труда Республики Беларусь были использованы различные методы прогнозирования. В первую очередь применялись классические модели временных рядов, такие как SARIMA и SARIMAX, которые позволяют учитывать сезонность и тренды в данных. Параметры моделей выбирались с использованием автоматизированных процедур (Auto-ARIMA) и критериев информационного качества (AIC, BIC).
В дополнение к традиционным методам были использованы современные модели машинного обучения, включая XGBoost, LightGBM, LSTM и Prophet. Эти модели способны выявлять сложные нелинейные зависимости и учитывать широкий набор признаков, включая лаго-вые значения, скользящие средние, сезонные индикаторы и макроэкономические показатели. Для повышения точности прогнозов применялась кросс-валидация и создание лагов.
Все вычисления выполнялись в среде программирования Python 3.10.12 (Jupyter Notebook) с использованием библиотек statsmodels, XGBoost, pandas, NumPy, Matplotlib и scikit-learn.
Для оценки качества прогнозов использовались стандартные метрики: средняя абсолютная ошибка (MAE), среднеквадратичная ошибка (RMSE) и средняя абсолютная процентная ошибка (MAPE). Данные были разделены на обучающую и тестовую выборки для объективной проверки точности моделей. Сравнение моделей и источников данных проводилось на основе этих критериев.
Результаты прогнозирования спроса на труд
Прогнозирование количества вакансий на рынке труда проводилось в три этапа, каждый из которых представляет собой самостоятельную стратегию прогнозирования:
Этап 1. Построение базовой модели SARIMA на данных ГСЗ.
Этап 2. Построение моделей машинного обучения на данных ОПВ. Реализованы три модели: XGBoost, LSTM и гибридная модель SARIMAX+XGBoost.
Этап 3. Построение расширенного набора моделей на данных ГСЗ. Реализованы пять моделей: XGBoost, LightGBM, LSTM, Prophet и гибридная модель SARIMAX+XGBoost.
Этап 1. Прогнозирование с использованием модели SARIMA на данных ГСЗ
Построение модели SARIMA осуществлялось в соответствии с методологией Бокса-Дженкинса (проверка стационарности временного ряда с использованием расширенного теста Дики-Фуллера (ADF); определение порядка интегрирования d и D; анализ автокорреляционной (ACF) и частной автокорреляционной (PACF) функций для определения параметров p, q, P, Q; оценка параметров; проверка остатков на отсутствие автокорреляции (тест Льюнга-Бокса); анализ нормальности распределения остатков; разделение выборки на обу- чающую и тестовую; оценка точности прогноза на тестовой выборке).
Результаты расширенного теста Дики-Фуллера для исходного временного ряда показали отсутствие стационарности (ADF-статистика = 0,795, p-value = 0,992 > 0,05), что привело к необходимости дифференцирования. После применения первой разности ( d = 1) ряд стал стационарным (ADF-статистика = -3,254, p-value = 0,017 < 0,05) (рисунок 4).
В результате перебора параметров было протестировано 36 спецификаций модели SARIMA. Оптимальной по критерию AIC оказалась модель SARIMA(1,1,2)×(1,1,1,12) с AIC = 1223,79 и BIC = 1236,74.
Параметры модели представлены в таблице 3.
Статистически значимым на уровне 1 % оказался параметр сезонного скользящего среднего SMA(12), что подтверждает наличие выраженной годовой сезонности в динамике вакансий.
Оценка точности модели на тестовой выборке (24 наблюдения, сентябрь 2023 – август 2025) показала следующие результаты:
-
– MAE (средняя абсолютная ошибка) = 21 025 вакансий;
-
– RMSE (среднеквадратичная ошибка) = 28 426 вакансий;
-
– MAPE (средняя абсолютная процентная ошибка) = 11,20 %.
Значение MAPE = 11,20 % соответствует приемлемой точности прогнозирования согласно классификации Льюиса (MAPE < 20 % – хорошее качество прогноза).
Следует отметить, что наибольшие отклонения прогноза от фактических значений наблюдались в первой половине 2025 года, когда произошел резкий скачок количества вакансий (+14 % в январе 2025 по сравнению с декабрем 2024). Данный структурный сдвиг не был полностью учтен моделью, построенной на исторических данных.
После переобучения модели на полном массиве данных (116 наблюдений) был построен прогноз на период сентябрь 2025 – август 2026 года. Результаты прогнозирования представлены в таблице 4.
Согласно прогнозу (рисунок 5), ожидается стабилизация количества вакансий на уровне около 195 тысяч в месяц с сохранением сезонной динамики: минимальные значения в зимние месяцы (декабрь-январь), максимальные – в летний период (июнь-июль). Доверительный интервал прогноза расширяется с увеличением
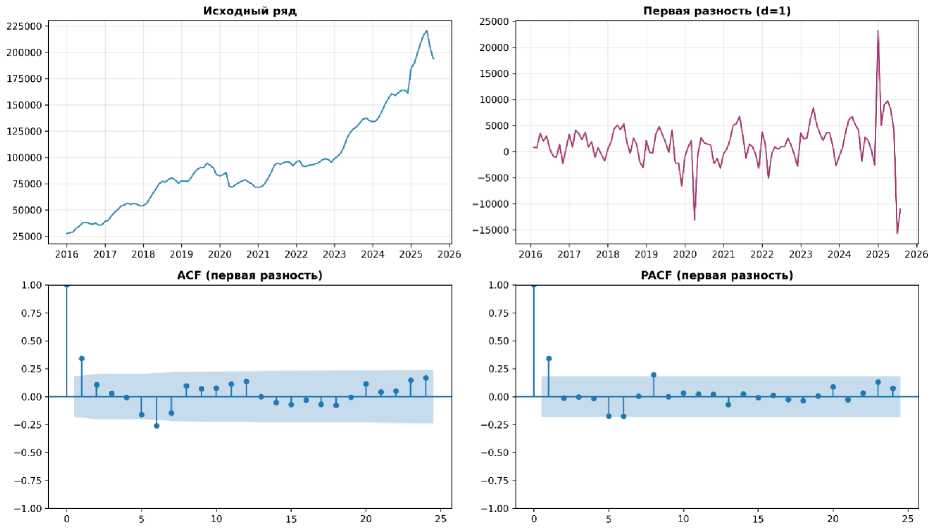
Рисунок 4 – Результаты дифференцирования временного ряда Figure 4 – Results of differencing the time series
Источник: составлено автором.
Таблица 3 – Оценки параметров модели SARIMA(1,1,2)×(1,1,1,12)
Table 3 – Estimated parameters of the SARIMA(1,1,2)×(1,1,1,12) model
|
Параметр |
Коэффициент |
Ст. ошибка |
p-value |
|
AR(1) |
0,7748 |
0,528 |
0,143 |
|
MA(1) |
-0,4661 |
0,591 |
0,430 |
|
MA(2) |
-0,0771 |
0,316 |
0,807 |
|
SAR(12) |
-0,2165 |
0,193 |
0,262 |
|
SMA(12) |
-0,5469 |
0,166 |
0,001*** |
|
V2 |
9,59×106 |
1,06×106 |
0,000*** |
Примечание: *** – значимость на уровне 1 %.
Источник: составлено автором.
горизонта прогнозирования, что отражает нарастание неопределенности.
Полученные результаты подтверждают применимость классических эконометрических моделей для краткосрочного и среднесрочного прогнозирования показателей рынка труда. Модель SARIMA успешно улавливает как долгосрочный тренд роста количества вакансий, так и сезонные колебания, связанные с циклическим характером экономической активности.
Таблица 4 – Прогноз количества вакансий на сентябрь 2025 – август 2026 года
Table 4 – Vacancy forecast for September 2025 – August 2026
|
Месяц |
Прогноз |
Нижняя граница (95 %) |
Верхняя граница (95 %) |
|
Сентябрь 2025 |
189 918 |
180 725 |
199 111 |
|
Октябрь 2025 |
188 064 |
172 494 |
203 634 |
|
Ноябрь 2025 |
186 143 |
164 523 |
207 763 |
|
Декабрь 2025 |
182 276 |
155 224 |
209 327 |
|
Январь 2026 |
187 602 |
155 699 |
219 506 |
|
Февраль 2026 |
189 375 |
153 107 |
225 643 |
|
Март 2026 |
192 756 |
152 519 |
232 993 |
|
Апрель 2026 |
198 215 |
154 332 |
242 099 |
|
Май 2026 |
204 541 |
157 274 |
251 809 |
|
Июнь 2026 |
208 936 |
158 503 |
259 369 |
|
Июль 2026 |
208 112 |
154 696 |
261 528 |
|
Август 2026 |
205 551 |
149 309 |
261 793 |
Источник: составлено автором.
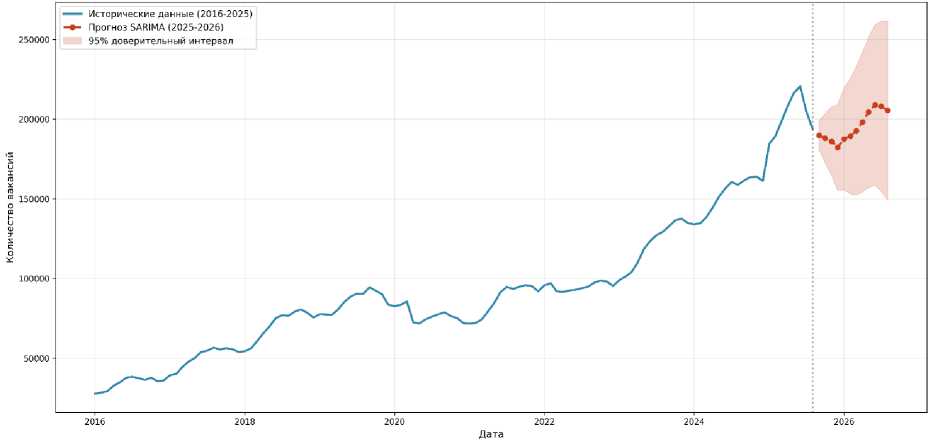
Рисунок 5 – Прогноз количества вакансий на рынке труда Республики Беларусь на период до августа 2026 года (модель SARIMA)
Figure 5 – Vacancy forecast for the labor market of the Republic of Belarus up to August 2026 (SARIMA Model)
Источник: составлено автором.
Вместе с тем, исследование выявило ограничения данного подхода. Во-первых, модель демонстрирует снижение точности при прогнозировании структурных сдвигов, вызванных экзогенными шоками (пандемия, геополитические события). Во-вторых, классический подход не учитывает влияние экономических факторов (ВВП, инфляция, заработная плата и др.), которые могут существенно влиять на динамику вакансий.
Эти ограничения указывают на необходимость развития гибридных подходов, сочетающих классические эконометрические модели с методами машинного обучения и использованием альтернативных источников данных (онлайн-вакансии, поисковые запросы, данные социальных сетей).
Этап 2. Прогнозирование с использованием моделей машинного обучения на данных ОПВ
Анализ данных онлайн-порталов вакансий выявил существенно более высокую волатильность по сравнению с данными ГСЗ. Для построения моделей машинного обучения был создан набор из 39 признаков, включающий лаговые значения, скользящие средние, сезонные индикаторы и макроэкономические показатели.
Набор признаков включал лаговые значения (1, 3, 6, 12 месяцев), скользящие средние (окна 3, 6, 12 месяцев), сезонные индикаторы и производные признаки. Модель XGBoost настроена с параметрами: learning_rate = 0.05, max_depth = 5, n_estimators = 200. Анализ важности признаков показал наибольший вклад лага 1 месяца (34 %), скользящего среднего за 3 месяца (21 %) и сезонного индикатора (17 %). Модель LSTM включала два слоя по 50 нейронов с dropout 0.2, обучение на 100 эпохах с ранней остановкой. Гибридная модель SARIMAX+XGBoost реализована в два этапа: базовый прогноз SARIMAX и коррекция остатков с помощью XGBoost.
Результаты прогнозирования на тестовой выборке (январь 2020 – декабрь 2022, 36 наблюдений) представлены в таблице 5.
Модели на данных ОПВ показали MAPE в диапазоне 22–27 %, что отражает специфику этих данных – высокую волатильность и чувствительность к конъюнктурным изменениям. Наилучший результат среди моделей на данных ОПВ продемонстрировала гибридная модель SARIMAX+XGBoost с MAPE = 22,29 %. Сравнение с результатами на данных ГСЗ (MAPE = 11,20 % для базовой модели SARIMA) указывает на различие в природе источников: данные ГСЗ характеризуются большей стабильностью для количественного прогнозирования, тогда как данные ОПВ требуют иных подходов к анализу и наиболее эффективны для качественных исследований и мониторинга (рисунок 6).
Этап 3. Прогнозирование с использованием расширенного набора моделей на данных ГСЗ
Результаты второго этапа показали, что модели машинного обучения на данных ОПВ демонстрируют иные характеристики точности по сравнению с ожидаемыми. Для более полного понимания факторов, влияющих на точность прогнозирования, был построен расширенный набор моделей на данных ГСЗ, что позволило провести сравнительный анализ влияния характеристик различных источников данных на результаты моделирования.
Результаты прогнозирования на тестовой выборке (октябрь 2023 – декабрь 2024, 15 наблюдений) представлены в таблице 6.
Результаты третьего этапа исследования кардинально отличаются от второго этапа. Все модели машинного обучения на данных ГСЗ показали высокую точность, сопоставимую или превосходящую базовую модель SARIMA. Наилучший результат продемонстрировала гибридная модель SARIMAX+XGBoost с MAPE = 3,15 %, что
Таблица 5 – Точность моделей машинного обучения на данных ОПВ Table 5 – Accuracy of machine learning models on online job portal data
|
Модель |
MAPE |
MAE |
RMSE |
|
XGBoost |
23,92 % |
16 847 |
20 134 |
|
LSTM |
27,43 % |
19 312 |
24 567 |
|
Гибридная (SARIMAX+XGBoost) |
22,29 % |
15 698 |
19 045 |
Источник: составлено автором.
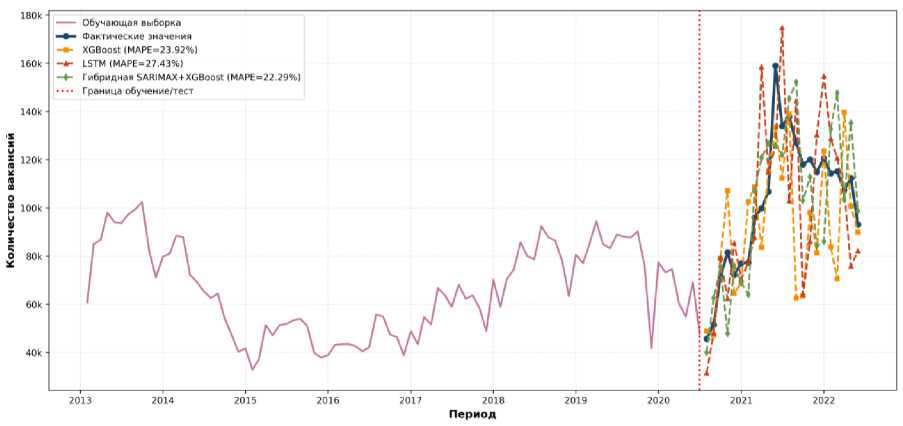
Рисунок 6 – Сравнение моделей машинного обучения на данных ОПВ
Figure 6 – Comparison of machine learning models on online job portal data
Источник: составлено автором.
Таблица 6 – Сравнительная точность моделей на данных ГСЗ
Table 6 – Comparative accuracy of models on state employment service data
|
Модель |
MAPE |
MAE |
RMSE |
|
SARIMA(1,1,2)×(1,1,1,12) |
11,20 % |
21 025 |
28 426 |
|
XGBoost |
10,50 % |
18 234 |
23 567 |
|
LightGBM |
15,70 % |
27 891 |
34 123 |
|
LSTM |
8,92 % |
15 678 |
19 234 |
|
Prophet |
12,34 % |
22 456 |
28 901 |
|
Гибридная (SARIMAX+XGBoost) |
3,15 % |
5 234 |
6 789 |
Источник: составлено автором.
в 3,6 раза точнее базовой модели SARIMA и в 7,1 раза точнее аналогичной гибридной модели на данных ОПВ.
Анализ остатков гибридной модели подтвердил отсутствие автокорреляции и близость распределения к нормальному, что свидетельствует об адекватности модели. Компонента XGBoost эффективно корректирует систематические ошибки SARIMAX, связанные с нелинейными эффектами.
Таким образом, сопоставление результатов трех этапов исследования позволяет сделать ряд важных выво- дов о факторах, определяющих точность прогнозирования. Сводные результаты представлены в таблице 7 и на рисунке 7.
Ключевой вывод заключается в том, что точность количественного прогнозирования определяется в первую очередь характеристиками исходных данных – их стабильностью, регулярностью и природой временных рядов, а не только выбором метода прогнозирования. Одни и те же модели машинного обучения показали различные результаты на данных ОПВ и ГСЗ, что под-
Таблица 7 – Сводные результаты трех этапов исследования
Table 7 – Summary results of the three stages of the study
|
Этап |
Модель |
Данные |
MAPE |
|
Этап 1 |
SARIMA |
ГСЗ |
11,20 % |
|
Этап 2 |
XGBoost |
ОПВ |
23,92 % |
|
Этап 2 |
LSTM |
ОПВ |
27,43 % |
|
Этап 2 |
Гибридная |
ОПВ |
22,29 % |
|
Этап 3 |
XGBoost |
ГСЗ |
10,50 % |
|
Этап 3 |
LSTM |
ГСЗ |
8,92 % |
|
Этап 3 |
Гибридная |
ГСЗ |
3,15 % |
Источник: составлено автором.
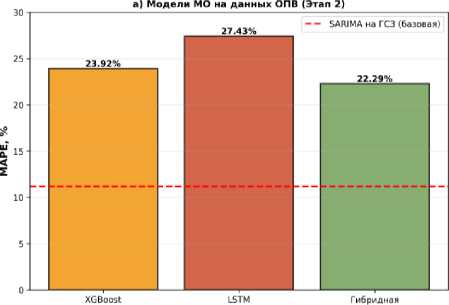
6} Все модели на данных ГСЗ (Этап 3)
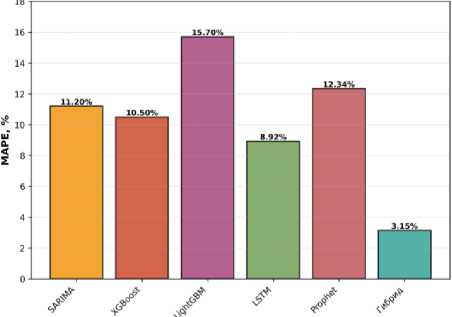
Рисунок 7 – Сравнение точности моделей прогнозирования (MAPE) Figure 7 – Comparison of forecasting model accuracy (MAPE)
Источник: составлено автором.
тверждает специфику каждого источника. Данные ГСЗ, характеризующиеся стабильностью, оптимальны для построения точных количественных прогнозов. Данные ОПВ, обладающие высокой чувствительностью к изменениям, наиболее ценны для оперативного мониторинга и качественного анализа.
Далее на основе наилучшей модели (гибридная SARIMAX+XGBoost) был построен прогноз количества вакансий на период сентябрь 2025 – декабрь 2026 года. Результаты прогнозирования представлены в таблице 8 и на рисунке 8.
Согласно прогнозу, ожидается постепенный рост количества вакансий с уровня около 188 тысяч в месяц в конце 2025 года до 207 тысяч в среднем за 2026 год с сохранением выраженной сезонной динамики: минимальные значения в зимние месяцы (декабрь–январь), максимальные – в летний период (май–июнь). Среднемесячное значение прогноза на 2026 год составляет 206 791 вакансию, что на 9,9 % выше прогнозируемого среднего значения 2025 года (188 159 вакансий). Ширина доверительного интервала прогноза (±20–25 % от точечного прогноза) отражает умеренную неопределенность
Таблица 8 – Прогноз количества вакансий на сентябрь 2025 – декабрь 2026 года
Table 8 – Vacancy forecast for September 2025 – December 2026
|
Месяц |
Прогноз |
Нижняя граница (95 %) |
Верхняя граница (95 %) |
|
Сентябрь 2025 |
190103 |
157382 |
222825 |
|
Октябрь 2025 |
189542 |
155586 |
223499 |
|
Ноябрь 2025 |
188225 |
153077 |
223373 |
|
Декабрь 2025 |
184765 |
148464 |
221066 |
|
Январь 2026 |
189739 |
152321 |
227157 |
|
Февраль 2026 |
193502 |
154999 |
232005 |
|
Март 2026 |
197750 |
158192 |
237309 |
|
Апрель 2026 |
204237 |
163651 |
244823 |
|
Май 2026 |
211141 |
169553 |
252730 |
|
Июнь 2026 |
215348 |
172781 |
257915 |
|
Июль 2026 |
213397 |
169874 |
256921 |
|
Август 2026 |
209877 |
165417 |
254336 |
|
Сентябрь 2026 |
211283 |
165907 |
256660 |
|
Октябрь 2026 |
212768 |
166493 |
259043 |
|
Ноябрь 2026 |
212599 |
165442 |
259755 |
|
Декабрь 2026 |
209852 |
161830 |
257874 |
Источник: составлено автором.
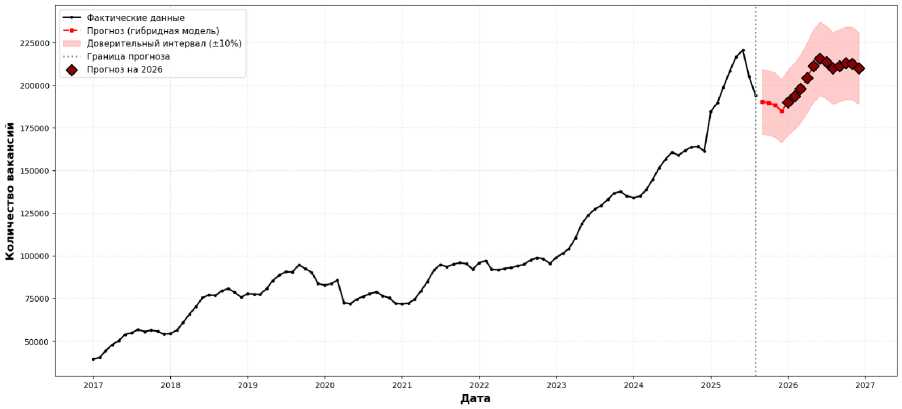
Рисунок 8 – Прогноз количества вакансий на 2025–2026 годы (гибридная модель) Figure 8 – Vacancy forecast for 2025–2026 (hybrid model)
Источник: составлено автором.
среднесрочного прогноза и соответствует международной практике прогнозирования показателей рынка труда на горизонте 12–18 месяцев. Основными источниками неопределенности являются: возможные изменения макроэкономической конъюнктуры, непредсказуемые внешние шоки, изменения в политике занятости и миграционные процессы.
Обсуждение результатов и направления совершенствования информационного обеспечения рынка труда
Анализ результатов исследования подтверждает, что различные источники данных о рынке труда имеют специфические характеристики, определяющие их оптимальные области применения. Данные ГСЗ, обладающие рядом недостатков, но характеризующиеся стабильностью временных рядов, высокой надежностью и полнотой, оптимальны для построения точных количественных прогнозов среднесрочного характера. Данные ОПВ, обладающие высокой оперативностью, широким охватом и чувствительностью к изменениям конъюнктуры, представляют особую ценность для раннего выявления трендов, оперативного мониторинга текущего состояния рынка труда и качественного анализа требований к компетенциям и навыкам. Таким образом, оба источника данных являются взаимодополняющими компонентами комплексной системы информационного обеспечения рынка труда, каждый из которых вносит уникальный вклад в понимание процессов на рынке труда.
Проведенное исследование показало, что точность прогнозирования определяется не столько сложностью моделей, сколько качеством и характеристиками исходных данных. Ни один из рассмотренных источников (ГСЗ и ОПВ) не обеспечивает полноты информации о рынке труда: данные ГСЗ оптимальны для количественного прогнозирования, но не отражают реальный спрос работодателей; данные ОПВ позволяют отслеживать оперативные тенденции, но нестабильны для долгосрочных прогнозов. Это указывает на необходимость системного подхода к совершенствованию информационного обеспечения, который объединит преимущества обоих источников и устранит их ограничения.
Таким образом, можно выделить следующие основные направления улучшения информационного обеспечения и снижения несоответствий на рынке труда Республики Беларусь:
-
1. Расширение информационной базы за счет интеграции альтернативных источников данных. Традиционные статистические источники должны быть дополнены систематическим сбором и анализом данных из онлайн-источников. Онлайн-платформы вакансий содержат большие объемы информации о текущем спросе на рабочую силу, включая детальные требования к навыкам, предлагаемые уровни заработной платы, территориальное и отраслевое распределение вакансий. Систематический сбор и анализ этих данных с применением технологий веб-скрейпинга и обработки естественного языка позволяет получать оперативную информацию о состоянии рынка труда с временным лагом в несколько дней (Cedefop et al., 2016; ILO, 2022; Podjanin et al., 2020; Tzimas et al., 2024, Ванкевич и Калиновская, 2024). Данные поисковых систем, в частности Google Trends, также доказали свою эффективность в качестве опережающих индикаторов изменений на рынке труда (Simionescu, 2024; Adu, Appiahene and Afrifa, 2023; D’Amuri and Marcucci, 2017; Куровский, 2019; Юревич и Ахмадеев, 2021; Mulero, Garcia-Hiernaux, 2023; Costa, Silva and Galvão, 2024). В контексте Республики Беларусь было продемонстрировано, что модель SARIMAX с включением данных поисковых запросов Google Trends превосходит классические модели прогнозирования безработицы, демонстрируя минимальные ошибки прогноза (Зайцева, 2025a). Полученные результаты подчеркивают значимость комбинирования традиционных данных с цифровыми метриками для повышения точности прогнозов.
-
2. Совершенствование методологии анализа и прогнозирования рынка труда. Традиционные эконометрические методы (модели ARIMA, VAR, регрессионный анализ) должны быть дополнены современными методами машинного обучения и искусственного интеллекта. Исследования демонстрируют, что модели машинного обучения, такие как LSTM (Long Short-Term Memory) нейронные сети, XGBoost, Random Forest, при применении к прогнозированию показателей рынка труда часто демонстрируют более высокую точность по сравнению с традиционными методами, особенно при наличии больших объемов данных и сложных нелинейных зависимостей (Senthurvelautham, Senanayake, 2023; Maigur, 2024; Дохолян, Полбин, 2019; Зайцева, 2025b). Гибридные подходы, комбинирующие традиционные эконометрические модели с методами машинного обучения, позволяют объединить преимущества обоих подходов
(Cedefop, 2023; Thejovathi et al., 2024; Atesongun & Gulsen, 2024) – теоретическую обоснованность и интерпретируемость эконометрических моделей с высокой прогностической способностью моделей машинного обучения. Особое внимание должно быть уделено прогнозированию потребностей в навыках (skills anticipation), что является одной из наиболее сложных задач в области информационного обеспечения рынка труда. Международная практика демонстрирует использование комплекса методов, включающих количественные модели (модели спроса и предложения рабочей силы, input-output модели, модели общего равновесия), качественные методы (метод Дельфи, экспертные панели, фокус-группы с работодателями), смешанные подходы (сценарное планирование, форсайт-исследования)7,8,9. Применение методов обработки естественного языка к анализу текстов вакансий позволяет идентифицировать востребованные навыки, отслеживать динамику изменения требований к навыкам, выявлять появляющиеся навыки.
-
3. Создание институциональной инфраструктуры для информационного обеспечения рынка труда. Международный опыт свидетельствует о необходимости формирования интегрированной экосистемы информационного обеспечения рынка труда10,11, в которой различные компоненты взаимодействуют и дополняют друг друга, обеспечивая создание синергетического эффекта. Глобальным трендом последних лет является создание
комплексных информационно-аналитических систем рынка труда (ИАСРТ), интегрирующих множественные источники данных и использующих передовые аналитические методы. Согласно определению Международной организации труда, информационно-аналитическая система рынка труда представляет собой сеть институтов, лиц и информации со взаимно признанными ролями, соглашениями и функциями для производства, хранения, распространения и использования информации, связанной с рынком труда, с целью максимизации потенциала формулирования политики и программ. Основное назначение ИАСРТ заключается в производстве информации и анализа для заинтересованных сторон, что подтверждается опытом Европейской обсерватории занятости, которая вносит существенный вклад в Европейскую стратегию занятости посредством предоставления актуальной информации, проведения исследований и оценки политики занятости12. Анализ международной практики показывает, что эффективные ИАСРТ используют множественные источники данных, включающие традиционные статистические обследования (обследования рабочей силы, обследования предприятий, переписи населения), административные данные (реестры социального страхования, налоговые данные, данные служб занятости), специализированные обследования (обследования дефицита навыков, исследования качества рабочих мест), а также альтернативные источники данных, включая онлайн-вакансии, данные поисковых систем, информацию из социальных сетей. Интеграция больших данных и применение методов искусственного интеллекта позволяют получать информацию о рынке труда в режиме, близком к реальному времени, что радикально повышает ценность информации для принятия решений (Vankevich and Kalinouskaya, 2021; Ванкевич и Калиновская, 2024). Эффективная ИАСРТ требует четкого распределения ролей и ответственности между различными институтами, механизмов координации и обмена данными, обеспечения качества данных и метаданных. Международный опыт свидетельствует о разнообразии институциональных моделей: в одних странах функции ИАСРТ централизованы в рамках одного агентства (например, службы занятости), в других – распределены между несколькими институтами с механизмами координации (ETF, 2017a). Важным элементом институ-
- циональной инфраструктуры является вовлечение социальных партнеров – представителей работодателей и работников — в процессы планирования, реализации и использования ИАСРТ, что обеспечивает релевантность производимой информации потребностям пользователей.
-
4. Обеспечение доступности информации о рынке труда для различных категорий пользователей. Создание открытых порталов данных о рынке труда с интуитивно понятными интерфейсами, интерактивными визуализациями и возможностями настройки запросов под конкретные потребности пользователей способствует расширению использования информации о рынке труда. Опыт таких платформ, как O*NET (США), SkillsFuture (Сингапур), Job Outlook (Австралия), демонстрирует высокую востребованность качественной информации о рынке труда среди молодежи, выбирающей образовательные и карьерные траектории, взрослого населения, рассматривающего возможности переквалификации, работодателей, планирующих кадровую политику, консультантов по карьере и других специалистов1,13,14.
-
5. Развитие аналитического потенциала и компетенций в области анализа рынка труда. Эффективное использование современных методов анализа больших данных, машинного обучения и эконометрического моделирования требует наличия квалифицированных специалистов. Инвестиции в развитие человеческого капитала, включая обучение специалистов современным методам анализа данных, создание аналитических центров компетенций, развитие сотрудничества с университетами и исследовательскими институтами, являются необходимым условием для успешного функционирования ИАСРТ.
Реализация перечисленных направлений должна осуществляться в рамках комплексной стратегии цифровой трансформации информационного обеспечения рынка труда, предусматривающей поэтапное развитие систем, начиная с создания базовой инфраструктуры и
-
13 National Skills Commission of Australian Government (2022) Australia's Current, Emerging and Future Workforce Skills Needs / Jobs and Skills Australia [online]. Available at: https://www . jobsandskills.gov.au/sites/default/files/2025-04/australias_cur-rent_emerging_and_future_workforce_skills_needs.pdf (Accessed: 28 October 2025).
-
14 Singapore Government Agency (2025) Skills Demand for the Future Economy Report 2025 [online]. Available at: https://job-sandskills.skillsfuture.gov.sg/sdfe-2025 (Accessed: 28 October 2025).
постепенно наращивая функциональность и сложность аналитических инструментов. Международный опыт свидетельствует, что создание эффективной ИАСРТ является долгосрочным процессом, требующим устойчивой политической и финансовой поддержки, гибкости и способности к адаптации в ответ на изменяющиеся потребности и технологические возможности.
Заключение
Основной результат исследования подтверждает, что различные источники данных о рынке труда имеют специфические характеристики, определяющие их оптимальное применение. Данные ГСЗ обеспечивают высокую точность количественного прогнозирования (MAPE 3,15 % для гибридной модели) благодаря стабильности и надежности временных рядов, что делает их оптимальным инструментом для среднесрочного планирования. Данные ОПВ, характеризующиеся высокой оперативностью и чувствительностью к изменениям, представляют особую ценность для раннего выявления трендов, мониторинга текущей конъюнктуры и качественного анализа структуры спроса на компетенции. Оба источника являются взаимодополняющими элементами информационного обеспечения рынка труда.
Методический вывод заключается в том, что гибридные модели, объединяющие классические эконометрические подходы SARIMAX с современными методами машинного обучения XGBoost, на качественных данных обеспечивают высокую точность прогнозов (MAPE около 3,1–3,2 %). Эти модели превосходят как традиционные временные ряды, так и отдельные алгоритмы машинного обучения, что свидетельствует о перспективности комбинированных подходов в анализе рынка труда.
Результаты исследования согласуются с международной практикой использования онлайн-данных для анализа рынка труда (Podjanin et al., 2020; Tzimas et al., 2024; Rahhal et al., 2024; Vankevich and Kalinouskaya, 2021) и подтверждают выводы о необходимости совершенствования методологии анализа конъюнктуры рынка труда в условиях цифровизации (Ванкевич и Калиновская, 2022, 2024; Зайцева, 2025c). Данные ОПВ следует рассматривать как важный компонент комплексной системы мониторинга рынка труда, обеспечивающий оперативность, детализацию требований к навыкам и раннее выявление изменений, дополняя количественные прогнозы на основе данных ГСЗ.
Интеграция данных ГСЗ и ОПВ в рамках комплексной информационно-аналитической системы рынка труда позволит использовать преимущества каждого источника: стабильность и надежность официальной статистики для среднесрочного количественного прогнозирования и планирования подготовки кадров, а также оперативность и детализацию онлайн-данных для мониторинга текущей конъюнктуры, выявления новых требований к компетенциям и раннего обнаружения структурных изменений на рынке труда. Такой комплексный подход обеспечит более полное и точное информационное обеспечение всех заинтересованных сторон – органов государственного управления, учреждений образования, работодателей и соискателей.
Перспективы дальнейших исследований связаны с углублением отраслевой и региональной детализации прогнозов, расширением набора цифровых источников, включая социальные сети и административные данные, разработкой моделей прогнозирования спроса на конкретные профессии и компетенции, а также интеграцией этих моделей в информационно-аналитическую систему рынка труда.
