Создание и пополнение терминологических систем с помощью семантического анализатора

Автор: Мочалова Анастасия Викторовна
Журнал: Ученые записки Петрозаводского государственного университета @uchzap-petrsu
Рубрика: Физико-математические науки
Статья в выпуске: 4 (149), 2015 года.
Бесплатный доступ
Автоматическое создание и пополнение терминологических систем на сегодняшний день является актуальной задачей. Это связано с тем, что подобные системы применяются для решения широкого спектра задач, связанных с анализом текстовой информации. Часто решение таких задач требует постоянного пополнения терминологических систем (терминосистем) актуальной информацией. В работе предлагается способ автоматического пополнения терминосистем с помощью алгоритма наложения семантических цепочек, специальным образом получаемых из набора семантических зависимостей. Эти семантические зависимости строит семантический анализатор по каждому анализируемому предложению входного русскоязычного текста. Определяются условия формирования семантических цепочек, а также предлагается алгоритм их наложения. Преимущество такого способа пополнения терминосистемы состоит в том, что в качестве анализируемых текстов могут использоваться любые русскоязычные тексты, содержащие проверенную, непротиворечивую информацию, а не только энциклопедические и толковые словари, или готовые онтологии, что позволяет вносить в систему информацию из новейших текстовых источников, например из научных статей, книг, докладов, новостных и аналитических обзоров.
Терминосистемы, пополнение терминосистем, семантические отношения, семантический анализатор
Короткий адрес: https://sciup.org/14750894
IDR: 14750894 | УДК: 004.822
Creation and update of terminological systems by means of semantic analyzer
An automated creation and update of terminological systems is an urgent challenge today. Such systems are used to solve a wide range of problems concerning the process of text analysis. The problem associated with these systems is substantiated by the need to permanently update current information. In the paper we propose a method, which automatically creates and updates terminological systems with the help of an algorithm. The algorithm overlaps semantic chains that are derived from a set of semantic dependencies built by a semantic analyzer applied to every sentence of the text. The advantage of this method, developed to create and update terminological systems, is based on the fact that any Russian authentic textual data may be used as an analyzed text. Encyclopedia dictionaries or glossaries can also be studied with the help of the analyzer. This method is instrumental in the update of the system with the information from new textual sources: scientific papers, books, scientific reports, news or analytical reviews.
Текст научной статьи Создание и пополнение терминологических систем с помощью семантического анализатора
В настоящее время уже существует достаточно большое количество различных терминологических систем. Такие системы могут использоваться как самостоятельно (например, в системах автоматических языковых переводов, в диалоговых, вопросно-ответных, поисковых системах и др.), так и в качестве составляющей более высокоуровневых хранилищ информации, например онтологий.
Одна из важнейших проблем, возникающих при использовании терминосистем, заключается в том, что данные, содержащиеся в них, должны соответствовать действительности: окружающий мир постоянно изменяется, что влечет за собой интенсивный рост объема информации. Для того чтобы уже созданные терминологические системы были актуальными, необходимо постоянно пополнять их новыми реальными данными.
На сегодняшний день имеются попытки автоматизировать процесс создания и пополнения терминосистем. Один из самых распространенных способов пополнения терминосистем базируется на использовании словарных определений. Также существует онтологический подход к построению терминосистем.
Однако большинство терминологических систем создается вручную (примерами подобных систем могут служить системы, особенности построения которых описаны в работах [6], [7]), что зачастую вызывает непреодолимые трудно
сти в силу крайне большого объема обрабатываемых информационных материалов и малого количества специалистов, способных выполнить подобную работу, или же дороговизны оплаты их труда. Поэтому задача автоматизации пополнения терминосистем в настоящее время является актуальной.
СПОСОБЫ АВТОМАТИЧЕСКОГО ПОПОЛНЕНИЯ ТЕРМИНОСИСТЕМ
Один из самых распространенных способов автоматического пополнения терминологических систем базируется на анализе словарных определений. При таком подходе в терминосистему добавляются сущности и тип их связи, найденные с помощью шаблонного поиска в словарном определении. Например, если требуется собрать все возможные виды строительных инструментов, то поиск в словаре производится по шаблонам вида «Х является разновидностью строительных инструментов, которые…», «Х – это строительный инструмент, используемый для…», «Х – вид строительного инструмента, применяемый с целью…» и т. д. Подобные шаблоны поиска могут формироваться как вручную, так и автоматически с помощью самообучающихся программ [9]. К примеру, идея автоматического пополнения терминологической системы, являющейся основной составляющей онтологии, подробным образом описывается в работах [15], [17], [18]. Автор работы [15], оценивая методы автоматического пополнения терминологических систем в рамках онтологий, утверждает, что изучение результатов, полученных на двух основных направлениях – Ontology learning from texts и Ontology learning from machine-readable dictionaries, а также собственный опыт привели его к выводу, что на данном этапе наиболее перспективна с точки зрения получения практических результатов технология, основанная на анализе и формализации определений, содержащихся в традиционных энциклопедических и толковых словарях. Автор работы [15] указывает на наличие отечественных работ, ориентированных на пополнение терминологических систем, находящихся в составе онтологий, на основе русскоязычных текстов. Примерами таких работ могут служить работы наших соотечественников А. Е. Ермакова [4], И. А. Минакова [8], В. И. Пекара [14], А. Нечи-поренко и А. Русина [13].
Другой способ автоматизации пополнения терминосистем базируется на использовании онтологий. Например, автор работы [1] описывает онтологический подход к построению термино-систем. В работе [3] на примере терминологии логистики описывается способ создания терми-носистем с помощью онтологий.
АВТОМАТИЧЕСКОЕ СОЗДАНИЕ И ПОПОЛНЕНИЕ ТЕРМИНОСИСТЕМЫ
Терминология
Терминосистема – упорядоченное множество терминов с зафиксированными отношениями между ними, отражающими отношения между называемыми этими терминами понятиями [2]. Терминосистему можно представить в виде ориентированного графа, узлами которого являются термины, а направленные ребра соответствуют семантическим зависимостям, связывающим эти термины.
Семантическая зависимость – некая универсальная связь, усматриваемая носителем языка в тексте. Эта связь бинарна, то есть она идет от одного семантического узла к другому узлу [16]. Будем говорить, что два различных слова α и β из одного предложения связывает семантическая зависимость с именем R (обозначим R ( α, β )), если между α и β существует некая универсальная бинарная связь.
Семантическая сеть – информационная модель предметной области, имеющая вид ориентированного графа, вершины которого соответствуют объектам предметной области, а дуги (ребра) задают отношения между ними. Объектами могут быть понятия, события, свойства, процессы [20].
Семантическим анализатором назовем программу, автоматически создающую базу данных, хранящую анализируемый текст в виде семантической сети.
Факт – достоверное знание, истинность которого доказана [5]. Предполагается, что на вход семантическому анализатору подаются тексты, истинность содержания которых не подлежит сомнению, поэтому в качестве фактов предлагается использовать определенные наборы семантических отношений между словами, словосочетаниями и другими синтаксическими единицами этих текстов на русском языке. О том, как именно формируются эти наборы, будет изложено далее. Подобное определение факта предложено в работе [12], где за факт принята семантическая зависимость, связывающая два термина.
Связные семантические отношения
Рассмотрим все возможные варианты соотношений (с точки зрения точного совпадения и несовпадения) между аргументами двух семантических зависимостей R 1 ( « 1 , 0 1) и R 2 ( а 2 , 0 2 ) (см. табл. 1).
В табл. 1 показано, что случай, когда совпадают аргументы более чем одной из четырех рассматриваемых пар, невозможен. Это связано с тем, что семантическая зависимость не может связывать два одинаковых аргумента, так же как не может быть двух зависимостей, связывающих одни и те же аргументы, расположенные в инверсном порядке, или двух различных семантических зависимостей, связывающих одни и те же аргументы. Другими словами, не существует R( а , а ), так же как не может существовать R 1 ( « 1 , 0 1), если есть R 2 ( 0 1 , а 1 ) и не может быть таких различных R 1 и R 2 , для которых будет верно как R 1 ( « 1 , 0 1) , так и R2( а 1 , 0 1 ) (случай когда R 1 = R 2 , « 1 = а 2 и 0 1 = 0 2 , очевидно, тоже рассматривать бессмысленно ). Таким образом , имеет смысл рассматривать лишь те варианты соотношений между аргументами семантичес ких зависимостей R 1 ( a 1 , 0 1 ) и R 2 ( а 2 , 0 2 ), которые в табл . 1 отмечены как возможные случаи .
Пару семантических отношений R 1 ( а 1 , 01) и R 2 ( а 2 , 0 2 ) назовем связной, если выполнено одно из четырех следующих условий :
( « 1 * «2) &( 0 1 * 02) &( « 1 * 0 2 )&( 0 1 = Л2) (1) ( а 1 * а 2)&( 0 1 * 0 2)&( а 1 = 0 2)&( 0 1 * Л 2) (2) ( а 1 * а 2)&( 0 1 = 0 2)&( а 1 * 0 2)&( 0 1 * Я 2 ) (3) ( « 1 = « 2 )&( 0 1 * 0 2 )&( « 1 * 0 2 )&( 0 1 * Х 2) (4)
Пример 1: Рассмотрим анализируемое пред ложение : «Скачет, мчится по пыльной дороге уставший всадник». Для этого предложения будут составлены семантические связи :
-
• Основа (всадник, мчаться) (R1) • Основа (всадник, скакать) (R2) • Характеристика_действия
(скакать, быстро) (R3) • Местоположение (скакать, по дорога) (R4) • Местоположение (мчаться, по дорога) (R5) • Признак (дорога, пыльный) (R6)
Таблица 1
Соотношение между аргументами семантических зависимостей R i ( a i , 0 ) и R 2 ( a 2 , 02)
|
№ |
Соотн. между a i и a 2 |
Соотн. между 0 и 0 2 |
Соотн. между a i и 0 2 |
Соотн. между 0 i и a 2 |
Выводы |
|
1 |
а * a 2 |
0 i * 0 2 |
a i * 0 2 |
0 i * a 2 |
Недостаточно информации |
|
2 |
a i * a 2 |
0 i * 0 2 |
a i * 0 2 |
0 i = a 2 |
Возможный случай № 1 |
|
3 |
a i * a 2 |
0 i * 0 2 |
a i = 0 2 |
0 i * a 2 |
Возможный случай № 2 |
|
4 |
a i * a 2 |
0 i * 0 2 |
a i = 0 2 |
0 i = a 2 |
Противоречие |
|
5 |
a i * a 2 |
0 i = 0 2 |
a i * 0 2 |
0 i * a 2 |
Возможный случай № 3 |
|
6 |
a i * a 2 |
0 i = 0 2 |
a i * 0 2 |
0 i = a 2 |
Противоречие |
|
7 |
a i * a 2 |
0 = 0 2 |
a i = 0 2 |
0 i * a 2 |
Противоречие |
|
8 |
a i * a 2 |
0 i = 0 2 |
a = 0 2 |
0 i = a 2 |
Противоречие |
|
9 |
a i = a 2 |
0 i * 0 2 |
a i * 0 2 |
0 i * a 2 |
Возможный случай № 4 |
|
10 |
a = a 2 |
0 i * 0 2 |
a i * 0 2 |
0 i = a 2 |
Противоречие |
|
11 |
a = a 2 |
0 i * 0 2 |
a i = 0 2 |
0 i * a 2 |
Противоречие |
|
12 |
a i = a 2 |
0 i * 0 2 |
a i = 0 2 |
0 i = a 2 |
Противоречие |
|
13 |
a = a 2 |
0 = 0 2 |
a i * 0 2 |
0 i * a 2 |
Противоречие |
|
14 |
a = a 2 |
0 i = 0 2 |
a i * 0 2 |
0 i = a 2 |
Противоречие |
|
15 |
a i = a 2 |
0 i = 0 2 |
a i = 0 2 |
0 i * a 2 |
Противоречие |
|
16 |
a i = a 2 |
0 i = 0 2 |
a i = 0 2 |
0 i = a 2 |
Противоречие |
-
• Признак (всадник, уставший) (R7)
В табл. 2 приведены пары семантических зависимостей, сформированные семантическим анализатором по предложению из примера 1. Каждый столбец таблицы содержит пары семантических отношений, для которых выполняются условия (1)–(4) соответственно.
Таблица 2
Пары связных семантических отношений, классифицированных в соответствии с условиями (1)–(4)
|
Пары сем. отнош., для которых верно условие ( ) |
Пары сем. отнош., для которых верно условие (2) |
Пары сем. отнош., для которых верно условие (3) |
Пары сем. отнош., для которых верно условие (4) |
|
(R )–(R5) |
(R3)–(R2) |
(R5)–(R4) |
(R )–(R7) |
|
(R4)–(R6) |
(R )–(R2) |
Семантическая цепочка
Семантической цепочкой назовем такой набор различных семантических связей R a0 = { RM, Д ) ,R 2 ( « 2 , АХ™, R n ( « n , 0 )} , в Котором все семантические связи можно упорядочить таким образом, что любое семантическое отношение, не стоящее на первом месте, будет связано хотя бы с одним семантическим отношением, стоящим до него (не обязательно c соседним). При этом a i , являющееся подлежащим в анализируемом предложении, по которому строится семантическая цепочка, назовем головным словом данной цепочки.
В работе [19] авторы определяют понятие лексической цепочки как последовательности слов текста, в которой каждое следующее слово связа- но некоторым отношением с предшествующими словами цепочки. Такие цепочки могут выходить за рамки одного предложения и проходить через целый текст.
Опираясь на это определение, семантические цепочки можно рассматривать как частный случай представления лексических цепочек, в которых отношения между узлами являются семантическими зависимостями, а сама семан- тическая цепочка рассматривается в рамках одного предложения. Однако узлы семантической цепочки имеют более высокий уровень в иерар- хии языковых единиц, так как являются не просто словами, как в случае с лексической цепочкой, а неделимыми смысловыми единицами, которые могут быть представлены группой слов.
Пример 2 : Рассмотрим предложение, приведенное в Примере 1. Для этого предложения семантическая цепочка будет представлена следующим множеством семантических связей R ap :
R aP = {
Основа (всадник, мчаться)
Основа (всадник, скакать)
Характеристика действия (скакать, быстро)
Местоположение (скакать, по дорога)
Местоположение (мчаться, по дорога) Признак (дорога, пыльный)
Признак (всадник, уставший)
},
так как все отношения из этого множества можно переставить таким образом, что любое семантическое отношение, не стоящее на первом месте, будет связано хотя бы с одним семантическим отношением, стоящим до него. На рис. 1 нагляд-
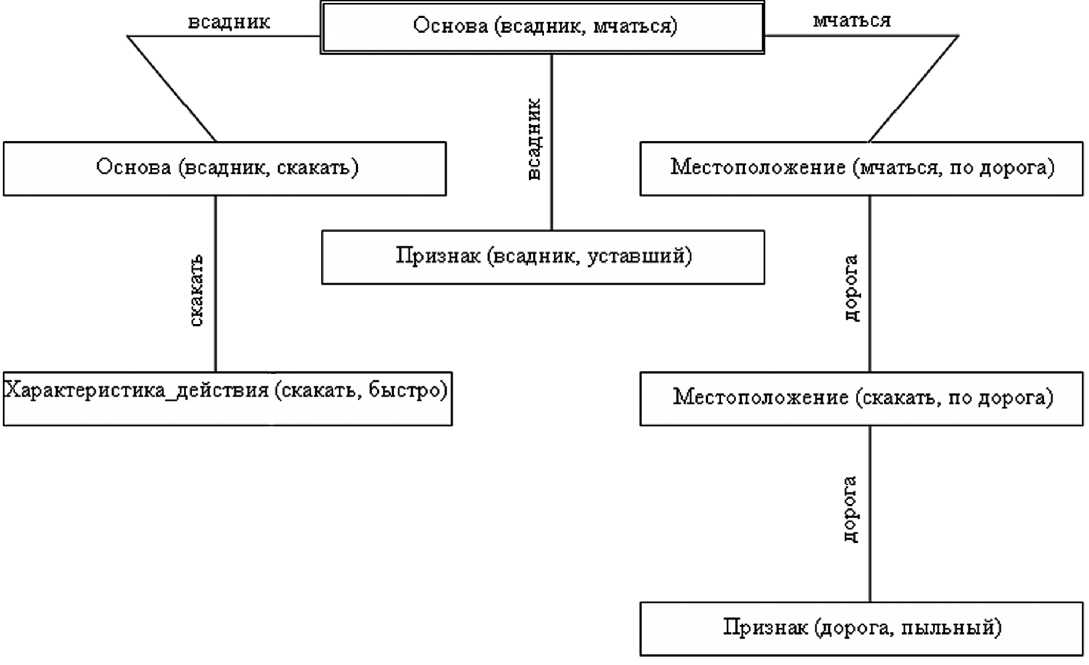
Рис. 1. Пары связных семантических зависимостей
но представлены пары связных семантических отношений, переставленные вышеописанным способом.
Очевидно, что все семантические зависимости из правильно построенного предложения будут принадлежать одной семантической цепочке.
Семантической цепочке соответствует ориентированный граф, в котором узлы - это слова, словосочетания или части предложения, являющиеся аргументами семантических зависимостей; вершины этого графа соединяют ребра, направленные от первого аргумента семантической связи ко второму. Ребра графа имеют названия, одноименные с семантическими связями, связывающими пару вершин данного графа.
На рис. 2 представлен семантический граф, сформированный по вышеописанным правилам и отражающий семантическую цепочку, сформированную по предложению из Примера 1 (головное слово обведено двойной рамкой).
Алгоритм наложения семантических цепочек
Результатом наложения двух семантических цепочек является один (в случае если головные слова семантических цепочек совпадают) либо
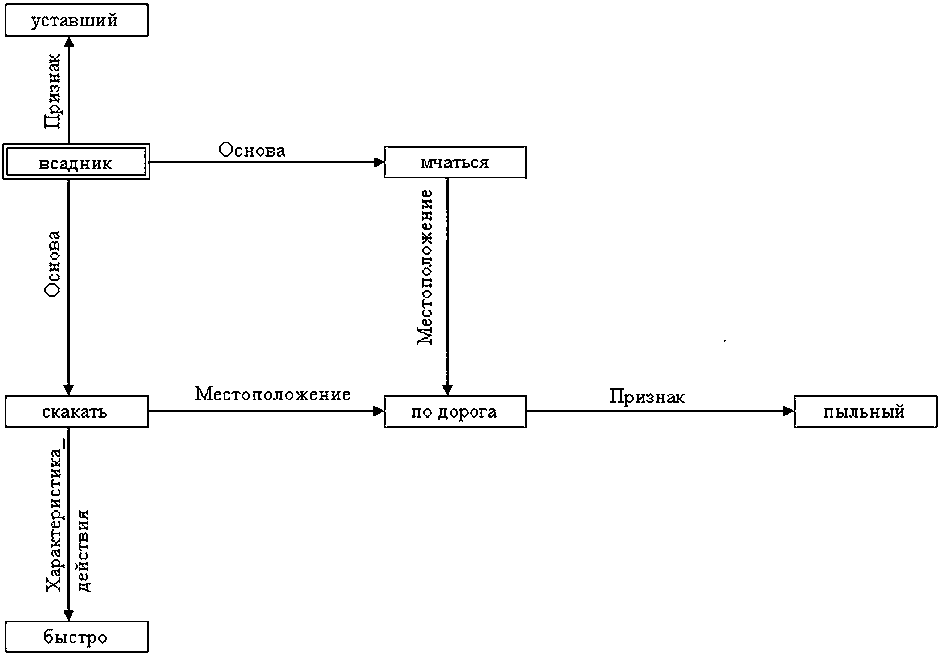
Рис. 2. Представление семантической цепочки в виде графа
два графа. Каждый граф, полученный в результате наложения семантических цепочек, является взвешенным и ориентированным. Узлы такого графа – это аргументы семантических связей, а ребра – семантические связи, связывающие эти аргументы. Каждое ребро такого графа имеет свой вес, определяющий количество вхождений конкретной семантической цепочки в анализируемый текст.
В результате наложения семантической цепочки R Op = { R O P^R O Ppp..,R>\,PX головным словом которой являет ся o\, на семантическую цепочку R Op = = { R 2( O 2, p 2), R O ftV , R O P^ } С ГО -ловным словом a 1 ( m > n ) должна быть получена либо одна семантическая цепочка R Op = { ROp;),R * ( o * , Ph,...,RM,О (в случае когда семантические зависимости , содержа щие головные слова цепочек R Op и R Op , совпадают, то есть R OP (oP pp = R^(OpPX, либо две исходные семантические цепочки R Op и R- Op .
Семантическая цепочка R Op (для случая когда R Op ( 0 1 , P 1 ) = R Op ( O 1 2, Д 2)) формируется из цепочек R Op и R pp путем объединения соответствующих им графов: R* ap : = R OP U R Op , при этом веса этих графов , представленные матрицами W ( R Op ) и W ( RO p ) соответственно, складываются: W ( R Op ): = W ( R Op ) + W( R Op ).
На рис . 3 представлена блок - схема алгоритма наложения семантических цепочек R O 1 p и R O 2 p .
На рис . 4 показан пример наложения двух се мантических цепочек R 0 P (рис. 4a) и R Op (рис. 4b), представленных в виде графов, у которых одинаковые узлы, являющиеся семантическими отношениями, обозначены одинаковыми литерами, а узел, являющийся семантическим отношением, содержащим головное слово цепочки, обведен в двойную рамку. На рис. 4c показана семантическая цепочка, полученная в результате
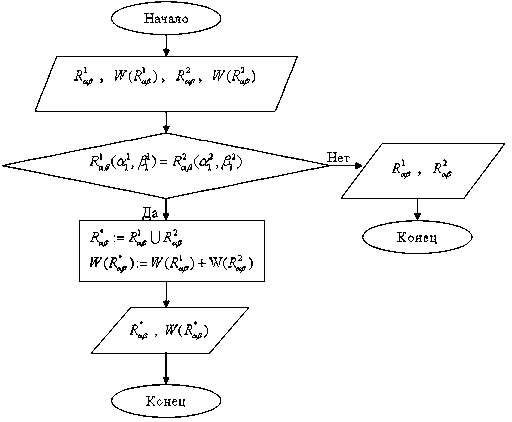
Рис. 3. Блок-схема алгоритма наложения семантических цепочек
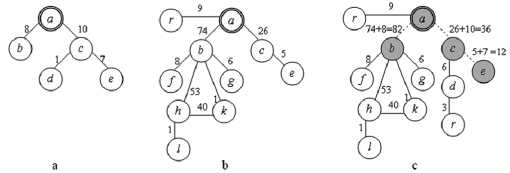
Рис. 4. Наложение семантических цепочек, представленных в виде графов наложения цепочек ROp и ROp . Вершины графа, являющиеся общими для графов, представляющих ROp и Rpp , выделены серым, а дуги, веса которых получились в результате суммирования соответствующих весов дуг R1P и ROp , нарисованы пунктиром.
Применение алгоритма наложения семантических цепочек для автоматизации пополнения терминосистем
Предлагается создавать терминологическую систему, представляя ее в виде ориентированного, взвешенного графа, полученного в результате наложения всех семантических цепочек, построенных по анализируемому тексту семантическим анализатором. Такое представление терминосис-темы позволит определять семантические связи между всеми терминами, содержащимися в анализируемых текстах. Терминологическую систему, построенную вышеописанным образом, можно постоянно пополнять путем анализа новых текстов. Это позволит хранить в системе новейшую информацию о терминах и связях между ними.
Значения веса ребер семантического графа было решено нормировать на диапазон от 0 до 1.
На основании анализа весов ребер графа, входящих в общее представление терминосистемы и образующих путь от одной вершины-термина до другой, можно делать предположение о кор -ректности и достоверности построенной между терминами связи. Логично предположить, что большее значение весов обуславливает бóльшую корректность и достоверность связи, определенной между терминами. Малое же значение весов может быть поводом для рассмотрения найденных связей между двумя терминами специалистом вручную.
Так как ребра графа, представляющего тер-миносистему, имеют веса и в качестве фактов рассматриваются семантические цепочки, то каждому факту в терминосистеме можно в соответствие поставить значение «веса факта», который, например, может определяться минимальным весом из всех ребер цепочки. Тогда для каждого факта в терминологической системе можно предположить его истинность и достоверность: очевидно, что факт с бóльшим весом будет иметь бóльшую достоверность с большей вероятностью.
Вышеописанный способ построения термино-системы был программно реализован на языке
| рабочий |
| для лечение |
| бронхит]
|волчанка|
ХАРАКТЕРИСТИКА ДЕЙСТВИЯ
(!)
|пчела|
I3
I------------ПРИЗНАК,---------1
| восковьш | «— | железа |
В 3 :г———--- основа, -----—~--------1
1 пчелиный, —^у-► |выраоатываться|
| в медицина | применяться.
- использоваться
■ | шпроко|
| в промышленность |
| косметический |
Рис. 5. Граф представления терминосистемы программирования Java и в качестве составного модуля внедрен в вопросно-ответную систему, описанную в работе [11]. В качестве семантического анализатора, с помощью которого находятся семантические отношения и из которых впоследствии составляются семантические цепочки, использовалась программа-анализатор, алгоритм работы которой описан в статье [10].
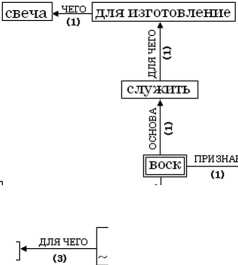
Пример 3 : Рассмотрим в качестве анализируемого текста следующие предложения, описывающие некоторые свойства термина «воск»: «Пчелиный воск вырабатывается восковыми железами рабочих пчел. Для лечения бронхитов используется воск. Воск широко применяется в косметической промышленности. Воск использовали в медицине. Воск служит для изготовления свечей. Воск применяется для лечения волчанки. Воск используется для лечения бронхитов».
Для этого текста по правилам, описанным в разделе «Алгоритм наложения семантических цепочек», будет создан ориентированный, взвешенный граф, представленный на рис. 5 (головное слово, являющееся термином, заносимым в систему, обведено двойной рамкой).
ЗАКЛЮЧЕНИЕ
В работе предложен способ создания и пополнения терминологической системы с помощью разработанного и описанного алгоритма наложения семантических цепочек. Семантические цепочки специальным образом составляются из связных семантических зависимостей, которые семантический анализатор строит для каждого анализируемого предложения. Связность семантических зависимостей предлагается определять условиями (1)–(4).
В отличие от наиболее распространенного в настоящее время способа пополнения термино-систем, основанного на использовании толковых и энциклопедических словарей, предлагаемый способ позволяет дополнять такие системы данными, содержащимися в текстовых источниках, на которые не накладываются дополнительные ограничения (помимо корректности описываемой информации и правильности составления предложений).
Предлагаемый в работе способ автоматического составления и пополнения терминосистемы программно реализован на языке программирования Java. Созданная терминосистема используется в алгоритме работы вопросно-ответной системы, описанной в статье [11].
В перспективе планируется использовать алгоритм построения и пополнения терминосисте-мы для автоматизации создания онтологии, которая будет интегрирована с вопросно-ответной системой [11].
* Работа выполнена при финансовой поддержке РГНФ в рамках научного проекта № 15–04–12029 «Программная разработка электронного ресурса с онлайн-версией русскоязычной вопросно-ответной системы».
CREATION AND UPDATE OF TERMINOLOGICAL SYSTEMS BY MEANS
OF SEMANTIC ANALYZER
Список литературы Создание и пополнение терминологических систем с помощью семантического анализатора
- Арзамасцева И. В. Модели, методы и средства разработки лингвистического обеспечения проектных репозиториев САПР: Дисс.. канд. техн. наук. Ульяновск, 2011. 270 с.
- Гринев С. В. Введение в терминоведение. М.: Московский Лицей, 1993. 309 с.
- Мюллер Ю. Э. Применение онтологий для создания терминосистем (на примере терминологии логистики)//II Congreso Intemacional “La lengua y literatura rusas en el espacio educativo intemacional: estado actual y perspectivas”. Т. II. Мадрид: Rubinos-1860, S. A, 2010. С. 2038-2042.
- Ермаков А. Е. Автоматизация онтологического инжиниринга в системах извлечения знаний из текста//Труды международной конференции «Диалог 2008» . Режим доступа: http://www.dialog-21.ru/digests/dialog2008/materials/html/23.htm
- Ефремова Т. Ф. Новый словарь русского языка (толково-словообразовательный). М.: Дрофа: Русский язык, 2000. 1233 с.
- Леонова С. А. Терминосистема «автоматизированный электропривод» в английском и русском языках: синхронно-диахронный анализ: Дисс.. канд. филол. наук. М., 2012. 257 с.
- Майтов а А. В. Терминосистема предметно-специального языка «Банковское дело» в лингвокогнитивном аспекте -на материале русского и немецкого языков: Дисс.. канд. филол. наук. М., 2008. 257 с.
- Минаков И. А. Системный анализ, онтологический синтез и инструментальные средства обработки информации в процессах интеграции профессиональных знаний: Автореф. дисс.. д-ра техн. наук. Самара, 2007. 43 с.
- Митрофанова О. А., Константинова Н. С. Онтологии как системы хранения знаний//Всероссийский конкурсный отбор обзорно-аналитических статей по приоритетному направлению «Информационно-телекоммуникационные системы». 2008. 54 с.
- Мочалова А. В. Алгоритм семантического анализа текста, основанный на базовых семантических шаблонах с удалением//Научно-технический вестник информационных технологий, механики и оптики. 2014. № 5. С. 126-132.
- Мочалова А. В., Мочалов В. А. Интеллектуальная вопросно-ответная система//Информационные технологии. 2011. № 5. С. 6-12.
- Найханова Л. В. Методы и модели автоматического построения онтологий на основе генетического и автоматного программирования: Дисс.. д-ра техн. наук. M., 2009. 451 с.
- Нечипоренко А.,Русин А. Система автоматизированного извлечения знаний из текстов на естественном языке//Труды международной научно-технической конференции «Информационные системы и технологии -2003». Новосибирск, НГТУ, 2003 . Режим доступа: http://www.noolab.ru/index.php?id=stat&show=18
- Пекар В. И. Автоматическое пополнение специализированного тезауруса//Труды международной конференции «Диалог 2002» . Режим доступа: http://www.dialog-21.ru/en/digest/archive/2002/?year=2002&vol =22725&id=7631
- Рубашкин В. Ш. Онтологическая семантика. Знания. Онтологии. Онтологически ориентированные методы информационного анализа текстов. М.: ФИЗМАТЛИТ, 2013. 348 с.
- Сокирко А. В. Семантические словари в автоматической обработке текста: По материалам системы ДИАЛИНГ: Дисс.. канд. техн. наук. М., 2001. 120 с.
- Aramaki E., Imai T., Kashiwagi M., Kajino M., Miyo K. and Ohe K. Toward medical ontology using Natural Language Processing. Available at: http://www.rn.u-tokyo.ac jp/medinfo/ont/paper/2005-ara.-1.pdf
- Hovy E., Knight K., Junk M. Large Resources. Ontologies (SENSUS) and Lexicons. Available at: www.isi.edu/natural-language/projects/ONTOLOGIES.html
- Morris J., Hirst G. Lexical Cohesion Computed by Thesaural Relations as an Indicator of the Structure of the Text//Computational Linguistics, 1991. № 17 (1). P. 21-45.
- Roussopoulos N. D. A semantic network model of data bases. -TR No 104, Department of Computer Science, University of Toronto, 1976.
