Совершенствование управления кадровой политикой образовательной организации на основе технологий интеллектуального анализа данных

Автор: Никифорова М.А.
Журнал: Теория и практика современной науки @modern-j
Рубрика: Основной раздел
Статья в выпуске: 5 (23), 2017 года.
Бесплатный доступ
Статья посвящена совершенствованию управления кадровой политикой образовательной организации путем повышения эффективности процесса оценки и подбора персонала на основе технологий интеллектуального анализа данных. В качестве инструментов решения данной задачи предлагается комплексный подход на основе совместного использования метода латентно-семантического анализа и технологии статистического имитационного моделирования. Также в работе описывается пример реализации предлагаемого комплексного подхода на основе интеллектуальной программной системы анализа данных.
Интеллектуальные информационные технологии, интеллектуальный анализ данных, латентно-семантический анализ, статистическое имитационное моделирование, управление социально-экономическими процессами, управление кадровой политикой
Короткий адрес: https://sciup.org/140271642
IDR: 140271642
Management of personnel policy of the educational organizations improvement based on data mining technologies
Main goal of this article is in the personnel policy of the educational organization management improvement by increasing the efficiency of the personnel assessment and selection process based on data mining technologies. As an instrument for this problem solving proposed a comprehensive approach that based on latent semantic analysis and statistical simulation modeling technologies integration. Also article describes the Intelligent Software System for Data Analysis that is implements the proposed integrated approach.
Текст научной статьи Совершенствование управления кадровой политикой образовательной организации на основе технологий интеллектуального анализа данных
Целью данной работы является совершенствование управления кадровой политикой образовательной организации на основе технологий интеллектуального анализа данных (ИАД), а именно комплексного использования методов латентно-семантического анализа (ЛСА) и технологии статистического имитационного моделирования (СИМ).
Кадровое обеспечение образовательных организаций является одним из самых важных механизмов функционирования образовательной системы. Именно качественный подбор преподавателей и педагогов на основании объективной оценки их текущих компетенций, непрерывное совершенствование квалификации и удержание высококвалифицированных кадров обеспечивают высокое качество образовательного процесса. В настоящее время сохраняется устойчивая тенденция к нехватке квалифицированных специалистов в образовательных учреждениях различных типов вследствие низких уровня оплаты труда и социального престижа профессии педагога, слабой социальной защищенности педагогических и научно-педагогических работников [1]. Также все чаще наблюдается несоответствие квалификации сотрудников современным образовательным стандартам и требованиям, предъявляемым к занимаемым ими должностям. Кроме того, существует проблема некорректного планирования учебной нагрузки и последующего вынужденного экстренного поиска специалистов, а также проблема развития сотрудников и повышения уровня их квалификации. Учитывая все вышесказанное, можно сделать вывод об актуальности проблемы совершенствования управления кадровой политикой образовательных организаций. Для решения данной проблемы предлагается использование технологий интеллектуального анализа данных, которые в настоящий момент имеют достаточно развитые и проверенные на практике методы и инструментарии, позволяющие с необходимой эффективностью решить поставленные в задачи.
Объектом исследования являются образовательные организации различных уровней образования, включая начальную, среднюю и высшую школы.
Предметом исследования являются процессы управления кадровой политикой образовательных организаций.
Для достижения поставленной цели было решено использовать ЛСА и СИМ.
Латентно-семантический анализ - это метод, относящийся к технологиям ИАД [2, 3] и применяющийся в задачах анализа информации на естественном языке. ЛСА позволяет решать задачи классификации текста, другими словами, распределять анализируемые тексты по различным заранее заданным категориям (классам).
В качестве исходной информации ЛСА использует матрицу термы-на-документы (термы – слова или словосочетания), описывающую набор данных, используемый для обучения системы. Элементы этой матрицы содержат, как правило, веса, учитывающие частоты использования каждого терма в каждом документе или вероятностные меры (PLSA – вероятностный латентно-семантический анализ), основанные на независимом мультимодальном распределении. [4]
ЛСА «проецирует» документы и отдельные слова в так называемое «семантическое пространство», в котором и производятся все дальнейшие вычисления. При этом делаются следующие предположения:
-
1. Документы это просто набор слов. Порядок слов в документах игнорируется. Важно только то, сколько раз то или иное слово встречается в документе (вес терма).
-
2. Семантическое значение документа определяется набором слов, которые, как правило, используются в анализируемом документе совместно.
-
3. Каждое слово имеет единственное значение. [5]
В рамках предлагаемого подхода при помощи ЛСА будет осуществляться анализ текстовой информации о кандидатах на вакантные должности, а также кандидатов на позиции временной замены других сотрудников (на время отпуска или больничного) по заранее определенным критериям с целью подбора на вакантные места и распределения свободной рабочей нагрузки учебного заведения. Поиск будет осуществляться по внутренней базе сотрудников, а также в сторонних источниках – сайтах поиска работы (например, сайт hh.ru и т.п.). Подбор будет производиться путем анализа частоты встречаемости ключевых слов в различных документах, имеющихся по рассматриваемому кандидату (резюме, личное дело, статьи, публикации), для определения направления его деятельности. Под статистическим имитационным моделированием понимают построение имитационной модели существующего или гипотетического (предполагаемого, разрабатываемого) объекта, учитывающей случайные явления, оказывающие влияние на состояние или поведение моделируемого объекта. СИМ базируется на численном статистическом методе решения математических задач, называемых методом Монте-Карло. Использование СИМ позволяет моделировать практически любые объекты и явления, в том числе социально-экономические, с учетом большого числа случайных факторов. [6]
В данной работе СИМ используется для создания СИМ-модели бизнес-процесса формирования учебной нагрузки с целью моделирования и расчета учебной нагрузки и числа необходимых для данной нагрузки ставок преподавателей. Расчеты будут учитывать текущее число учащихся и учебных групп учебного заведения.
Использование описанных методов ИАД обусловлено тем, что в научной литературе имеются примеры их успешного применения для решения задач совершенствования процессов образовательных учреждений.
К примеру, в Петербургском государственном университете путей и сообщений латентно-семантический анализ был успешно применен для автоматической рубрикации документов по множеству заданных тематических рубрик в системах электронного документооборота с целью тематического разграничения доступа пользователей к ним [7].
Другим примером является использование ЛСА для анализа Интернет-текстов с целью формирования, разработки и корректировки учебных планов и образовательных программ. Система выявляет теоретически полезные понятия для каждой дисциплины и предупреждает о необходимости корректировки учебной программы из-за изменений в ядре знаний. Выбираются ключевые термины, затем по диаграмме кластеров терминов термины, наиболее близкие к ключевым, помечаются в качестве кандидатов для включения в учебную программу, наиболее отдаленные – в качестве кандидатов на исключение из неё [8].
Также в Воронежском государственном университете в рамках эксперимента внедрили технологию ЛСА для оценки качества переводов текстов с английского языка на русский при проведении тестирования учащихся [9]. Сначала качество переводов оценивал преподаватель, затем с помощью ЛСА оценивалась релевантность переводов студентов к переводу преподавателя и проводилось ранжирование. Результаты оценки системы и преподавателя сошлись. В тех случаях, когда преподаватель затруднялся с оценкой, система осуществляла оценку точнее.
Примером использования СИМ в совершенствовании образовательных процессов может служить система моделирования и организации учебного процесса заведения среднего профессионального образования, интегрированная с информационной системой образовательного учреждения, позволяющая руководству не только оценивать текущие экономические показатели учебного процесса, но и моделировать возможные варианты развития событий в зависимости от принимаемых решений, а также прогнозировать динамику основных показателей деятельности [10].
Другим примером может служить система автоматизированного определения соответствия кандидатов по заданным параметрам (включая оценку профессионального, этического и психологического соответствия) при найме и аттестациях [11]. Система использует сценарное имитационное моделирование для мониторинга потребности в рабочей силе для разных корпоративных стратегий и с учетом рисков, ограничений и возможностей внутреннего и внешнего рынков рабочей силы. Эта система выполняет некоторые необходимые функции, однако не осуществляет подбор кандидатов из уже работающих сотрудников. Она не обладает модулем анализа, то есть не может определить компетенции преподавателей. Также она не осуществляет прогноз учебной нагрузки и количества вакансий в зависимости от результатов прогноза.
Помимо рассмотренных подходов на рынке программного обеспечения существуют готовые программные продукты для управления кадровой политикой. Их можно условно разделить на следующие группы.
-
• Модули управления кадрами в составе комплексных информационных систем (например, SAP, Oracle, BAAN, Scala, Navision 38, Галактика, Парус, 1С, БОСС, Бэст-Про).
-
• Специализированные программы учета кадров (например, «1С: Управление персоналом 8.0», «1С:Зарплата и кадры 7.7», система HRB компании Robertson&Blums).
-
• Локальные специализированные решения – (например, «Резюмакс» и «Рекрутер», Maintest3, CAPTain Online).
-
• Распределенные узкоспециализированные информационные системы (например,«Единая государственная кадровая система «Картка»). [12]
Все перечисленные программные системы имеют множество функций для учета и мониторинга различных аспектов выполнения процессов организации, но не имеют функционала для поддержки принятия решений.
Анализ существующих примеров применения ИАД-технологий и готовых программ для управления кадровой политикой в образовательной сфере позволяет сделать вывод об отсутствии подходов и обеспечивающих данные подходы программных продуктов, которые бы учитывали специфику образовательных организаций. В этой связи необходимо разработать собственную программную систему для обеспечения процесса управления кадровой политикой образовательных организаций, которая позволит реализовать предлагаемой в статье подход к управлению с учетом особенностей образовательной системы.
Алгоритм функционирования разрабатываемой интеллектуальной системы анализа данных представлен в виде блок-схемы на рисунке 1. На схеме алгоритма отражены основные функции, которые будет выполнять система и используемые системой данные.
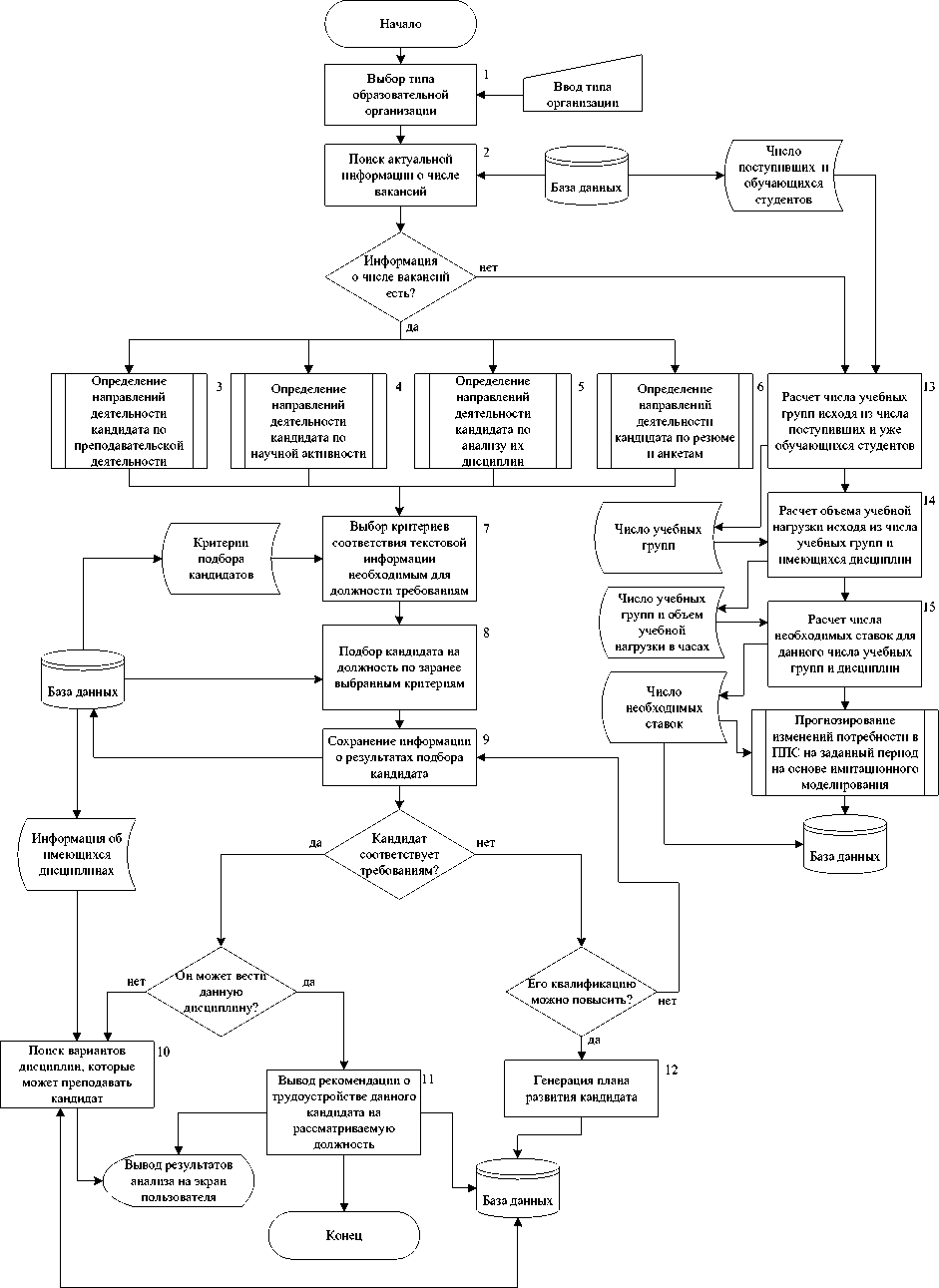
Рис.1. Блок-схема работы предлагаемой интеллектуальной системы анализа
данных
Основные структурные компоненты разрабатываемой системы представлены на рисунке 2.
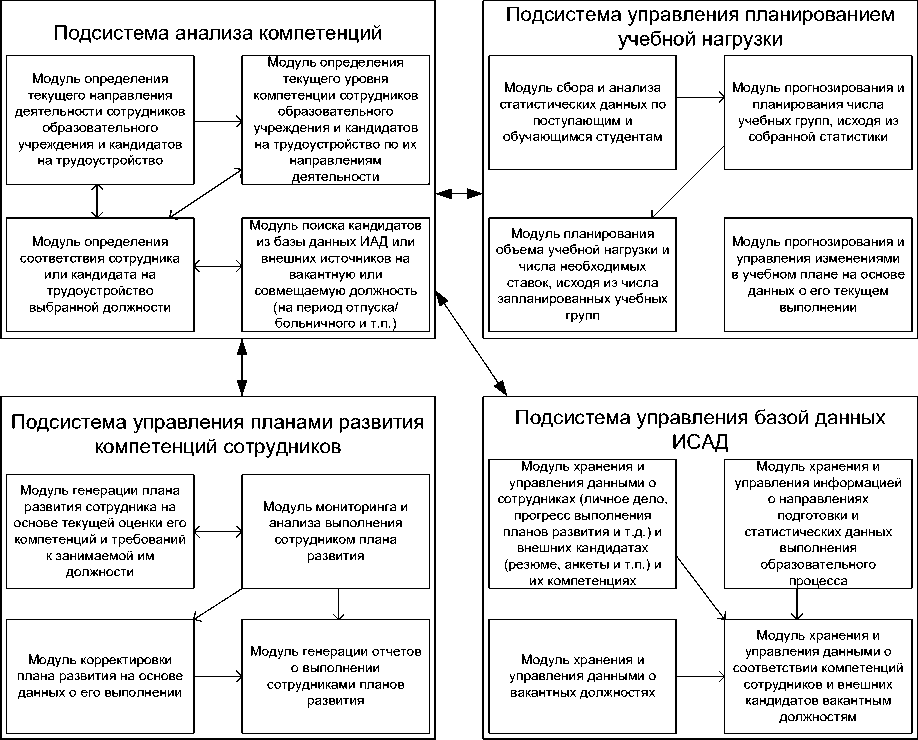
Рис.2. Основные структурные компоненты интеллектуальной системы анализа данных и их взаимосвязи
Для начала, при помощи технологии СИМ, с использованием статистических данных (число студентов/учеников, учебных групп, преподавателей/педагогов, дисциплин/предметов) разрабатывается СИМ-модель бизнес-процесса формирования учебной нагрузки. Разработанная СИМ-модель будет моделировать и рассчитывать показатели по учебной нагрузке за заданный период моделирования, основываясь на числе обучаемых на данный момент в учебном заведении числе учебных групп.
Для разработки СИМ-модели необходимо идентифицировать законы распределения случайных величин моделируемого процесса и найти оценки параметров их моделирования, разработать математическую модель и моделирующий алгоритм, на основе которого модель и будет функционировать.
Число ставок будет рассчитываться по формуле: t=(T-730)/900 , где t - количество ставок,
T - общая нагрузка за один учебный год.
В свою очередь, нагрузка рассчитывается путем сложения часов, необходимых для занятий различных форм: практик, прием зачетов, экзаменов и т.д. Модель будет использовать данные учебных планов и нормативы нагрузки, а также введенные пользователем данные. Далее модель будет выводить прогноз на заданный период по числу необходимых ставок и по учебной нагрузке в часах, а руководитель принимать кадровые решения.
Затем при помощи ЛСА производится анализ различных текстов (текстов статей и докладов, названий дисциплин, названий специальностей и т.п., научной активности и преподавательской деятельности). Анализ текстов выполняется автоматически. Базу текстов и часто встречаемых важных термов создает пользователь. После того, как для рассматриваемого преподавателя определены направления деятельности, система по заранее заложенным в неё критериям определяет, соответствует ли он занимаемой должности. Если не соответствует, то генерирует и предлагает план развития и производит непрерывный мониторинг прогресса по нему. В случае отсутствия прогресса, на место педагога системой подыскивается и предлагается новый сотрудник. Поиск осуществляется сначала по базе имеющихся преподавателей, подходящих на должность по ключевым словам. При отсутствии подходящих кандидатов, поиск производится за пределами образовательной организации – на сайтах и ресурсах поиска работы.
Также систему можно применять и для поиска временной замены преподавателя на период отпуска, больничного, отпуска по уходу за детьми в период декрета, поиска членов диссертационного совета на основе определенных критериев и т.п. Система хранит в базе данных описание всех специальностей и всех дисциплин по каждой специальности в виде наборов ключевых слов (термов). Для того чтобы определить, подходит ли кандидат на должность преподавателя по какой-либо дисциплине, анализируются на частоту встречаемости ключевые термы специальности и дисциплины, тексты статей, резюме, характеристика кандидата и т.п. (вся информация о нем).
Проиллюстрируем работу ЛСА следующим примером. У нас имеется три кандидата на должность преподавателя по дисциплине, которую можно охарактеризовать тремя термами: магнит, слоя, развитого. Необходимо определить, какой из кандидатов больше подходит на данную вакансию. Для этого рассмотрим по одной статье от каждого кандидата и определим насколько заголовки статей кандидатов близки дисциплине, на которую он рассматривается и которая характеризуется тремя указанными выше термами. Другими словами, определим с помощью ЛСА насколько суть каждой из статей, описываемых словами из их заголовков, близка сути дисциплины, описываемой указанными выше тремя термами.
Заголовки статей следующие:
Статья_1: Моделирование электрического поля в рамках токового слоя.
Статья_2: Моделирование развитого магнитного поля в сильно возмущенной магнитосфере.
Статья_3: Моделирование сильно развитого поля в рамках слоя
Предположим, что мы используем термин частоты появления терминов из нашего запроса в анализируемых статьях для определения веса запроса.
Используем ЛСА для ранжирования этих статей по ключевым словам. Для этого выполним несколько шагов.
Шаг 1: Определим веса термов и построим матрицу по статьям и матрицу ключевых слов:
|
Термы |
Статья 1 ^^^^^^^™ |
Статья 2 ^^^^^^^™ |
Статья 3 ^^^^^^^™ |
Запрос |
|
в |
1 |
1 |
1 |
0 |
|
сильно |
0 |
1 |
1 |
0 |
|
электрического |
1 |
0 |
0 |
0 |
|
возмущенно й |
0 |
1 |
0 |
0 |
|
токового |
1 |
0 |
0 |
0 |
|
А = |
q = |
|||
|
слоя |
1 |
0 |
1 |
1 |
|
поля |
1 |
1 |
1 |
0 |
|
моделирование |
1 |
1 |
1 |
0 |
|
рамках |
1 |
0 |
1 |
0 |
|
магнит |
0 |
2 |
0 |
1 |
|
развитого |
0 |
1 |
1 |
1 |
Шаг 2: Произведем сингулярное разложение ( Singular Value
Decomposition, SVD) [5, 7] матрицы A, для этого найдем U, S и V матрицы, где A=USVT, при этом U и V – ортогональные матрицы, S – диагональная матрица, содержащая коэффициенты SVD, а VT – это транспонированная матрица V:
|
Статья 1 ^^^^^^^™ |
Статья 2 ^^^^^^^™ |
Статья 3 ^^^^^^^™ |
|
- 0.4201 |
0.0748 |
- 0.0460 |
|
- 0.2995 |
- 0.2001 |
0.4078 |
|
- 0.1206 |
0.2749 |
- 0.4538 |
|
- 0.1576 |
- 0.3046 |
- 0.2006 |
|
- 0.1206 |
0.2749 |
- 0.4538 |
|
U = - 0.2626 |
0.3794 |
0.1547 |
|
- 0.4201 |
0.0748 |
- 0.0460 |
|
- 0.4201 |
0.0748 |
- 0.0460 |
|
- 0.2626 |
0.3794 |
0.1547 |
|
- 0.3151 |
- 0.6093 |
- 0.4013 |
|
- 0.2995 |
- 0.2001 |
0.4078 |
4.0989 0.0000 0.0000
S = 0.0000 2.3616 0.0000
0.0000 0.0000 1.2737
|
- 0.4945 |
0.6492 |
- 0.5780 |
|
V = - 0.6458 |
- 0.7194 |
- 0.2556 |
|
- 0.5817 |
0.2469 |
0.7750 |
- 0.4945 - 0.6458 - 0.5817
VT = 0.6492 - 0.7194 0.2469
- 0.5780 - 0.2556 0.7750
Шаг 3: Уменьшим размерность выборки до k=2 , и запишем данные в матрицы Uk, Vk, Sk, VTk этой размерности. Для этого возьмем первые два столбца матриц U и V и первые два столбца и строки матрицы S .
|
- 0.4201 |
0.0748 |
|
- 0.2995 |
- 0.2001 |
|
- 0.1206 |
0.2749 |
|
- 0.1576 |
- 0.3046 |
|
- 0.1206 |
0.2749 |
|
U ≈ Uk = - 0.2626 |
0.3794 |
|
- 0.4201 |
0.0748 |
|
- 0.4201 |
0.0748 |
|
- 0.2626 |
0.3794 |
|
- 0.3151 |
- 0.6093 |
|
- 0.2995 |
- 0.2001 |
S-Sk = 4.0989 0.0000
0.0000 2.3616
-0.4945 0.6492
V « Vk = -0.6458 -0.7194
-0.5817 0.2469
1 VT % VTk = -0.4945 -0.6458 - 0.5817 0.6492 -0.7194 0.2469
Шаг 4: Найдем векторные координаты названий статей в этом сокращенном двумерном пространстве.
Строки из матрицы V имеют значения собственных векторов. Следовательно, это индивидуальные координаты статей:
Статья_1 = a1(-0.4945, 0.6492)
Статья_2 = a2(-0.6458, -0.7194)
Статья_3 = a3(-0.5817, 0.2469)
Шаг 5: Найдем векторные координаты ключевых слов дисциплины из нашего запроса в этом сокращенном двумерном пространстве, для этого необходимо выполнить следующую операцию над найденными на предыдущих шагах матрицами:
q = - 0.2140 - 0.1821
|
q = qTUkS - |
|
1 0.0000 |
|
qT = 00000100011 S -- = 4-0989 |
|
0.0000 1 |
|
2.3616 |
- 0.4201 0.0748
- 0.2995 - 0.2001
- 0.1206 0.2749
- 0.1576 - 0.3046
_ - 0.1206 0.2749
U k = - 0.2626 0.3794
- 0.4201 0.0748
- 0.4201 0.0748
- 0.2626 0.3794
- 0.3151 - 0.6093
- 0.2995 - 0.2001
Примечание: это новые векторные координаты ключевых слов в двух измерениях. Обратите внимание, что эта матрица отличается от исходной матрицы q на шаге 1.
Шаг 6: Определим «близость» значений матрицы q (описывающей двумерное векторное пространство термов дисциплины) и значений al, a2 и a3 координат статей (описывающих двумерное векторное пространство термов каждой из статей):
sun V(-0.2140)2 + (-0.182 l)2V(-0.4945)2+(0.64922 х (—0.2140)(—0.6458) + (-0.1821)(0.7194) sim(q, аа = . . = —0.9910 V'(-0.2140)2 + (-0.1821)\/(-0.6458)2+(0.71942 (—0.2140)(—0.5817) + (-0.1821)(0.2469) s im (q, a a = . . = —0.4478 7(-0.2140)2 + (-0.1821)2V(-0.5817)2+(0.24692 Проранжируем статьи в порядке убывания сходства ключевых слов дисциплины и названий статей: Статья_2 (а2) > Статья_3 (а3) > Статья_1 (а1) Мы видим, что вторая статья (Статья_2) имеет коэффициент корреляции с дисциплиной выше, чем третья (Статья_3) и первая (Статья_1) статьи. Значит, данная статья ближе по содержанию к набору заданных ключевых слов и на должность больше подходит написавший ее кандидат. Определив таким образом, соответствует ли текст работ соискателей на вакансию термам, описывающим саму вакансию, предлагаемая в данной работе система автоматически делает вывод о соответствии кандидата вакантной или занимаемой должности и выдает рекомендации по его трудоустройству, либо, в случае, с определением уровня квалификации сотрудника, по повышению его квалификации. В итоге на выходе после проведения имитационного моделирования получаются прогнозные значения необходимого числа ставок и часов учебной нагрузке. Выходными данными после проведения ЛСА будут являться план развития преподавателя, выводы о соответствии занимаемой или вакантной должности, требования к соискателям, рекомендации по приему на работу. Новизна результатов проведенного исследования состоит в комплексном применении технологий ЛСА и СИМ, позволяющем принимать решения в рамках управления кадровой политикой образовательного учреждения более оперативно и обоснованно.
Список литературы Совершенствование управления кадровой политикой образовательной организации на основе технологий интеллектуального анализа данных
- Совершенствование кадровой политики образовательных учреждений [Электронный ресурс] / ред. Коврига В.М.; Электрон.дан. - М: Издательский дом "Первое сентября"- Режим доступа: http://festival.1september.ru/articles/632089/, свободный. - Загл. с экрана.
- Лекция 1: Что такое DataMining? [Электронный ресурс]. - Национальный открытый университет "Интуит", 2003-2017. - Режим доступа: http://www.intuit.ru/studies/courses/6/6/lecture/158, свободный - Загл. с экрана.
- Интеллектуальный анализ данных [Электронный ресурс] - Режим доступа: http://www.studfiles.ru/preview/5663201/page:5/- Загл. с экрана.
- Латентно-семантический анализ [Электронный ресурс]; Электрон.дан. - Википедия. Свободная энциклопедия. - Режим доступа: https://ru.wikipedia.org/wiki/Латентно-семантический_анализ, свободный. - Загл. с экрана.
- Латентно-семантический анализ [Электронный ресурс]; - Режим доступа: https://habrahabr.ru/post/110078/, свободный. - Загл. с экрана.
- Статистическое имитационное моделирование [Электронный ресурс]; Электр.данные - Лекции - Имитационное моделирование экономических процессов. 2010г. - Режим доступа: http://www.studmed.ru/docs/document7137?view=4, свободный. - Загл. с экрана.
- Применение латентно-семантического анализа для автоматической рубрикации документов [Текст] / А.Д.Хомоненко, С.А.Краснов,. -Известия ПГУПС, 2012. - стр. 124-132.
- Использование веб-семантики для совершенствования образовательных программ вузов [Текст]/М.М.Шарнин, И.Шагаев, В.И.Протасов, И.В.Родина, О.В.Золотарев, О.А.Попова.-Журнал "RHEMA.PEMA"Московский педагогический государственный университет. Москва, номер 2/2015г. - стр.97-112
- Использование латентно-семантического анализа в компьютерном тестировании [Текст]/А.В.Сычев, м.М.Павловский - Санкт-Петербург, Труды XIIВсероссийской научно-методической конференции "Телематика-2005" - 2 с.
- Построение системы организации учебного процесса с использованием имитационного моделирования [Текст]/Д.А.Клопов. - М.2006г. - 138с.
- Управление персоналом (с применением информационных технологий) [Текст]/Н.В.Кисляк - Екатерингбург,2007г. - 91с.
- Матричный латентно-семантический анализ [Электронный ресурс]. - Режим доступа:http://wiki.dvo.ru/wiki/Матричный_латентно-семантический_анализ_текстовых_данных, свободный. - Загл. с экрана.
